 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMAE: Single Model Masked Pretraining on Images and Videos
Jun 16, 2022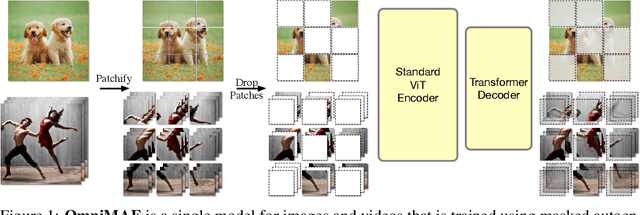

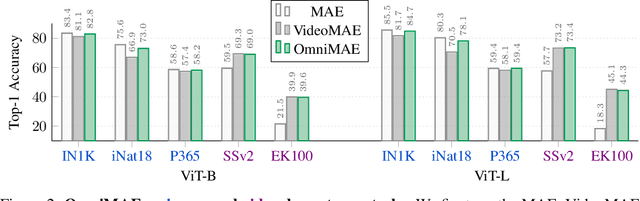
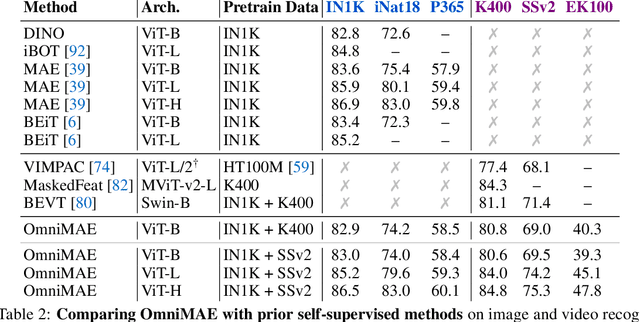
Transformer-based architectures have become competitive across a variety of visual domains, most notably images and videos. While prior work has studied these modalities in isolation, having a common architecture suggests that one can train a single unified model for multiple visual modalities. Prior attempts at unified modeling typically use architectures tailored for vision tasks, or obtain worse performance compared to single modality models. In this work, we show that masked autoencoding can be used to train a simple Vision Transformer on images and videos, without requiring any labeled data. This single model learns visual representations that are comparable to or better than single-modality representations on both image and video benchmarks, while using a much simpler architecture. In particular, our single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark. Furthermore, this model can be learned by dropping 90% of the image and 95% of the video patches, enabling extremely fast training.
Three things everyone should know about Vision Transformers
Mar 18, 2022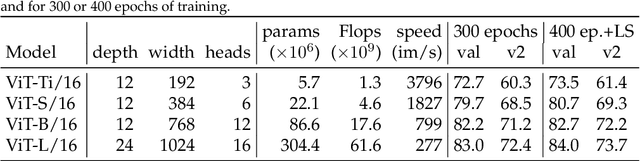
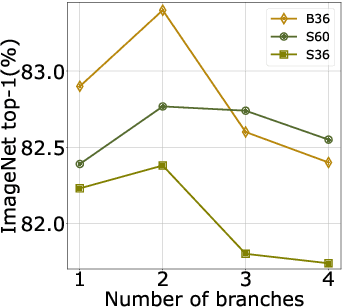
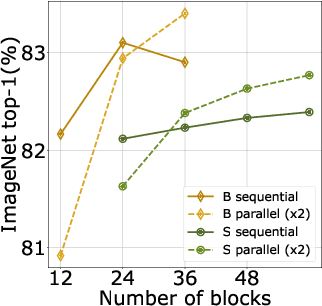
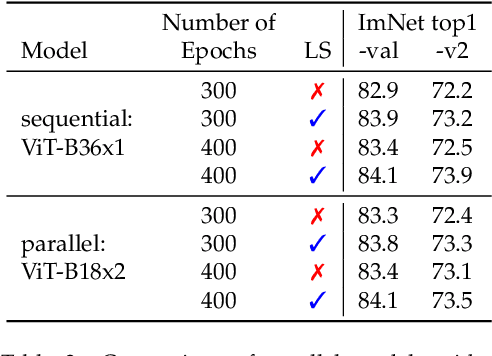
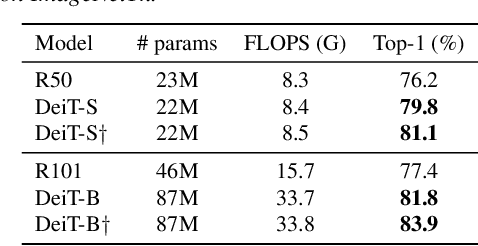
After their initial success in natural language processing, transformer architectures have rapidly gained traction in computer vision, providing state-of-the-art results for tasks such as image classification, detection, segmentation, and video analysis. We offer three insights based on simple and easy to implement variants of vision transformers. (1) The residual layers of vision transformers, which are usually processed sequentially, can to some extent be processed efficiently in parallel without noticeably affecting the accuracy. (2) Fine-tuning the weights of the attention layers is sufficient to adapt vision transformers to a higher resolution and to other classification tasks. This saves compute, reduces the peak memory consumption at fine-tuning time, and allows sharing the majority of weights across tasks. (3) Adding MLP-based patch pre-processing layers improves Bert-like self-supervised training based on patch masking. We evaluate the impact of these design choices using the ImageNet-1k dataset, and confirm our findings on the ImageNet-v2 test set. Transfer performance is measured across six smaller datasets.
