 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Non-Collaborative Dialog Systems with Explicit Semantic and Strategic Dialog History
Sep 30, 2019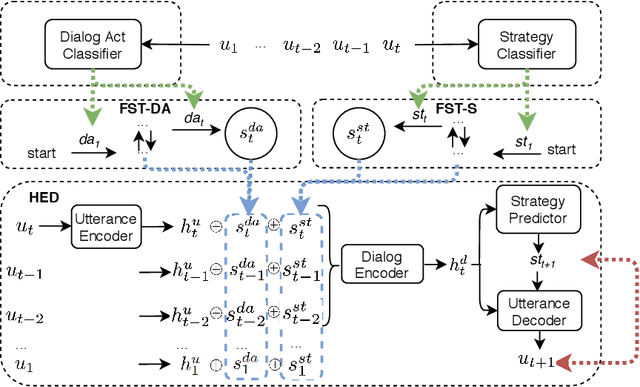
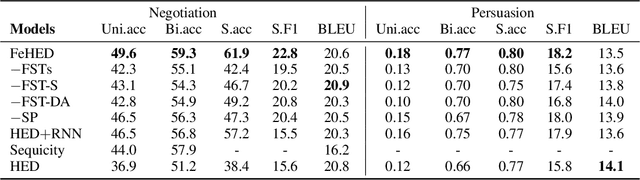
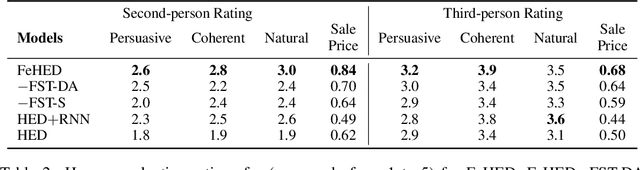
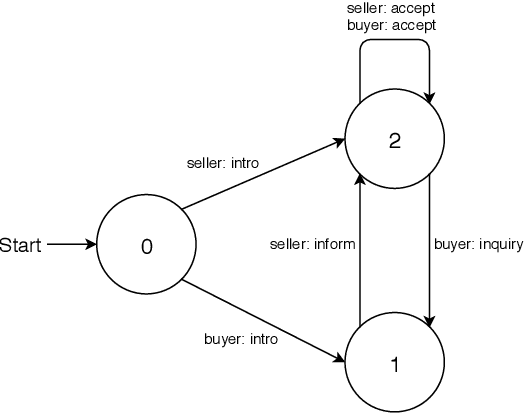
We study non-collaborative dialogs, where two agents have a conflict of interest but must strategically communicate to reach an agreement (e.g., negotiation). This setting poses new challenges for modeling dialog history because the dialog's outcome relies not only on the semantic intent, but also on tactics that convey the intent. We propose to model both semantic and tactic history using finite state transducers (FSTs). Unlike RNN, FSTs can explicitly represent dialog history through all the states traversed, facilitating interpretability of dialog structure. We train FSTs on a set of strategies and tactics used in negotiation dialogs. The trained FSTs show plausible tactic structure and can be generalized to other non-collaborative domains (e.g., persuasion). We evaluate the FSTs by incorporating them in an automated negotiating system that attempts to sell products and a persuasion system that persuades people to donate to a charity. Experiments show that explicitly modeling both semantic and tactic history is an effective way to improve both dialog policy planning and generation performance.
