 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Deep Latent Variable Models of Natural Language
Dec 18, 2018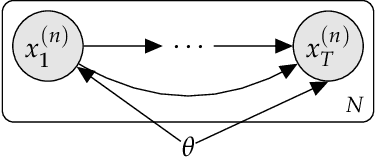

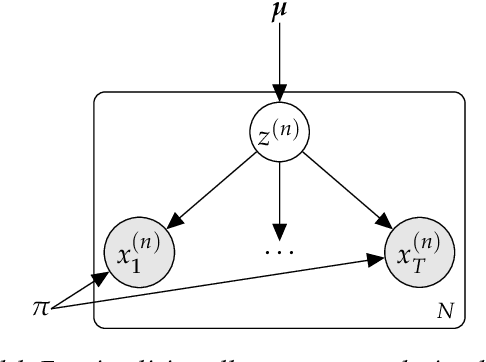
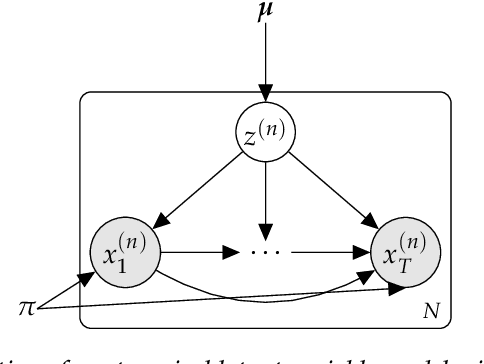
There has been much recent, exciting work on combining the complementary strengths of latent variable models and deep learning. Latent variable modeling makes it easy to explicitly specify model constraints through conditional independence properties, while deep learning makes it possible to parameterize these conditional likelihoods with powerful function approximators. While these "deep latent variable" models provide a rich, flexible framework for modeling many real-world phenomena, difficulties exist: deep parameterizations of conditional likelihoods usually make posterior inference intractable, and latent variable objectives often complicate backpropagation by introducing points of non-differentiability. This tutorial explores these issues in depth through the lens of variational inference.
