 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Map Transform Coding for Energy-Efficient CNN Inference
May 26, 2019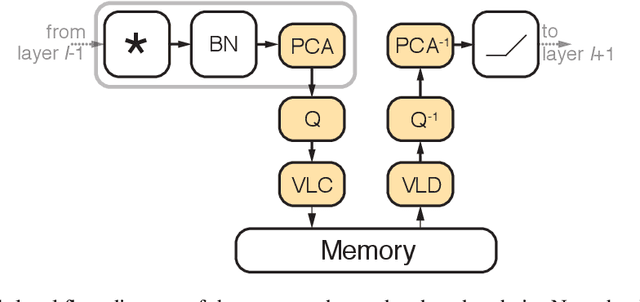
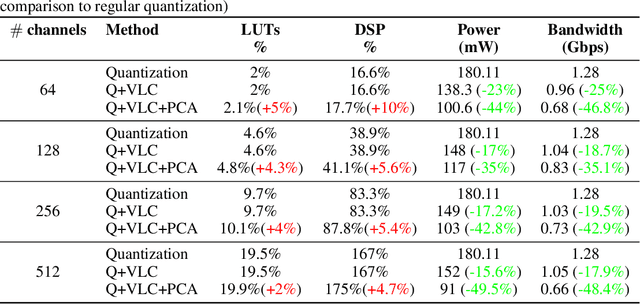
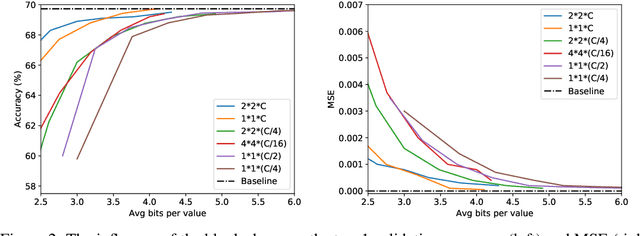
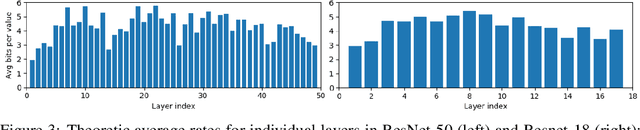
Convolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their relatively high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method exploits the high correlations between feature maps and adjacent pixels and allows to halve the data transfer volumes to the main memory without re-training. We analyze the performance of our approach on a variety of CNN architectures and demonstrated FPGA implementation of ResNet18 with our approach results in reduction of around 40% in the memory energy footprint compared to quantized network with negligible impact on accuracy. A reference implementation is available at https://github.com/CompressTeam/TransformCodingInference
Towards Learning of Filter-Level Heterogeneous Compression of Convolutional Neural Networks
Apr 29, 2019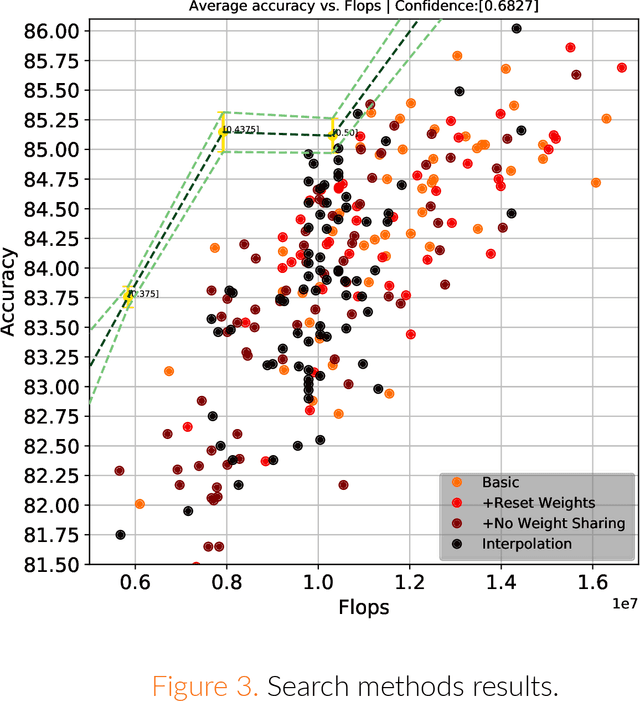
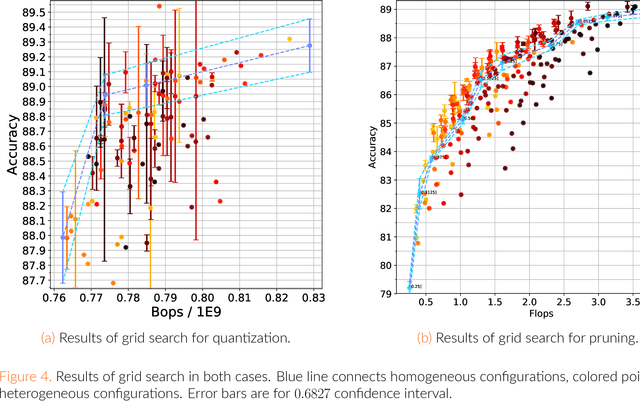
Recently, deep learning has become a de facto standard in machine learning with convolutional neural networks (CNNs) demonstrating spectacular success on a wide variety of tasks. However, CNNs are typically very demanding computationally at inference time. One of the ways to alleviate this burden on certain hardware platforms is quantization relying on the use of low-precision arithmetic representation for the weights and the activations. Another popular method is the pruning of the number of filters in each layer. While mainstream deep learning methods train the neural networks weights while keeping the network architecture fixed, the emerging neural architecture search (NAS) techniques make the latter also amenable to training. In this paper, we formulate optimal arithmetic bit length allocation and neural network pruning as a NAS problem, searching for the configurations satisfying a computational complexity budget while maximizing the accuracy. We use a differentiable search