Augmenting Convolutional networks with attention-based aggregation
Dec 27, 2021
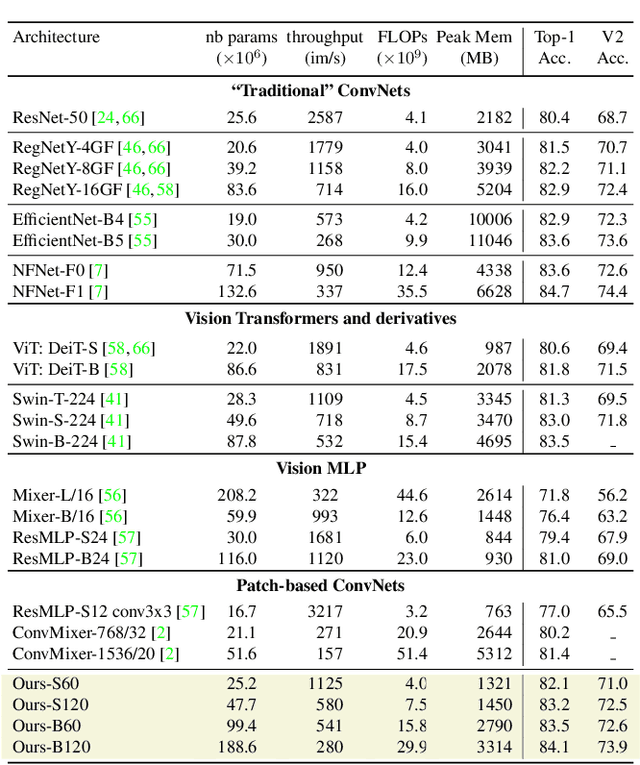

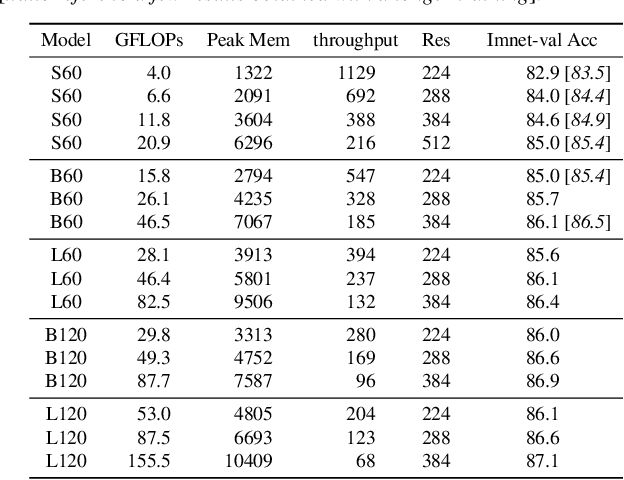
We show how to augment any convolutional network with an attention-based global map to achieve non-local reasoning. We replace the final average pooling by an attention-based aggregation layer akin to a single transformer block, that weights how the patches are involved in the classification decision. We plug this learned aggregation layer with a simplistic patch-based convolutional network parametrized by 2 parameters (width and depth). In contrast with a pyramidal design, this architecture family maintains the input patch resolution across all the layers. It yields surprisingly competitive trade-offs between accuracy and complexity, in particular in terms of memory consumption, as shown by our experiments on various computer vision tasks: object classification, image segmentation and detection.