Seq2Seq-Vis: A Visual Debugging Tool for Sequence-to-Sequence Models
Oct 16, 2018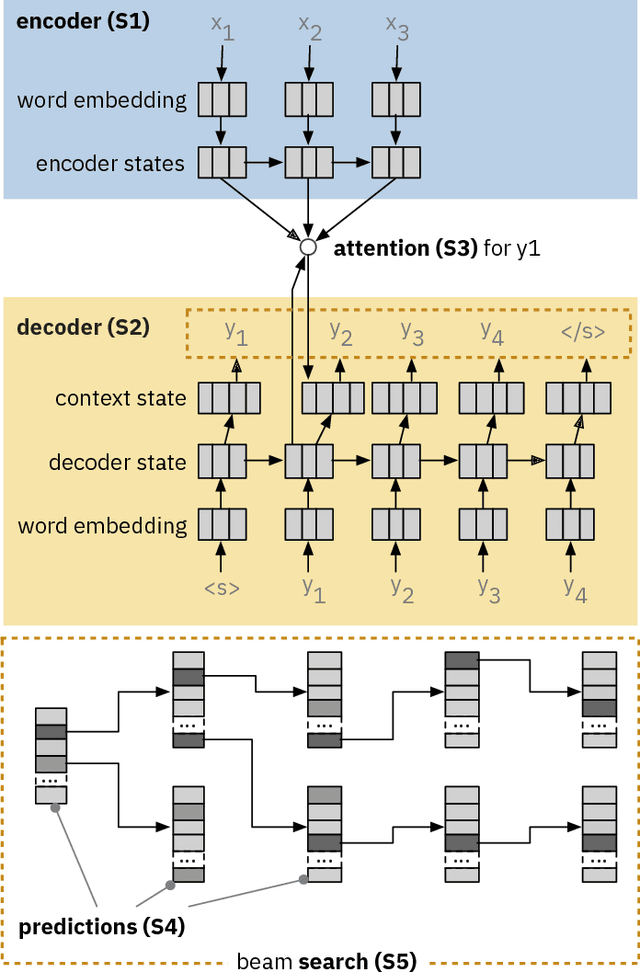
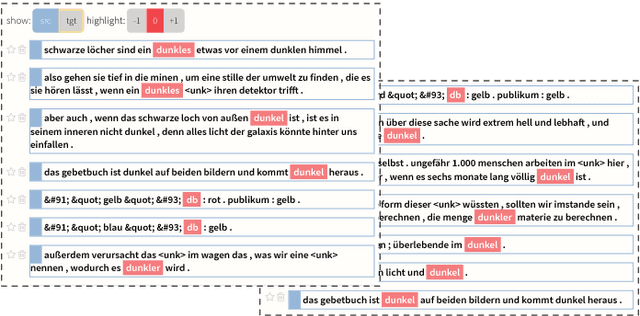
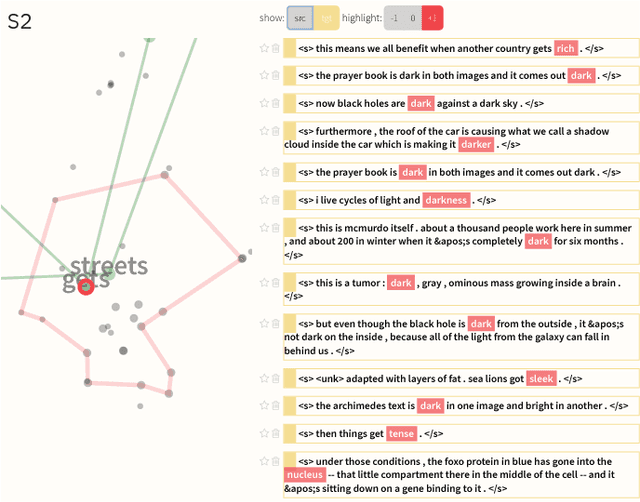
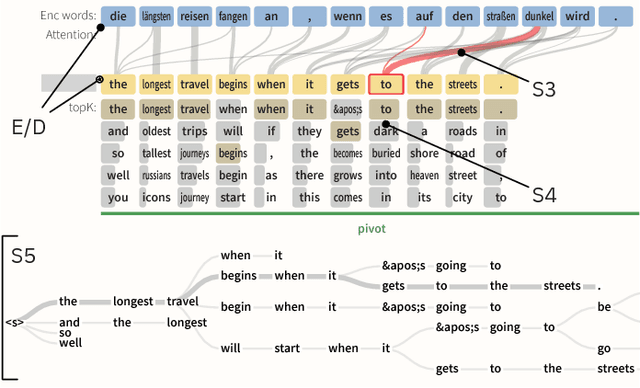
Neural Sequence-to-Sequence models have proven to be accurate and robust for many sequence prediction tasks, and have become the standard approach for automatic translation of text. The models work in a five stage blackbox process that involves encoding a source sequence to a vector space and then decoding out to a new target sequence. This process is now standard, but like many deep learning methods remains quite difficult to understand or debug. In this work, we present a visual analysis tool that allows interaction with a trained sequence-to-sequence model through each stage of the translation process. The aim is to identify which patterns have been learned and to detect model errors. We demonstrate the utility of our tool through several real-world large-scale sequence-to-sequence use cases.