method based on the continuous relaxation of the search space proposed by Liu et al. (arXiv:1806.09055). We show, by grid search, that heterogeneous quantized networks suffer from a high variance which renders the benefit of the search questionable. For pruning, improvement over homogeneous cases is possible, but it is still challenging to find those configurations with the proposed method. The code is publicly available at https://github.com/yochaiz/Slimmable and https://github.com/yochaiz/darts-UNIQ
LaSO: Label-Set Operations networks for multi-label few-shot learning
Feb 26, 2019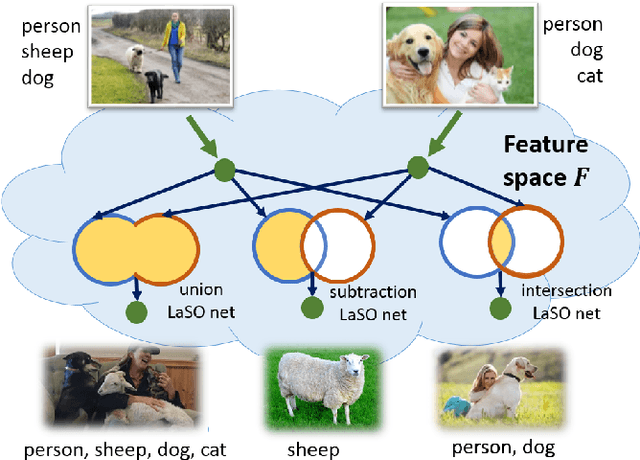
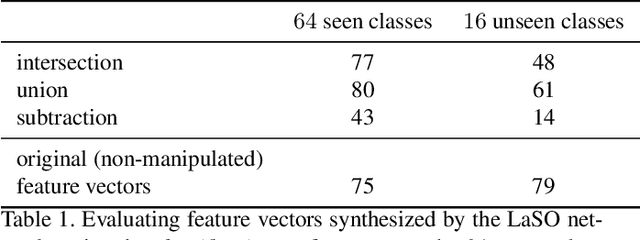

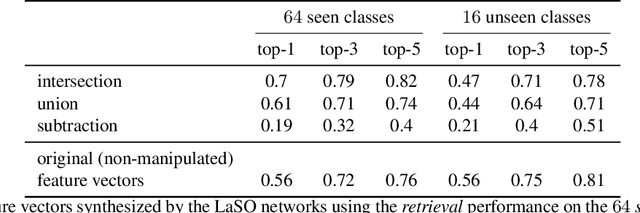
Example synthesis is one of the leading methods to tackle the problem of few-shot learning, where only a small number of samples per class are available. However, current synthesis approaches only address the scenario of a single category label per image. In this work, we propose a novel technique for synthesizing samples with multiple labels for the (yet unhandled) multi-label few-shot classification scenario. We propose to combine pairs of given examples in feature space, so that the resulting synthesized feature vectors will correspond to examples whose label sets are obtained through certain set operations on the label sets of the corresponding input pairs. Thus, our method is capable of producing a sample containing the intersection, union or set-difference of labels present in two input samples. As we show, these set operations generalize to labels unseen during training. This enables performing augmentation on examples of novel categories, thus, facilitating multi-label few-shot classifier learning. We conduct numerous experiments showing promising results for the label-set manipulation capabilities of the proposed approach, both directly (using the classification and retrieval metrics), and in the context of performing data augmentation for multi-label few-shot learning. We propose a benchmark for this new and challenging task and show that our method compares favorably to all the common baselines.