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
Dec 20, 2021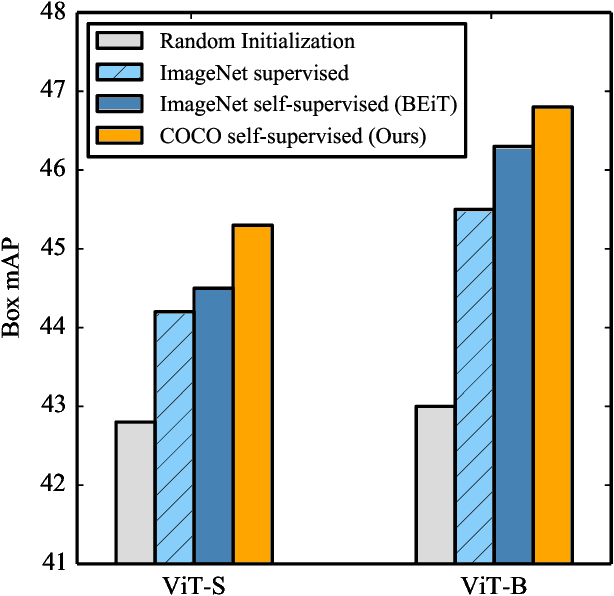
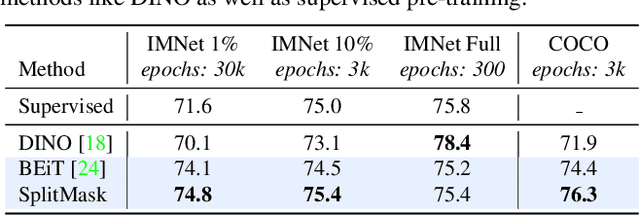
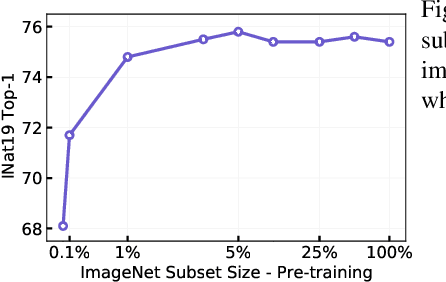

Pre-training models on large scale datasets, like ImageNet, is a standard practice in computer vision. This paradigm is especially effective for tasks with small training sets, for which high-capacity models tend to overfit. In this work, we consider a self-supervised pre-training scenario that only leverages the target task data. We consider datasets, like Stanford Cars, Sketch or COCO, which are order(s) of magnitude smaller than Imagenet. Our study shows that denoising autoencoders, such as BEiT or a variant that we introduce in this paper, are more robust to the type and size of the pre-training data than popular self-supervised methods trained by comparing image embeddings.We obtain competitive performance compared to ImageNet pre-training on a variety of classification datasets, from different domains. On COCO, when pre-training solely using COCO images, the detection and instance segmentation performance surpasses the supervised ImageNet pre-training in a comparable setting.
