 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Linguistic Steganography
Sep 03, 2019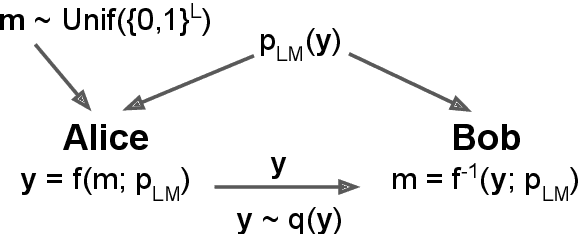

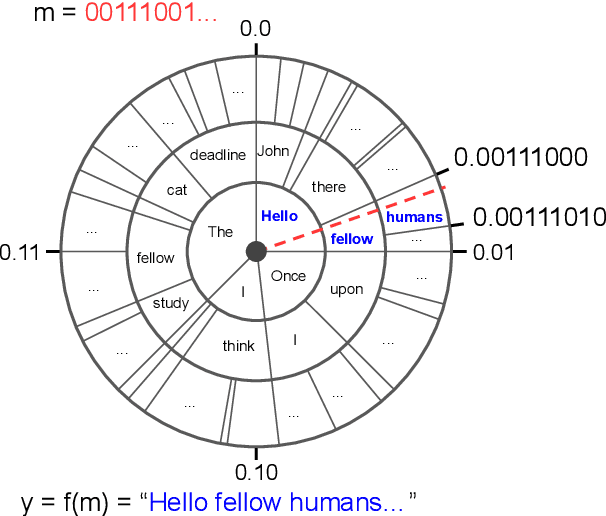

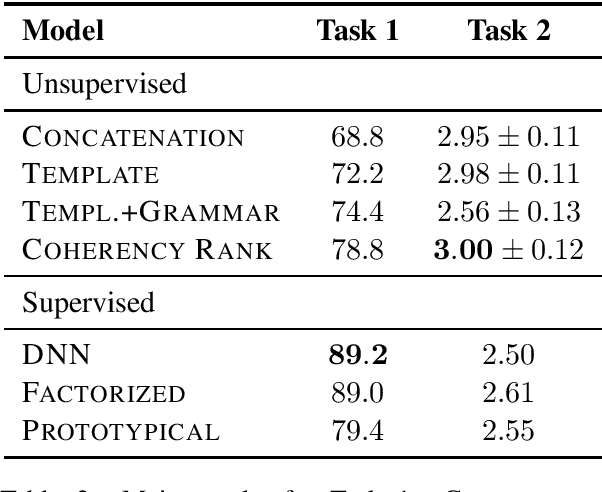
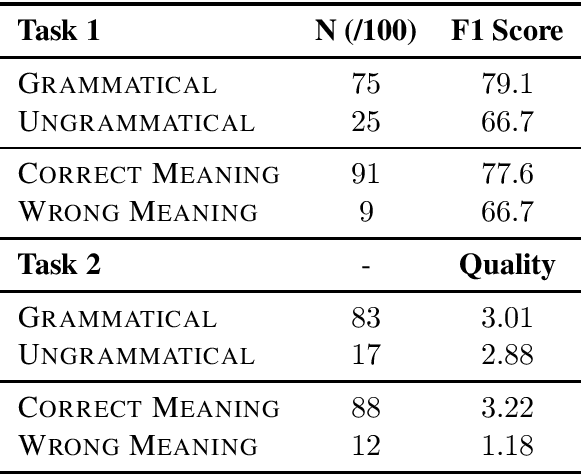
Whereas traditional cryptography encrypts a secret message into an unintelligible form, steganography conceals that communication is taking place by encoding a secret message into a cover signal. Language is a particularly pragmatic cover signal due to its benign occurrence and independence from any one medium. Traditionally, linguistic steganography systems encode secret messages in existing text via synonym substitution or word order rearrangements. Advances in neural language models enable previously impractical generation-based techniques. We propose a steganography technique based on arithmetic coding with large-scale neural language models. We find that our approach can generate realistic looking cover sentences as evaluated by humans, while at the same time preserving security by matching the cover message distribution with the language model distribution.
