 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Federated Contextual Bandit Algorithms
Mar 17, 2023As the adoption of federated learning increases for learning from sensitive data local to user devices, it is natural to ask if the learning can be done using implicit signals generated as users interact with the applications of interest, rather than requiring access to explicit labels which can be difficult to acquire in many tasks. We approach such problems with the framework of federated contextual bandits, and develop variants of prominent contextual bandit algorithms from the centralized seting for the federated setting. We carefully evaluate these algorithms in a range of scenarios simulated using publicly available datasets. Our simulations model typical setups encountered in the real-world, such as various misalignments between an initial pre-trained model and the subsequent user interactions due to non-stationarity in the data and/or heterogeneity across clients. Our experiments reveal the surprising effectiveness of the simple and commonly used softmax heuristic in balancing the well-know exploration-exploitation tradeoff across the breadth of our settings.
Leveraging User-Triggered Supervision in Contextual Bandits
Feb 07, 2023We study contextual bandit (CB) problems, where the user can sometimes respond with the best action in a given context. Such an interaction arises, for example, in text prediction or autocompletion settings, where a poor suggestion is simply ignored and the user enters the desired text instead. Crucially, this extra feedback is user-triggered on only a subset of the contexts. We develop a new framework to leverage such signals, while being robust to their biased nature. We also augment standard CB algorithms to leverage the signal, and show improved regret guarantees for the resulting algorithms under a variety of conditions on the helpfulness of and bias inherent in this feedback.
Learning in POMDPs is Sample-Efficient with Hindsight Observability
Feb 03, 2023POMDPs capture a broad class of decision making problems, but hardness results suggest that learning is intractable even in simple settings due to the inherent partial observability. However, in many realistic problems, more information is either revealed or can be computed during some point of the learning process. Motivated by diverse applications ranging from robotics to data center scheduling, we formulate a Hindsight Observable Markov Decision Process (HOMDP) as a POMDP where the latent states are revealed to the learner in hindsight and only during training. We introduce new algorithms for the tabular and function approximation settings that are provably sample-efficient with hindsight observability, even in POMDPs that would otherwise be statistically intractable. We give a lower bound showing that the tabular algorithm is optimal in its dependence on latent state and observation cardinalities.
VO$Q$L: Towards Optimal Regret in Model-free RL with Nonlinear Function Approximation
Dec 12, 2022


We study time-inhomogeneous episodic reinforcement learning (RL) under general function approximation and sparse rewards. We design a new algorithm, Variance-weighted Optimistic $Q$-Learning (VO$Q$L), based on $Q$-learning and bound its regret assuming completeness and bounded Eluder dimension for the regression function class. As a special case, VO$Q$L achieves $\tilde{O}(d\sqrt{HT}+d^6H^{5})$ regret over $T$ episodes for a horizon $H$ MDP under ($d$-dimensional) linear function approximation, which is asymptotically optimal. Our algorithm incorporates weighted regression-based upper and lower bounds on the optimal value function to obtain this improved regret. The algorithm is computationally efficient given a regression oracle over the function class, making this the first computationally tractable and statistically optimal approach for linear MDPs.
