 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextWorld: A Learning Environment for Text-based Games
Jun 29, 2018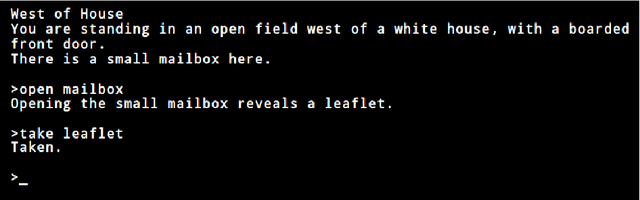
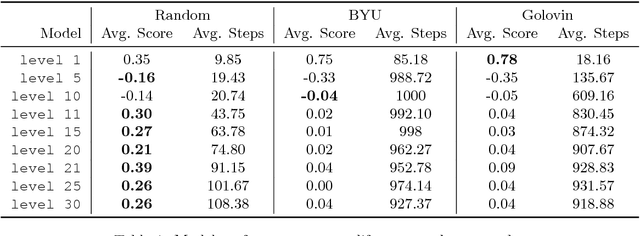

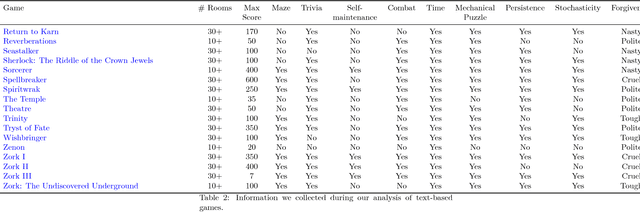
We introduce TextWorld, a sandbox learning environment for the training and evaluation of RL agents on text-based games. TextWorld is a Python library that handles interactive play-through of text games, as well as backend functions like state tracking and reward assignment. It comes with a curated list of games whose features and challenges we have analyzed. More significantly, it enables users to handcraft or automatically generate new games. Its generative mechanisms give precise control over the difficulty, scope, and language of constructed games, and can be used to relax challenges inherent to commercial text games like partial observability and sparse rewards. By generating sets of varied but similar games, TextWorld can also be used to study generalization and transfer learning. We cast text-based games in the Reinforcement Learning formalism, use our framework to develop a set of benchmark games, and evaluate several baseline agents on this set and the curated list.
Counting to Explore and Generalize in Text-based Games
Jun 29, 2018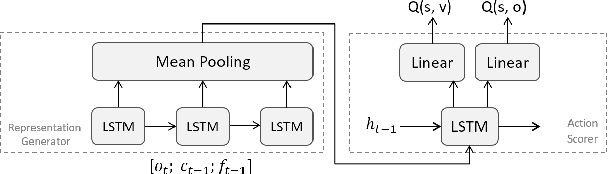
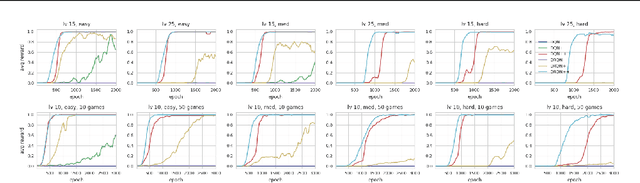

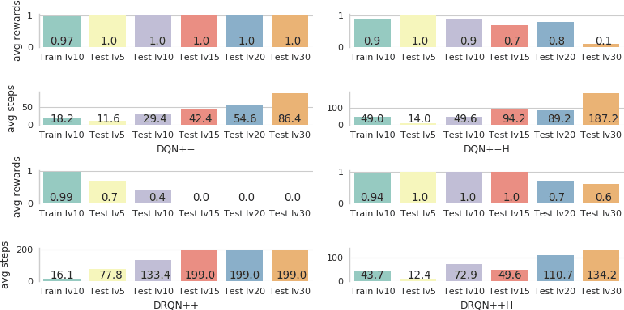
We propose a recurrent RL agent with an episodic exploration mechanism that helps discovering good policies in text-based game environments. We show promising results on a set of generated text-based games of varying difficulty where the goal is to collect a coin located at the end of a chain of rooms. In contrast to previous text-based RL approaches, we observe that our agent learns policies that generalize to unseen games of greater difficulty.