Beholder-GAN: Generation and Beautification of Facial Images with Conditioning on Their Beauty Level
Feb 25, 2019
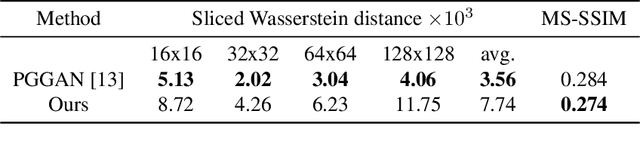

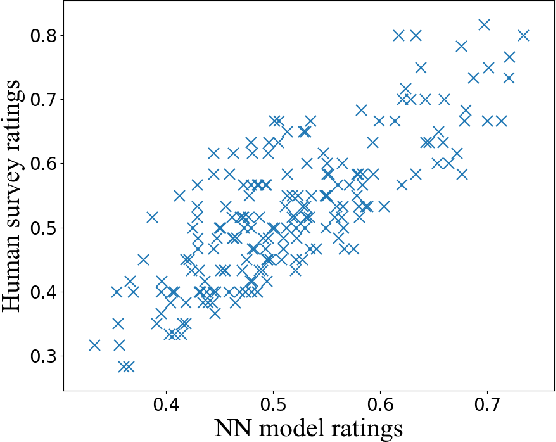
Beauty is in the eye of the beholder. This maxim, emphasizing the subjectivity of the perception of beauty, has enjoyed a wide consensus since ancient times. In the digitalera, data-driven methods have been shown to be able to predict human-assigned beauty scores for facial images. In this work, we augment this ability and train a generative model that generates faces conditioned on a requested beauty score. In addition, we show how this trained generator can be used to beautify an input face image. By doing so, we achieve an unsupervised beautification model, in the sense that it relies on no ground truth target images.
Efficient non-uniform quantizer for quantized neural network targeting reconfigurable hardware
Nov 27, 2018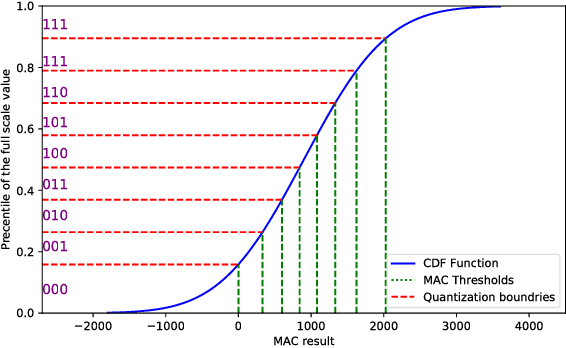

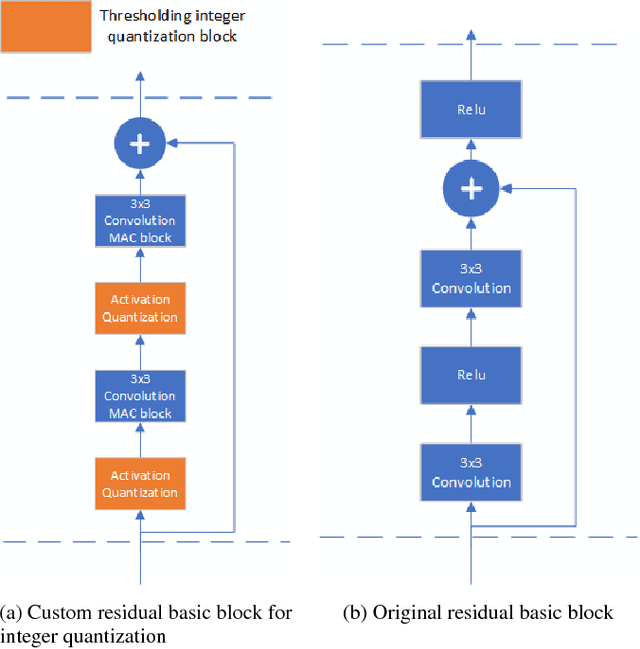
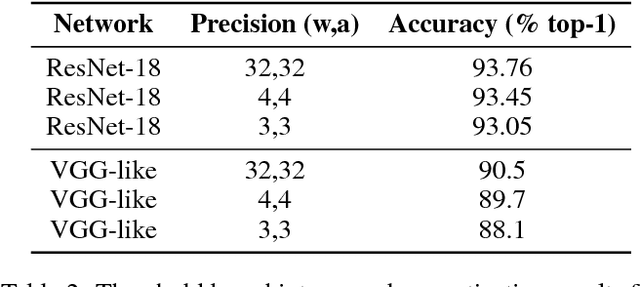
Convolutional Neural Networks (CNN) has become more popular choice for various tasks such as computer vision, speech recognition and natural language processing. Thanks to their large computational capability and throughput, GPUs ,which are not power efficient and therefore does not suit low power systems such as mobile devices, are the most common platform for both training and inferencing