 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers
Oct 09, 2024



The performance of Transformer models has been enhanced by increasing the number of parameters and the length of the processed text. Consequently, fine-tuning the entire model becomes a memory-intensive process. High-performance methods for parameter-efficient fine-tuning (PEFT) typically work with Attention blocks and often overlook MLP blocks, which contain about half of the model parameters. We propose a new selective PEFT method, namely SparseGrad, that performs well on MLP blocks. We transfer layer gradients to a space where only about 1\% of the layer's elements remain significant. By converting gradients into a sparse structure, we reduce the number of updated parameters. We apply SparseGrad to fine-tune BERT and RoBERTa for the NLU task and LLaMa-2 for the Question-Answering task. In these experiments, with identical memory requirements, our method outperforms LoRA and MeProp, robust popular state-of-the-art PEFT approaches.
Konstruktor: A Strong Baseline for Simple Knowledge Graph Question Answering
Sep 24, 2024While being one of the most popular question types, simple questions such as "Who is the author of Cinderella?", are still not completely solved. Surprisingly, even the most powerful modern Large Language Models are prone to errors when dealing with such questions, especially when dealing with rare entities. At the same time, as an answer may be one hop away from the question entity, one can try to develop a method that uses structured knowledge graphs (KGs) to answer such questions. In this paper, we introduce Konstruktor - an efficient and robust approach that breaks down the problem into three steps: (i) entity extraction and entity linking, (ii) relation prediction, and (iii) querying the knowledge graph. Our approach integrates language models and knowledge graphs, exploiting the power of the former and the interpretability of the latter. We experiment with two named entity recognition and entity linking methods and several relation detection techniques. We show that for relation detection, the most challenging step of the workflow, a combination of relation classification/generation and ranking outperforms other methods. We report Konstruktor's strong results on four datasets.
* 18 pages, 2 figures, 7 tables
Unconditional Truthfulness: Learning Conditional Dependency for Uncertainty Quantification of Large Language Models
Aug 20, 2024



Uncertainty quantification (UQ) is a perspective approach to detecting Large Language Model (LLM) hallucinations and low quality output. In this work, we address one of the challenges of UQ in generation tasks that arises from the conditional dependency between the generation steps of an LLM. We propose to learn this dependency from data. We train a regression model, which target variable is the gap between the conditional and the unconditional generation confidence. During LLM inference, we use this learned conditional dependency model to modulate the uncertainty of the current generation step based on the uncertainty of the previous step. Our experimental evaluation on nine datasets and three LLMs shows that the proposed method is highly effective for uncertainty quantification, achieving substantial improvements over rivaling approaches.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
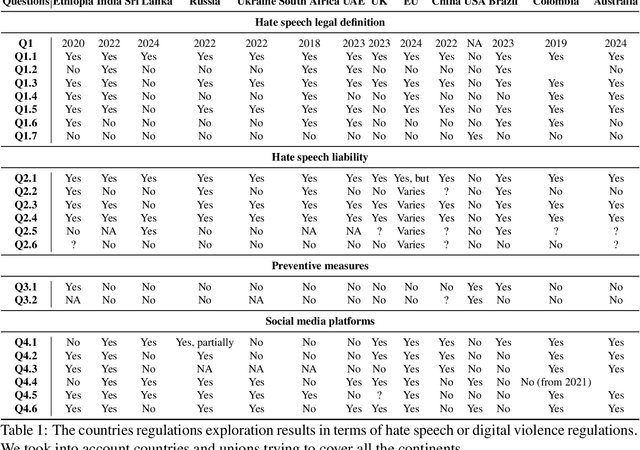
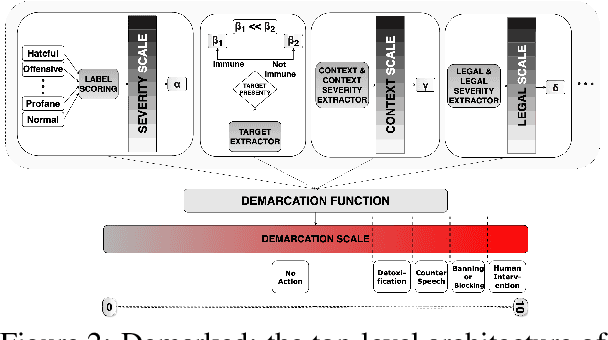

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
S3: A Simple Strong Sample-effective Multimodal Dialog System
Jun 26, 2024



In this work, we present a conceptually simple yet powerful baseline for the multimodal dialog task, an S3 model, that achieves near state-of-the-art results on two compelling leaderboards: MMMU and AI Journey Contest 2023. The system is based on a pre-trained large language model, pre-trained modality encoders for image and audio, and a trainable modality projector. The proposed effective data mixture for training such an architecture demonstrates that a multimodal model based on a strong language model and trained on a small amount of multimodal data can perform efficiently in the task of multimodal dialog.
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph
Jun 21, 2024



