 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 9: Detecting Multilingual, Multicultural and Multievent Online Polarization
Apr 08, 2026We present SemEval-2026 Task 9, a shared task on online polarization detection, covering 22 languages and comprising over 110K annotated instances. Each data instance is multi-labeled with the presence of polarization, polarization type, and polarization manifestation. Participants were asked to predict labels in three sub-tasks: (1) detecting the presence of polarization, (2) identifying the type of polarization, and (3) recognizing the polarization manifestation. The three tasks attracted over 1,000 participants worldwide and more than 10k submission on Codabench. We received final submissions from 67 teams and 73 system description papers. We report the baseline results and analyze the performance of the best-performing systems, highlighting the most common approaches and the most effective methods across different subtasks and languages. The dataset of this task is publicly available.
Comprehensive Comparison of RAG Methods Across Multi-Domain Conversational QA
Feb 10, 2026Conversational question answering increasingly relies on retrieval-augmented generation (RAG) to ground large language models (LLMs) in external knowledge. Yet, most existing studies evaluate RAG methods in isolation and primarily focus on single-turn settings. This paper addresses the lack of a systematic comparison of RAG methods for multi-turn conversational QA, where dialogue history, coreference, and shifting user intent substantially complicate retrieval. We present a comprehensive empirical study of vanilla and advanced RAG methods across eight diverse conversational QA datasets spanning multiple domains. Using a unified experimental setup, we evaluate retrieval quality and answer generation using generator and retrieval metrics, and analyze how performance evolves across conversation turns. Our results show that robust yet straightforward methods, such as reranking, hybrid BM25, and HyDE, consistently outperform vanilla RAG. In contrast, several advanced techniques fail to yield gains and can even degrade performance below the No-RAG baseline. We further demonstrate that dataset characteristics and dialogue length strongly influence retrieval effectiveness, explaining why no single RAG strategy dominates across settings. Overall, our findings indicate that effective conversational RAG depends less on method complexity than on alignment between the retrieval strategy and the dataset structure. We publish the code used.\footnote{\href{https://github.com/Klejda-A/exp-rag.git}{GitHub Repository}}
LEMUR: A Corpus for Robust Fine-Tuning of Multilingual Law Embedding Models for Retrieval
Feb 10, 2026Large language models (LLMs) are increasingly used to access legal information. Yet, their deployment in multilingual legal settings is constrained by unreliable retrieval and the lack of domain-adapted, open-embedding models. In particular, existing multilingual legal corpora are not designed for semantic retrieval, and PDF-based legislative sources introduce substantial noise due to imperfect text extraction. To address these challenges, we introduce LEMUR, a large-scale multilingual corpus of EU environmental legislation constructed from 24,953 official EUR-Lex PDF documents covering 25 languages. We quantify the fidelity of PDF-to-text conversion by measuring lexical consistency against authoritative HTML versions using the Lexical Content Score (LCS). Building on LEMUR, we fine-tune three state-of-the-art multilingual embedding models using contrastive objectives in both monolingual and bilingual settings, reflecting realistic legal-retrieval scenarios. Experiments across low- and high-resource languages demonstrate that legal-domain fine-tuning consistently improves Top-k retrieval accuracy relative to strong baselines, with particularly pronounced gains for low-resource languages. Cross-lingual evaluations show that these improvements transfer to unseen languages, indicating that fine-tuning primarily enhances language-independent, content-level legal representations rather than language-specific cues. We publish code\footnote{\href{https://github.com/nargesbh/eur_lex}{GitHub Repository}} and data\footnote{\href{https://huggingface.co/datasets/G4KMU/LEMUR}{Hugging Face Dataset}}.
FASCIST-O-METER: Classifier for Neo-fascist Discourse Online
Jun 12, 2025Neo-fascism is a political and societal ideology that has been having remarkable growth in the last decade in the United States of America (USA), as well as in other Western societies. It poses a grave danger to democracy and the minorities it targets, and it requires active actions against it to avoid escalation. This work presents the first-of-its-kind neo-fascist coding scheme for digital discourse in the USA societal context, overseen by political science researchers. Our work bridges the gap between Natural Language Processing (NLP) and political science against this phenomena. Furthermore, to test the coding scheme, we collect a tremendous amount of activity on the internet from notable neo-fascist groups (the forums of Iron March and Stormfront.org), and the guidelines are applied to a subset of the collected posts. Through crowdsourcing, we annotate a total of a thousand posts that are labeled as neo-fascist or non-neo-fascist. With this labeled data set, we fine-tune and test both Small Language Models (SLMs) and Large Language Models (LLMs), obtaining the very first classification models for neo-fascist discourse. We find that the prevalence of neo-fascist rhetoric in this kind of forum is ever-present, making them a good target for future research. The societal context is a key consideration for neo-fascist speech when conducting NLP research. Finally, the work against this kind of political movement must be pressed upon and continued for the well-being of a democratic society. Disclaimer: This study focuses on detecting neo-fascist content in text, similar to other hate speech analyses, without labeling individuals or organizations.
