 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magni Human Motion Dataset: Accurate, Complex, Multi-Modal, Natural, Semantically-Rich and Contextualized
Aug 31, 2022
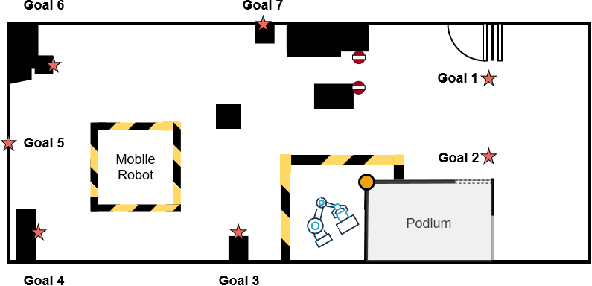

Rapid development of social robots stimulates active research in human motion modeling, interpretation and prediction, proactive collision avoidance, human-robot interaction and co-habitation in shared spaces. Modern approaches to this end require high quality datasets for training and evaluation. However, the majority of available datasets suffers from either inaccurate tracking data or unnatural, scripted behavior of the tracked people. This paper attempts to fill this gap by providing high quality tracking information from motion capture, eye-gaze trackers and on-board robot sensors in a semantically-rich environment. To induce natural behavior of the recorded participants, we utilise loosely scripted task assignment, which induces the participants navigate through the dynamic laboratory environment in a natural and purposeful way. The motion dataset, presented in this paper, sets a high quality standard, as the realistic and accurate data is enhanced with semantic information, enabling development of new algorithms which rely not only on the tracking information but also on contextual cues of the moving agents, static and dynamic environment.
The Atlas Benchmark: an Automated Evaluation Framework for Human Motion Prediction
Jul 20, 2022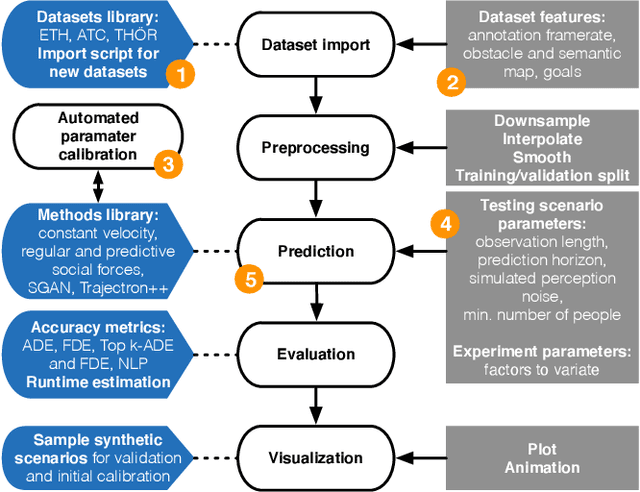
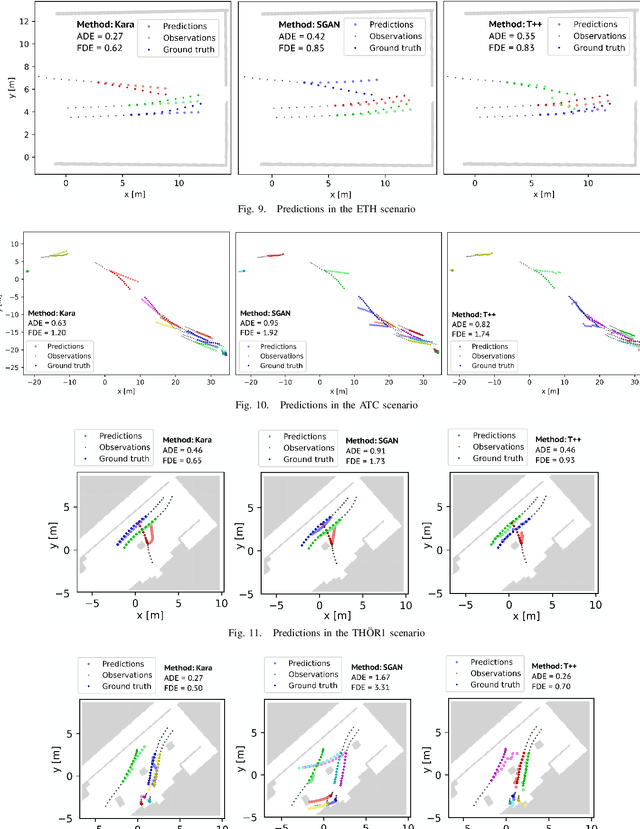
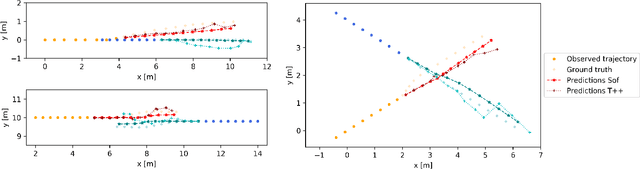
Human motion trajectory prediction, an essential task for autonomous systems in many domains, has been on the rise in recent years. With a multitude of new methods proposed by different communities, the lack of standardized benchmarks and objective comparisons is increasingly becoming a major limitation to assess progress and guide further research. Existing benchmarks are limited in their scope and flexibility to conduct relevant experiments and to account for contextual cues of agents and environments. In this paper we present Atlas, a benchmark to systematically evaluate human motion trajectory prediction algorithms in a unified framework. Atlas offers data preprocessing functions, hyperparameter optimization, comes with popular datasets and has the flexibility to setup and conduct underexplored yet relevant experiments to analyze a method's accuracy and robustness. In an example application of Atlas, we compare five popular model- and learning-based predictors and find that, when properly applied, early physics-based approaches are still remarkably competitive. Such results confirm the necessity of benchmarks like Atlas.