XCiT: Cross-Covariance Image Transformers
Jun 18, 2021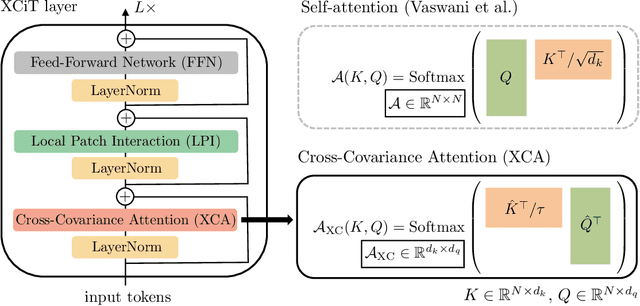
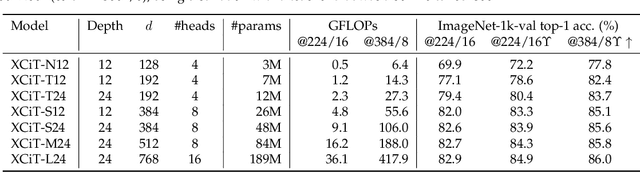
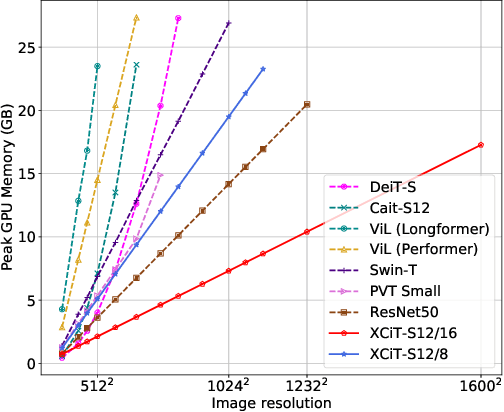
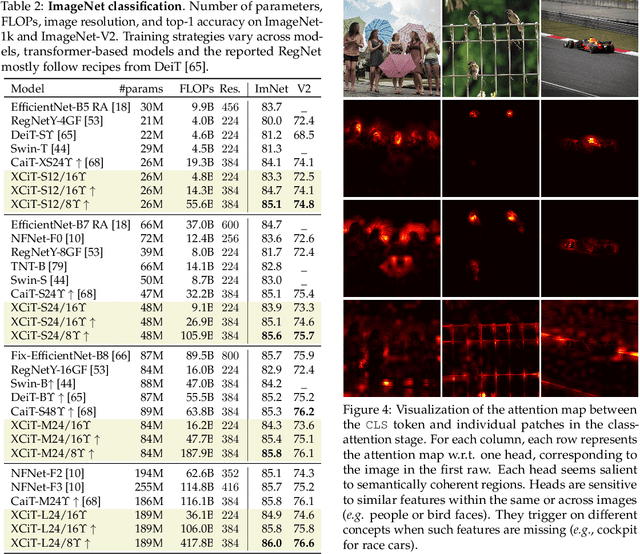
Following their success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens ,i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a "transposed" version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k.
ResMLP: Feedforward networks for image classification with data-efficient training
May 07, 2021
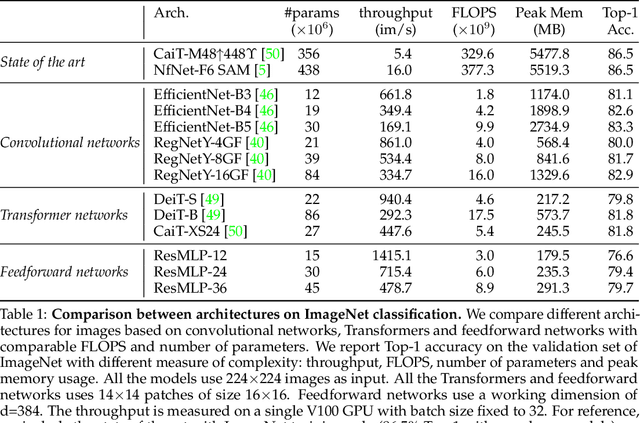
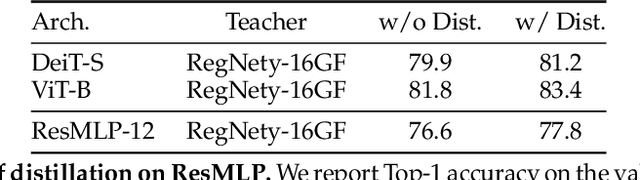
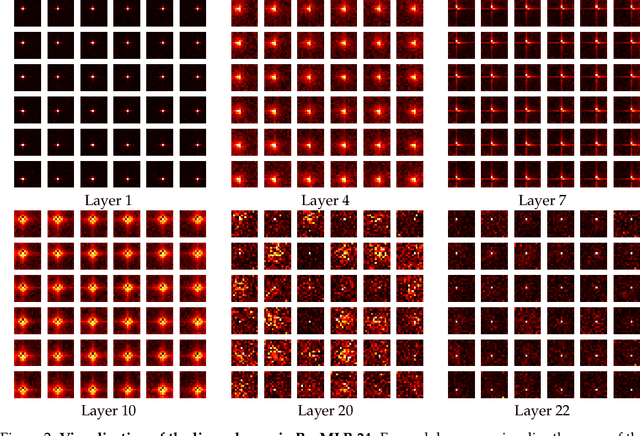
We present ResMLP, an architecture built entirely upon multi-layer perceptrons for image classification. It is a simple residual network that alternates (i) a linear layer in which image patches interact, independently and identically across channels, and (ii) a two-layer feed-forward network in which channels interact independently per patch. When trained with a modern training strategy using heavy data-augmentation and optionally distillation, it attains surprisingly good accuracy/complexity trade-offs on ImageNet. We will share our code based on the Timm library and pre-trained models.
