 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal and data-adaptive algorithms for model selection in linear contextual bandits
Nov 08, 2021

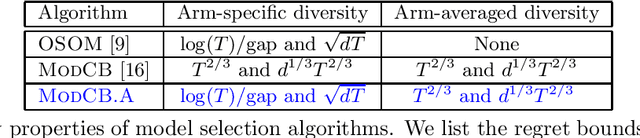
Model selection in contextual bandits is an important complementary problem to regret minimization with respect to a fixed model class. We consider the simplest non-trivial instance of model-selection: distinguishing a simple multi-armed bandit problem from a linear contextual bandit problem. Even in this instance, current state-of-the-art methods explore in a suboptimal manner and require strong "feature-diversity" conditions. In this paper, we introduce new algorithms that a) explore in a data-adaptive manner, and b) provide model selection guarantees of the form $\mathcal{O}(d^{\alpha} T^{1- \alpha})$ with no feature diversity conditions whatsoever, where $d$ denotes the dimension of the linear model and $T$ denotes the total number of rounds. The first algorithm enjoys a "best-of-both-worlds" property, recovering two prior results that hold under distinct distributional assumptions, simultaneously. The second removes distributional assumptions altogether, expanding the scope for tractable model selection. Our approach extends to model selection among nested linear contextual bandits under some additional assumptions.
Anti-Concentrated Confidence Bonuses for Scalable Exploration
Oct 21, 2021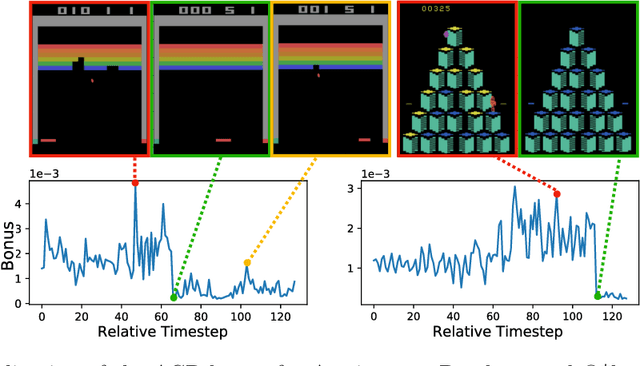
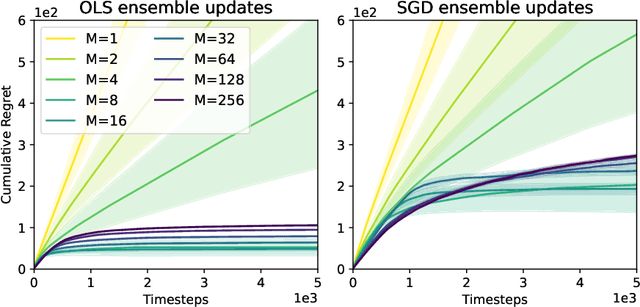


Intrinsic rewards play a central role in handling the exploration-exploitation trade-off when designing sequential decision-making algorithms, in both foundational theory and state-of-the-art deep reinforcement learning. The LinUCB algorithm, a centerpiece of the stochastic linear bandits literature, prescribes an elliptical bonus which addresses the challenge of leveraging shared information in large action spaces. This bonus scheme cannot be directly transferred to high-dimensional exploration problems, however, due to the computational cost of maintaining the inverse covariance matrix of action features. We introduce \emph{anti-concentrated confidence bounds} for efficiently approximating the elliptical bonus, using an ensemble of regressors trained to predict random noise from policy network-derived features. Using this approximation, we obtain stochastic linear bandit algorithms which obtain $\tilde O(d \sqrt{T})$ regret bounds for $\mathrm{poly}(d)$ fixed actions. We develop a practical variant for deep reinforcement learning that is competitive with contemporary intrinsic reward heuristics on Atari benchmarks.