Uncertainty quantification (UQ) is becoming increasingly recognized as a critical component of applications that rely on machine learning (ML). The rapid proliferation of large language models (LLMs) has stimulated researchers to seek efficient and effective approaches to UQ in text generation tasks, as in addition to their emerging capabilities, these models have introduced new challenges for building safe applications. As with other ML models, LLMs are prone to make incorrect predictions, ``hallucinate'' by fabricating claims, or simply generate low-quality output for a given input. UQ is a key element in dealing with these challenges. However research to date on UQ methods for LLMs has been fragmented, with disparate evaluation methods. In this work, we tackle this issue by introducing a novel benchmark that implements a collection of state-of-the-art UQ baselines, and provides an environment for controllable and consistent evaluation of novel techniques by researchers in various text generation tasks. Our benchmark also supports the assessment of confidence normalization methods in terms of their ability to provide interpretable scores. Using our benchmark, we conduct a large-scale empirical investigation of UQ and normalization techniques across nine tasks and shed light on the most promising approaches.
xCOMET-lite: Bridging the Gap Between Efficiency and Quality in Learned MT Evaluation Metrics
Jun 20, 2024



State-of-the-art trainable machine translation evaluation metrics like xCOMET achieve high correlation with human judgment but rely on large encoders (up to 10.7B parameters), making them computationally expensive and inaccessible to researchers with limited resources. To address this issue, we investigate whether the knowledge stored in these large encoders can be compressed while maintaining quality. We employ distillation, quantization, and pruning techniques to create efficient xCOMET alternatives and introduce a novel data collection pipeline for efficient black-box distillation. Our experiments show that, using quantization, xCOMET can be compressed up to three times with no quality degradation. Additionally, through distillation, we create an xCOMET-lite metric, which has only 2.6% of xCOMET-XXL parameters, but retains 92.1% of its quality. Besides, it surpasses strong small-scale metrics like COMET-22 and BLEURT-20 on the WMT22 metrics challenge dataset by 6.4%, despite using 50% fewer parameters. All code, dataset, and models are available online.
SmurfCat at SemEval-2024 Task 6: Leveraging Synthetic Data for Hallucination Detection
Apr 09, 2024In this paper, we present our novel systems developed for the SemEval-2024 hallucination detection task. Our investigation spans a range of strategies to compare model predictions with reference standards, encompassing diverse baselines, the refinement of pre-trained encoders through supervised learning, and an ensemble approaches utilizing several high-performing models. Through these explorations, we introduce three distinct methods that exhibit strong performance metrics. To amplify our training data, we generate additional training samples from unlabelled training subset. Furthermore, we provide a detailed comparative analysis of our approaches. Notably, our premier method achieved a commendable 9th place in the competition's model-agnostic track and 17th place in model-aware track, highlighting its effectiveness and potential.
MultiParaDetox: Extending Text Detoxification with Parallel Data to New Languages
Apr 02, 2024



Text detoxification is a textual style transfer (TST) task where a text is paraphrased from a toxic surface form, e.g. featuring rude words, to the neutral register. Recently, text detoxification methods found their applications in various task such as detoxification of Large Language Models (LLMs) (Leong et al., 2023; He et al., 2024; Tang et al., 2023) and toxic speech combating in social networks (Deng et al., 2023; Mun et al., 2023; Agarwal et al., 2023). All these applications are extremely important to ensure safe communication in modern digital worlds. However, the previous approaches for parallel text detoxification corpora collection -- ParaDetox (Logacheva et al., 2022) and APPADIA (Atwell et al., 2022) -- were explored only in monolingual setup. In this work, we aim to extend ParaDetox pipeline to multiple languages presenting MultiParaDetox to automate parallel detoxification corpus collection for potentially any language. Then, we experiment with different text detoxification models -- from unsupervised baselines to LLMs and fine-tuned models on the presented parallel corpora -- showing the great benefit of parallel corpus presence to obtain state-of-the-art text detoxification models for any language.
TaxoLLaMA: WordNet-based Model for Solving Multiple Lexical Sematic Tasks
Mar 14, 2024In this paper, we explore the capabilities of LLMs in capturing lexical-semantic knowledge from WordNet on the example of the LLaMA-2-7b model and test it on multiple lexical semantic tasks. As the outcome of our experiments, we present TaxoLLaMA, the everything-in-one model, lightweight due to 4-bit quantization and LoRA. It achieves 11 SotA results, 4 top-2 results out of 16 tasks for the Taxonomy Enrichment, Hypernym Discovery, Taxonomy Construction, and Lexical Entailment tasks. Moreover, it demonstrates very strong zero-shot performance on Lexical Entailment and Taxonomy Construction with no fine-tuning. We also explore its hidden multilingual and domain adaptation capabilities with a little tuning or few-shot learning. All datasets, code, and model are available online at https://github.com/VityaVitalich/TaxoLLaMA