 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dexterous Grasping of Novel Objects from a Single View
Aug 10, 2019



Dexterous grasping of a novel object given a single view is an open problem. This paper makes several contributions to its solution. First, we present a simulator for generating and testing dexterous grasps. Second we present a data set, generated by this simulator, of 2.4 million simulated dexterous grasps of variations of 294 base objects drawn from 20 categories. Third, we present a basic architecture for generation and evaluation of dexterous grasps that may be trained in a supervised manner. Fourth, we present three different evaluative architectures, employing ResNet-50 or VGG16 as their visual backbone. Fifth, we train, and evaluate seventeen variants of generative-evaluative architectures on this simulated data set, showing improvement from 69.53% grasp success rate to 90.49%. Finally, we present a real robot implementation and evaluate the four most promising variants, executing 196 real robot grasps in total. We show that our best architectural variant achieves a grasp success rate of 87.8% on real novel objects seen from a single view, improving on a baseline of 57.1%.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
Exploring object-centric and scene-centric CNN features and their complementarity for human rights violations recognition in images
May 12, 2018


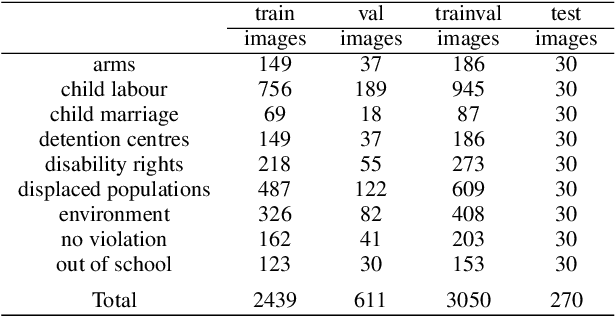
Identifying potential abuses of human rights through imagery is a novel and challenging task in the field of computer vision, that will enable to expose human rights violations over large-scale data that may otherwise be impossible. While standard databases for object and scene categorisation contain hundreds of different classes, the largest available dataset of human rights violations contains only 4 classes. Here, we introduce the `Human Rights Archive Database' (HRA), a verified-by-experts repository of 3050 human rights violations photographs, labelled with human rights semantic categories, comprising a list of the types of human rights abuses encountered at present. With the HRA dataset and a two-phase transfer learning scheme, we fine-tuned the state-of-the-art deep convolutional neural networks (CNNs) to provide human rights violations classification CNNs (HRA-CNNs). We also present extensive experiments refined to evaluate how well object-centric and scene-centric CNN features can be combined for the task of recognising human rights abuses. With this, we show that HRA database poses a challenge at a higher level for the well studied representation learning methods, and provide a benchmark in the task of human rights violations recognition in visual context. We expect this dataset can help to open up new horizons on creating systems able of recognising rich information about human rights violations. Our dataset, codes and trained models are available online at https://github.com/GKalliatakis/Human-Rights-Archive-CNNs.
Material Classification in the Wild: Do Synthesized Training Data Generalise Better than Real-World Training Data?
Nov 09, 2017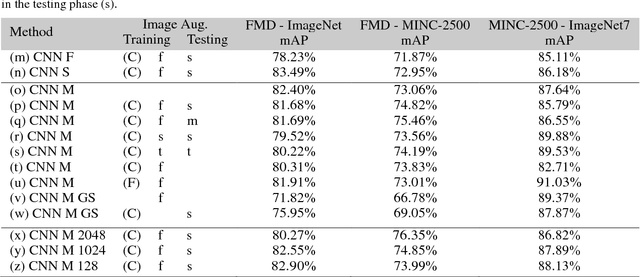
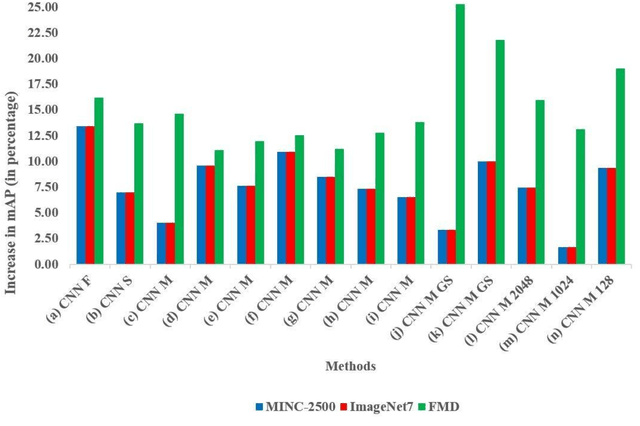
We question the dominant role of real-world training images in the field of material classification by investigating whether synthesized data can generalise more effectively than real-world data. Experimental results on three challenging real-world material databases show that the best performing pre-trained convolutional neural network (CNN) architectures can achieve up to 91.03% mean average precision when classifying materials in cross-dataset scenarios. We demonstrate that synthesized data achieve an improvement on mean average precision when used as training data and in conjunction with pre-trained CNN architectures, which spans from ~ 5% to ~ 19% across three widely used material databases of real-world images.
