 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Distinctive Properties of Universal Perturbations
Dec 31, 2021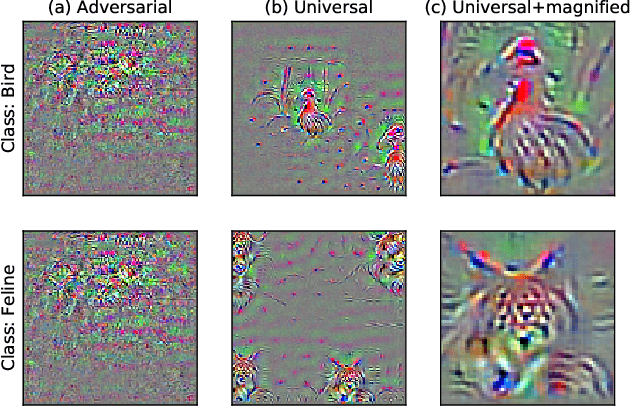
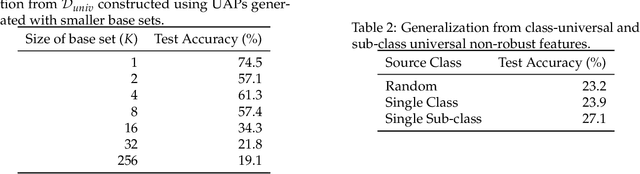
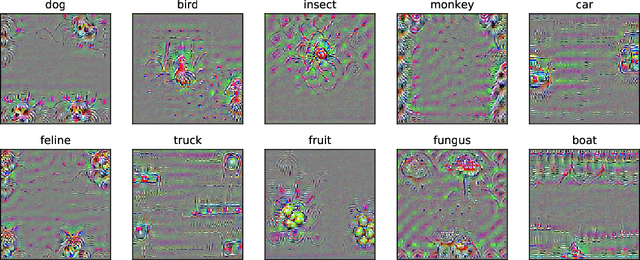
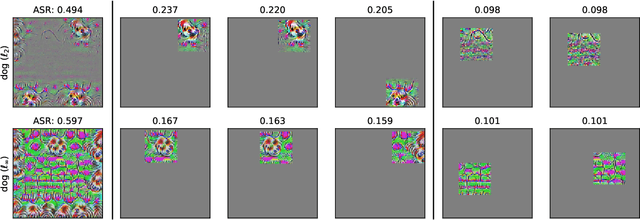
We identify properties of universal adversarial perturbations (UAPs) that distinguish them from standard adversarial perturbations. Specifically, we show that targeted UAPs generated by projected gradient descent exhibit two human-aligned properties: semantic locality and spatial invariance, which standard targeted adversarial perturbations lack. We also demonstrate that UAPs contain significantly less signal for generalization than standard adversarial perturbations -- that is, UAPs leverage non-robust features to a smaller extent than standard adversarial perturbations.
Editing a classifier by rewriting its prediction rules
Dec 02, 2021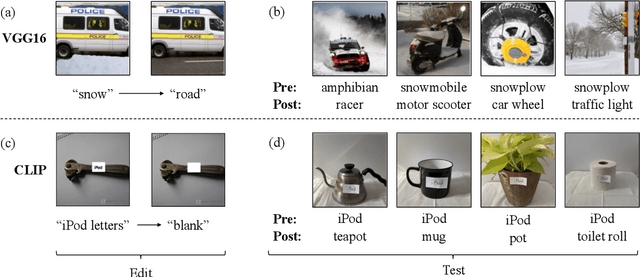