POLAR: A Benchmark for Multilingual, Multicultural, and Multi-Event Online Polarization
May 27, 2025Online polarization poses a growing challenge for democratic discourse, yet most computational social science research remains monolingual, culturally narrow, or event-specific. We introduce POLAR, a multilingual, multicultural, and multievent dataset with over 23k instances in seven languages from diverse online platforms and real-world events. Polarization is annotated along three axes: presence, type, and manifestation, using a variety of annotation platforms adapted to each cultural context. We conduct two main experiments: (1) we fine-tune six multilingual pretrained language models in both monolingual and cross-lingual setups; and (2) we evaluate a range of open and closed large language models (LLMs) in few-shot and zero-shot scenarios. Results show that while most models perform well on binary polarization detection, they achieve substantially lower scores when predicting polarization types and manifestations. These findings highlight the complex, highly contextual nature of polarization and the need for robust, adaptable approaches in NLP and computational social science. All resources will be released to support further research and effective mitigation of digital polarization globally.
CollEX -- A Multimodal Agentic RAG System Enabling Interactive Exploration of Scientific Collections
Apr 10, 2025In this paper, we introduce CollEx, an innovative multimodal agentic Retrieval-Augmented Generation (RAG) system designed to enhance interactive exploration of extensive scientific collections. Given the overwhelming volume and inherent complexity of scientific collections, conventional search systems often lack necessary intuitiveness and interactivity, presenting substantial barriers for learners, educators, and researchers. CollEx addresses these limitations by employing state-of-the-art Large Vision-Language Models (LVLMs) as multimodal agents accessible through an intuitive chat interface. By abstracting complex interactions via specialized agents equipped with advanced tools, CollEx facilitates curiosity-driven exploration, significantly simplifying access to diverse scientific collections and records therein. Our system integrates textual and visual modalities, supporting educational scenarios that are helpful for teachers, pupils, students, and researchers by fostering independent exploration as well as scientific excitement and curiosity. Furthermore, CollEx serves the research community by discovering interdisciplinary connections and complementing visual data. We illustrate the effectiveness of our system through a proof-of-concept application containing over 64,000 unique records across 32 collections from a local scientific collection from a public university.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
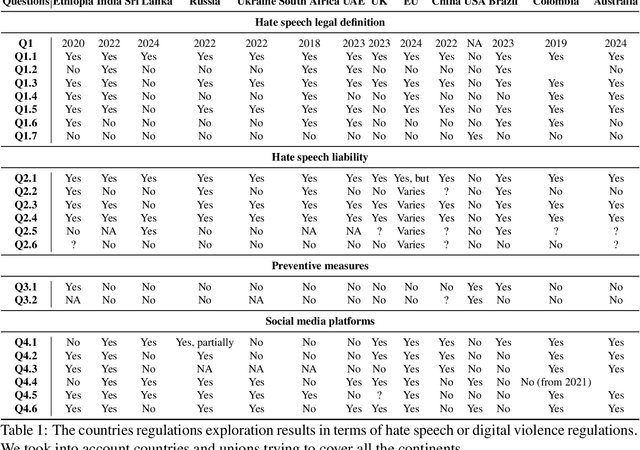
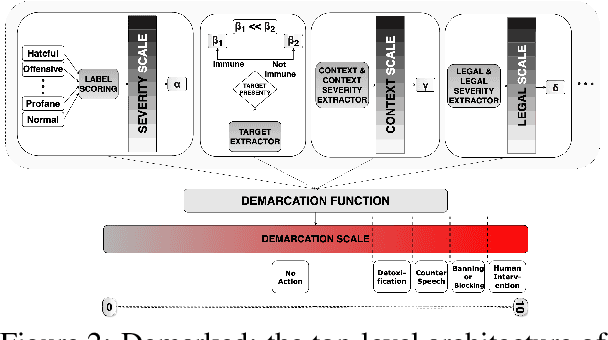

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.