Induction and Reference of Entities in a Visual Story
Sep 15, 2019
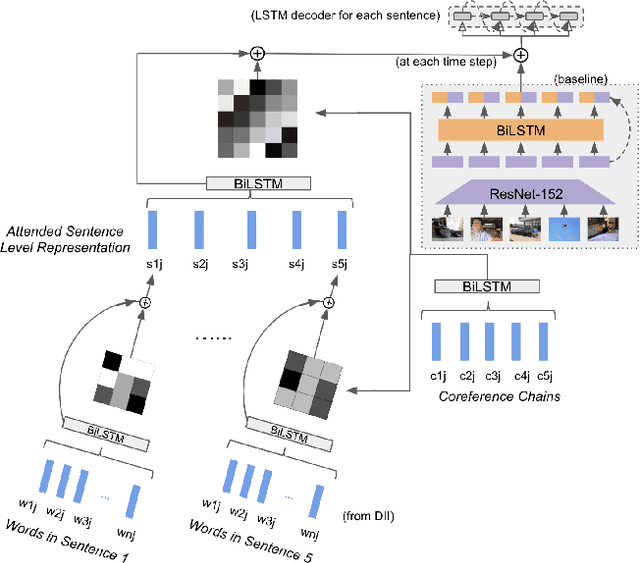
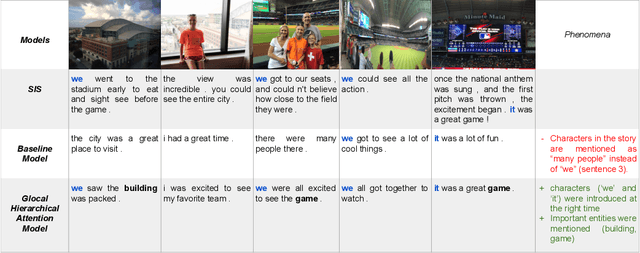
We are enveloped by stories of visual interpretations in our everyday lives. The way we narrate a story often comprises of two stages, which are, forming a central mind map of entities and then weaving a story around them. A contributing factor to coherence is not just basing the story on these entities but also, referring to them using appropriate terms to avoid repetition. In this paper, we address these two stages of introducing the right entities at seemingly reasonable junctures and also referring them coherently in the context of visual storytelling. The building blocks of the central mind map, also known as entity skeleton are entity chains including nominal and coreference expressions. This entity skeleton is also represented in different levels of abstractions to compose a generalized frame to weave the story. We build upon an encoder-decoder framework to penalize the model when the decoded story does not adhere to this entity skeleton. We establish a strong baseline for skeleton informed generation and then extend this to have the capability of multitasking by predicting the skeleton in addition to generating the story. Finally, we build upon this model and propose a glocal hierarchical attention model that attends to the skeleton both at the sentence (local) and the story (global) levels. We observe that our proposed models outperform the baseline in terms of automatic evaluation metric, METEOR. We perform various analysis targeted to evaluate the performance of our task of enforcing the entity skeleton such as the number and diversity of the entities generated. We also conduct human evaluation from which it is concluded that the visual stories generated by our model are preferred 82% of the times. In addition, we show that our glocal hierarchical attention model improves coherence by introducing more pronouns as required by the presence of nouns.