End-to-End Content and Plan Selection for Data-to-Text Generation
Oct 10, 2018
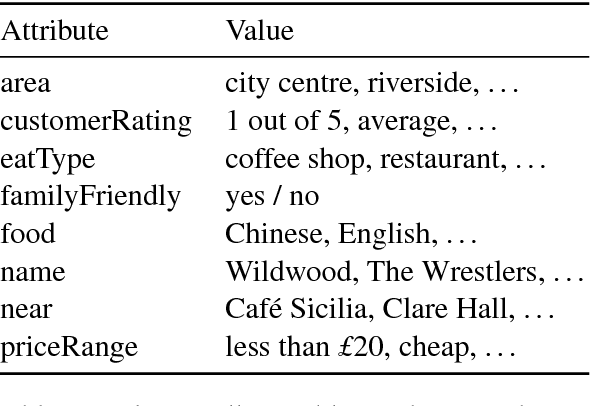
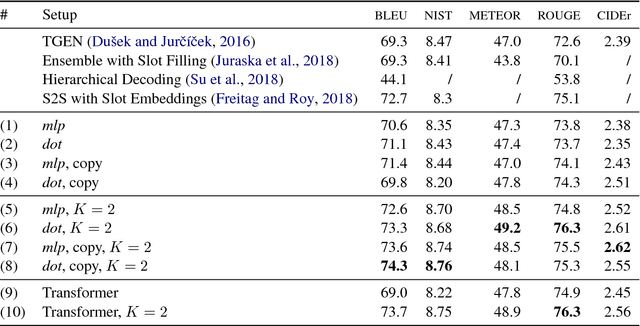
Learning to generate fluent natural language from structured data with neural networks has become an common approach for NLG. This problem can be challenging when the form of the structured data varies between examples. This paper presents a survey of several extensions to sequence-to-sequence models to account for the latent content selection process, particularly variants of copy attention and coverage decoding. We further propose a training method based on diverse ensembling to encourage models to learn distinct sentence templates during training. An empirical evaluation of these techniques shows an increase in the quality of generated text across five automated metrics, as well as human evaluation.
Bottom-Up Abstractive Summarization
Oct 09, 2018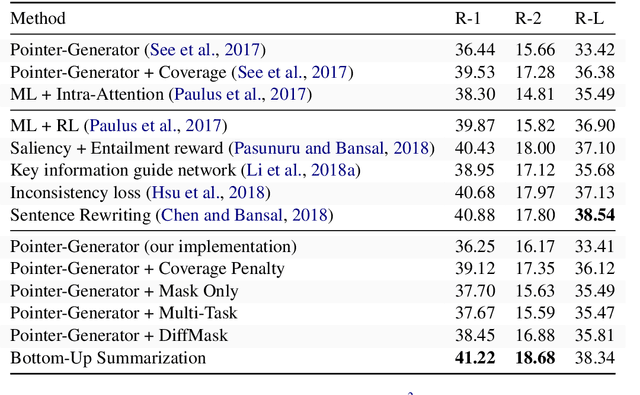
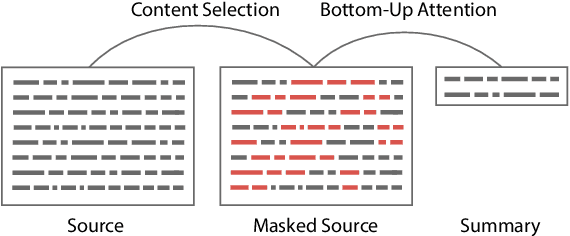
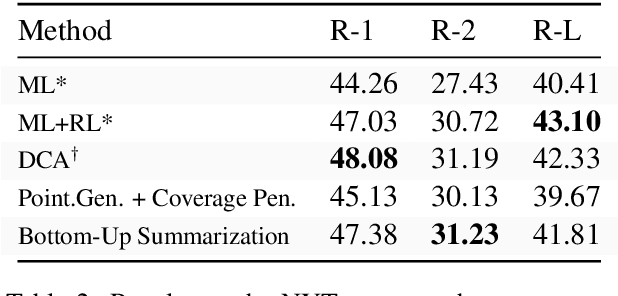
Neural network-based methods for abstractive summarization produce outputs that are more fluent than other techniques, but which can be poor at content selection. This work proposes a simple technique for addressing this issue: use a data-efficient content selector to over-determine phrases in a source document that should be part of the summary. We use this selector as a bottom-up attention step to constrain the model to likely phrases. We show that this approach improves the ability to compress text, while still generating fluent summaries. This two-step process is both simpler and higher performing than other end-to-end content selection models, leading to significant improvements on ROUGE for both the CNN-DM and NYT corpus. Furthermore, the content selector can be trained with as little as 1,000 sentences, making it easy to transfer a trained summarizer to a new domain.