Performance Characterization of Image Feature Detectors in Relation to the Scene Content Utilizing a Large Image Database
Oct 13, 2017

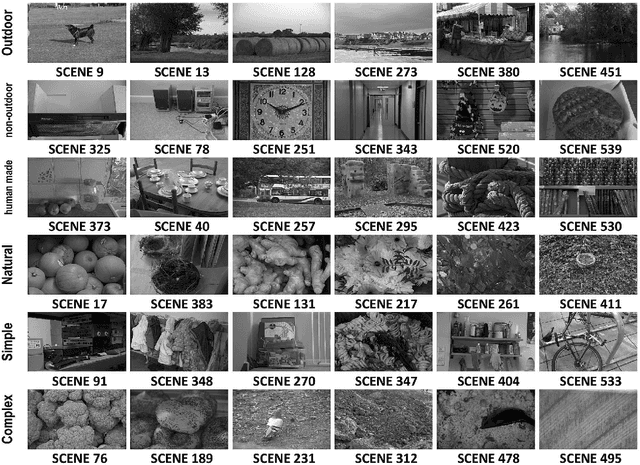
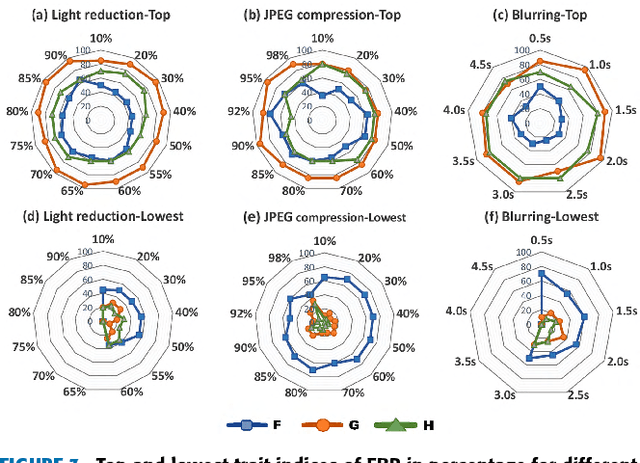
Selecting the most suitable local invariant feature detector for a particular application has rendered the task of evaluating feature detectors a critical issue in vision research. Although the literature offers a variety of comparison works focusing on performance evaluation of image feature detectors under several types of image transformations, the influence of the scene content on the performance of local feature detectors has received little attention so far. This paper aims to bridge this gap with a new framework for determining the type of scenes which maximize and minimize the performance of detectors in terms of repeatability rate. The results are presented for several state-of-the-art feature detectors that have been obtained using a large image database of 20482 images under JPEG compression, uniform light and blur changes with 539 different scenes captured from real-world scenarios. These results provide new insights into the behavior of feature detectors.
Detection of Human Rights Violations in Images: Can Convolutional Neural Networks help?
Mar 16, 2017
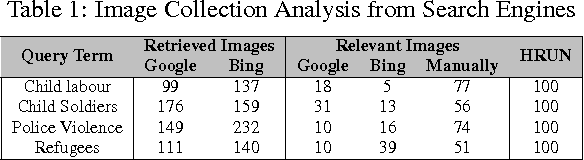
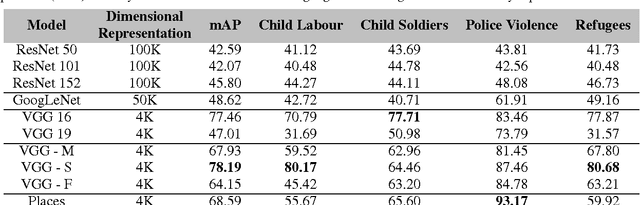
After setting the performance benchmarks for image, video, speech and audio processing, deep convolutional networks have been core to the greatest advances in image recognition tasks in recent times. This raises the question of whether there are any benefit in targeting these remarkable deep architectures with the unattempted task of recognising human rights violations through digital images. Under this perspective, we introduce a new, well-sampled human rights-centric dataset called Human Rights Understanding (HRUN). We conduct a rigorous evaluation on a common ground by combining this dataset with different state-of-the-art deep convolutional architectures in order to achieve recognition of human rights violations. Experimental results on the HRUN dataset have shown that the best performing CNN architectures can achieve up to 88.10\% mean average precision. Additionally, our experiments demonstrate that increasing the size of the training samples is crucial for achieving an improvement on mean average precision principally when utilising very deep networks.