CorAl: Introspection for Robust Radar and Lidar Perception in Diverse Environments Using Differential Entropy
May 12, 2022
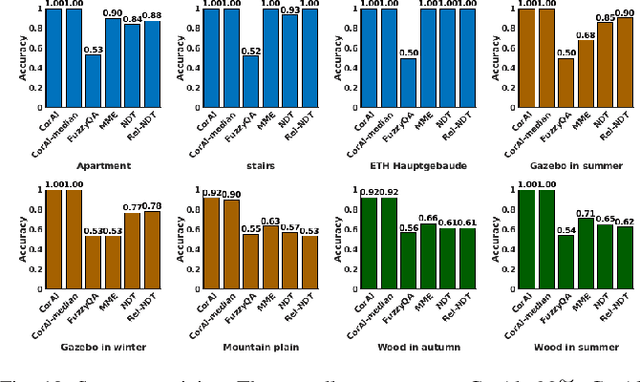
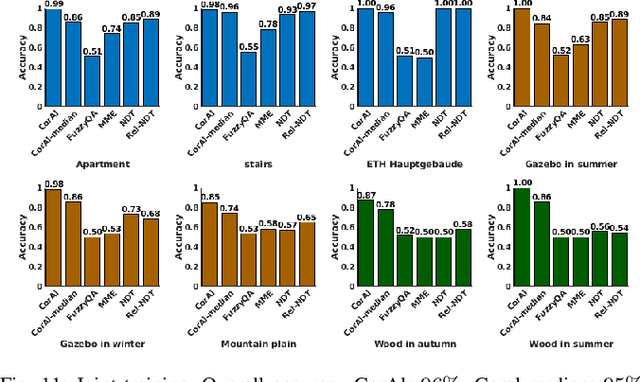
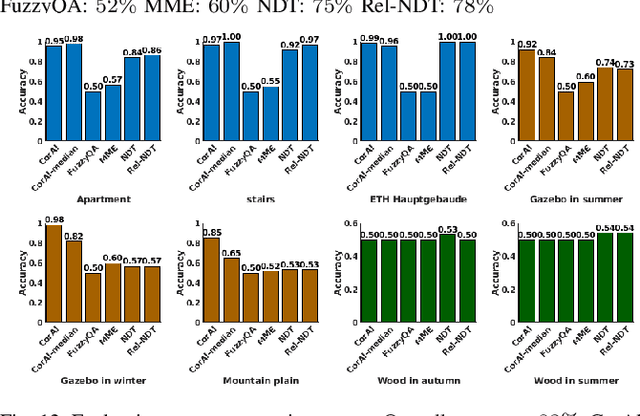
Robust perception is an essential component to enable long-term operation of mobile robots. It depends on failure resilience through reliable sensor data and preprocessing, as well as failure awareness through introspection, for example the ability to self-assess localization performance. This paper presents CorAl: a principled, intuitive, and generalizable method to measure the quality of alignment between pairs of point clouds, which learns to detect alignment errors in a self-supervised manner. CorAl compares the differential entropy in the point clouds separately with the entropy in their union to account for entropy inherent to the scene. By making use of dual entropy measurements, we obtain a quality metric that is highly sensitive to small alignment errors and still generalizes well to unseen environments. In this work, we extend our previous work on lidar-only CorAl to radar data by proposing a two-stage filtering technique that produces high-quality point clouds from noisy radar scans. Thus we target robust perception in two ways: by introducing a method that introspectively assesses alignment quality, and applying it to an inherently robust sensor modality. We show that our filtering technique combined with CorAl can be applied to the problem of alignment classification, and that it detects small alignment errors in urban settings with up to 98% accuracy, and with up to 96% if trained only in a different environment. Our lidar and radar experiments demonstrate that CorAl outperforms previous methods both on the ETH lidar benchmark, which includes several indoor and outdoor environments, and the large-scale Oxford and MulRan radar data sets for urban traffic scenarios The results also demonstrate that CorAl generalizes very well across substantially different environments without the need of retraining.