Focused Hierarchical RNNs for Conditional Sequence Processing
Jun 12, 2018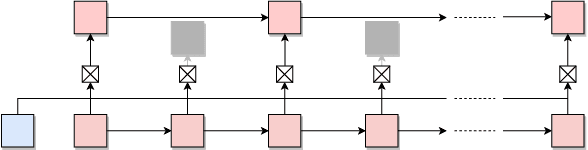
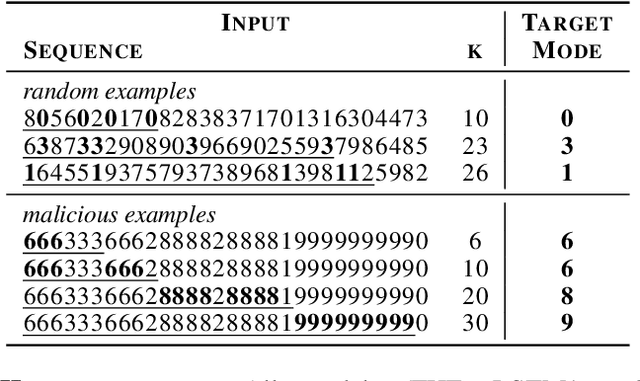
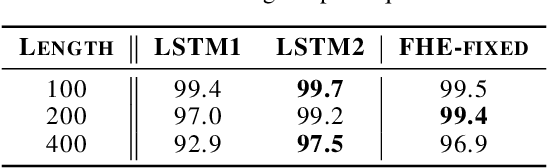
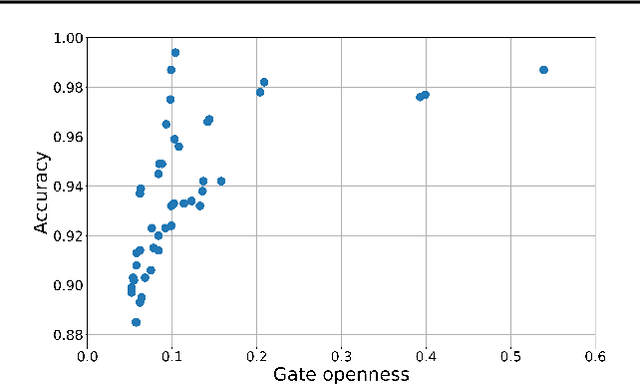
Recurrent Neural Networks (RNNs) with attention mechanisms have obtained state-of-the-art results for many sequence processing tasks. Most of these models use a simple form of encoder with attention that looks over the entire sequence and assigns a weight to each token independently. We present a mechanism for focusing RNN encoders for sequence modelling tasks which allows them to attend to key parts of the input as needed. We formulate this using a multi-layer conditional sequence encoder that reads in one token at a time and makes a discrete decision on whether the token is relevant to the context or question being asked. The discrete gating mechanism takes in the context embedding and the current hidden state as inputs and controls information flow into the layer above. We train it using policy gradient methods. We evaluate this method on several types of tasks with different attributes. First, we evaluate the method on synthetic tasks which allow us to evaluate the model for its generalization ability and probe the behavior of the gates in more controlled settings. We then evaluate this approach on large scale Question Answering tasks including the challenging MS MARCO and SearchQA tasks. Our models shows consistent improvements for both tasks over prior work and our baselines. It has also shown to generalize significantly better on synthetic tasks as compared to the baselines.
Neural Models for Key Phrase Detection and Question Generation
May 30, 2018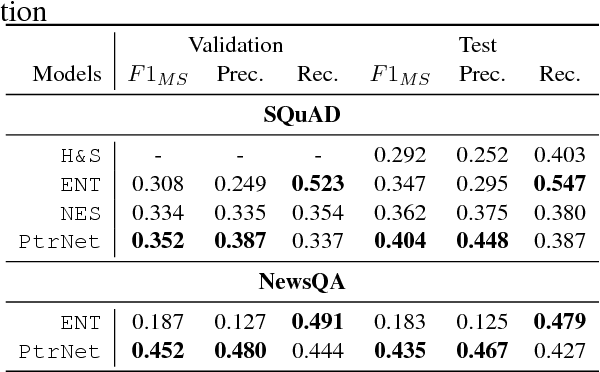


We propose a two-stage neural model to tackle question generation from documents. First, our model estimates the probability that word sequences in a document are ones that a human would pick when selecting candidate answers by training a neural key-phrase extractor on the answers in a question-answering corpus. Predicted key phrases then act as target answers and condition a sequence-to-sequence question-generation model with a copy mechanism. Empirically, our key-phrase extraction model significantly outperforms an entity-tagging baseline and existing rule-based approaches. We further demonstrate that our question generation system formulates fluent, answerable questions from key phrases. This two-stage system could be used to augment or generate reading comprehension datasets, which may be leveraged to improve machine reading systems or in educational settings.
Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning
Mar 30, 2018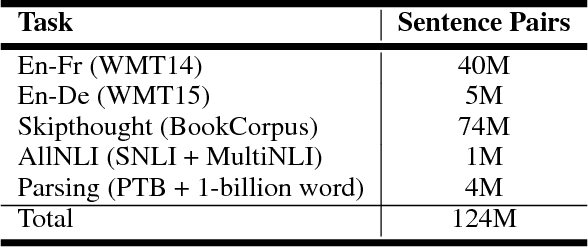
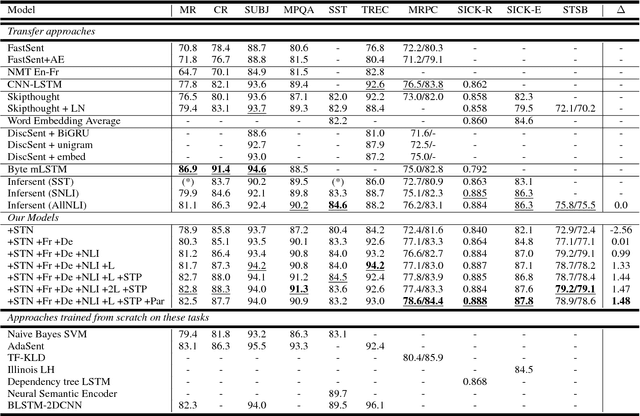
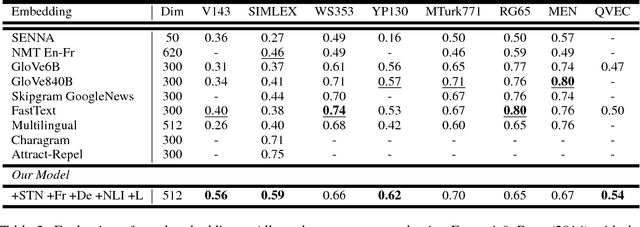
A lot of the recent success in natural language processing (NLP) has been driven by distributed vector representations of words trained on large amounts of text in an unsupervised manner. These representations are typically used as general purpose features for words across a range of NLP problems. However, extending this success to learning representations of sequences of words, such as sentences, remains an open problem. Recent work has explored unsupervised as well as supervised learning techniques with different training objectives to learn general purpose fixed-length sentence representations. In this work, we present a simple, effective multi-task learning framework for sentence representations that combines the inductive biases of diverse training objectives in a single model. We train this model on several data sources with multiple training objectives on over 100 million sentences. Extensive experiments demonstrate that sharing a single recurrent sentence encoder across weakly related tasks leads to consistent improvements over previous methods. We present substantial improvements in the context of transfer learning and low-resource settings using our learned general-purpose representations.
Twin Networks: Matching the Future for Sequence Generation
Feb 23, 2018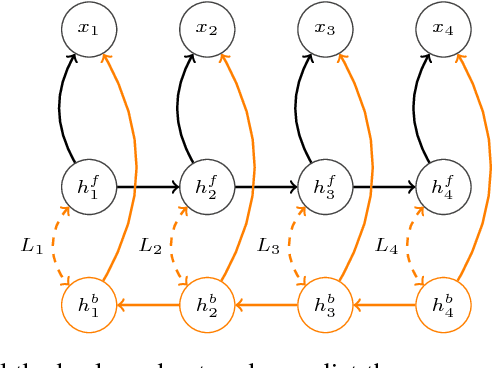

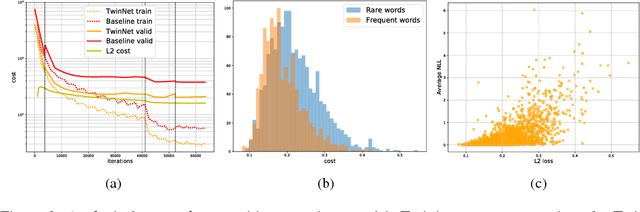
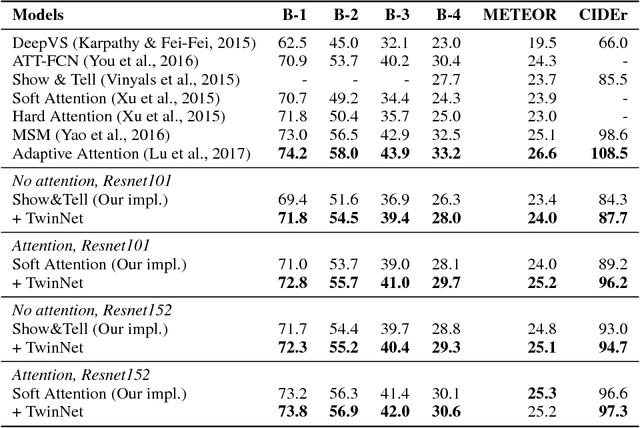
We propose a simple technique for encouraging generative RNNs to plan ahead. We train a "backward" recurrent network to generate a given sequence in reverse order, and we encourage states of the forward model to predict cotemporal states of the backward model. The backward network is used only during training, and plays no role during sampling or inference. We hypothesize that our approach eases modeling of long-term dependencies by implicitly forcing the forward states to hold information about the longer-term future (as contained in the backward states). We show empirically that our approach achieves 9% relative improvement for a speech recognition task, and achieves significant improvement on a COCO caption generation task.