Evaluating Deep Convolutional Neural Networks for Material Classification
Mar 16, 2017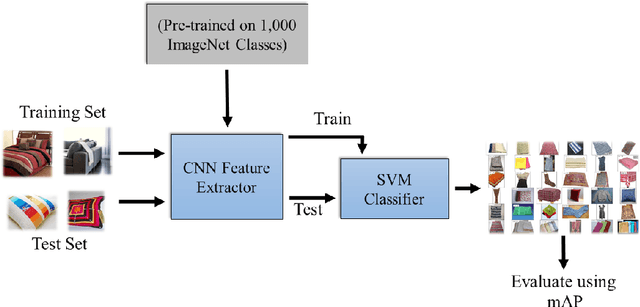
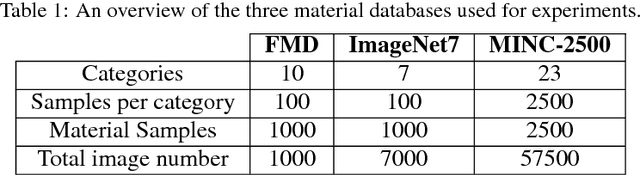
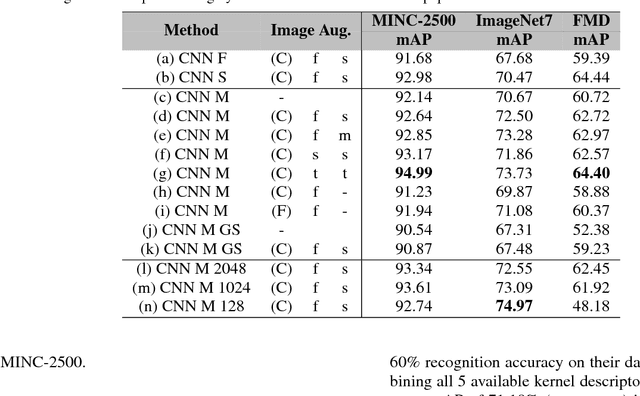
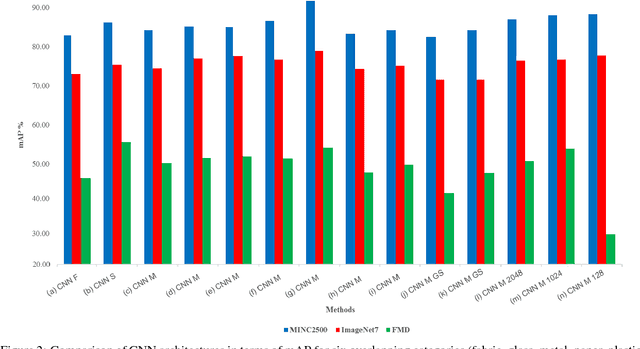
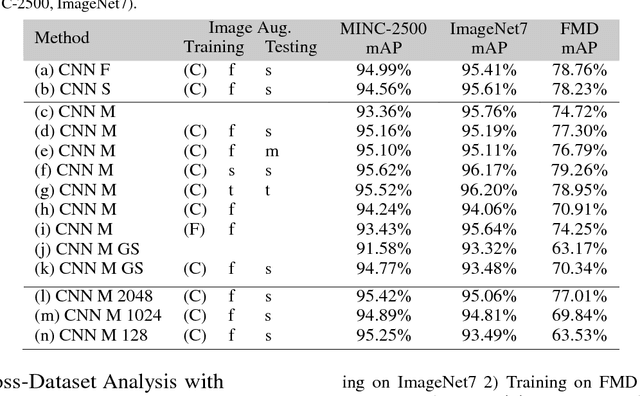
Determining the material category of a surface from an image is a demanding task in perception that is drawing increasing attention. Following the recent remarkable results achieved for image classification and object detection utilising Convolutional Neural Networks (CNNs), we empirically study material classification of everyday objects employing these techniques. More specifically, we conduct a rigorous evaluation of how state-of-the art CNN architectures compare on a common ground over widely used material databases. Experimental results on three challenging material databases show that the best performing CNN architectures can achieve up to 94.99\% mean average precision when classifying materials.