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
Apr 02, 2021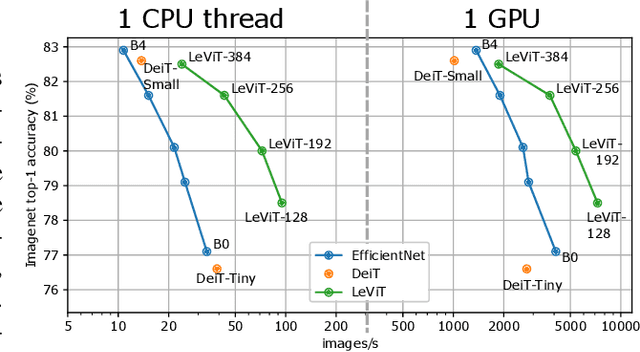
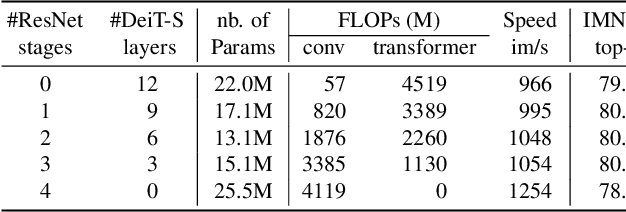

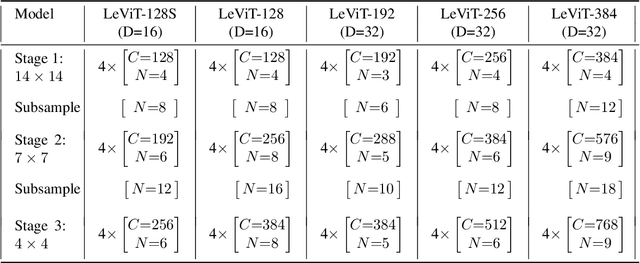
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We re-evaluated principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80\% ImageNet top-1 accuracy, LeViT is 3.3 times faster than EfficientNet on the CPU.
Training Vision Transformers for Image Retrieval
Feb 10, 2021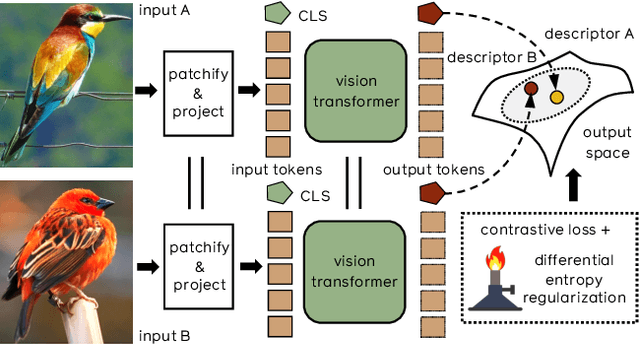
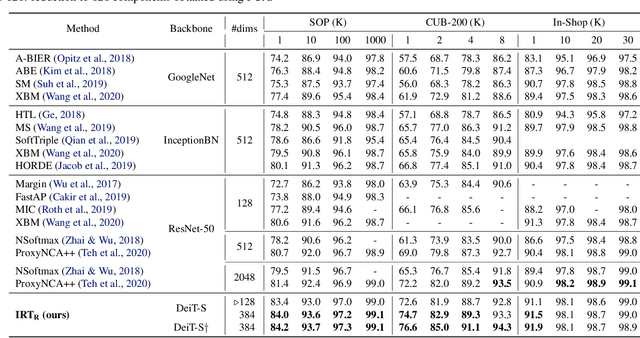
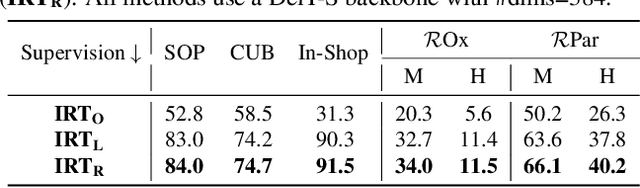
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
Skip-Clip: Self-Supervised Spatiotemporal Representation Learning by Future Clip Order Ranking
Oct 28, 2019

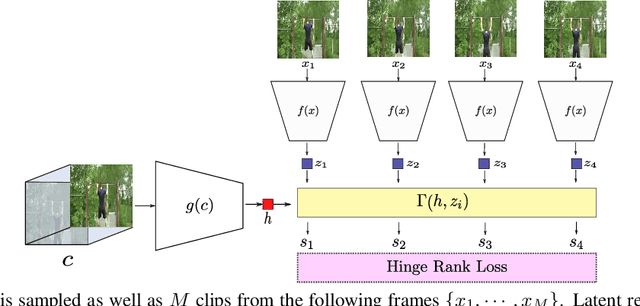

Deep neural networks require collecting and annotating large amounts of data to train successfully. In order to alleviate the annotation bottleneck, we