Provable RL with Exogenous Distractors via Multistep Inverse Dynamics
Oct 17, 2021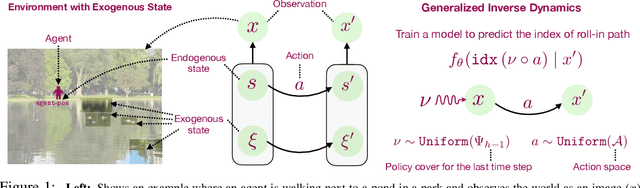

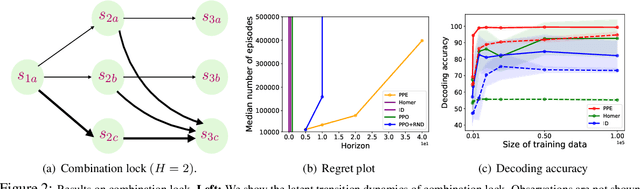
Many real-world applications of reinforcement learning (RL) require the agent to deal with high-dimensional observations such as those generated from a megapixel camera. Prior work has addressed such problems with representation learning, through which the agent can provably extract endogenous, latent state information from raw observations and subsequently plan efficiently. However, such approaches can fail in the presence of temporally correlated noise in the observations, a phenomenon that is common in practice. We initiate the formal study of latent state discovery in the presence of such exogenous noise sources by proposing a new model, the Exogenous Block MDP (EX-BMDP), for rich observation RL. We start by establishing several negative results, by highlighting failure cases of prior representation learning based approaches. Then, we introduce the Predictive Path Elimination (PPE) algorithm, that learns a generalization of inverse dynamics and is provably sample and computationally efficient in EX-BMDPs when the endogenous state dynamics are near deterministic. The sample complexity of PPE depends polynomially on the size of the latent endogenous state space while not directly depending on the size of the observation space, nor the exogenous state space. We provide experiments on challenging exploration problems which show that our approach works empirically.
Sparsity in Partially Controllable Linear Systems
Oct 12, 2021
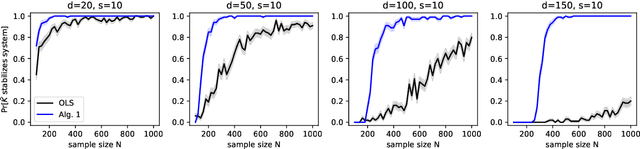
A fundamental concept in control theory is that of controllability, where any system state can be reached through an appropriate choice of control inputs. Indeed, a large body of classical and modern approaches are designed for controllable linear dynamical systems. However, in practice, we often encounter systems in which a large set of state variables evolve exogenously and independently of the control inputs; such systems are only \emph{partially controllable}. The focus of this work is on a large class of partially controllable linear dynamical systems, specified by an underlying sparsity pattern. Our main results establish structural conditions and finite-sample guarantees for learning to control such systems. In particular, our structural results characterize those state variables which are irrelevant for optimal control, an analysis which departs from classical control techniques. Our algorithmic results adapt techniques from high-dimensional statistics -- specifically soft-thresholding and semiparametric least-squares -- to exploit the underlying sparsity pattern in order to obtain finite-sample guarantees that significantly improve over those based on certainty-equivalence. We also corroborate these theoretical improvements over certainty-equivalent control through a simulation study.
Efficient First-Order Contextual Bandits: Prediction, Allocation, and Triangular Discrimination
Jul 05, 2021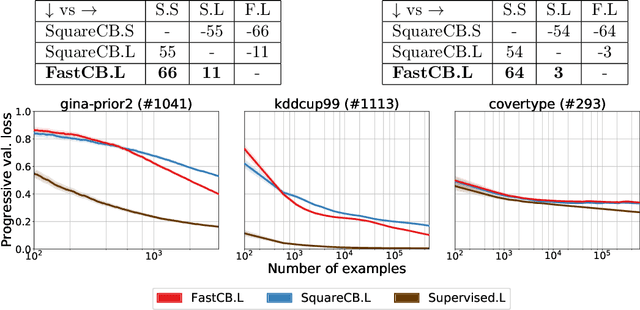
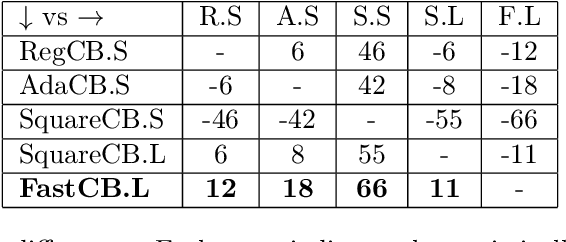
A recurring theme in statistical learning, online learning, and beyond is that faster convergence rates are possible for problems with low noise, often quantified by the performance of the best hypothesis; such results are known as first-order or small-loss guarantees. While first-order guarantees are relatively well understood in statistical and online learning, adapting to low noise in contextual bandits (and more broadly, decision making) presents major algorithmic challenges. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire asked whether first-order guarantees are even possible for contextual bandits and -- if so -- whether they can be attained by efficient algorithms. We give a resolution to this question by providing an optimal and efficient reduction from contextual bandits to online regression with the logarithmic (or, cross-entropy) loss. Our algorithm is simple and practical, readily accommodates rich function classes, and requires no distributional assumptions beyond realizability. In a large-scale empirical evaluation, we find that our approach typically outperforms comparable non-first-order methods. On the technical side, we show that the logarithmic loss and an information-theoretic quantity called the triangular discrimination play a fundamental role in obtaining first-order guarantees, and we combine this observation with new refinements to the regression oracle reduction framework of Foster and Rakhlin. The use of triangular discrimination yields novel results even for the classical statistical learning model, and we anticipate that it will find broader use.