Commonsense Knowledge Mining from Pretrained Models
Sep 02, 2019
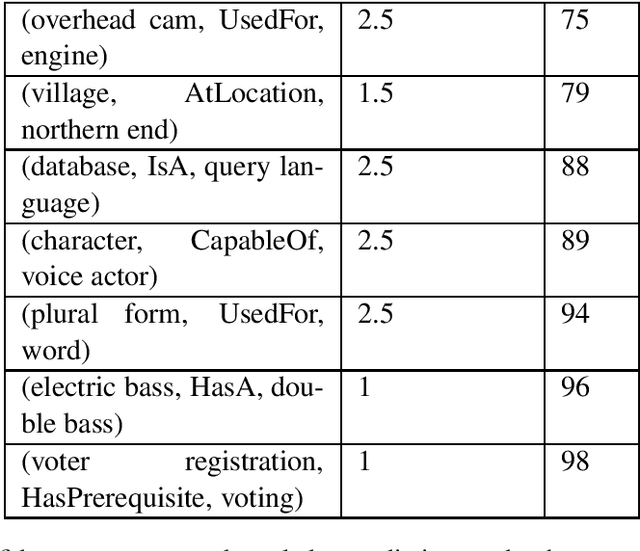
Inferring commonsense knowledge is a key challenge in natural language processing, but due to the sparsity of training data, previous work has shown that supervised methods for commonsense knowledge mining underperform when evaluated on novel data. In this work, we develop a method for generating commonsense knowledge using a large, pre-trained bidirectional language model. By transforming relational triples into masked sentences, we can use this model to rank a triple's validity by the estimated pointwise mutual information between the two entities. Since we do not update the weights of the bidirectional model, our approach is not biased by the coverage of any one commonsense knowledge base. Though this method performs worse on a test set than models explicitly trained on a corresponding training set, it outperforms these methods when mining commonsense knowledge from new sources, suggesting that unsupervised techniques may generalize better than current supervised approaches.
Compound Probabilistic Context-Free Grammars for Grammar Induction
Aug 18, 2019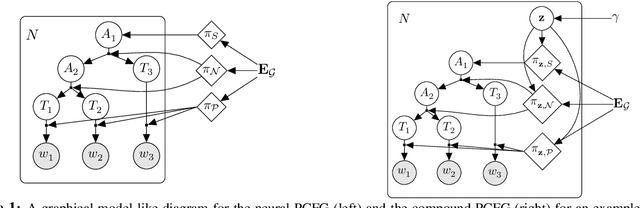
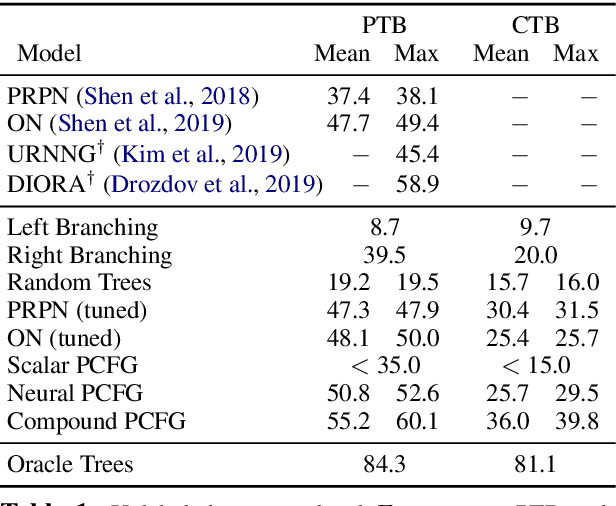
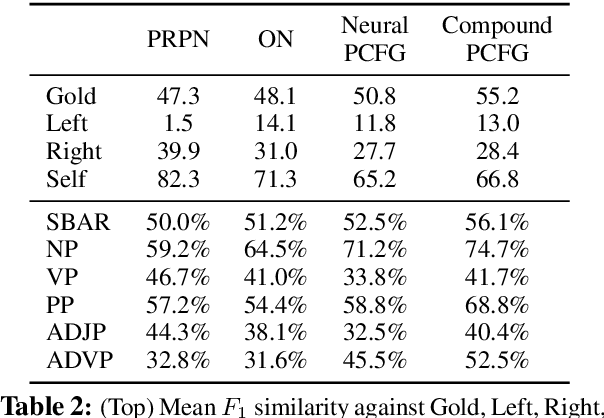

We study a formalization of the grammar induction problem that models sentences as being generated by a compound probabilistic context-free grammar. In contrast to traditional formulations which learn a single stochastic grammar, our context-free rule probabilities are modulated by a per-sentence continuous latent variable, which induces marginal dependencies beyond the traditional context-free assumptions. Inference in this grammar is performed by collapsed variational inference, in which an amortized variational posterior is placed on the continuous variable, and the latent trees are marginalized with dynamic programming. Experiments on English and Chinese show the effectiveness of our approach compared to recent state-of-the-art methods for grammar induction.