On the Statistical Efficiency of Reward-Free Exploration in Non-Linear RL
Jun 21, 2022
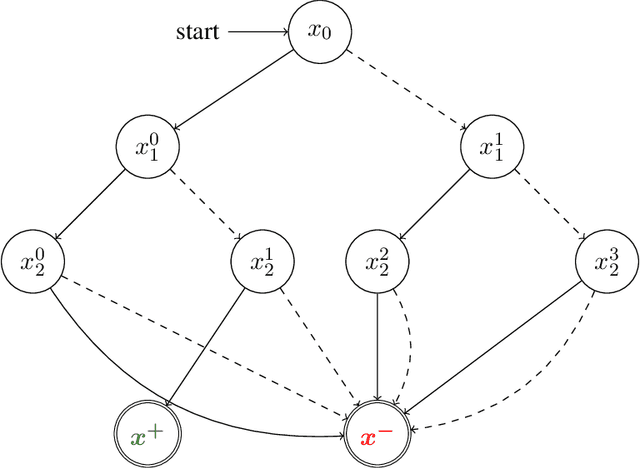
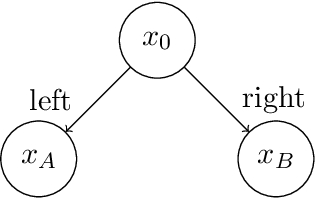
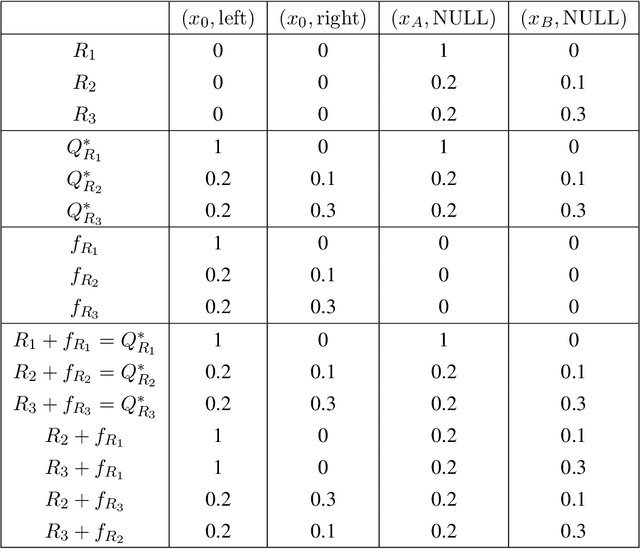
We study reward-free reinforcement learning (RL) under general non-linear function approximation, and establish sample efficiency and hardness results under various standard structural assumptions. On the positive side, we propose the RFOLIVE (Reward-Free OLIVE) algorithm for sample-efficient reward-free exploration under minimal structural assumptions, which covers the previously studied settings of linear MDPs (Jin et al., 2020b), linear completeness (Zanette et al., 2020b) and low-rank MDPs with unknown representation (Modi et al., 2021). Our analyses indicate that the explorability or reachability assumptions, previously made for the latter two settings, are not necessary statistically for reward-free exploration. On the negative side, we provide a statistical hardness result for both reward-free and reward-aware exploration under linear completeness assumptions when the underlying features are unknown, showing an exponential separation between low-rank and linear completeness settings.
Model-based RL with Optimistic Posterior Sampling: Structural Conditions and Sample Complexity
Jun 15, 2022We propose a general framework to design posterior sampling methods for model-based RL. We show that the proposed algorithms can be analyzed by reducing regret to Hellinger distance based conditional probability estimation. We further show that optimistic posterior sampling can control this Hellinger distance, when we measure model error via data likelihood. This technique allows us to design and analyze unified posterior sampling algorithms with state-of-the-art sample complexity guarantees for many model-based RL settings. We illustrate our general result in many special cases, demonstrating the versatility of our framework.
Provable Benefits of Representational Transfer in Reinforcement Learning
May 29, 2022

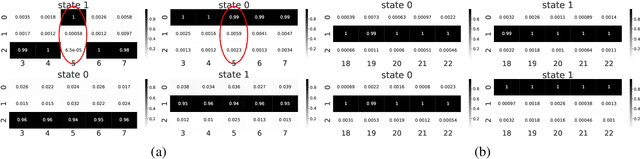
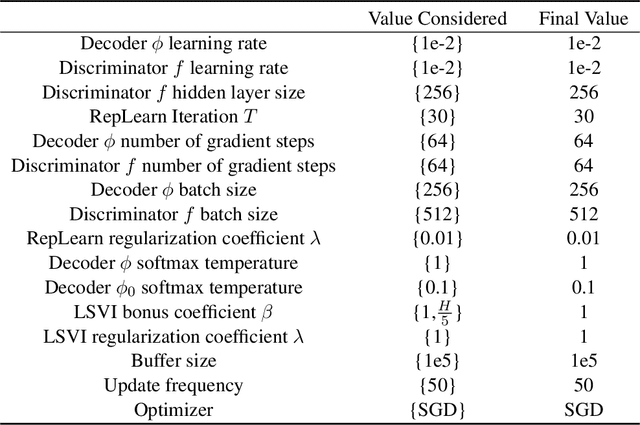
We study the problem of representational transfer in RL, where an agent first pretrains in a number of source tasks to discover a shared representation, which is subsequently used to learn a good policy in a target task. We propose a new notion of task relatedness between source and target tasks, and develop a novel approach for representational transfer under this assumption. Concretely, we show that given generative access to source tasks, we can discover a representation, using which subsequent linear RL techniques quickly converge to a near-optimal policy, with only online access to the target task. The sample complexity is close to knowing the ground truth features in the target task, and comparable to prior representation learning results in the source tasks. We complement our positive results with lower bounds without generative access, and validate our findings with empirical evaluation on rich observation MDPs that require deep exploration.