Bayesian decision-making under misspecified priors with applications to meta-learning
Jul 03, 2021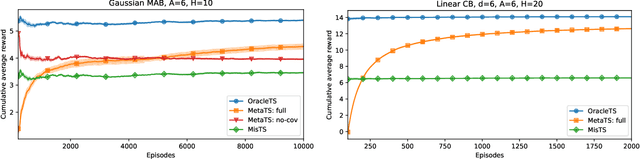
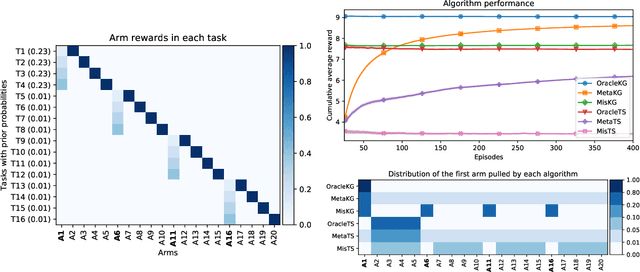
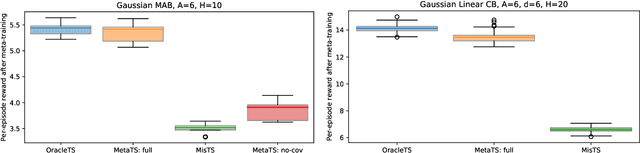
Thompson sampling and other Bayesian sequential decision-making algorithms are among the most popular approaches to tackle explore/exploit trade-offs in (contextual) bandits. The choice of prior in these algorithms offers flexibility to encode domain knowledge but can also lead to poor performance when misspecified. In this paper, we demonstrate that performance degrades gracefully with misspecification. We prove that the expected reward accrued by Thompson sampling (TS) with a misspecified prior differs by at most $\tilde{\mathcal{O}}(H^2 \epsilon)$ from TS with a well specified prior, where $\epsilon$ is the total-variation distance between priors and $H$ is the learning horizon. Our bound does not require the prior to have any parametric form. For priors with bounded support, our bound is independent of the cardinality or structure of the action space, and we show that it is tight up to universal constants in the worst case. Building on our sensitivity analysis, we establish generic PAC guarantees for algorithms in the recently studied Bayesian meta-learning setting and derive corollaries for various families of priors. Our results generalize along two axes: (1) they apply to a broader family of Bayesian decision-making algorithms, including a Monte-Carlo implementation of the knowledge gradient algorithm (KG), and (2) they apply to Bayesian POMDPs, the most general Bayesian decision-making setting, encompassing contextual bandits as a special case. Through numerical simulations, we illustrate how prior misspecification and the deployment of one-step look-ahead (as in KG) can impact the convergence of meta-learning in multi-armed and contextual bandits with structured and correlated priors.
Investigating the Role of Negatives in Contrastive Representation Learning
Jun 18, 2021
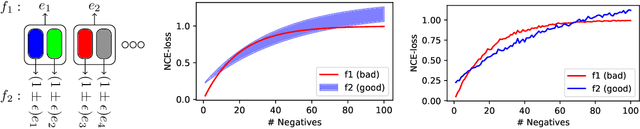
Noise contrastive learning is a popular technique for unsupervised representation learning. In this approach, a representation is obtained via reduction to supervised learning, where given a notion of semantic similarity, the learner tries to distinguish a similar (positive) example from a collection of random (negative) examples. The success of modern contrastive learning pipelines relies on many parameters such as the choice of data augmentation, the number of negative examples, and the batch size; however, there is limited understanding as to how these parameters interact and affect downstream performance. We focus on disambiguating the role of one of these parameters: the number of negative examples. Theoretically, we show the existence of a collision-coverage trade-off suggesting that the optimal number of negative examples should scale with the number of underlying concepts in the data. Empirically, we scrutinize the role of the number of negatives in both NLP and vision tasks. In the NLP task, we find that the results broadly agree with our theory, while our vision experiments are murkier with performance sometimes even being insensitive to the number of negatives. We discuss plausible explanations for this behavior and suggest future directions to better align theory and practice.
