 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Self-Consistency with Ranking
Jun 03, 2026Self-consistency improves large language models by sampling multiple reasoning paths and selecting the most frequent answer, but majority voting often fails to recover correct answers that are already present among the samples. We address this limitation with Ranking-Improved Self-Consistency (RISC), which reformulates answer selection in self-consistency as a ranking problem. Instead of relying on a single uncertainty or confidence signal, RISC uses a lightweight LambdaRank model to score candidate answers with five carefully designed features that capture answer frequency, semantic centrality, and reasoning-trace consistency. We evaluate RISC on three datasets under a range of test-time budgets. Across datasets, RISC consistently achieves a better accuracy-efficiency trade-off than standard self-consistency and strong baselines, with particularly large gains on question answering benchmarks. Further analysis shows that the proposed features are individually useful and, more importantly, complementary, highlighting the value of learning to combine multiple informative signals for test-time answer selection.
Leveraging LLM Parametric Knowledge for Fact Checking without Retrieval
Mar 05, 2026Trustworthiness is a core research challenge for agentic AI systems built on Large Language Models (LLMs). To enhance trust, natural language claims from diverse sources, including human-written text, web content, and model outputs, are commonly checked for factuality by retrieving external knowledge and using an LLM to verify the faithfulness of claims to the retrieved evidence. As a result, such methods are constrained by retrieval errors and external data availability, while leaving the models intrinsic fact-verification capabilities largely unused. We propose the task of fact-checking without retrieval, focusing on the verification of arbitrary natural language claims, independent of their source. To study this setting, we introduce a comprehensive evaluation framework focused on generalization, testing robustness to (i) long-tail knowledge, (ii) variation in claim sources, (iii) multilinguality, and (iv) long-form generation. Across 9 datasets, 18 methods and 3 models, our experiments indicate that logit-based approaches often underperform compared to those that leverage internal model representations. Building on this finding, we introduce INTRA, a method that exploits interactions between internal representations and achieves state-of-the-art performance with strong generalization. More broadly, our work establishes fact-checking without retrieval as a promising research direction that can complement retrieval-based frameworks, improve scalability, and enable the use of such systems as reward signals during training or as components integrated into the generation process.
<think> So let's replace this phrase with insult... </think> Lessons learned from generation of toxic texts with LLMs
Sep 10, 2025



Modern Large Language Models (LLMs) are excellent at generating synthetic data. However, their performance in sensitive domains such as text detoxification has not received proper attention from the scientific community. This paper explores the possibility of using LLM-generated synthetic toxic data as an alternative to human-generated data for training models for detoxification. Using Llama 3 and Qwen activation-patched models, we generated synthetic toxic counterparts for neutral texts from ParaDetox and SST-2 datasets. Our experiments show that models fine-tuned on synthetic data consistently perform worse than those trained on human data, with a drop in performance of up to 30% in joint metrics. The root cause is identified as a critical lexical diversity gap: LLMs generate toxic content using a small, repetitive vocabulary of insults that fails to capture the nuances and variety of human toxicity. These findings highlight the limitations of current LLMs in this domain and emphasize the continued importance of diverse, human-annotated data for building robust detoxification systems.
Generalized Fisher-Weighted SVD: Scalable Kronecker-Factored Fisher Approximation for Compressing Large Language Models
May 23, 2025



The Fisher information is a fundamental concept for characterizing the sensitivity of parameters in neural networks. However, leveraging the full observed Fisher information is too expensive for large models, so most methods rely on simple diagonal approximations. While efficient, this approach ignores parameter correlations, often resulting in reduced performance on downstream tasks. In this work, we mitigate these limitations and propose Generalized Fisher-Weighted SVD (GFWSVD), a post-training LLM compression technique that accounts for both diagonal and off-diagonal elements of the Fisher information matrix, providing a more accurate reflection of parameter importance. To make the method tractable, we introduce a scalable adaptation of the Kronecker-factored approximation algorithm for the observed Fisher information. We demonstrate the effectiveness of our method on LLM compression, showing improvements over existing compression baselines. For example, at a 20 compression rate on the MMLU benchmark, our method outperforms FWSVD, which is based on a diagonal approximation of the Fisher information, by 5 percent, SVD-LLM by 3 percent, and ASVD by 6 percent compression rate.
How Much Knowledge Can You Pack into a LoRA Adapter without Harming LLM?
Feb 20, 2025



The performance of Large Language Models (LLMs) on many tasks is greatly limited by the knowledge learned during pre-training and stored in the model's parameters. Low-rank adaptation (LoRA) is a popular and efficient training technique for updating or domain-specific adaptation of LLMs. In this study, we investigate how new facts can be incorporated into the LLM using LoRA without compromising the previously learned knowledge. We fine-tuned Llama-3.1-8B-instruct using LoRA with varying amounts of new knowledge. Our experiments have shown that the best results are obtained when the training data contains a mixture of known and new facts. However, this approach is still potentially harmful because the model's performance on external question-answering benchmarks declines after such fine-tuning. When the training data is biased towards certain entities, the model tends to regress to few overrepresented answers. In addition, we found that the model becomes more confident and refuses to provide an answer in only few cases. These findings highlight the potential pitfalls of LoRA-based LLM updates and underscore the importance of training data composition and tuning parameters to balance new knowledge integration and general model capabilities.
SynthDetoxM: Modern LLMs are Few-Shot Parallel Detoxification Data Annotators
Feb 10, 2025



