 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Language Modeling using Perceptually-Guided Discrete Representations
Nov 04, 2022In this work, we study the task of Audio Language Modeling, in which we aim at learning probabilistic models for audio that can be used for generation and completion. We use a state-of-the-art perceptually-guided audio compression model, to encode audio to discrete representations. Next, we train a transformer-based causal language model using these representations. At inference time, we perform audio auto-completion by encoding an audio prompt as a discrete sequence, feeding it to the audio language model, sampling from the model, and synthesizing the corresponding time-domain signal. We evaluate the quality of samples generated by our method on Audioset, the largest dataset for general audio to date, and show that it is superior to the evaluated baseline audio encoders. We additionally provide an extensive analysis to better understand the trade-off between audio-quality and language-modeling capabilities. Samples:link.
AudioGen: Textually Guided Audio Generation
Sep 30, 2022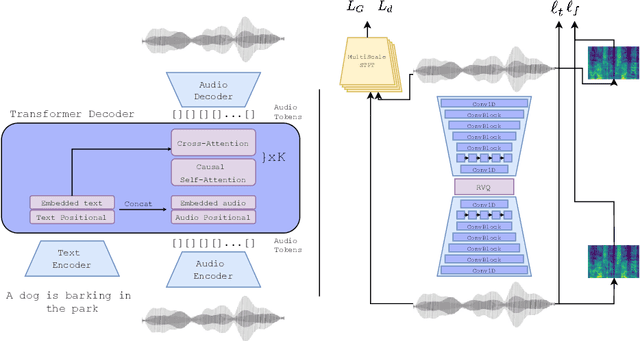
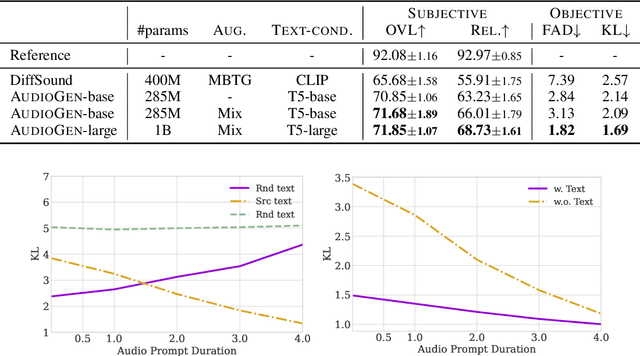
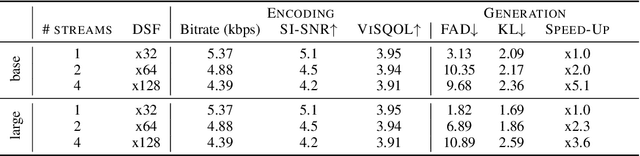
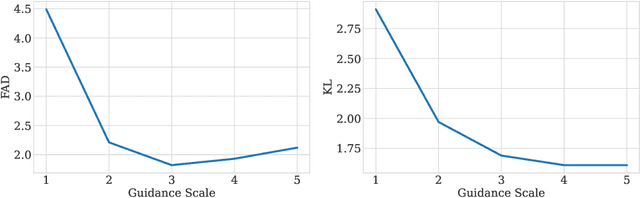
We tackle the problem of generating audio samples conditioned on descriptive text captions. In this work, we propose AaudioGen, an auto-regressive generative model that generates audio samples conditioned on text inputs. AudioGen operates on a learnt discrete audio representation. The task of text-to-audio generation poses multiple challenges. Due to the way audio travels through a medium, differentiating ``objects'' can be a difficult task (e.g., separating multiple people simultaneously speaking). This is further complicated by real-world recording conditions (e.g., background noise, reverberation, etc.). Scarce text annotations impose another constraint, limiting the ability to scale models. Finally, modeling high-fidelity audio requires encoding audio at high sampling rate, leading to extremely long sequences. To alleviate the aforementioned challenges we propose an augmentation technique that mixes different audio