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Feb 22, 2018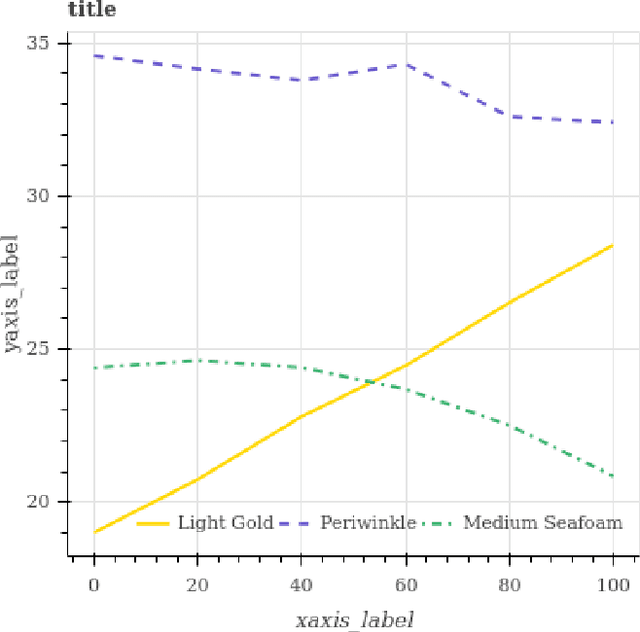


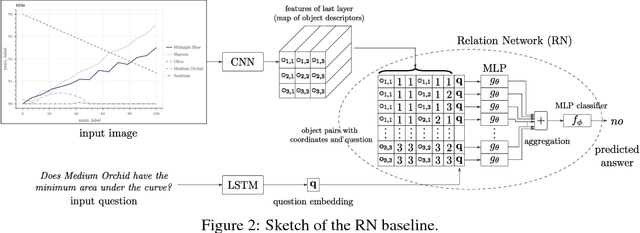
We introduce FigureQA, a visual reasoning corpus of over one million question-answer pairs grounded in over 100,000 images. The images are synthetic, scientific-style figures from five classes: line plots, dot-line plots, vertical and horizontal bar graphs, and pie charts. We formulate our reasoning task by generating questions from 15 templates; questions concern various relationships between plot elements and examine characteristics like the maximum, the minimum, area-under-the-curve, smoothness, and intersection. To resolve, such questions often require reference to multiple plot elements and synthesis of information distributed spatially throughout a figure. To facilitate the training of machine learning systems, the corpus also includes side data that can be used to formulate auxiliary objectives. In particular, we provide the numerical data used to generate each figure as well as bounding-box annotations for all plot elements. We study the proposed visual reasoning task by training several models, including the recently proposed Relation Network as a strong baseline. Preliminary results indicate that the task poses a significant machine learning challenge. We envision FigureQA as a first step towards developing models that can intuitively recognize patterns from visual representations of data.