CMU GetGoing: An Understandable and Memorable Dialog System for Seniors
Sep 03, 2019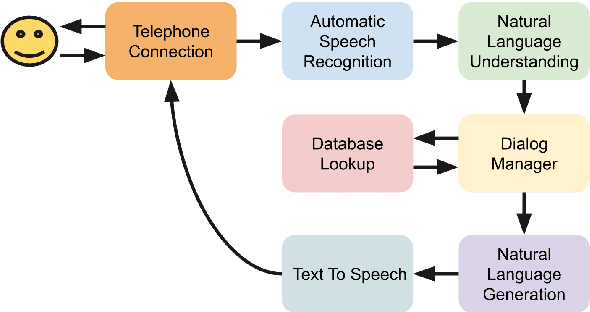
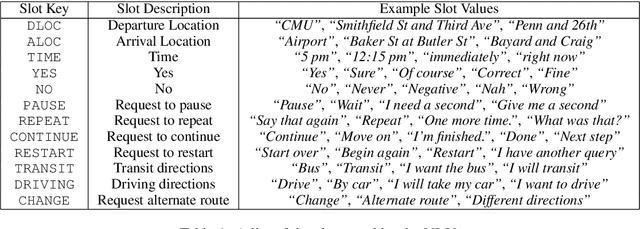
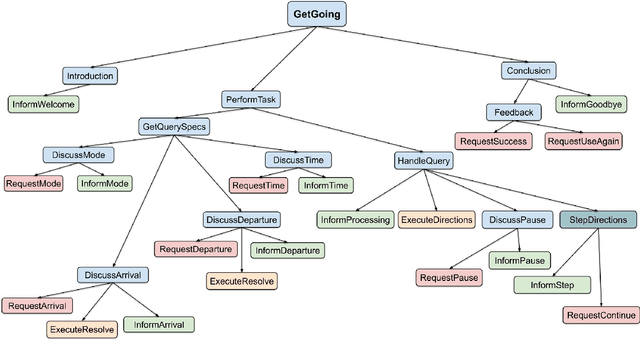
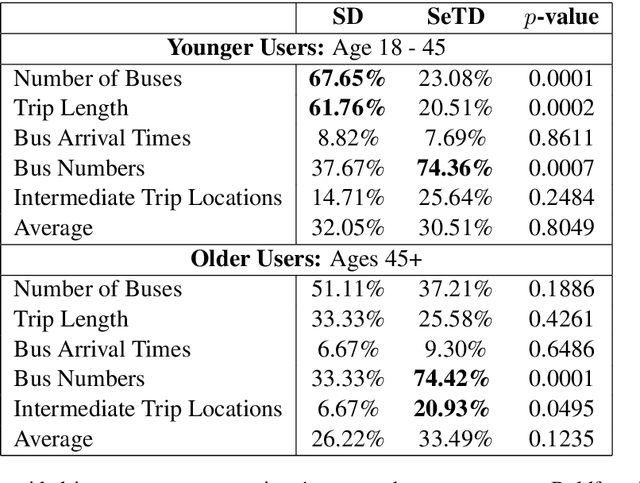
Voice-based technologies are typically developed for the average user, and thus generally not tailored to the specific needs of any subgroup of the population, like seniors. This paper presents CMU GetGoing, an accessible trip planning dialog system designed for senior users. The GetGoing system design is described in detail, with particular attention to the senior-tailored features. A user study is presented, demonstrating that the senior-tailored features significantly improve comprehension and retention of information.
Linguistic Versus Latent Relations for Modeling Coherent Flow in Paragraphs
Aug 30, 2019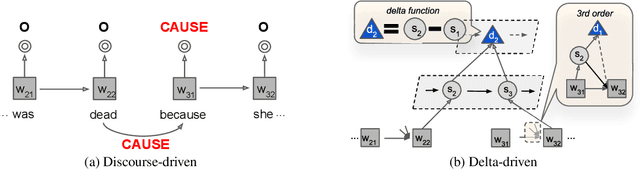
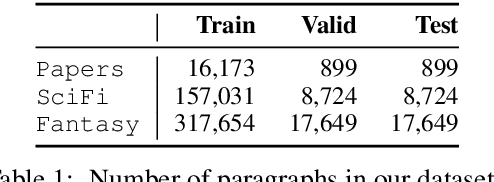

Generating a long, coherent text such as a paragraph requires a high-level control of different levels of relations between sentences (e.g., tense, coreference). We call such a logical connection between sentences as a (paragraph) flow. In order to produce a coherent flow of text, we explore two forms of intersentential relations in a paragraph: one is a human-created linguistical relation that forms a structure (e.g., discourse tree) and the other is a relation from latent representation learned from the sentences themselves. Our two proposed models incorporate each form of relations into document-level language models: the former is a supervised model that jointly learns a language model as well as discourse relation prediction, and the latter is an unsupervised model that is hierarchically conditioned by a recurrent neural network (RNN) over the latent information. Our proposed models with both forms of relations outperform the baselines in partially conditioned paragraph generation task. Our codes and data are publicly available.