Simple Unsupervised Summarization by Contextual Matching
Jul 31, 2019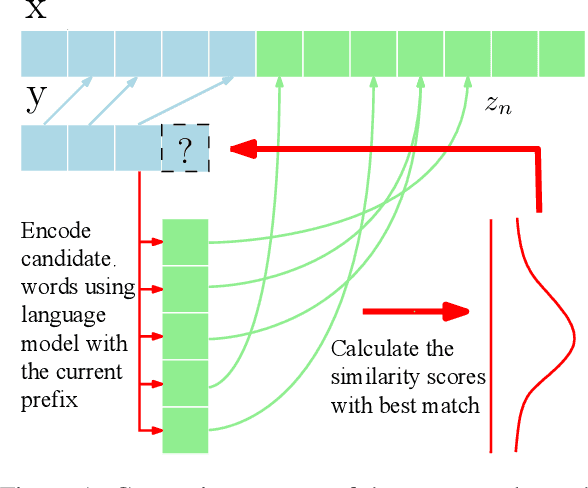
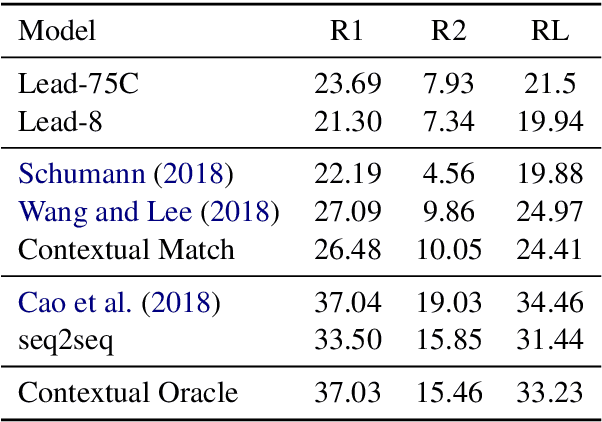
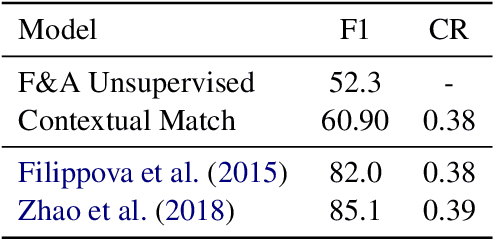
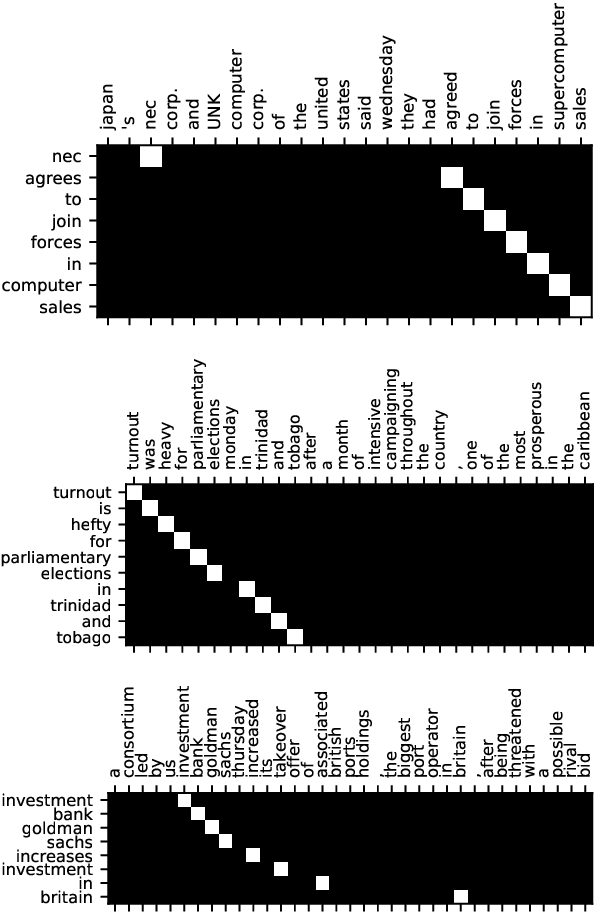
We propose an unsupervised method for sentence summarization using only language modeling. The approach employs two language models, one that is generic (i.e. pretrained), and the other that is specific to the target domain. We show that by using a product-of-experts criteria these are enough for maintaining continuous contextual matching while maintaining output fluency. Experiments on both abstractive and extractive sentence summarization data sets show promising results of our method without being exposed to any paired data.
Visual Interaction with Deep Learning Models through Collaborative Semantic Inference
Jul 24, 2019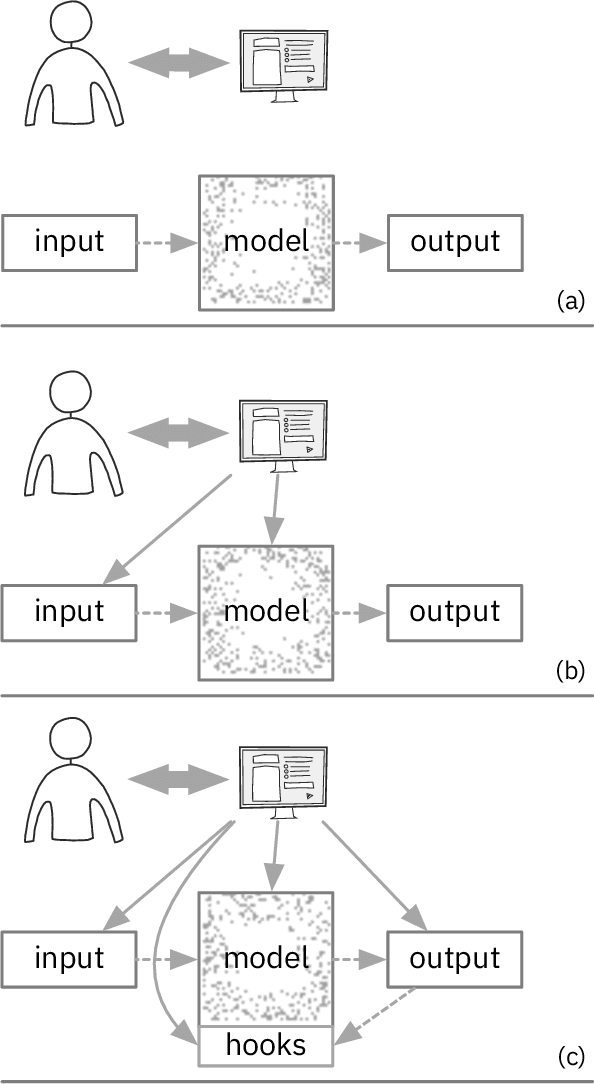
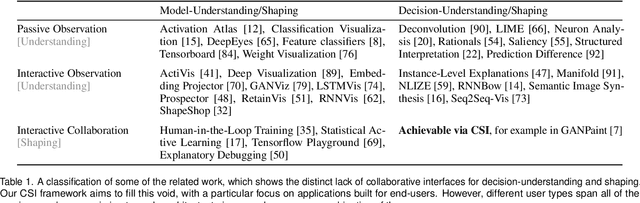

Automation of tasks can have critical consequences when humans lose agency over decision processes. Deep learning models are particularly susceptible since current black-box approaches lack explainable reasoning. We argue that both the visual interface and model structure of deep learning systems need to take into account interaction design. We propose a framework of collaborative semantic inference (CSI) for the co-design of interactions and models to enable visual collaboration between humans and algorithms. The approach exposes the intermediate reasoning process of models which allows semantic interactions with the visual metaphors of a problem, which means that a user can both understand and control parts of the model reasoning process. We demonstrate the feasibility of CSI with a co-designed case study of a document summarization system.
