 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoder-Agnostic Adaptation for Conditional Language Generation
Sep 11, 2019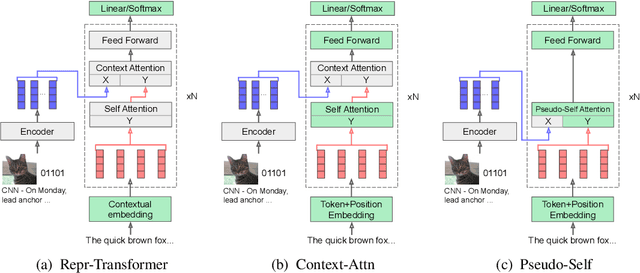
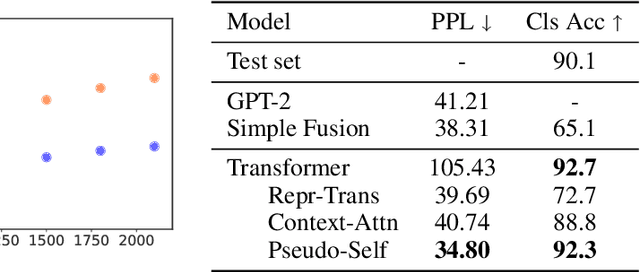
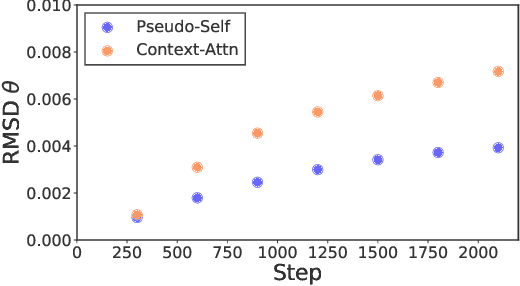
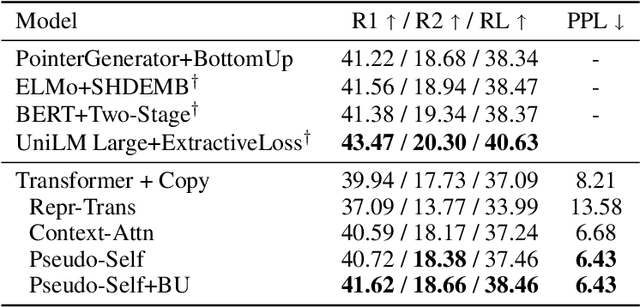
Large pretrained language models have changed the way researchers approach discriminative natural language understanding tasks, leading to the dominance of approaches that adapt a pretrained model for arbitrary downstream tasks. However it is an open-question how to use similar techniques for language generation. Early results in the encoder-agnostic setting have been mostly negative. In this work we explore methods for adapting a pretrained language model to arbitrary conditional input. We observe that pretrained transformer models are sensitive to large parameter changes during tuning. We therefore propose an adaptation that directly injects arbitrary conditioning into self attention, an approach we call pseudo self attention. Through experiments on four diverse conditional text generation tasks we show that this encoder-agnostic technique outperforms strong baselines, produces coherent generations, and is data efficient.
Neural Linguistic Steganography
Sep 03, 2019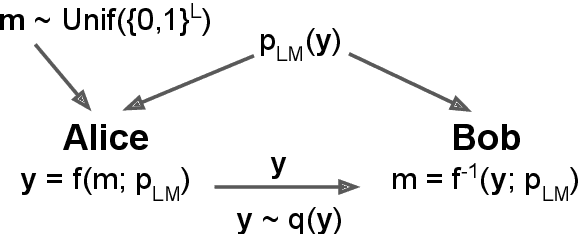

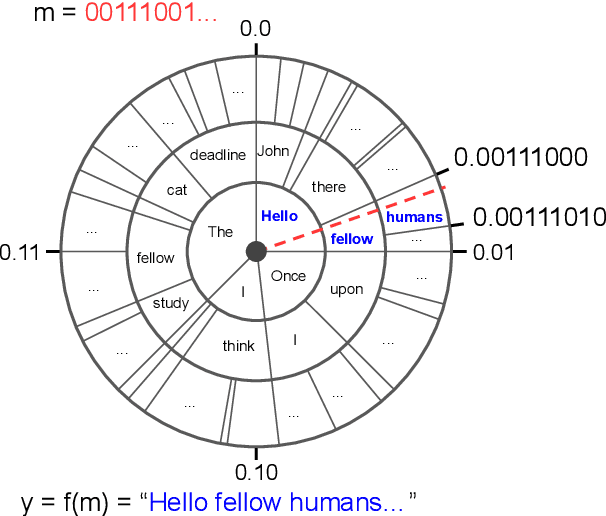

Whereas traditional cryptography encrypts a secret message into an unintelligible form, steganography conceals that communication is taking place by encoding a secret message into a cover signal. Language is a particularly pragmatic cover signal due to its benign occurrence and independence from any one medium. Traditionally, linguistic steganography systems encode secret messages in existing text via synonym substitution or word order rearrangements. Advances in neural language models enable previously impractical generation-based techniques. We propose a steganography technique based on arithmetic coding with large-scale neural language models. We find that our approach can generate realistic looking cover sentences as evaluated by humans, while at the same time preserving security by matching the cover message distribution with the language model distribution.