Learning Neural Templates for Text Generation
Sep 13, 2018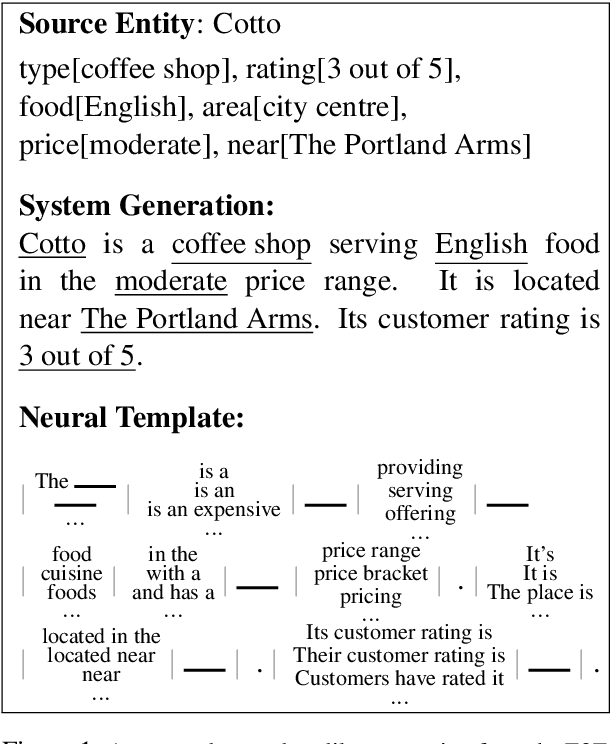
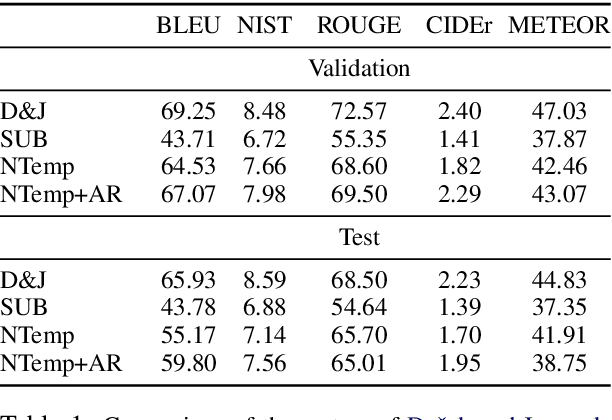
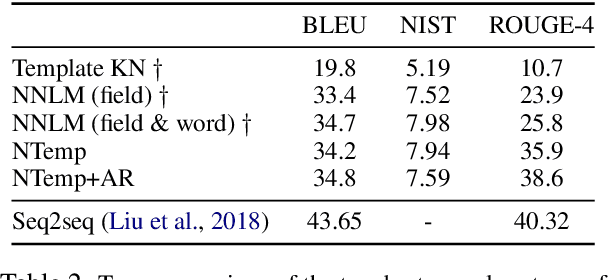
While neural, encoder-decoder models have had significant empirical success in text generation, there remain several unaddressed problems with this style of generation. Encoder-decoder models are largely (a) uninterpretable, and (b) difficult to control in terms of their phrasing or content. This work proposes a neural generation system using a hidden semi-markov model (HSMM) decoder, which learns latent, discrete templates jointly with learning to generate. We show that this model learns useful templates, and that these templates make generation both more interpretable and controllable. Furthermore, we show that this approach scales to real data sets and achieves strong performance nearing that of encoder-decoder text generation models.