Oriented surface points for efficient and accurate radar odometry
Sep 21, 2021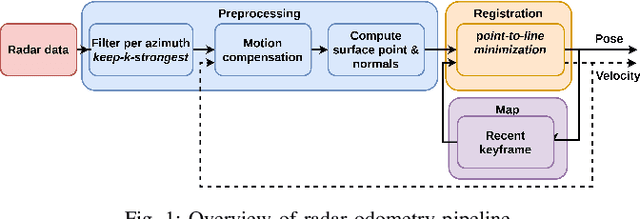
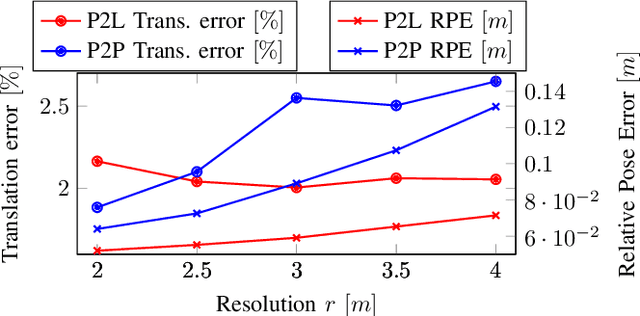


This paper presents an efficient and accurate radar odometry pipeline for large-scale localization. We propose a radar filter that keeps only the strongest reflections per-azimuth that exceeds the expected noise level. The filtered radar data is used to incrementally estimate odometry by registering the current scan with a nearby keyframe. By modeling local surfaces, we were able to register scans by minimizing a point-to-line metric and accurately estimate odometry from sparse point sets, hence improving efficiency. Specifically, we found that a point-to-line metric yields significant improvements compared to a point-to-point metric when matching sparse sets of surface points. Preliminary results from an urban odometry benchmark show that our odometry pipeline is accurate and efficient compared to existing methods with an overall translation error of 2.05%, down from 2.78% from the previously best published method, running at 12.5ms per frame without need of environmental specific training.
CorAl -- Are the point clouds Correctly Aligned?
Sep 20, 2021

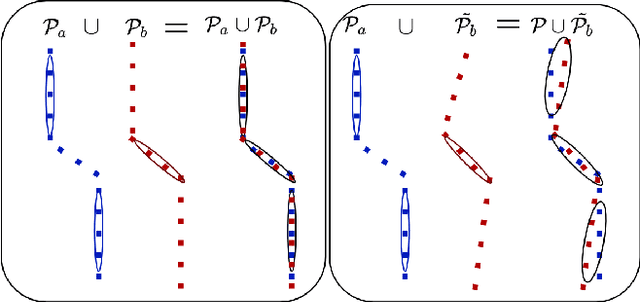
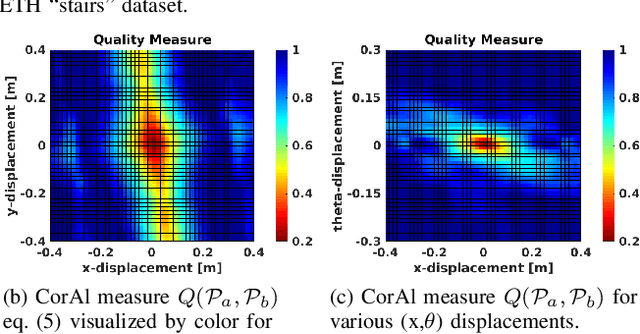
In robotics perception, numerous tasks rely on point cloud registration. However, currently there is no method that can automatically detect misaligned point clouds reliably and without environment-specific parameters. We propose "CorAl", an alignment quality measure and alignment classifier for point cloud pairs, which facilitates the ability to introspectively assess the performance of registration. CorAl compares the joint and the separate entropy of the two point clouds. The separate entropy provides a measure of the entropy that can be expected to be inherent to the environment. The joint entropy should therefore not be substantially higher if the point clouds are properly aligned. Computing the expected entropy makes the method sensitive also to small alignment errors, which are particularly hard to detect, and applicable in a range of different environments. We found that CorAl is able to detect small alignment errors in previously unseen environments with an accuracy of 95% and achieve a substantial improvement to previous methods.