WriterForcing: Generating more interesting story endings
Jul 18, 2019

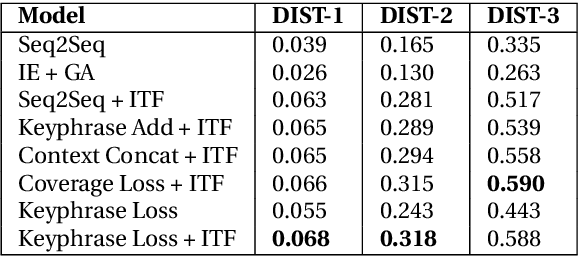
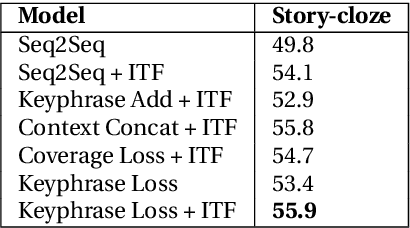
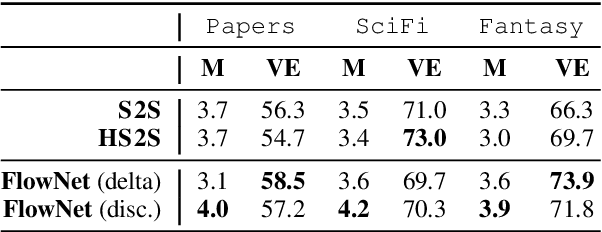
We study the problem of generating interesting endings for stories. Neural generative models have shown promising results for various text generation problems. Sequence to Sequence (Seq2Seq) models are typically trained to generate a single output sequence for a given input sequence. However, in the context of a story, multiple endings are possible. Seq2Seq models tend to ignore the context and generate generic and dull responses. Very few works have studied generating diverse and interesting story endings for a given story context. In this paper, we propose models which generate more diverse and interesting outputs by 1) training models to focus attention on important keyphrases of the story, and 2) promoting generation of non-generic words. We show that the combination of the two leads to more diverse and interesting endings.
Measuring Bias in Contextualized Word Representations
Jun 18, 2019

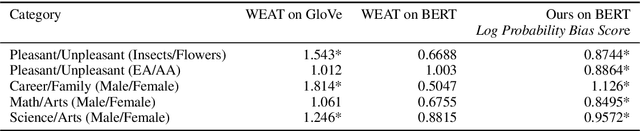
Contextual word embeddings such as BERT have achieved state of the art performance in numerous NLP tasks. Since they are optimized to capture the statistical properties of training data, they tend to pick up on and amplify social stereotypes present in the data as well. In this study, we (1)~propose a template-based method to quantify bias in BERT; (2)~show that this method obtains more consistent results in capturing social biases than the traditional cosine based method; and (3)~conduct a case study, evaluating gender bias in a downstream task of Gender Pronoun Resolution. Although our case study focuses on gender bias, the proposed technique is generalizable to unveiling other biases, including in multiclass settings, such as racial and religious biases.
Principled Frameworks for Evaluating Ethics in NLP Systems
Jun 14, 2019
We critique recent work on ethics in natural language processing. Those discussions have focused on data collection, experimental design, and interventions in modeling. But we argue that we ought to first understand the frameworks of ethics that are being used to evaluate the fairness and justice of algorithmic systems. Here, we begin that discussion by outlining deontological ethics, and envision a research agenda prioritized by it.
"My Way of Telling a Story": Persona based Grounded Story Generation
Jun 14, 2019


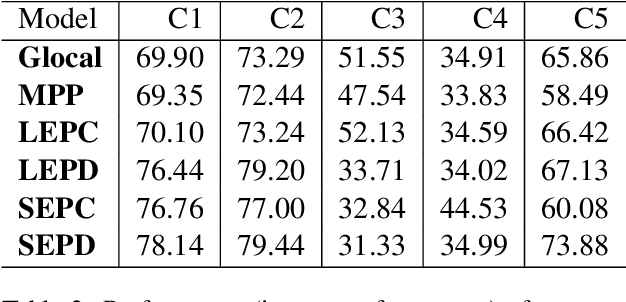
Visual storytelling is the task of generating stories based on a sequence of images. Inspired by the recent works in neural generation focusing on controlling the form of text, this paper explores the idea of generating these stories in different personas. However, one of the main challenges of performing this task is the lack of a dataset of visual stories in different personas. Having said that, there are independent datasets for both visual storytelling and annotated sentences for various persona. In this paper we describe an approach to overcome this by getting labelled persona data from a different task and leveraging those annotations to perform persona based story generation. We inspect various ways of incorporating personality in both the encoder and the decoder representations to steer the generation in the target direction. To this end, we propose five models which are incremental extensions to the baseline model to perform the task at hand. In our experiments we use five different personas to guide the generation process. We find that the models based on our hypotheses perform better at capturing words while generating stories in the target persona.