Semi-Amortized Variational Autoencoders
Jul 23, 2018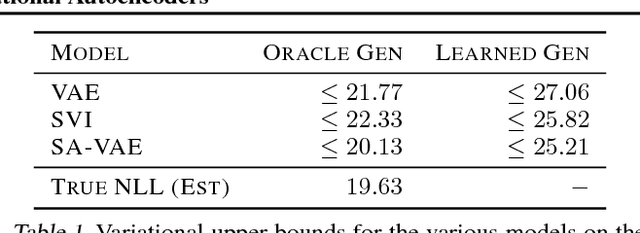
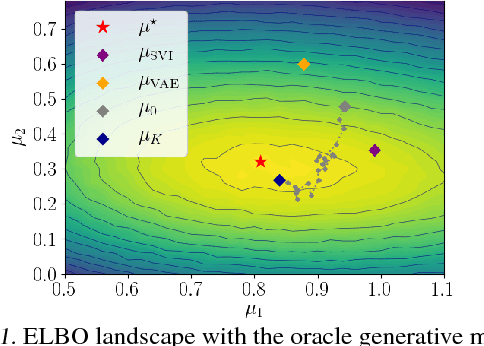
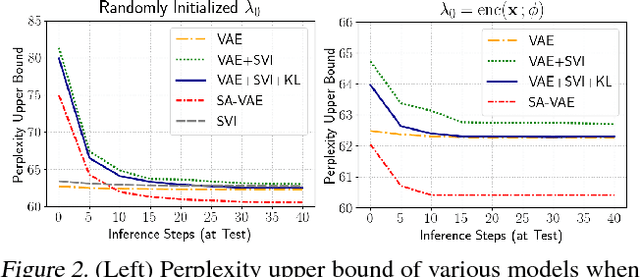
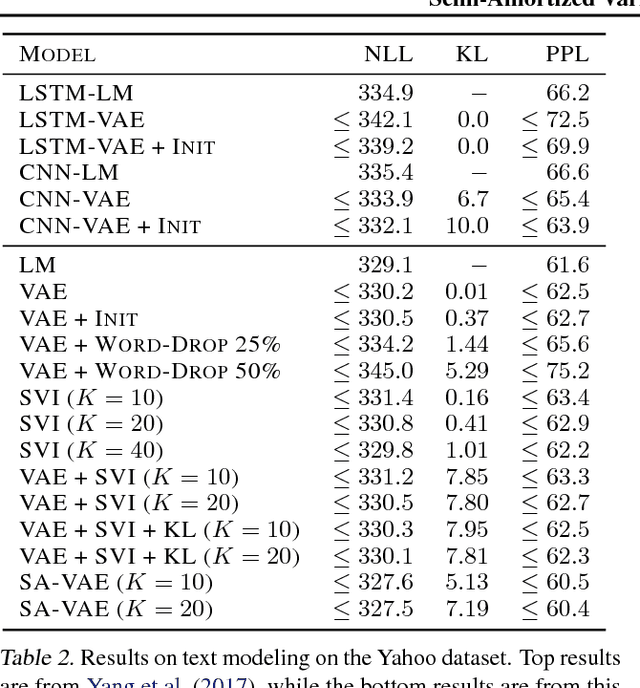
Amortized variational inference (AVI) replaces instance-specific local inference with a global inference network. While AVI has enabled efficient training of deep generative models such as variational autoencoders (VAE), recent empirical work suggests that inference networks can produce suboptimal variational parameters. We propose a hybrid approach, to use AVI to initialize the variational parameters and run stochastic variational inference (SVI) to refine them. Crucially, the local SVI procedure is itself differentiable, so the inference network and generative model can be trained end-to-end with gradient-based optimization. This semi-amortized approach enables the use of rich generative models without experiencing the posterior-collapse phenomenon common in training VAEs for problems like text generation. Experiments show this approach outperforms strong autoregressive and variational baselines on standard text and image datasets.