samples, driving the model to internally learn to separate multiple sources. We curated 10 datasets containing different types of audio and text annotations to handle the scarcity of text-audio data points. For faster inference, we explore the use of multi-stream modeling, allowing the use of shorter sequences while maintaining a similar bitrate and perceptual quality. We apply classifier-free guidance to improve adherence to text. Comparing to the evaluated baselines, AudioGen outperforms over both objective and subjective metrics. Finally, we explore the ability of the proposed method to generate audio continuation conditionally and unconditionally. Samples: https://tinyurl.com/audiogen-text2audio
Make-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

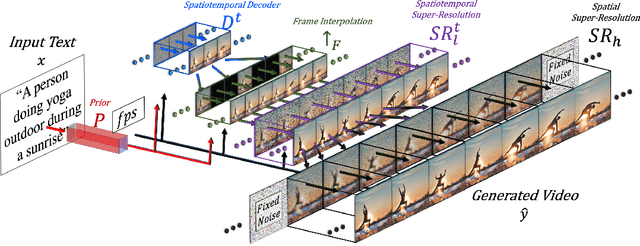
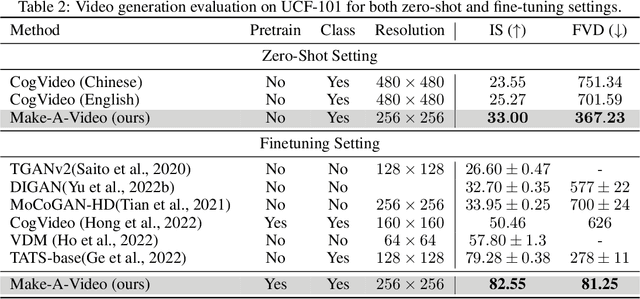
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022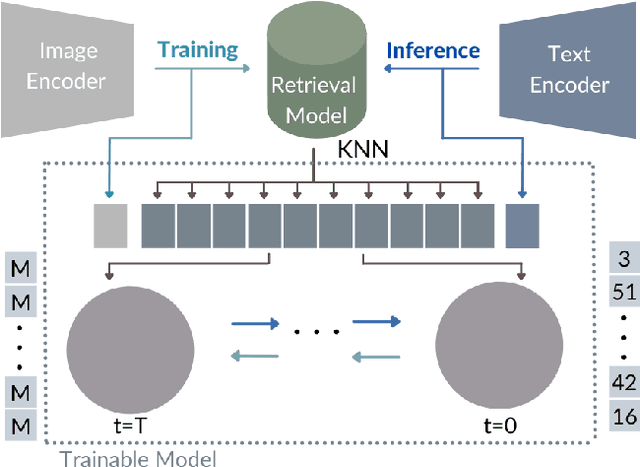
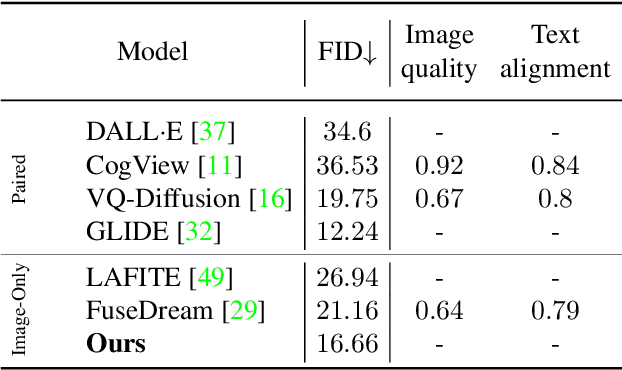
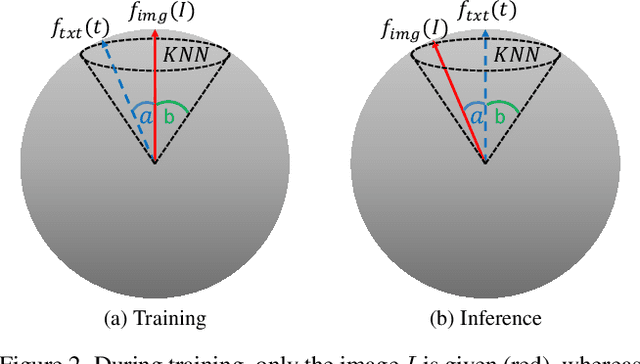

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Mar 24, 2022

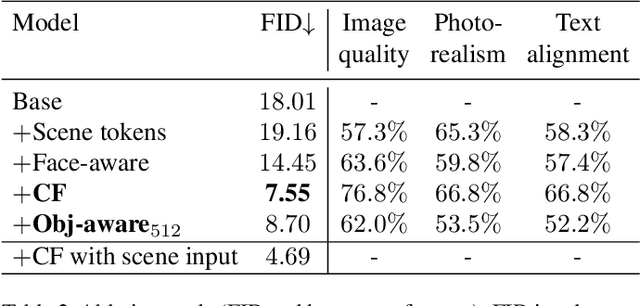

Recent text-to-image generation methods provide a simple yet exciting conversion capability between text and image domains. While these methods have incrementally improved the generated image fidelity and text relevancy, several pivotal gaps remain unanswered, limiting applicability and quality. We propose a novel text-to-image method that addresses these gaps by (i) enabling a simple control mechanism complementary to text in the form of a scene, (ii) introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions (faces and salient objects), and (iii) adapting classifier-free guidance for the transformer use case. Our model achieves state-of-the-art FID and human evaluation results, unlocking the ability to generate high fidelity images in a resolution of 512x512 pixels, significantly improving visual quality. Through scene controllability, we introduce several new capabilities: (i) Scene editing, (ii) text editing with anchor scenes, (iii) overcoming out-of-distribution text prompts, and (iv) story illustration generation, as demonstrated in the story we wrote.