On Adversarial Removal of Hypothesis-only Bias in Natural Language Inference
Jul 09, 2019
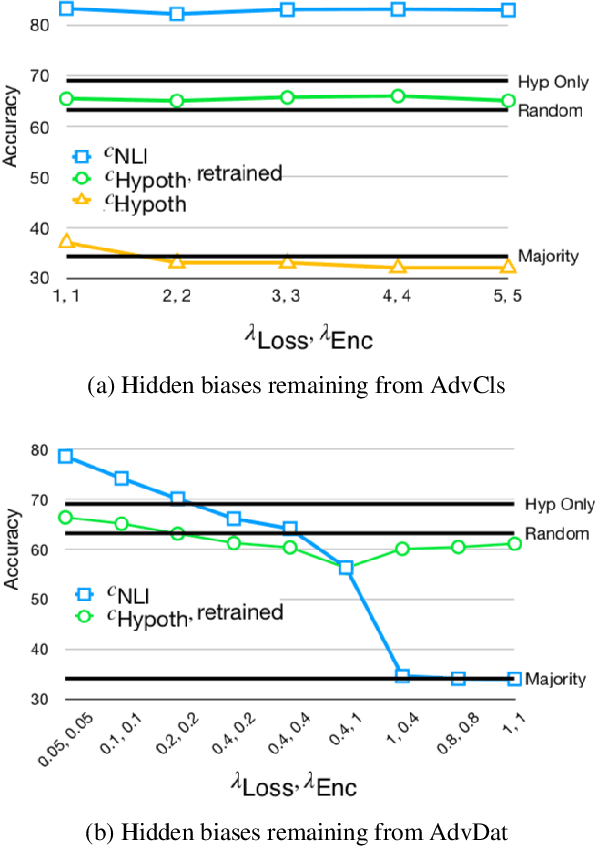
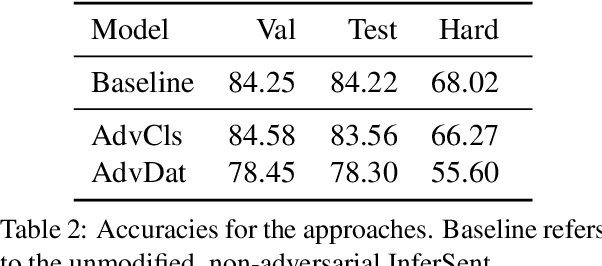
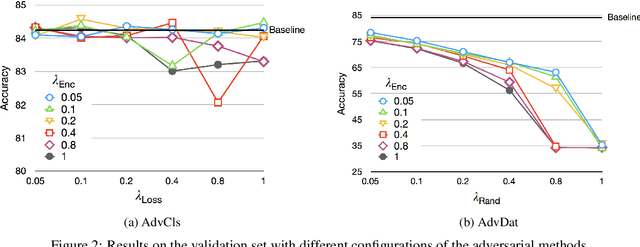
Popular Natural Language Inference (NLI) datasets have been shown to be tainted by hypothesis-only biases. Adversarial learning may help models ignore sensitive biases and spurious correlations in data. We evaluate whether adversarial learning can be used in NLI to encourage models to learn representations free of hypothesis-only biases. Our analyses indicate that the representations learned via adversarial learning may be less biased, with only small drops in NLI accuracy.