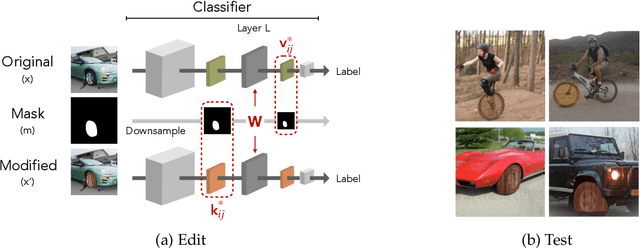
We present a methodology for modifying the behavior of a classifier by directly rewriting its prediction rules. Our approach requires virtually no additional data collection and can be applied to a variety of settings, including adapting a model to new environments, and modifying it to ignore spurious features. Our code is available at https://github.com/MadryLab/EditingClassifiers .
Combining Diverse Feature Priors
Oct 15, 2021
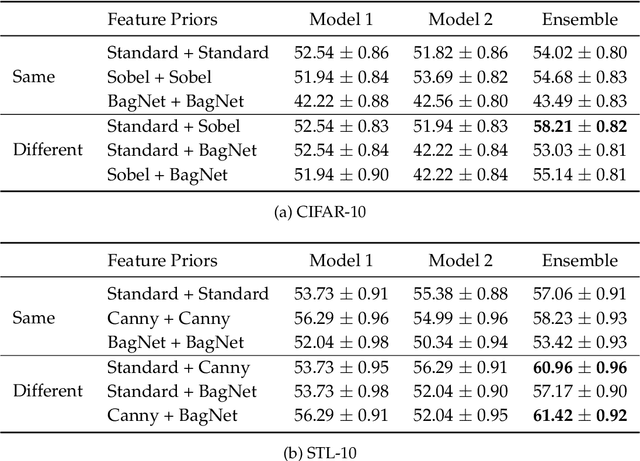
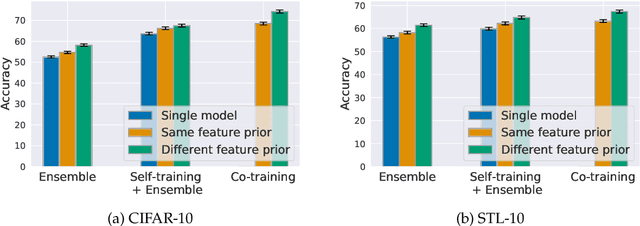
To improve model generalization, model designers often restrict the features that their models use, either implicitly or explicitly. In this work, we explore the design space of leveraging such feature priors by viewing them as distinct perspectives on the data. Specifically, we find that models trained with diverse sets of feature priors have less overlapping failure modes, and can thus be combined more effectively. Moreover, we demonstrate that jointly training such models on additional (unlabeled) data allows them to correct each other's mistakes, which, in turn, leads to better generalization and resilience to spurious correlations. Code available at https://github.com/MadryLab/copriors.
3DB: A Framework for Debugging Computer Vision Models
Jun 07, 2021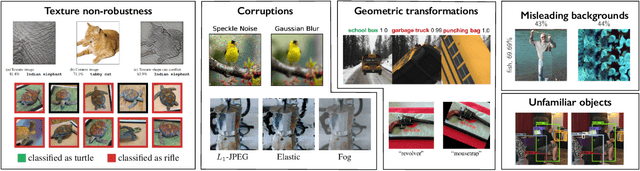
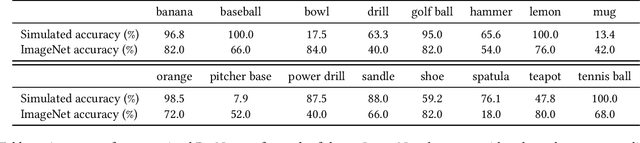

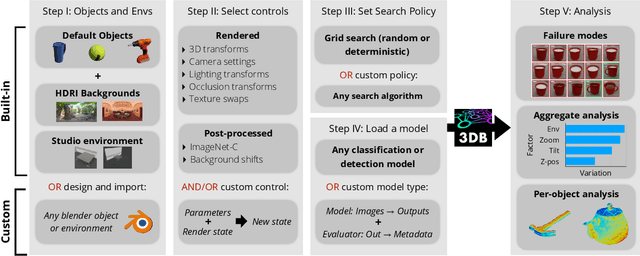
We introduce 3DB: an extendable, unified framework for testing and debugging vision models using photorealistic simulation. We demonstrate, through a wide range of use cases, that 3DB allows users to discover vulnerabilities in computer vision systems and gain insights into how models make decisions. 3DB captures and generalizes many robustness analyses from prior work, and enables one to study their interplay. Finally, we find that the insights generated by the system transfer to the physical world. We are releasing 3DB as a library (https://github.com/3db/3db) alongside a set of example analyses, guides, and documentation: https://3db.github.io/3db/ .
Dataset Security for Machine Learning: Data Poisoning, Backdoor Attacks, and Defenses
Dec 30, 2020
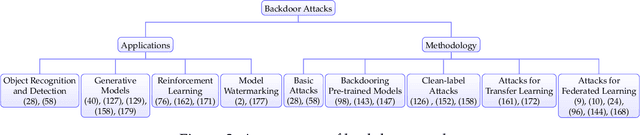


As machine learning systems grow in scale, so do their training data requirements, forcing practitioners to automate and outsource the curation of training data in order to achieve state-of-the-art performance. The absence of trustworthy human supervision over the data collection process exposes organizations to security vulnerabilities; training data can be manipulated to control and degrade the downstream behaviors of learned models. The goal of this work is to systematically categorize and discuss a wide range of dataset vulnerabilities and exploits, approaches for defending against these threats, and an array of open problems in this space. In addition to describing various poisoning and backdoor threat models and the relationships among them, we develop their unified taxonomy.
Unadversarial Examples: Designing Objects for Robust Vision
Dec 22, 2020