Locally Shifted Attention With Early Global Integration
Dec 22, 2021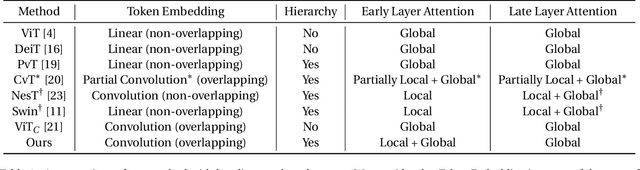

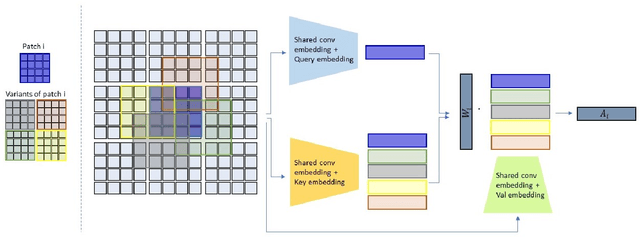
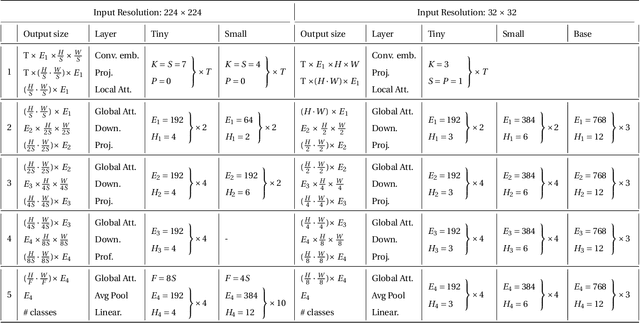
Recent work has shown the potential of transformers for computer vision applications. An image is first partitioned into patches, which are then used as input tokens for the attention mechanism. Due to the expensive quadratic cost of the attention mechanism, either a large patch size is used, resulting in coarse-grained global interactions, or alternatively, attention is applied only on a local region of the image, at the expense of long-range interactions. In this work, we propose an approach that allows for both coarse global interactions and fine-grained local interactions already at early layers of a vision transformer. At the core of our method is the application of local and global attention layers. In the local attention layer, we apply attention to each patch and its local shifts, resulting in virtually located local patches, which are not bound to a single, specific location. These virtually located patches are then used in a global attention layer. The separation of the attention layer into local and global counterparts allows for a low computational cost in the number of patches, while still supporting data-dependent localization already at the first layer, as opposed to the static positioning in other visual transformers. Our method is shown to be superior to both convolutional and transformer-based methods for image classification on CIFAR10, CIFAR100, and ImageNet. Code is available at: https://github.com/shellysheynin/Locally-SAG-Transformer.