Latent Normalizing Flows for Discrete Sequences
Jan 29, 2019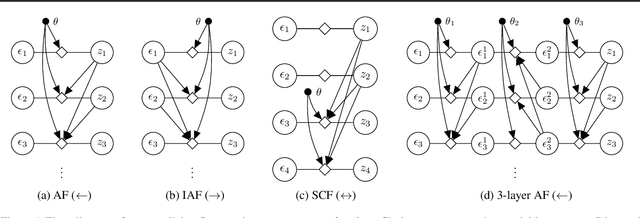
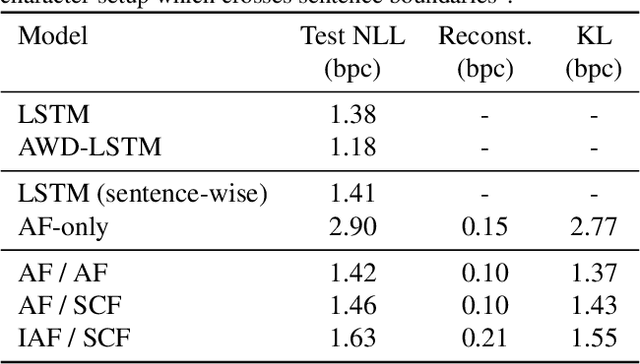
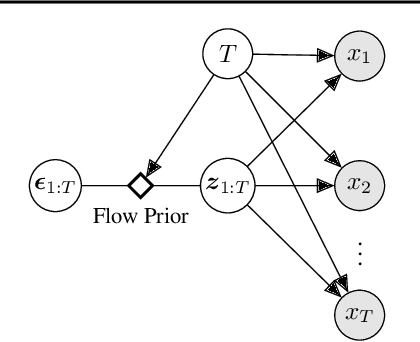
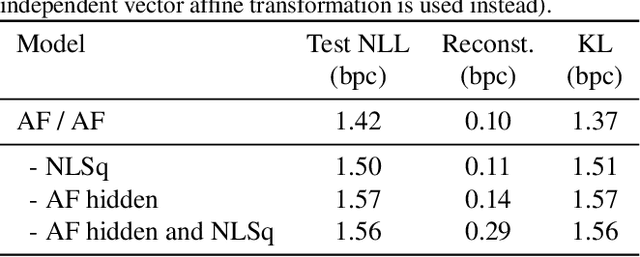
Normalizing flows have been shown to be a powerful class of generative models for continuous random variables, giving both strong performance and the potential for non-autoregressive generation. These benefits are also desired when modeling discrete random variables such as text, but directly applying normalizing flows to discrete sequences poses significant additional challenges. We propose a generative model which jointly learns a normalizing flow-based distribution in the latent space and a stochastic mapping to an observed discrete space. In this setting, we find that it is crucial for the flow-based distribution to be highly multimodal. To capture this property, we propose several normalizing flow architectures to maximize model flexibility. Experiments consider common discrete sequence tasks of character-level language modeling and polyphonic music generation. Our results indicate that an autoregressive flow-based model can match the performance of a comparable autoregressive baseline, and a non-autoregressive flow-based model can improve generation speed with a penalty to performance.