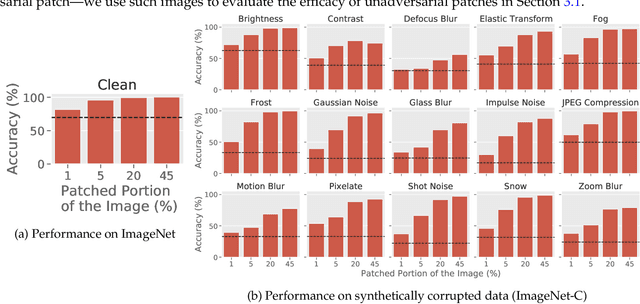
We study a class of realistic computer vision settings wherein one can influence the design of the objects being recognized. We develop a framework that leverages this capability to significantly improve vision models' performance and robustness. This framework exploits the sensitivity of modern machine learning algorithms to input perturbations in order to design "robust objects," i.e., objects that are explicitly optimized to be confidently detected or classified. We demonstrate the efficacy of the framework on a wide variety of vision-based tasks ranging from standard benchmarks, to (in-simulation) robotics, to real-world experiments. Our code can be found at https://git.io/unadversarial .
BREEDS: Benchmarks for Subpopulation Shift
Aug 11, 2020


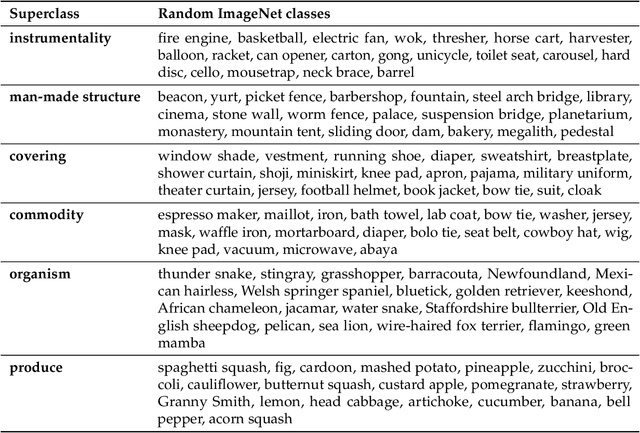
We develop a methodology for assessing the robustness of models to subpopulation shift---specifically, their ability to generalize to novel data subpopulations that were not observed during training. Our approach leverages the class structure underlying existing datasets to control the data subpopulations that comprise the training and test distributions. This enables us to synthesize realistic distribution shifts whose sources can be precisely controlled and characterized, within existing large-scale datasets. Applying this methodology to the ImageNet dataset, we create a suite of subpopulation shift benchmarks of varying granularity. We then validate that the corresponding shifts are tractable by obtaining human baselines for them. Finally, we utilize these benchmarks to measure the sensitivity of standard model architectures as well as the effectiveness of off-the-shelf train-time robustness interventions. Code and data available at https://github.com/MadryLab/BREEDS-Benchmarks .
Do Adversarially Robust ImageNet Models Transfer Better?
Jul 16, 2020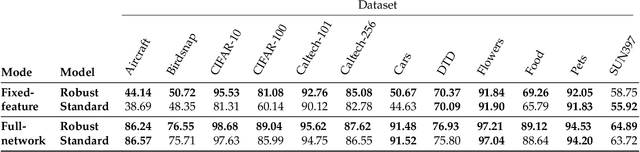