Textless Speech Emotion Conversion using Decomposed and Discrete Representations
Nov 14, 2021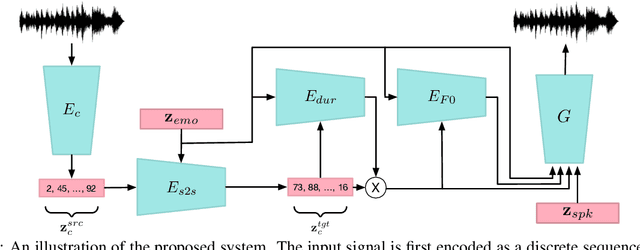
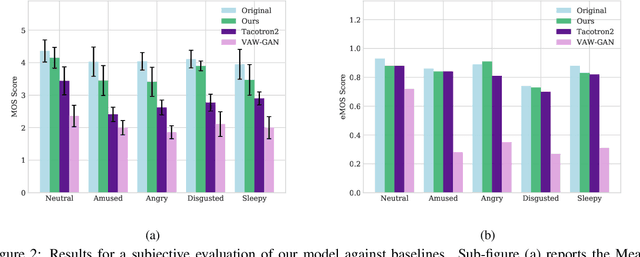
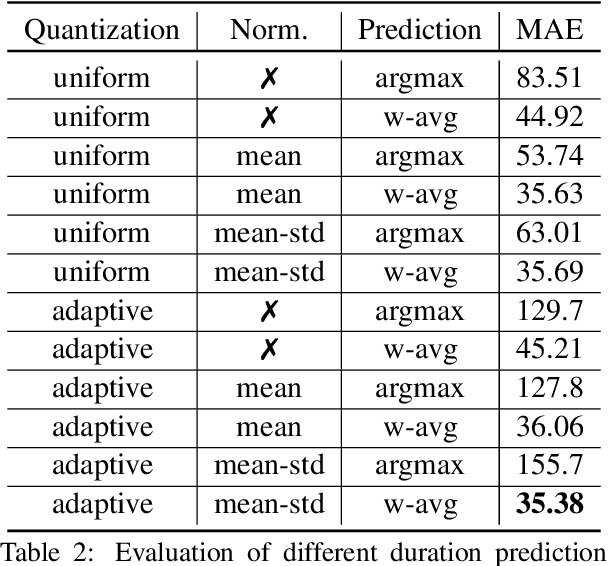
Speech emotion conversion is the task of modifying the perceived emotion of a speech utterance while preserving the lexical content and speaker identity. In this study, we cast the problem of emotion conversion as a spoken language translation task. We decompose speech into discrete and disentangled learned representations, consisting of content units, F0, speaker, and emotion. First, we modify the speech content by translating the content units to a target emotion, and then predict the prosodic features based on these units. Finally, the speech waveform is generated by feeding the predicted representations into a neural vocoder. Such a paradigm allows us to go beyond spectral and parametric changes of the signal, and model non-verbal vocalizations, such as laughter insertion, yawning removal, etc. We demonstrate objectively and subjectively that the proposed method is superior to the baselines in terms of perceived emotion and audio quality. We rigorously evaluate all components of such a complex system and conclude with an extensive model analysis and ablation study to better emphasize the architectural choices, strengths and weaknesses of the proposed method. Samples and code will be publicly available under the following link: https://speechbot.github.io/emotion.
fairseq S^2: A Scalable and Integrable Speech Synthesis Toolkit
Sep 14, 2021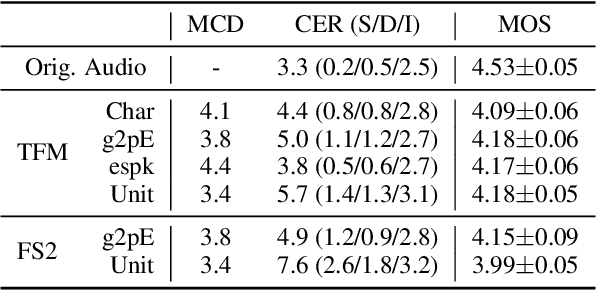
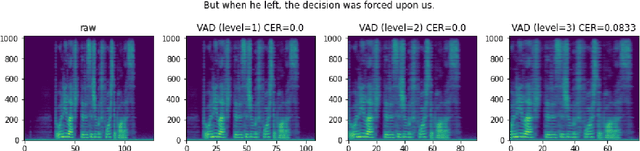

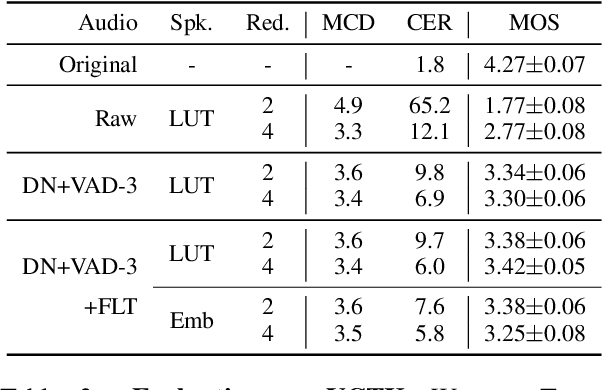
This paper presents fairseq S^2, a fairseq extension for speech synthesis. We implement a number of autoregressive (AR) and non-AR text-to-speech models, and their multi-speaker variants. To enable training speech synthesis models with less curated data, a number of preprocessing tools are built and their importance is shown empirically. To facilitate faster iteration of development and analysis, a suite of automatic metrics is included. Apart from the features added specifically for this extension, fairseq S^2 also benefits from the scalability offered by fairseq and can be easily integrated with other state-of-the-art systems provided in this framework. The code, documentation, and pre-trained models are available at https://github.com/pytorch/fairseq/tree/master/examples/speech_synthesis.