Avoiding Latent Variable Collapse With Generative Skip Models
Jul 12, 2018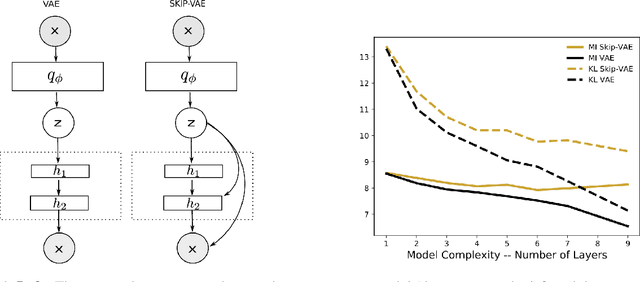
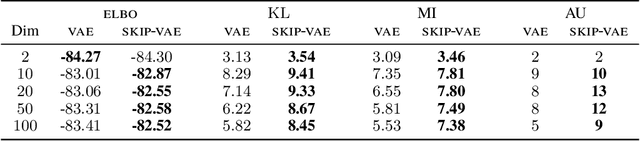

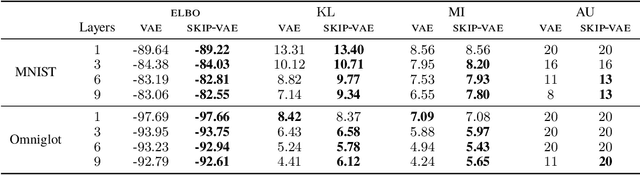
Variational autoencoders (VAEs) learn distributions of high-dimensional data. They model data by introducing a deep latent-variable model and then maximizing a lower bound of the log marginal likelihood. While VAEs can capture complex distributions, they also suffer from an issue known as "latent variable collapse." Specifically, the lower bound involves an approximate posterior of the latent variables; this posterior "collapses" when it is set equal to the prior, i.e., when the posterior is independent of the data. While VAEs learn good generative models, latent variable collapse prevents them from learning useful representations. In this paper, we propose a new way to avoid latent variable collapse. We expand the model class to one that includes skip connections; these connections enforce strong links between the latent variables and the likelihood function. We study these generative skip models both theoretically and empirically. Theoretically, we prove that skip models increase the mutual information between the observations and the inferred latent variables. Empirically, on both images (MNIST and Omniglot) and text (Yahoo), we show that generative skip models lead to less collapse than existing VAE architectures.
Latent Alignment and Variational Attention
Jul 10, 2018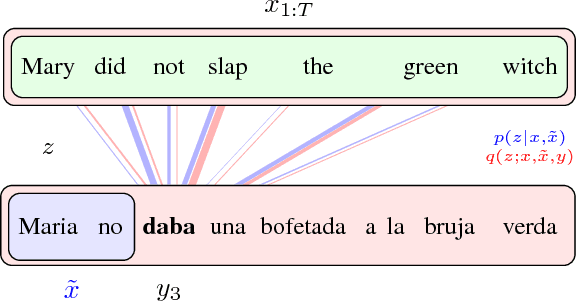
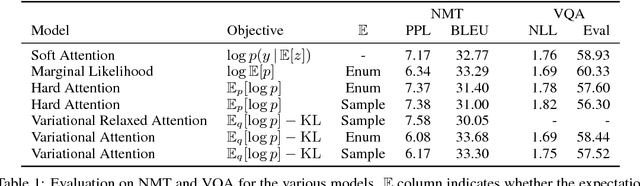
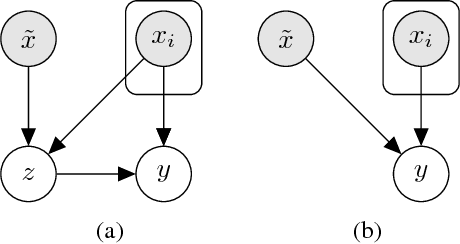
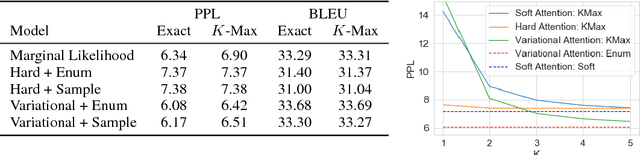
Neural attention has become central to many state-of-the-art models in natural language processing and related domains. Attention networks are an easy-to-train and effective method for softly simulating alignment; however, the approach does not marginalize over latent alignments in a probabilistic sense. This property makes it difficult to compare attention to other alignment approaches, to compose it with probabilistic models, and to perform posterior inference conditioned on observed data. A related latent approach, hard attention, fixes these issues, but is generally harder to train and less accurate. This work considers variational attention networks, alternatives to soft and hard attention for learning latent variable alignment models, with tighter approximation bounds based on amortized variational inference. We further propose methods for reducing the variance of gradients to make these approaches computationally feasible. Experiments show that for machine translation and visual question answering, inefficient exact latent variable models outperform standard neural attention, but these gains go away when using hard attention based training. On the other hand, variational attention retains most of the performance gain but with training speed comparable to neural attention.