Boundary-Seeking Generative Adversarial Networks
Feb 21, 2018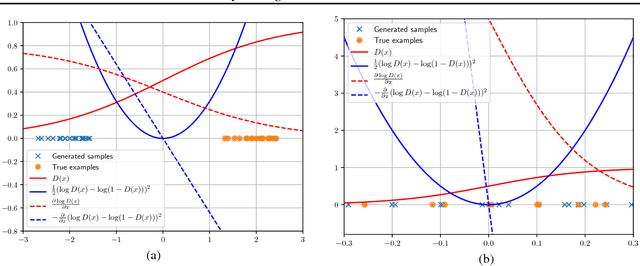

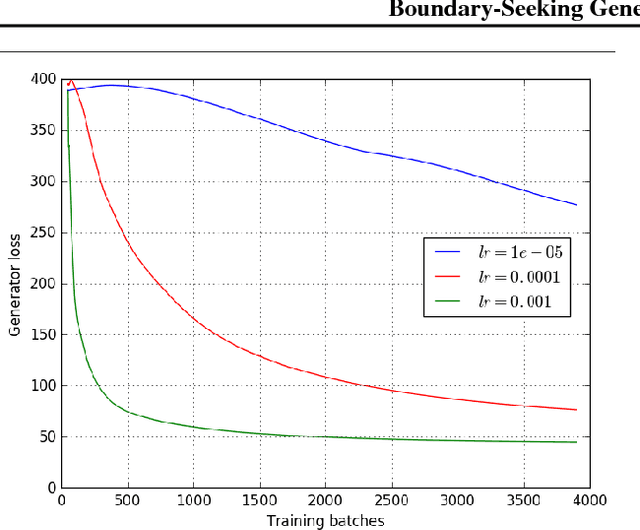
Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.
Plan, Attend, Generate: Planning for Sequence-to-Sequence Models
Nov 28, 2017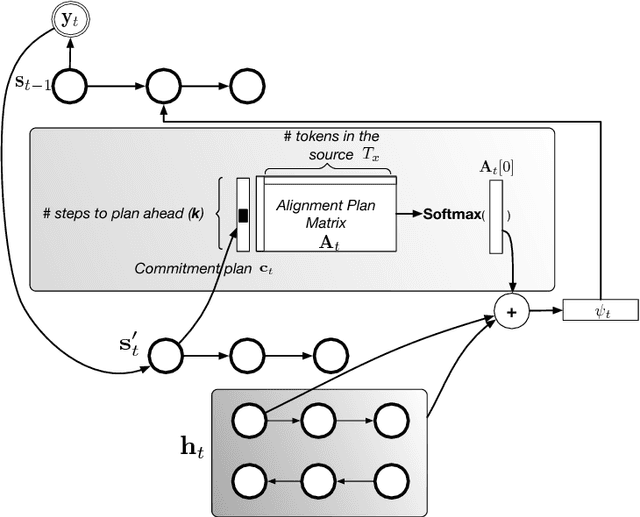
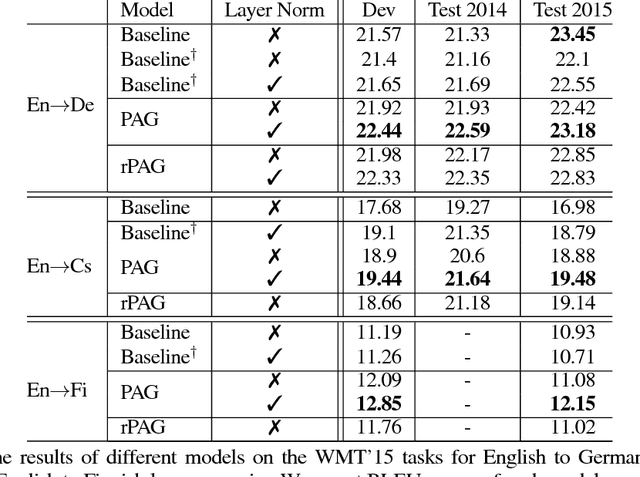

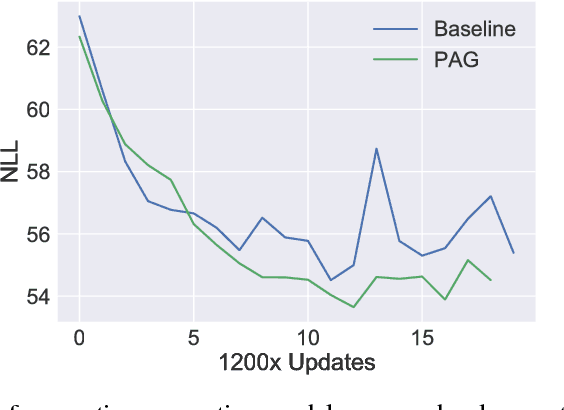
We investigate the integration of a planning mechanism into sequence-to-sequence models using attention. We develop a model which can plan ahead in the future when it computes its alignments between input and output sequences, constructing a matrix of proposed future alignments and a commitment vector that governs whether to follow or recompute the plan. This mechanism is inspired by the recently proposed strategic attentive reader and writer (STRAW) model for Reinforcement Learning. Our proposed model is end-to-end trainable using primarily differentiable operations. We show that it outperforms a strong baseline on character-level translation tasks from WMT'15, the algorithmic task of finding Eulerian circuits of graphs, and question generation from the text. Our analysis demonstrates that the model computes qualitatively intuitive alignments, converges faster than the baselines, and achieves superior performance with fewer parameters.