Text-Free Prosody-Aware Generative Spoken Language Modeling
Sep 07, 2021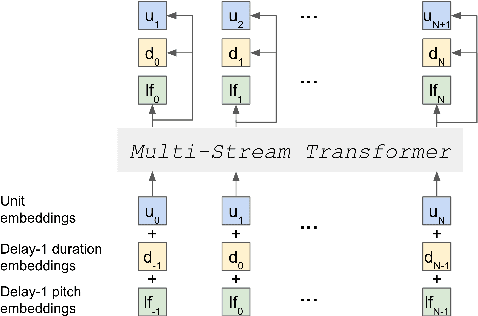
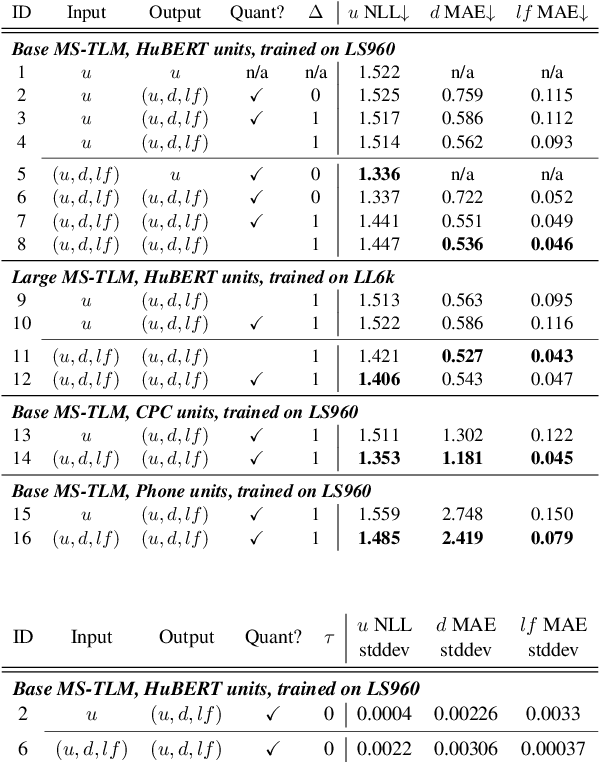
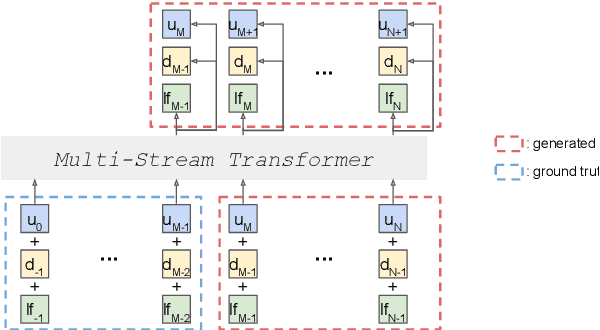
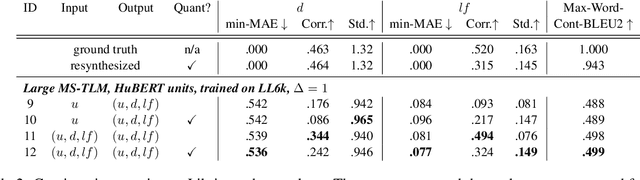
Speech pre-training has primarily demonstrated efficacy on classification tasks, while its capability of generating novel speech, similar to how GPT-2 can generate coherent paragraphs, has barely been explored. Generative Spoken Language Modeling (GSLM) (Lakhotia et al., 2021) is the only prior work addressing the generative aspects of speech pre-training, which replaces text with discovered phone-like units for language modeling and shows the ability to generate meaningful novel sentences. Unfortunately, despite eliminating the need of text, the units used in GSLM discard most of the prosodic information. Hence, GSLM fails to leverage prosody for better comprehension, and does not generate expressive speech. In this work, we present a prosody-aware generative spoken language model (pGSLM). It is composed of a multi-stream transformer language model (MS-TLM) of speech, represented as discovered unit and prosodic feature streams, and an adapted HiFi-GAN model converting MS-TLM outputs to waveforms. We devise a series of metrics for prosody modeling and generation, and re-use metrics from GSLM for content modeling. Experimental results show that the pGSLM can utilize prosody to improve both prosody and content modeling, and also generate natural, meaningful, and coherent speech given a spoken prompt. Audio samples can be found at https://speechbot.github.io/pgslm.