Don't Take the Premise for Granted: Mitigating Artifacts in Natural Language Inference
Jul 09, 2019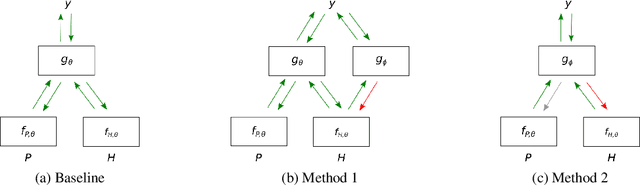

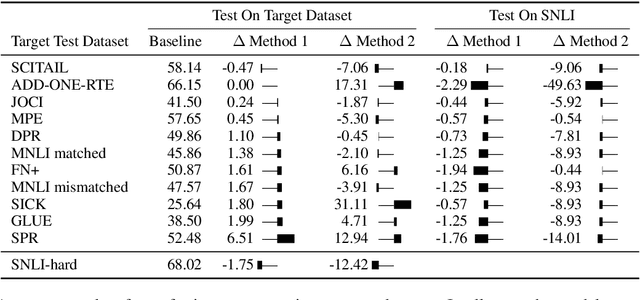
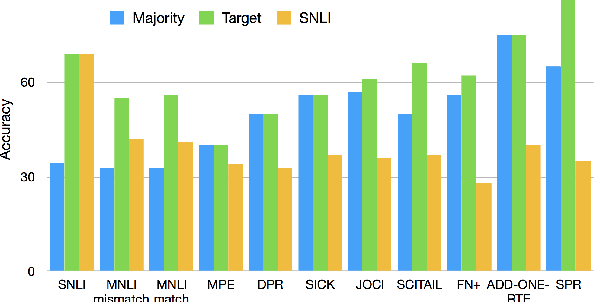
Natural Language Inference (NLI) datasets often contain hypothesis-only biases---artifacts that allow models to achieve non-trivial performance without learning whether a premise entails a hypothesis. We propose two probabilistic methods to build models that are more robust to such biases and better transfer across datasets. In contrast to standard approaches to NLI, our methods predict the probability of a premise given a hypothesis and NLI label, discouraging models from ignoring the premise. We evaluate our methods on synthetic and existing NLI datasets by training on datasets containing biases and testing on datasets containing no (or different) hypothesis-only biases. Our results indicate that these methods can make NLI models more robust to dataset-specific artifacts, transferring better than a baseline architecture in 9 out of 12 NLI datasets. Additionally, we provide an extensive analysis of the interplay of our methods with known biases in NLI datasets, as well as the effects of encouraging models to ignore biases and fine-tuning on target datasets.