Variational Bi-LSTMs
Nov 15, 2017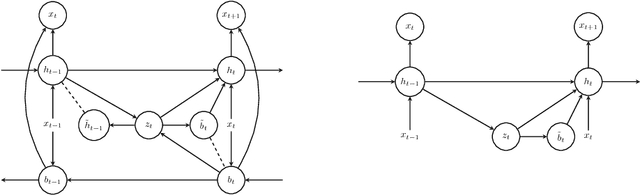
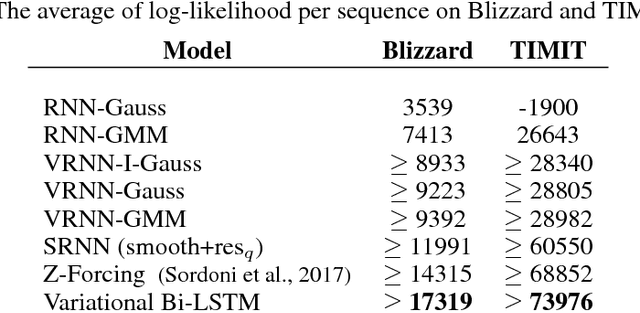
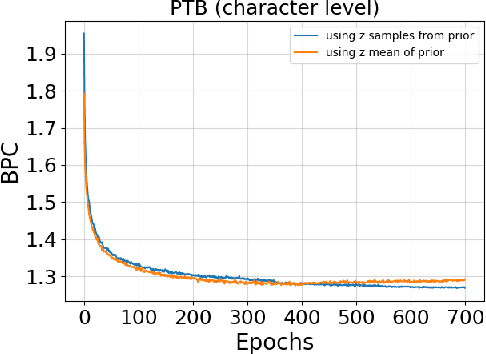
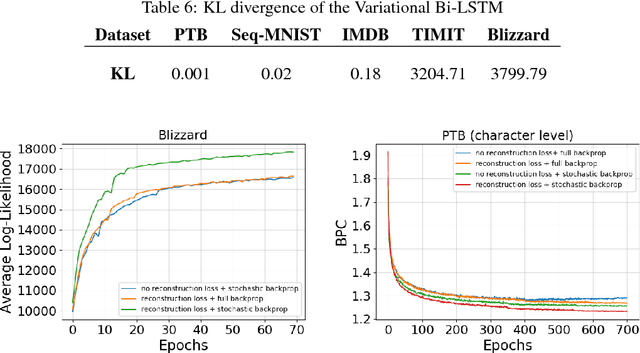
Recurrent neural networks like long short-term memory (LSTM) are important architectures for sequential prediction tasks. LSTMs (and RNNs in general) model sequences along the forward time direction. Bidirectional LSTMs (Bi-LSTMs) on the other hand model sequences along both forward and backward directions and are generally known to perform better at such tasks because they capture a richer representation of the data. In the training of Bi-LSTMs, the forward and backward paths are learned independently. We propose a variant of the Bi-LSTM architecture, which we call Variational Bi-LSTM, that creates a channel between the two paths (during training, but which may be omitted during inference); thus optimizing the two paths jointly. We arrive at this joint objective for our model by minimizing a variational lower bound of the joint likelihood of the data sequence. Our model acts as a regularizer and encourages the two networks to inform each other in making their respective predictions using distinct information. We perform ablation studies to better understand the different components of our model and evaluate the method on various benchmarks, showing state-of-the-art performance.