Direct speech-to-speech translation with discrete units
Jul 12, 2021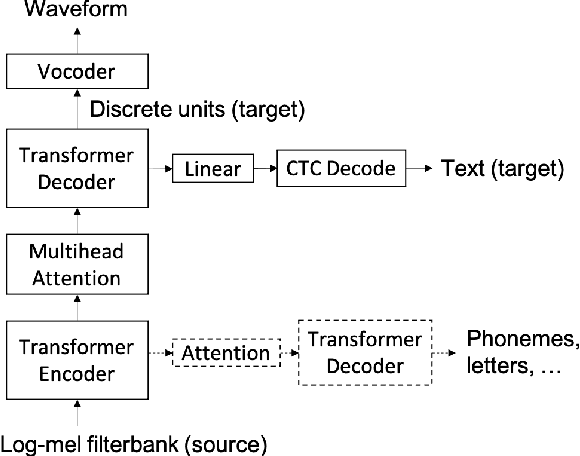
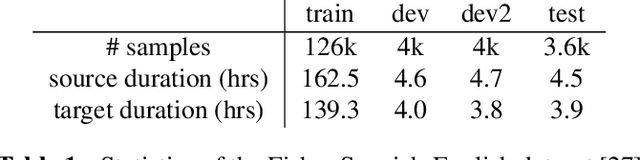
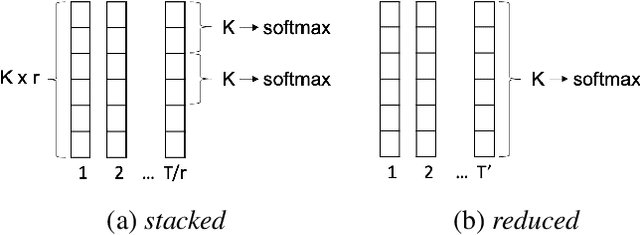
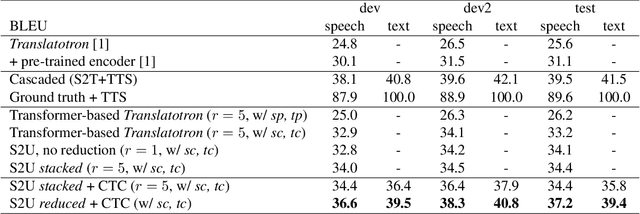
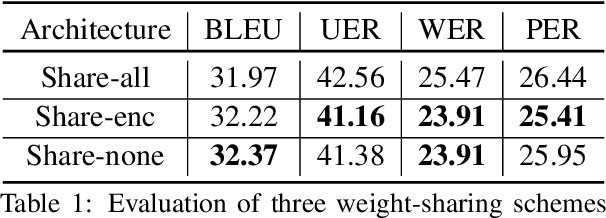
We present a direct speech-to-speech translation (S2ST) model that translates speech from one language to speech in another language without relying on intermediate text generation. Previous work addresses the problem by training an attention-based sequence-to-sequence model that maps source speech spectrograms into target spectrograms. To tackle the challenge of modeling continuous spectrogram features of the target speech, we propose to predict the self-supervised discrete representations learned from an unlabeled speech corpus instead. When target text transcripts are available, we design a multitask learning framework with joint speech and text training that enables the model to generate dual mode output (speech and text) simultaneously in the same inference pass. Experiments on the Fisher Spanish-English dataset show that predicting discrete units and joint speech and text training improve model performance by 11 BLEU compared with a baseline that predicts spectrograms and bridges 83% of the performance gap towards a cascaded system. When trained without any text transcripts, our model achieves similar performance as a baseline that predicts spectrograms and is trained with text data.