tasks. Recent studies has shown that FPGAs can provide a good alternative to GPUs as a CNN accelerator, due to their re-configurable nature, low power and small latency. In order for FPGA-based accelerators outperform GPUs in inference task, both the parameters of the network and the activations must be quantized. While most works use uniform quantizers for both parameters and activations, it is not always the optimal one, and a non-uniform quantizer need to be considered. In this work we introduce a custom hardware-friendly approach to implement non-uniform quantizers. In addition, we use a single scale integer representation of both parameters and activations, for both training and inference. The combined method yields a hardware efficient non-uniform quantizer, fit for real-time applications. We have tested our method on CIFAR-10 and CIFAR-100 image classification datasets with ResNet-18 and VGG-like architectures, and saw little degradation in accuracy.
UNIQ: Uniform Noise Injection for Non-Uniform Quantization of Neural Networks
Oct 02, 2018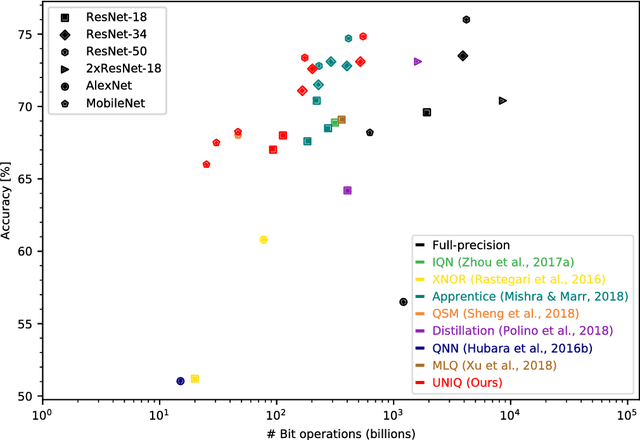
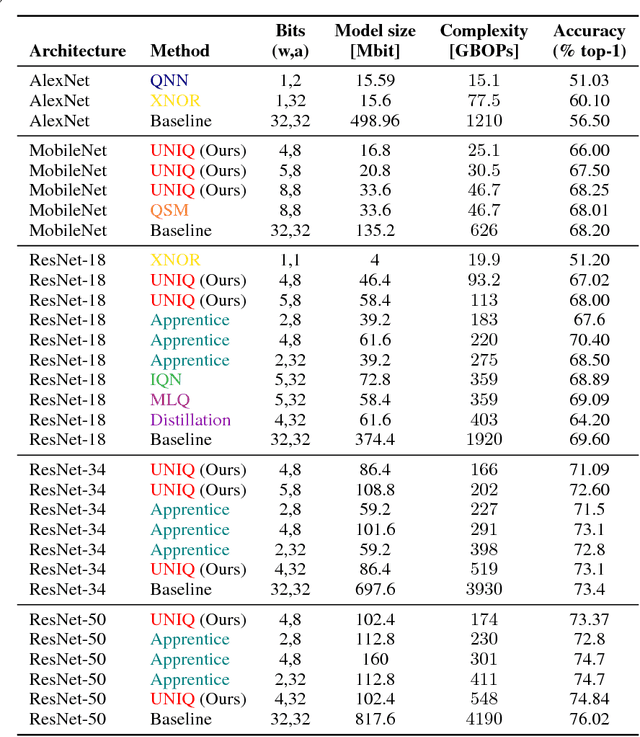
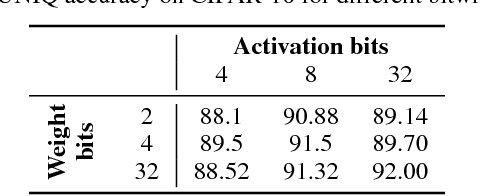
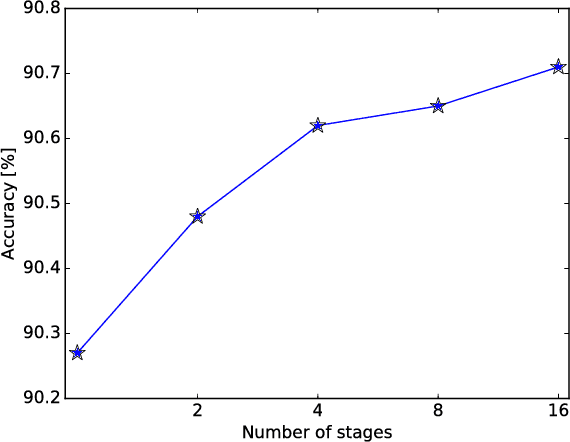
We present a novel method for neural network quantization that emulates a non-uniform $k$-quantile quantizer, which adapts to the distribution of the quantized parameters. Our approach provides a novel alternative to the existing uniform