GLTR: Statistical Detection and Visualization of Generated Text
Jun 10, 2019

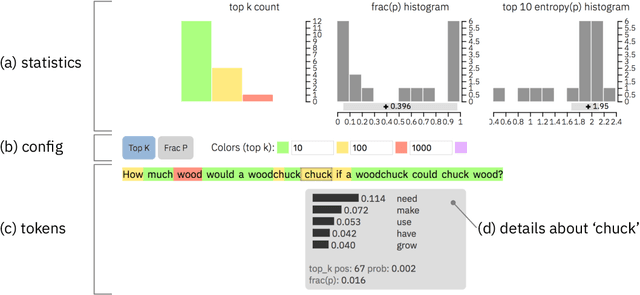

The rapid improvement of language models has raised the specter of abuse of text generation systems. This progress motivates the development of simple methods for detecting generated text that can be used by and explained to non-experts. We develop GLTR, a tool to support humans in detecting whether a text was generated by a model. GLTR applies a suite of baseline statistical methods that can detect generation artifacts across common sampling schemes. In a human-subjects study, we show that the annotation scheme provided by GLTR improves the human detection-rate of fake text from 54% to 72% without any prior training. GLTR is open-source and publicly deployed, and has already been widely used to detect generated outputs
Unsupervised Recurrent Neural Network Grammars
Apr 15, 2019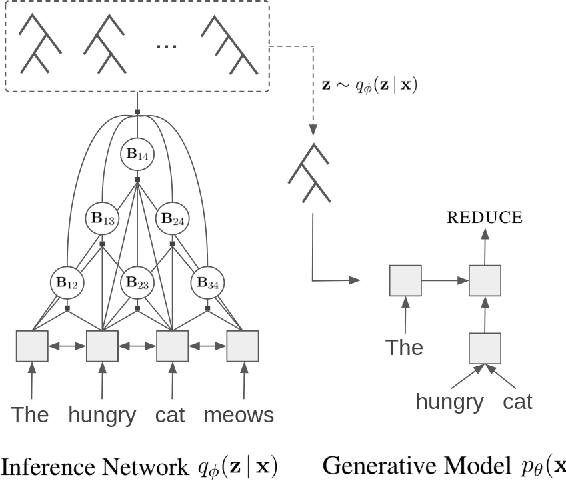
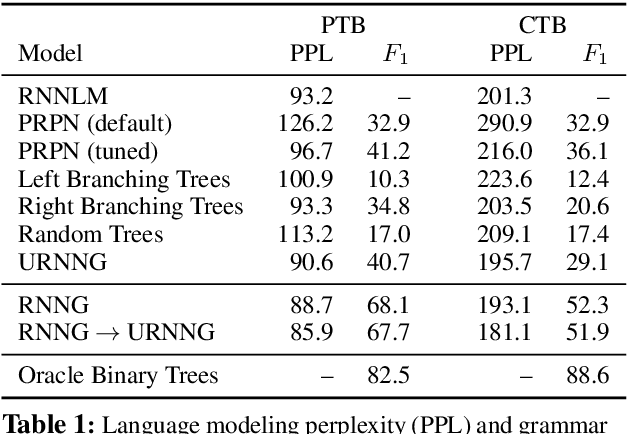
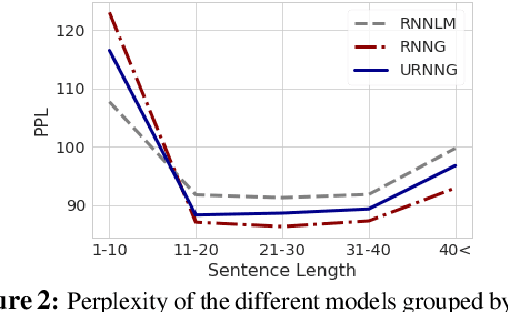
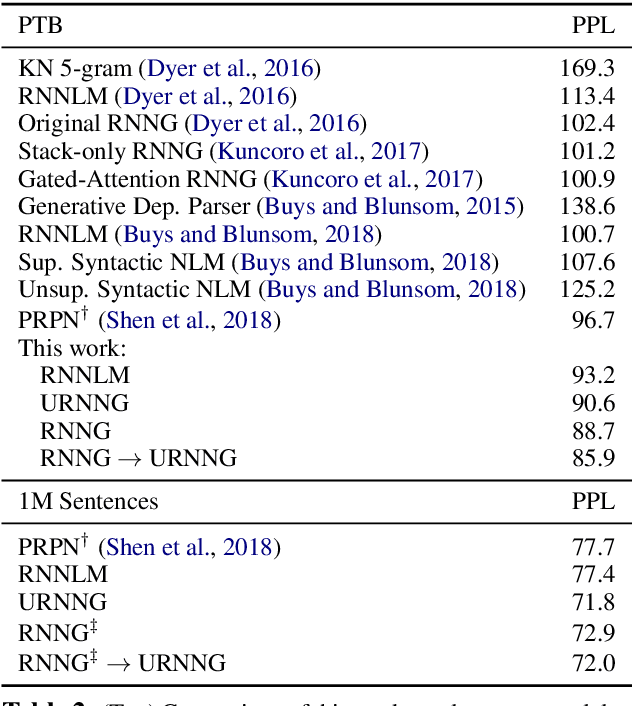
Recurrent neural network grammars (RNNG) are generative models of language which jointly model syntax and surface structure by incrementally generating a syntax tree and sentence in a top-down, left-to-right order. Supervised RNNGs achieve strong language modeling and parsing performance, but require an annotated corpus of parse trees. In this work, we experiment with unsupervised learning of RNNGs. Since directly marginalizing over the space of latent trees is intractable, we instead apply amortized variational inference. To maximize the evidence lower bound, we develop an inference network parameterized as a neural CRF constituency parser. On language modeling, unsupervised RNNGs perform as well their supervised counterparts on benchmarks in English and Chinese. On constituency grammar induction, they are competitive with recent neural language models that induce tree structures from words through attention mechanisms.