Non-Linear Reinforcement Learning in Large Action Spaces: Structural Conditions and Sample-efficiency of Posterior Sampling
Mar 15, 2022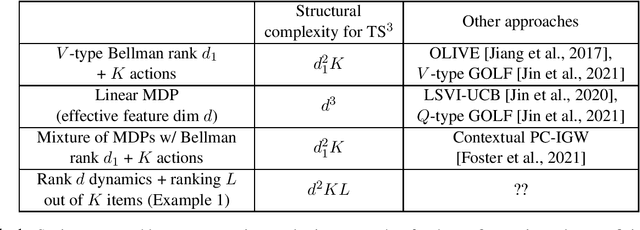
Provably sample-efficient Reinforcement Learning (RL) with rich observations and function approximation has witnessed tremendous recent progress, particularly when the underlying function approximators are linear. In this linear regime, computationally and statistically efficient methods exist where the potentially infinite state and action spaces can be captured through a known feature embedding, with the sample complexity scaling with the (intrinsic) dimension of these features. When the action space is finite, significantly more sophisticated results allow non-linear function approximation under appropriate structural constraints on the underlying RL problem, permitting for instance, the learning of good features instead of assuming access to them. In this work, we present the first result for non-linear function approximation which holds for general action spaces under a linear embeddability condition, which generalizes all linear and finite action settings. We design a novel optimistic posterior sampling strategy, TS^3 for such problems, and show worst case sample complexity guarantees that scale with a rank parameter of the RL problem, the linear embedding dimension introduced in this work and standard measures of the function class complexity.
Minimax Regret Optimization for Robust Machine Learning under Distribution Shift
Feb 11, 2022In this paper, we consider learning scenarios where the learned model is evaluated under an unknown test distribution which potentially differs from the training distribution (i.e. distribution shift). The learner has access to a family of weight functions such that the test distribution is a reweighting of the training distribution under one of these functions, a setting typically studied under the name of Distributionally Robust Optimization (DRO). We consider the problem of deriving regret bounds in the classical learning theory setting, and require that the resulting regret bounds hold uniformly for all potential test distributions. We show that the DRO formulation does not guarantee uniformly small regret under distribution shift. We instead propose an alternative method called Minimax Regret Optimization (MRO), and show that under suitable conditions this method achieves uniformly low regret across all test distributions. We also adapt our technique to have stronger guarantees when the test distributions are heterogeneous in their similarity to the training data. Given the widespead optimization of worst case risks in current approaches to robust machine learning, we believe that MRO can be a strong alternative to address distribution shift scenarios.