Exploring Phoneme-Level Speech Representations for End-to-End Speech Translation
Jun 04, 2019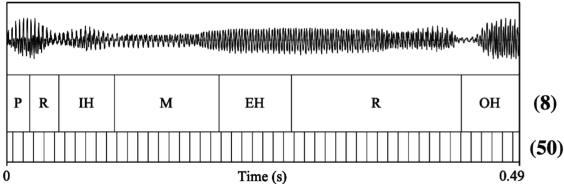

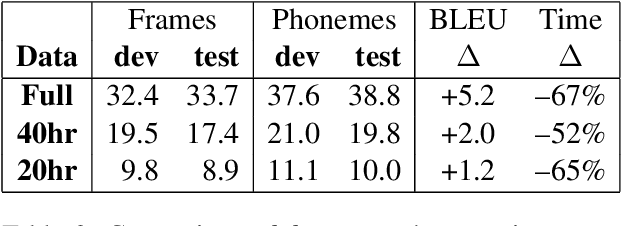
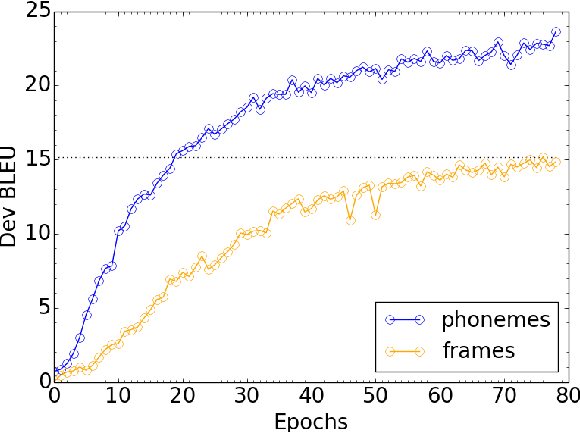
Previous work on end-to-end translation from speech has primarily used frame-level features as speech representations, which creates longer, sparser sequences than text. We show that a naive method to create compressed phoneme-like speech representations is far more effective and efficient for translation than traditional frame-level speech features. Specifically, we generate phoneme labels for speech frames and average consecutive frames with the same label to create shorter, higher-level source sequences for translation. We see improvements of up to 5 BLEU on both our high and low resource language pairs, with a reduction in training time of 60%. Our improvements hold across multiple data sizes and two language pairs.