Adversarially Regularized Autoencoders
Jun 29, 2018
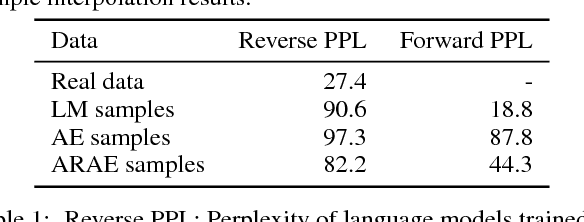


Deep latent variable models, trained using variational autoencoders or generative adversarial networks, are now a key technique for representation learning of continuous structures. However, applying similar methods to discrete structures, such as text sequences or discretized images, has proven to be more challenging. In this work, we propose a flexible method for training deep latent variable models of discrete structures. Our approach is based on the recently-proposed Wasserstein autoencoder (WAE) which formalizes the adversarial autoencoder (AAE) as an optimal transport problem. We first extend this framework to model discrete sequences, and then further explore different learned priors targeting a controllable representation. This adversarially regularized autoencoder (ARAE) allows us to generate natural textual outputs as well as perform manipulations in the latent space to induce change in the output space. Finally we show that the latent representation can be trained to perform unaligned textual style transfer, giving improvements both in automatic/human evaluation compared to existing methods.
OpenNMT: Neural Machine Translation Toolkit
May 28, 2018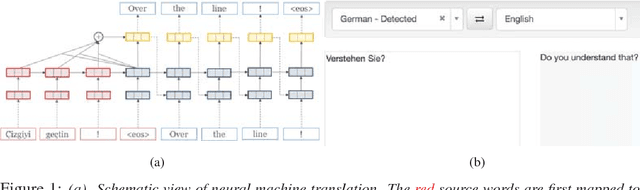

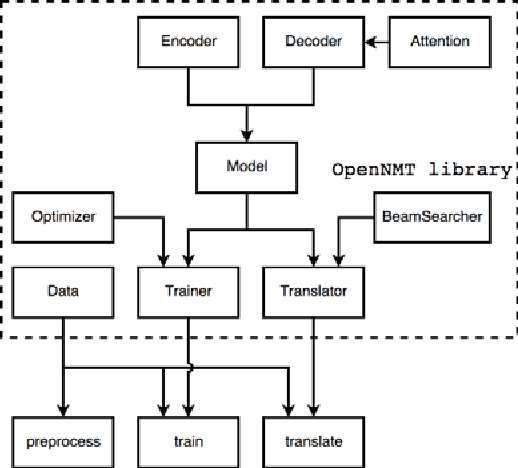

OpenNMT is an open-source toolkit for neural machine translation (NMT). The system prioritizes efficiency, modularity, and extensibility with the goal of supporting NMT research into model architectures, feature representations, and source modalities, while maintaining competitive performance and reasonable training requirements. The toolkit consists of modeling and translation support, as well as detailed pedagogical documentation about the underlying techniques. OpenNMT has been used in several production MT systems, modified for numerous research papers, and is implemented across several deep learning frameworks.