Adversarially Trained Actor Critic for Offline Reinforcement Learning
Feb 05, 2022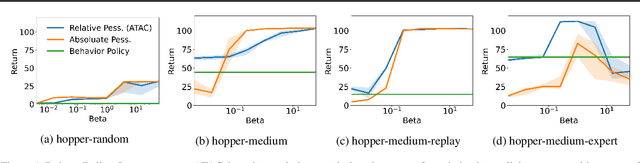
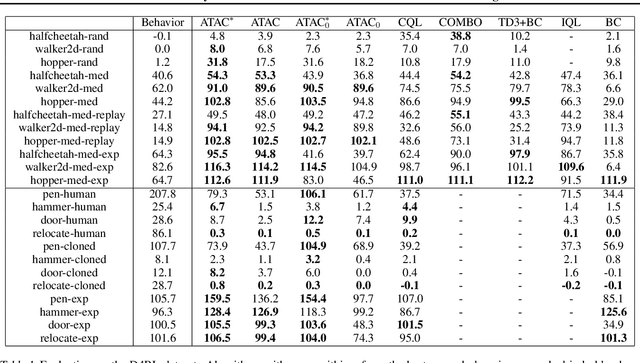
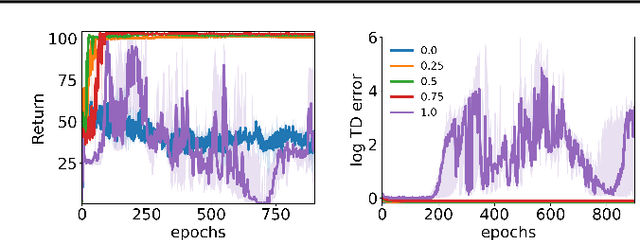
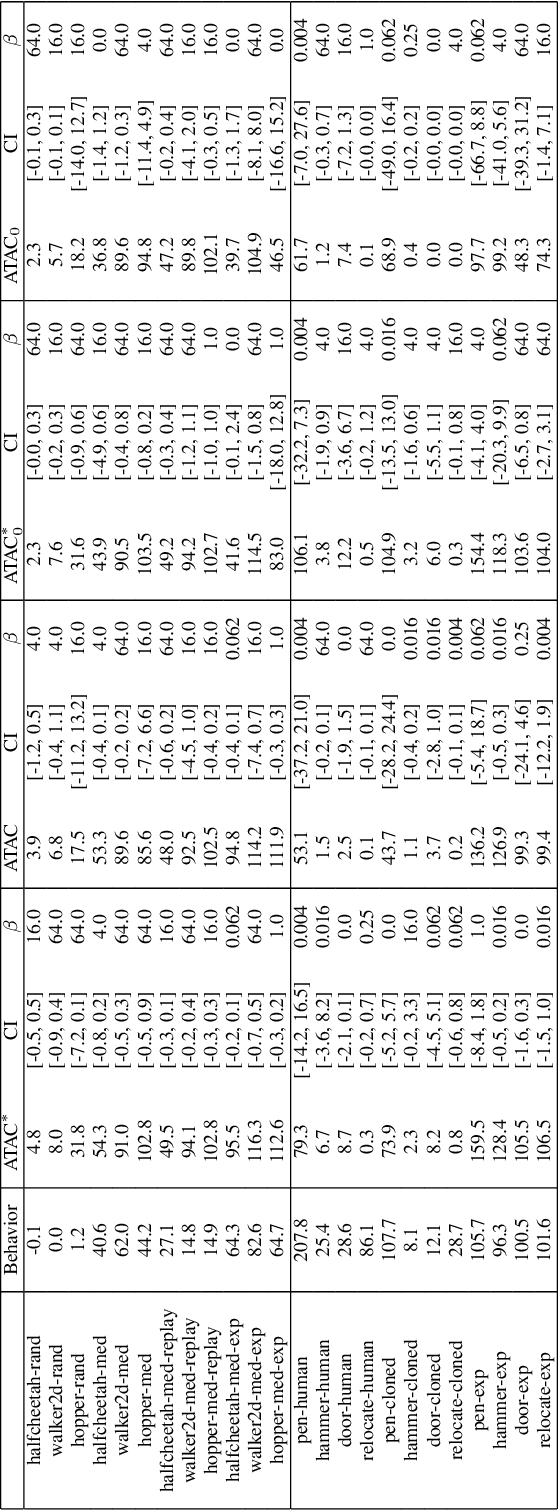
We propose Adversarially Trained Actor Critic (ATAC), a new model-free algorithm for offline reinforcement learning under insufficient data coverage, based on a two-player Stackelberg game framing of offline RL: A policy actor competes against an adversarially trained value critic, who finds data-consistent scenarios where the actor is inferior to the data-collection behavior policy. We prove that, when the actor attains no regret in the two-player game, running ATAC produces a policy that provably 1) outperforms the behavior policy over a wide range of hyperparameters, and 2) competes with the best policy covered by data with appropriately chosen hyperparameters. Compared with existing works, notably our framework offers both theoretical guarantees for general function approximation and a deep RL implementation scalable to complex environments and large datasets. In the D4RL benchmark, ATAC consistently outperforms state-of-the-art offline RL algorithms on a range of continuous control tasks