Gone Fishing: Neural Active Learning with Fisher Embeddings
Jun 17, 2021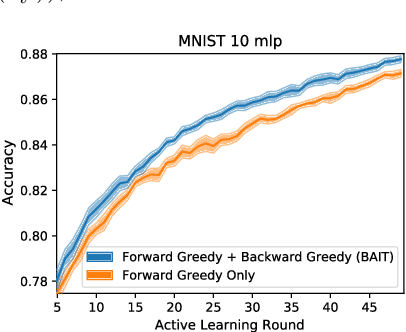
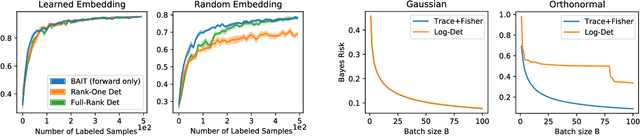
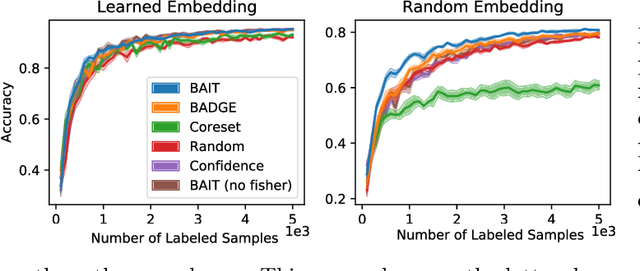
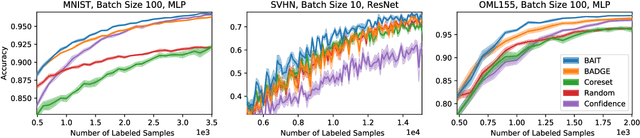
There is an increasing need for effective active learning algorithms that are compatible with deep neural networks. While there are many classic, well-studied sample selection methods, the non-convexity and varying internal representation of neural models make it unclear how to extend these approaches. This article introduces BAIT, a practical, tractable, and high-performing active learning algorithm for neural networks that addresses these concerns. BAIT draws inspiration from the theoretical analysis of maximum likelihood estimators (MLE) for parametric models. It selects batches of samples by optimizing a bound on the MLE error in terms of the Fisher information, which we show can be implemented efficiently at scale by exploiting linear-algebraic structure especially amenable to execution on modern hardware. Our experiments show that BAIT outperforms the previous state of the art on both classification and regression problems, and is flexible enough to be used with a variety of model architectures.
Model-free Representation Learning and Exploration in Low-rank MDPs
Feb 14, 2021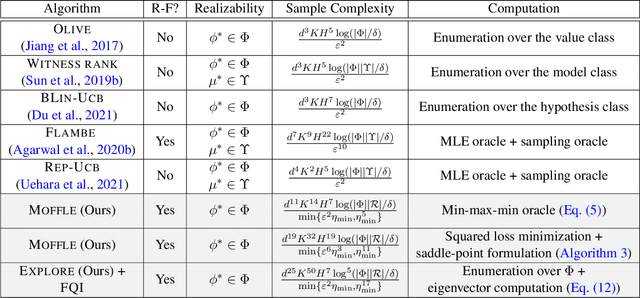
The low rank MDP has emerged as an important model for studying representation learning and exploration in reinforcement learning. With a known representation, several model-free exploration strategies exist. In contrast, all algorithms for the unknown representation setting are model-based, thereby requiring the ability to model the full dynamics. In this work, we present the first model-free representation learning algorithms for low rank MDPs. The key algorithmic contribution is a new minimax representation learning objective, for which we provide variants with differing tradeoffs in their statistical and computational properties. We interleave this representation learning step with an exploration strategy to cover the state space in a reward-free manner. The resulting algorithms are provably sample efficient and can accommodate general function approximation to scale to complex environments.
Learning the Linear Quadratic Regulator from Nonlinear Observations
Oct 08, 2020
We introduce a new problem setting for continuous control called the LQR with Rich Observations, or RichLQR. In our setting, the environment is summarized by a low-dimensional continuous latent state with linear dynamics and quadratic costs, but the agent operates on high-dimensional, nonlinear observations such as images from a camera. To enable sample-efficient learning, we assume that the learner has access to a class of decoder functions (e.g., neural networks) that is flexible enough to capture the mapping from observations to latent states. We introduce a new algorithm, RichID, which learns a near-optimal policy for the RichLQR with sample complexity scaling only with the dimension of the latent state space and the capacity of the decoder function class. RichID is oracle-efficient and accesses the decoder class only through calls to a least-squares regression oracle. Our results constitute the first provable sample complexity guarantee for continuous control with an unknown nonlinearity in the system model and general function approximation.