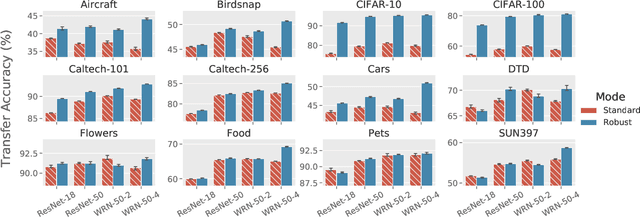
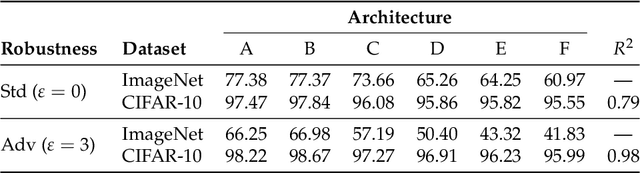
Transfer learning is a widely-used paradigm in deep learning, where models pre-trained on standard datasets can be efficiently adapted to downstream tasks. Typically, better pre-trained models yield better transfer results, suggesting that initial accuracy is a key aspect of transfer learning performance. In this work, we identify another such aspect: we find that adversarially robust models, while less accurate, often perform better than their standard-trained counterparts when used for transfer learning. Specifically, we focus on adversarially robust ImageNet classifiers, and show that they yield improved accuracy on a standard suite of downstream classification tasks. Further analysis uncovers more differences between robust and standard models in the context of transfer learning. Our results are consistent with (and in fact, add to) recent hypotheses stating that robustness leads to improved feature representations. Our code and models are available at https://github.com/Microsoft/robust-models-transfer .
Noise or Signal: The Role of Image Backgrounds in Object Recognition
Jun 17, 2020
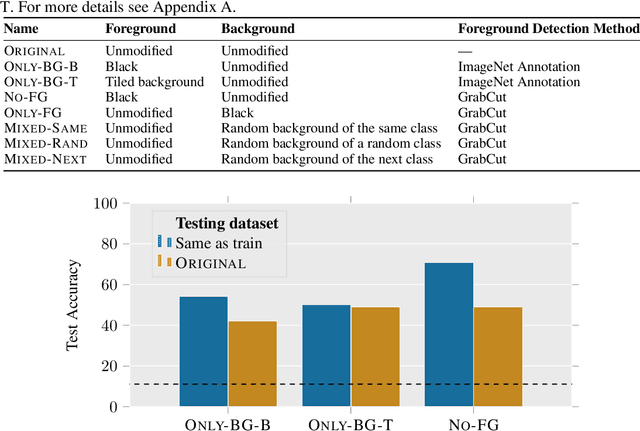
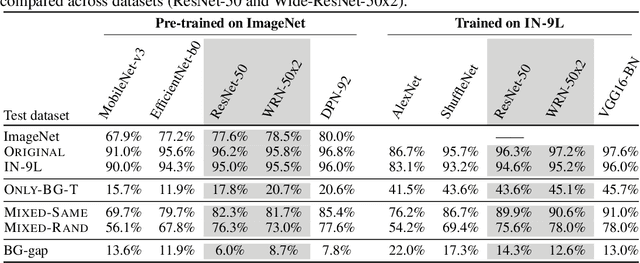

We assess the tendency of state-of-the-art object recognition models to depend on signals from image backgrounds. We create a toolkit for disentangling foreground and background signal on ImageNet images, and find that (a) models can achieve non-trivial accuracy by relying on the background alone, (b) models often misclassify images even in the presence of correctly classified foregrounds--up to 87.5% of the time with adversarially chosen backgrounds, and (c) more accurate models tend to depend on backgrounds less. Our analysis of backgrounds brings us closer to understanding which correlations machine learning models use, and how they determine models' out of distribution performance.
Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
May 25, 2020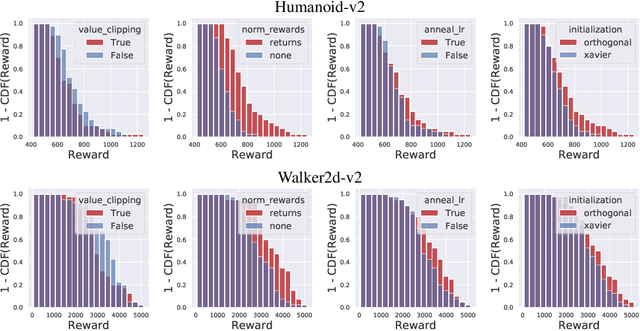

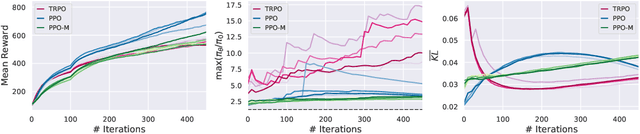
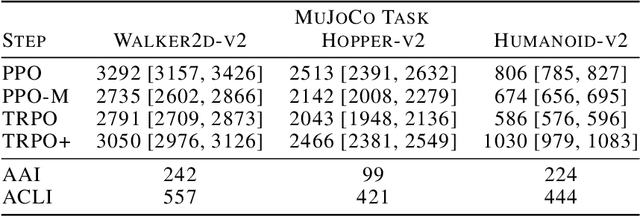
We study the roots of algorithmic progress in deep policy gradient algorithms through a case study on two popular algorithms: Proximal Policy Optimization (PPO) and Trust Region Policy Optimization (TRPO). Specifically, we investigate the consequences of "code-level optimizations:" algorithm augmentations found only in implementations or described as auxiliary details to the core algorithm. Seemingly of secondary importance, such optimizations turn out to have a major impact on agent behavior. Our results show that they (a) are responsible for most of PPO's gain in cumulative reward over TRPO, and (b) fundamentally change how RL methods function. These insights show the difficulty and importance of attributing performance gains in deep reinforcement learning. Code for reproducing our results is available at https://github.com/MadryLab/implementation-matters .