quantization techniques for neural networks. We suggest to compare the results as a function of the bit-operations (BOPS) performed, assuming a look-up table availability for the non-uniform case. In this setup, we show the advantages of our strategy in the low computational budget regime. While the proposed solution is harder to implement in hardware, we believe it sets a basis for new alternatives to neural networks quantization.
High frame-rate cardiac ultrasound imaging with deep learning
Aug 23, 2018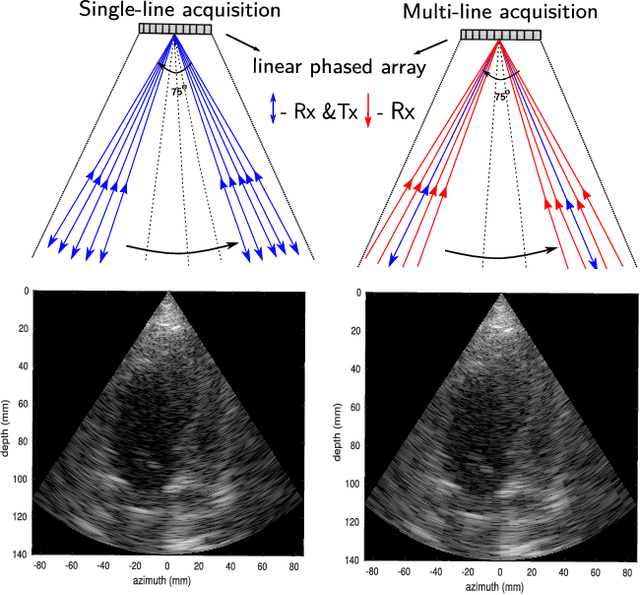
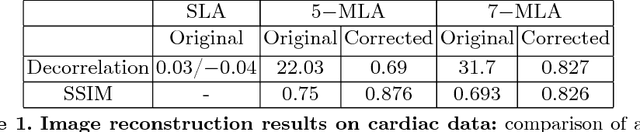
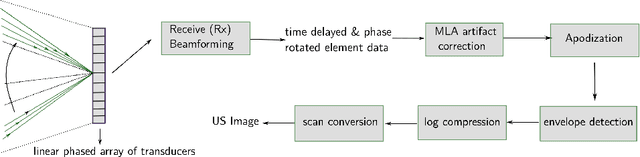
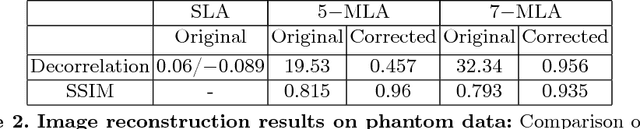
Cardiac ultrasound imaging requires a high frame rate in order to capture rapid motion. This can be achieved by multi-line acquisition (MLA), where several narrow-focused received lines are obtained from each wide-focused transmitted line. This shortens the acquisition time at the expense of introducing block artifacts. In this paper, we propose a data-driven learning-based approach to improve the MLA image quality. We train an end-to-end convolutional neural network on pairs of real ultrasound cardiac data, acquired through MLA and the corresponding single-line acquisition (SLA). The network achieves a significant improvement in image quality for both $5-$ and $7-$line MLA resulting in a decorrelation measure similar to that of SLA while having the frame rate of MLA.