Existing approaches to multilingual text detoxification are hampered by the scarcity of parallel multilingual datasets. In this work, we introduce a pipeline for the generation of multilingual parallel detoxification data. We also introduce SynthDetoxM, a manually collected and synthetically generated multilingual parallel text detoxification dataset comprising 16,000 high-quality detoxification sentence pairs across German, French, Spanish and Russian. The data was sourced from different toxicity evaluation datasets and then rewritten with nine modern open-source LLMs in few-shot setting. Our experiments demonstrate that models trained on the produced synthetic datasets have superior performance to those trained on the human-annotated MultiParaDetox dataset even in data limited setting. Models trained on SynthDetoxM outperform all evaluated LLMs in few-shot setting. We release our dataset and code to help further research in multilingual text detoxification.
Multilingual and Explainable Text Detoxification with Parallel Corpora
Dec 16, 2024Even with various regulations in place across countries and social media platforms (Government of India, 2021; European Parliament and Council of the European Union, 2022, digital abusive speech remains a significant issue. One potential approach to address this challenge is automatic text detoxification, a text style transfer (TST) approach that transforms toxic language into a more neutral or non-toxic form. To date, the availability of parallel corpora for the text detoxification task (Logachevavet al., 2022; Atwell et al., 2022; Dementievavet al., 2024a) has proven to be crucial for state-of-the-art approaches. With this work, we extend parallel text detoxification corpus to new languages -- German, Chinese, Arabic, Hindi, and Amharic -- testing in the extensive multilingual setup TST baselines. Next, we conduct the first of its kind an automated, explainable analysis of the descriptive features of both toxic and non-toxic sentences, diving deeply into the nuances, similarities, and differences of toxicity and detoxification across 9 languages. Finally, based on the obtained insights, we experiment with a novel text detoxification method inspired by the Chain-of-Thoughts reasoning approach, enhancing the prompting process through clustering on relevant descriptive attributes.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
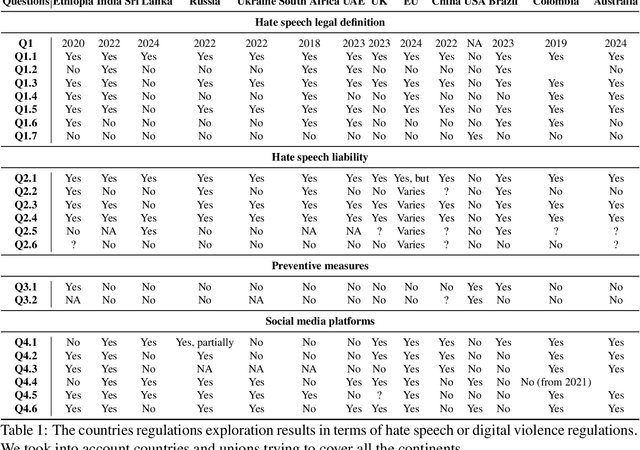
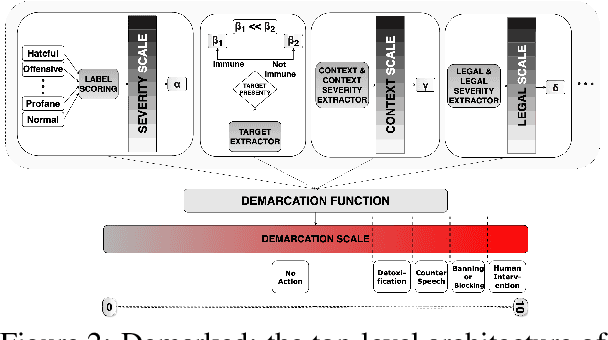

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
MERA: A Comprehensive LLM Evaluation in Russian
Jan 12, 2024



Over the past few years, one of the most notable advancements in AI research has been in foundation models (FMs), headlined by the rise of language models (LMs). As the models' size increases, LMs demonstrate enhancements in measurable aspects and the development of new qualitative features. However, despite researchers' attention and the rapid growth in LM application, the capabilities, limitations, and associated risks still need to be better understood. To address these issues, we introduce an open Multimodal Evaluation of Russian-language Architectures (MERA), a new instruction benchmark for evaluating foundation models oriented towards the Russian language. The benchmark encompasses 21 evaluation tasks for generative models in 11 skill domains and is designed as a black-box test to ensure the exclusion of data leakage. The paper introduces a methodology to evaluate FMs and LMs in zero- and few-shot fixed instruction settings that can be extended to other modalities. We propose an evaluation methodology, an open-source code base for the MERA assessment, and a leaderboard with a submission system. We evaluate open LMs as baselines and find that they are still far behind the human level. We publicly release MERA to guide forthcoming research, anticipate groundbreaking model features, standardize the evaluation procedure, and address potential societal drawbacks.
Exploring Methods for Cross-lingual Text Style Transfer: The Case of Text Detoxification
Nov 23, 2023



Text detoxification is the task of transferring the style of text from toxic to neutral. While here are approaches yielding promising results in monolingual setup, e.g., (Dale et al., 2021; Hallinan et al., 2022), cross-lingual transfer for this task remains a challenging open problem (Moskovskiy et al., 2022). In this work, we present a large-scale study of strategies for cross-lingual text detoxification -- given a parallel detoxification corpus for one language; the goal is to transfer detoxification ability to another language for which we do not have such a corpus. Moreover, we are the first to explore a new task where text translation and detoxification are performed simultaneously, providing several strong baselines for this task. Finally, we introduce new automatic detoxification evaluation metrics with higher correlations with human judgments than previous benchmarks. We assess the most promising approaches also with manual markup, determining the answer for the best strategy to transfer the knowledge of text detoxification between languages.