Semantic tracking: Single-target tracking with inter-supervised convolutional networks
Nov 19, 2016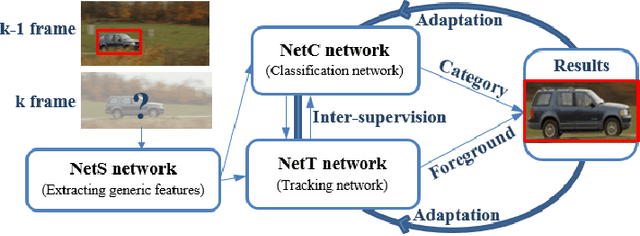

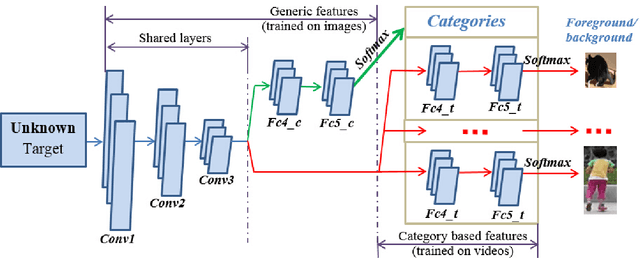

This article presents a semantic tracker which simultaneously tracks a single target and recognises its category. In general, it is hard to design a tracking model suitable for all object categories, e.g., a rigid tracker for a car is not suitable for a deformable gymnast. Category-based trackers usually achieve superior tracking performance for the objects of that specific category, but have difficulties being generalised. Therefore, we propose a novel unified robust tracking framework which explicitly encodes both generic features and category-based features. The tracker consists of a shared convolutional network (NetS), which feeds into two parallel networks, NetC for classification and NetT for tracking. NetS is pre-trained on ImageNet to serve as a generic feature extractor across the different object categories for NetC and NetT. NetC utilises those features within fully connected layers to classify the object category. NetT has multiple branches, corresponding to multiple categories, to distinguish the tracked object from the background. Since each branch in NetT is trained by the videos of a specific category or groups of similar categories, NetT encodes category-based features for tracking. During online tracking, NetC and NetT jointly determine the target regions with the right category and foreground labels for target estimation. To improve the robustness and precision, NetC and NetT inter-supervise each other and trigger network adaptation when their outputs are ambiguous for the same image regions (i.e., when the category label contradicts the foreground/background classification). We have compared the performance of our tracker to other state-of-the-art trackers on a large-scale tracking benchmark (100 sequences)---the obtained results demonstrate the effectiveness of our proposed tracker as it outperformed other 38 state-of-the-art tracking algorithms.
Automatic Selection of the Optimal Local Feature Detector
May 19, 2016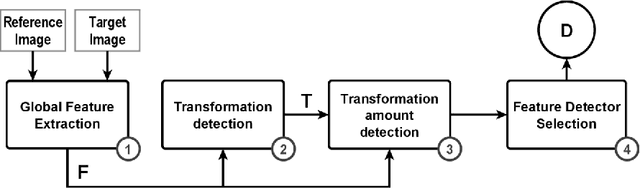
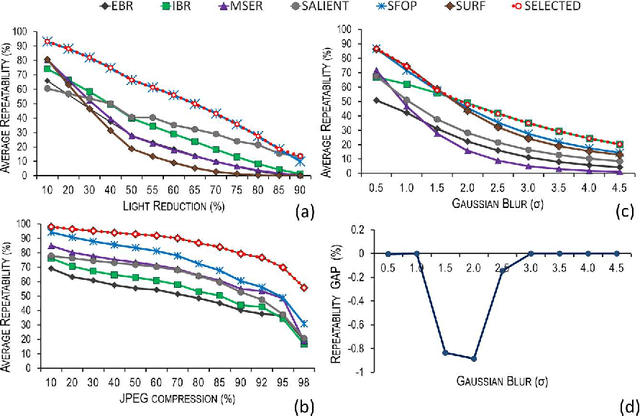
A large number of different feature detectors has been proposed so far. Any existing approach presents strengths and weaknesses, which make a detector optimal only for a limited range of applications. A tool capable of selecting the optimal feature detector in relation to the operating conditions is presented in this paper. The input images are quickly analyzed to determine what type of image transformation is applied to them and at which amount. Finally, the detector that is expected to obtain the highest repeatability under such conditions, is chosen to extract features from the input images. The efficiency and the good accuracy in determining the optimal feature detector for any operating condition, make the proposed tool suitable to be utilized in real visual applications. %A large number of different feature detectors has been proposed so far. Any existing approach presents strengths and weaknesses, which make a detector optimal only for a limited range of applications. A large number of different local feature detectors have been proposed in the last few years. However, each feature detector has its own strengths ad weaknesses that limit its use to a specific range of applications. In this paper is presented a tool capable of quickly analysing input images to determine which type and amount of transformation is applied to them and then selecting the optimal feature detector, which is expected to perform the best. The results show that the performance and the fast execution time render the proposed tool suitable for real-world vision applications.