High quality ultrasonic multi-line transmission through deep learning
Aug 23, 2018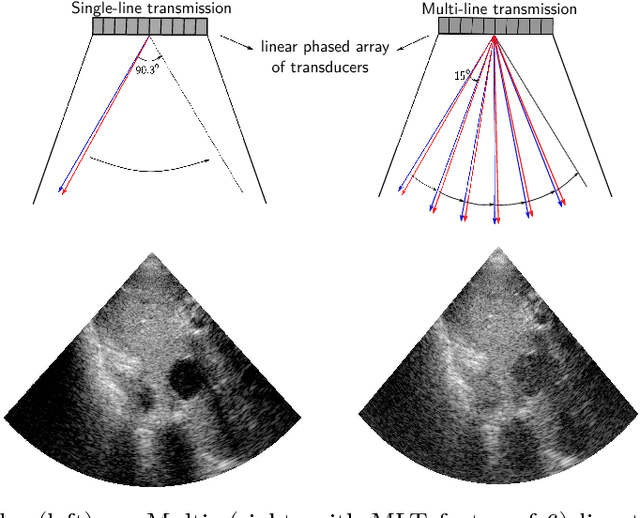
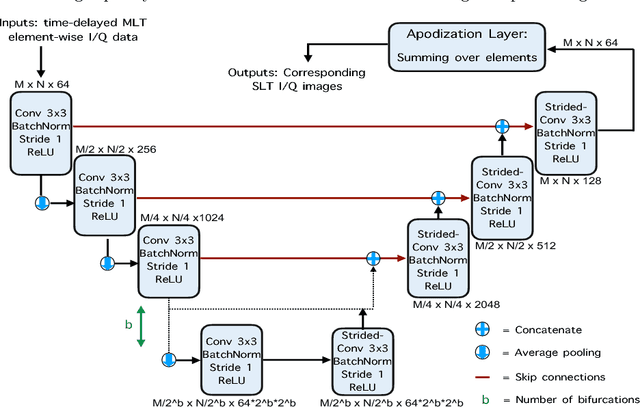
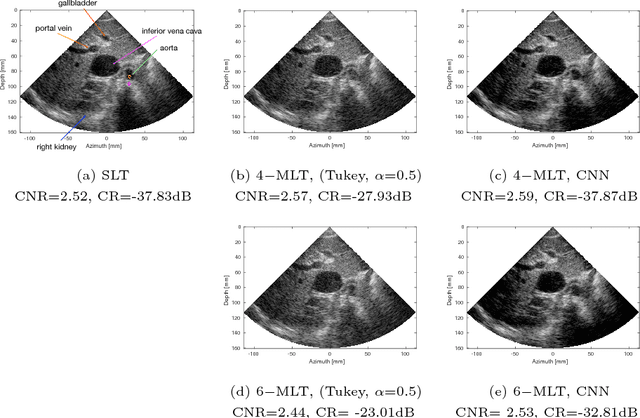
Frame rate is a crucial consideration in cardiac ultrasound imaging and 3D sonography. Several methods have been proposed in the medical ultrasound literature aiming at accelerating the image acquisition. In this paper, we consider one such method called \textit{multi-line transmission} (MLT), in which several evenly separated focused beams are transmitted simultaneously. While MLT reduces the acquisition time, it comes at the expense of a heavy loss of contrast due to the interactions between the beams (cross-talk artifact). In this paper, we introduce a data-driven method to reduce the artifacts arising in MLT. To this end, we propose to train an end-to-end convolutional neural network consisting of correction layers followed by a constant apodization layer. The network is trained on pairs of raw data obtained through MLT and the corresponding \textit{single-line transmission} (SLT) data. Experimental evaluation demonstrates significant improvement both in the visual image quality and in objective measures such as contrast ratio and contrast-to-noise ratio, while preserving resolution unlike traditional apodization-based methods. We show that the proposed method is able to generalize well across different patients and anatomies on real and phantom data.