Black is to Criminal as Caucasian is to Police: Detecting and Removing Multiclass Bias in Word Embeddings
May 13, 2019
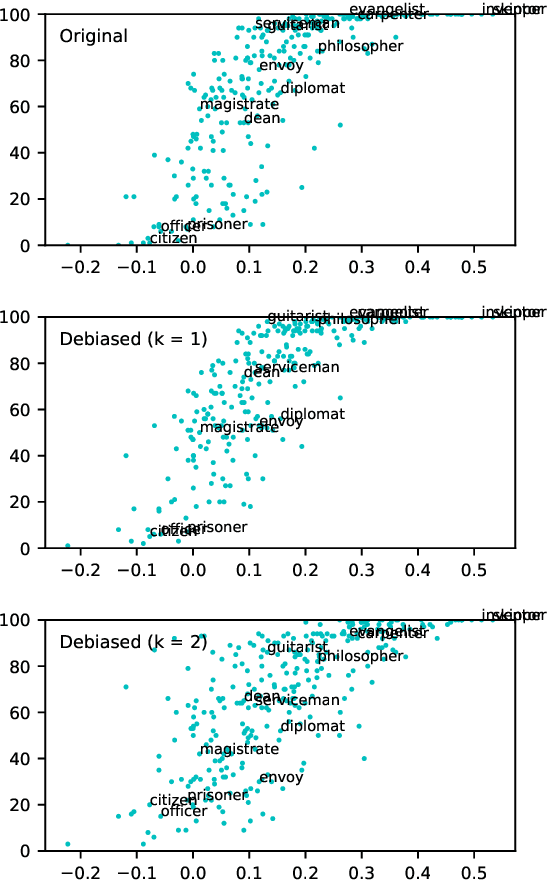
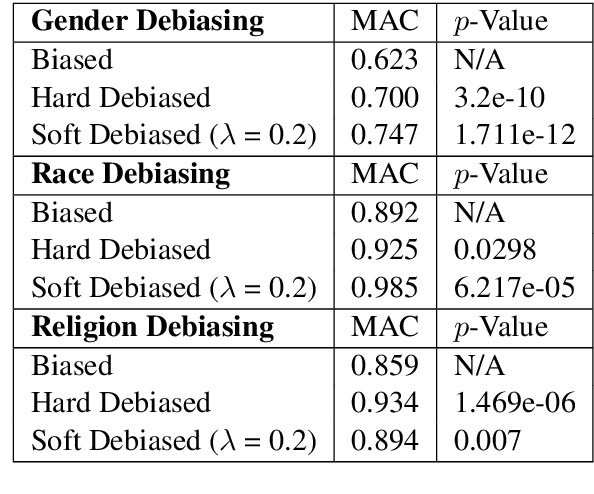
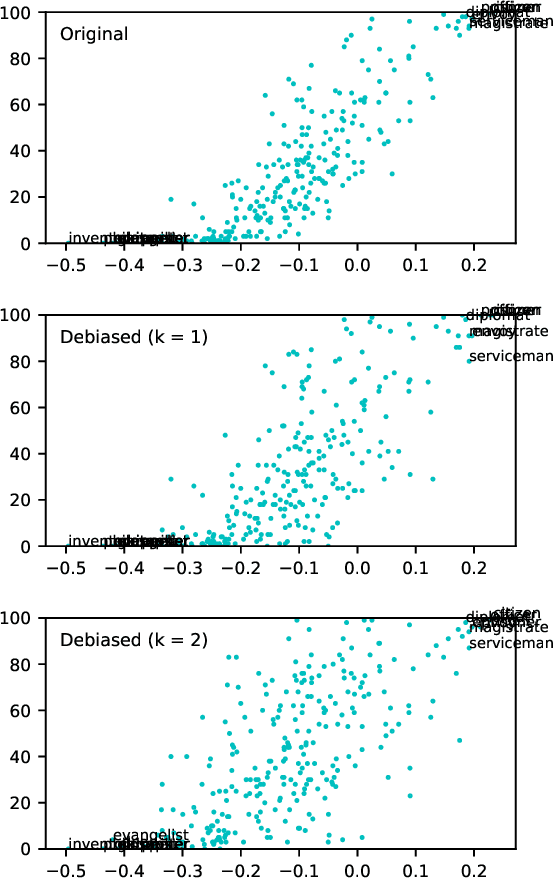
Online texts -- across genres, registers, domains, and styles -- are riddled with human stereotypes, expressed in overt or subtle ways. Word embeddings, trained on these texts, perpetuate and amplify these stereotypes, and propagate biases to machine learning models that use word embeddings as features. In this work, we propose a method to debias word embeddings in multiclass settings such as race and religion, extending the work of (Bolukbasi et al., 2016) from the binary setting, such as binary gender. Next, we propose a novel methodology for the evaluation of multiclass debiasing. We demonstrate that our multiclass debiasing is robust and maintains the efficacy in standard NLP tasks.