propose a novel self-supervised representation learning approach for spatiotemporal features extracted from videos. We introduce Skip-Clip, a method that utilizes temporal coherence in videos, by training a deep model for future clip order ranking conditioned on a context clip as a surrogate objective for video future prediction. We show that features learned using our method are generalizable and transfer strongly to downstream tasks. For action recognition on the UCF101 dataset, we obtain 51.8% improvement over random initialization and outperform models initialized using inflated ImageNet parameters. Skip-Clip also achieves results competitive with state-of-the-art self-supervision methods.
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018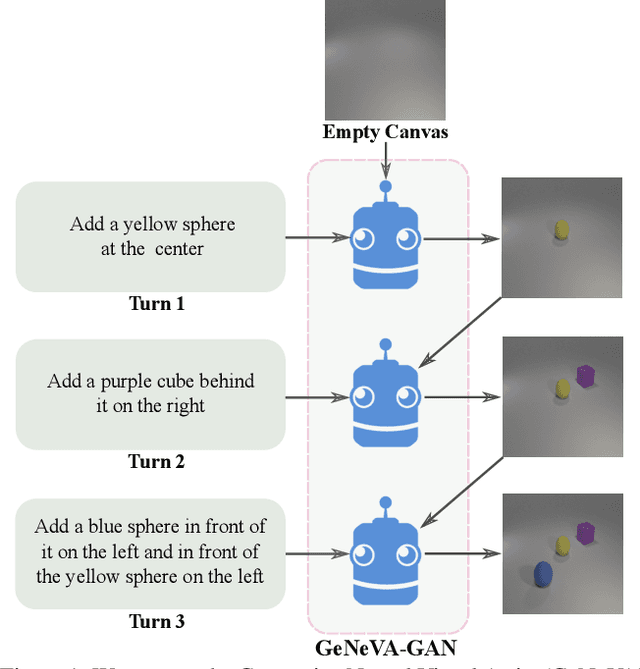
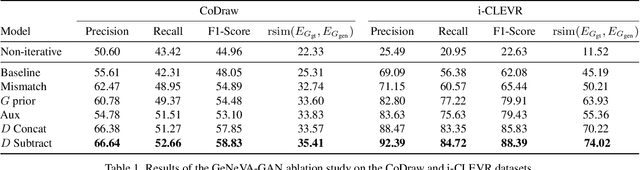

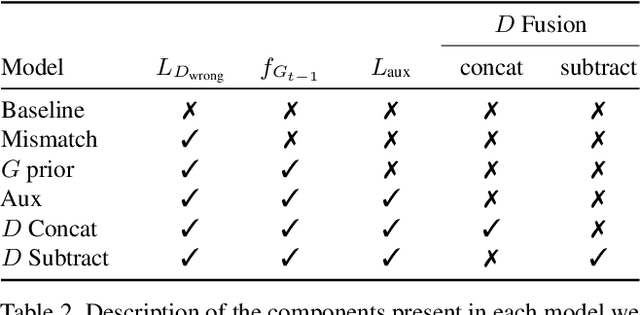
Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.