A Generic Framework for Assessing the Performance Bounds of Image Feature Detectors
May 19, 2016

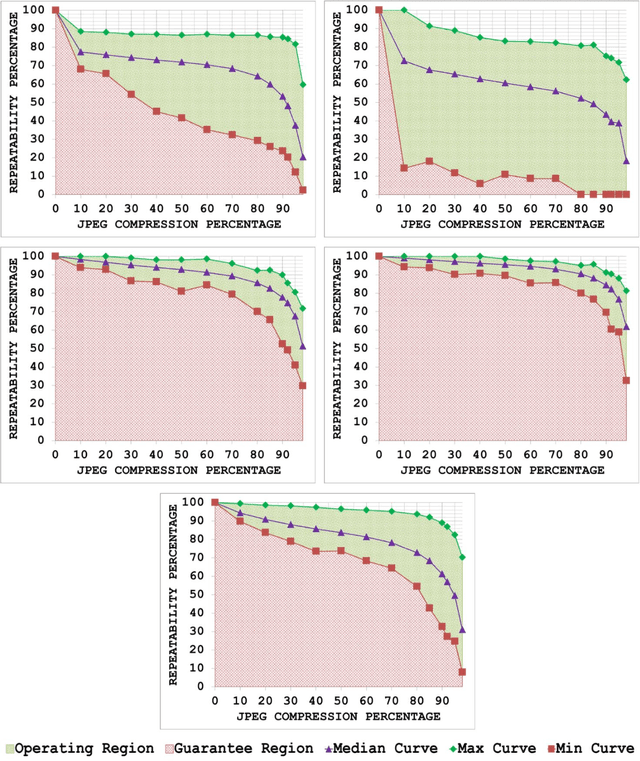
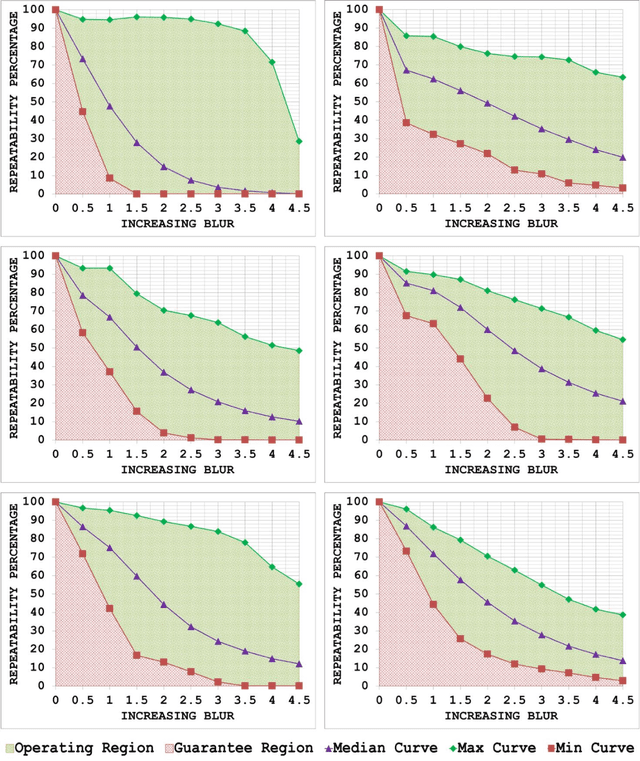
Since local feature detection has been one of the most active research areas in computer vision during the last decade, a large number of detectors have been proposed. The interest in feature-based applications continues to grow and has thus rendered the task of characterizing the performance of various feature detection methods an important issue in vision research. Inspired by the good practices of electronic system design, a generic framework based on the repeatability measure is presented in this paper that allows assessment of the upper and lower bounds of detector performance and finds statistically significant performance differences between detectors as a function of image transformation amount by introducing a new variant of McNemars test in an effort to design more reliable and effective vision systems. The proposed framework is then employed to establish operating and guarantee regions for several state-of-the-art detectors and to identify their statistical performance differences for three specific image transformations: JPEG compression, uniform light changes and blurring. The results are obtained using a newly acquired, large image database (20482) images with 539 different scenes. These results provide new insights into the behaviour of detectors and are also useful from the vision systems design perspective.