Latent Normalizing Flows for Discrete Sequences
Jan 29, 2019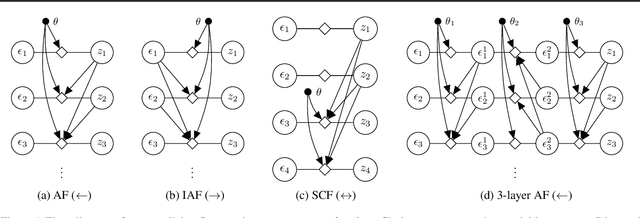
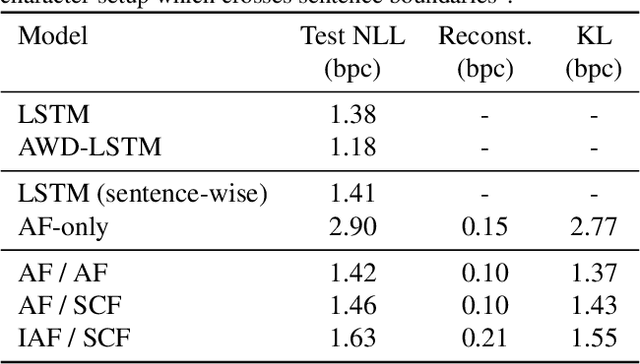
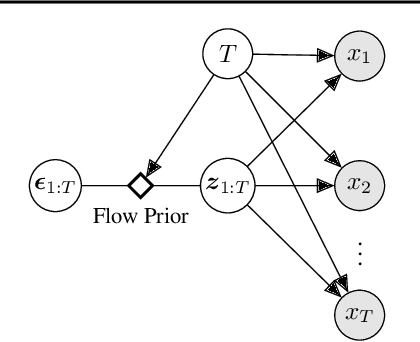
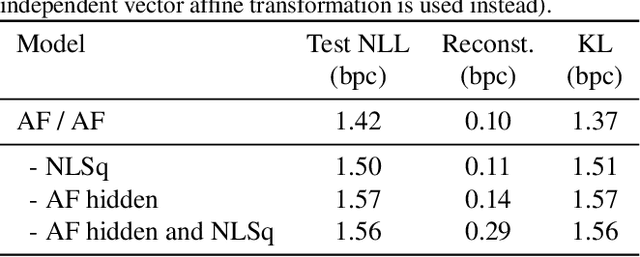
Normalizing flows have been shown to be a powerful class of generative models for continuous random variables, giving both strong performance and the potential for non-autoregressive generation. These benefits are also desired when modeling discrete random variables such as text, but directly applying normalizing flows to discrete sequences poses significant additional challenges. We propose a generative model which jointly learns a normalizing flow-based distribution in the latent space and a stochastic mapping to an observed discrete space. In this setting, we find that it is crucial for the flow-based distribution to be highly multimodal. To capture this property, we propose several normalizing flow architectures to maximize model flexibility. Experiments consider common discrete sequence tasks of character-level language modeling and polyphonic music generation. Our results indicate that an autoregressive flow-based model can match the performance of a comparable autoregressive baseline, and a non-autoregressive flow-based model can improve generation speed with a penalty to performance.