Class-Aware Fully-Convolutional Gaussian and Poisson Denoising
Aug 20, 2018
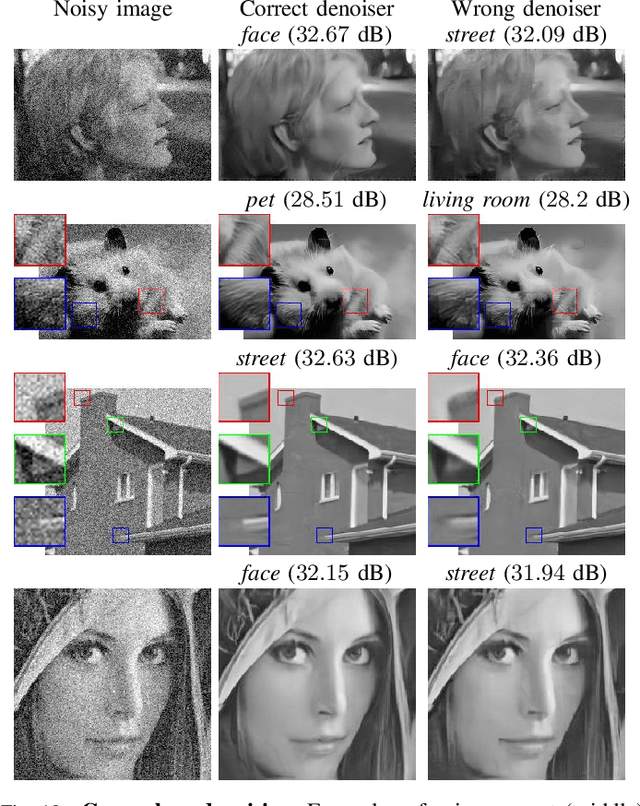
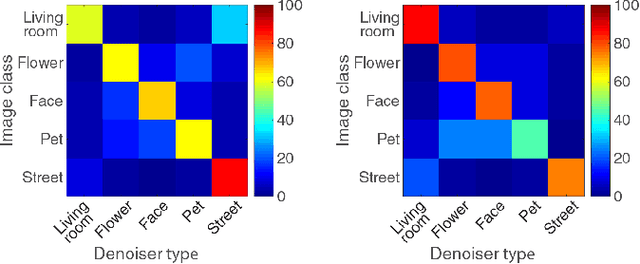

We propose a fully-convolutional neural-network architecture for image denoising which is simple yet powerful. Its structure allows to exploit the gradual nature of the denoising process, in which shallow layers handle local noise statistics, while deeper layers recover edges and enhance textures. Our method advances the state-of-the-art when trained for different noise levels and distributions (both Gaussian and Poisson). In addition, we show that making the denoiser class-aware by exploiting semantic class information boosts performance, enhances textures and reduces artifacts.
RepMet: Representative-based metric learning for classification and one-shot object detection
Jun 15, 2018
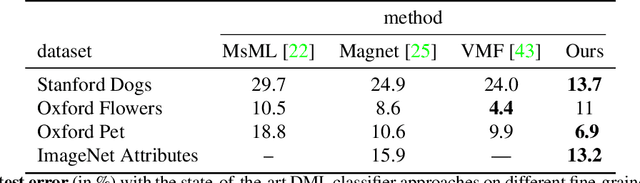
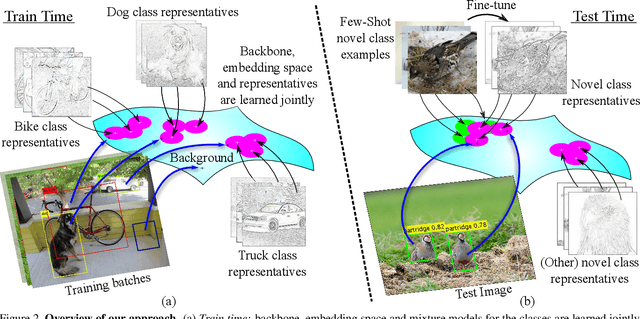
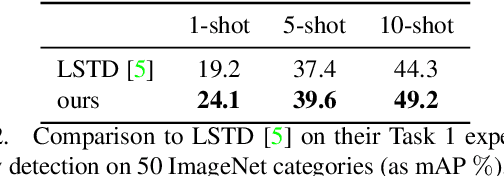
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in Computer Vision - a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset. The code will be made available upon acceptance.