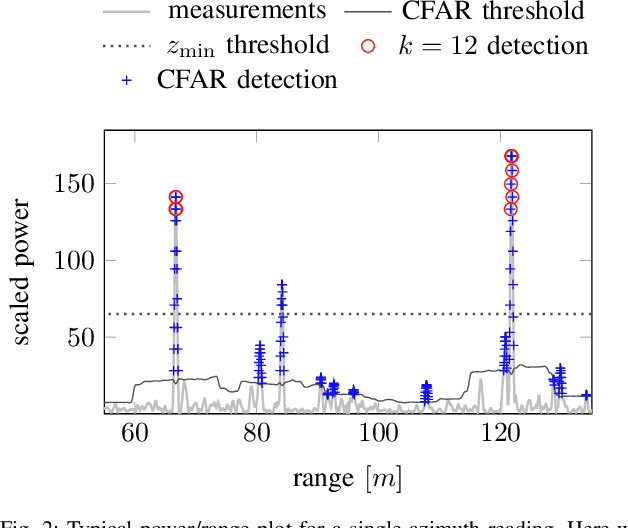
BFAR-Bounded False Alarm Rate detector for improved radar odometry estimation
Sep 20, 2021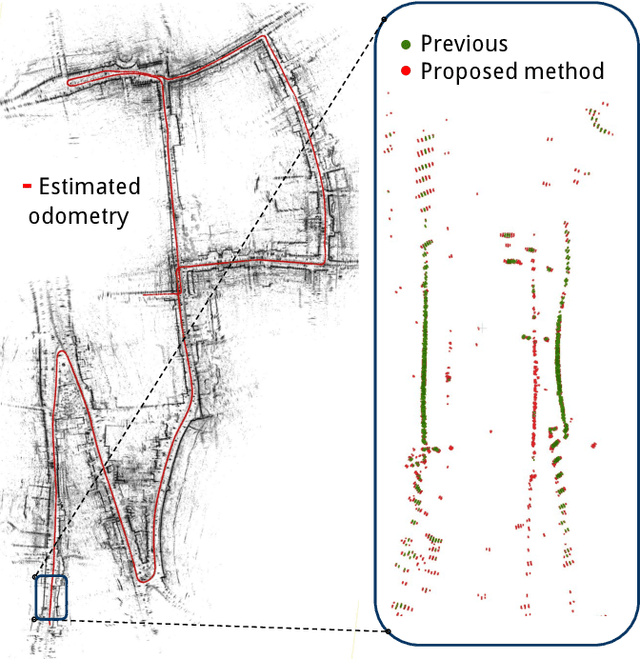
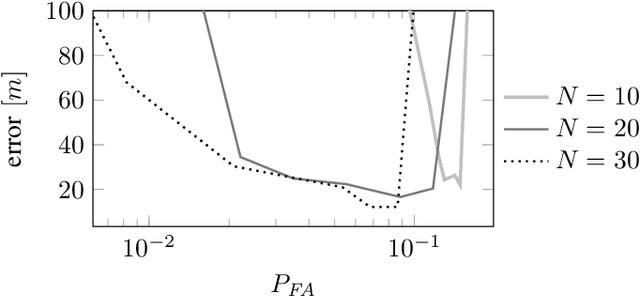
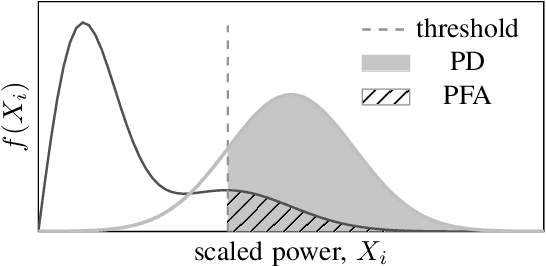
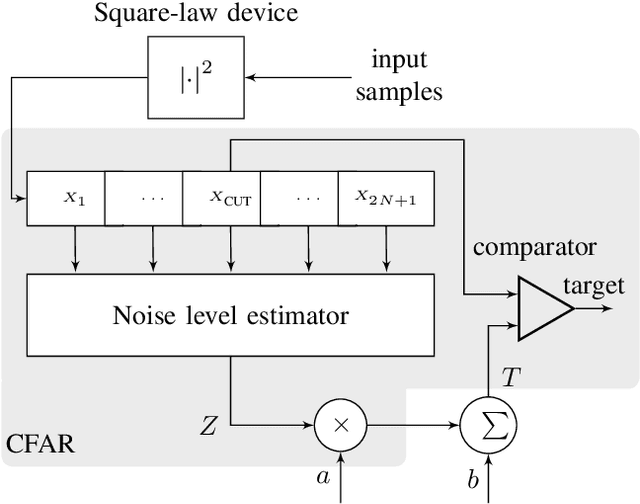
This paper presents a new detector for filtering noise from true detections in radar data, which improves the state of the art in radar odometry. Scanning Frequency-Modulated Continuous Wave (FMCW) radars can be useful for localization and mapping in low visibility, but return a lot of noise compared to (more commonly used) lidar, which makes the detection task more challenging. Our Bounded False-Alarm Rate (BFAR) detector is different from the classical Constant False-Alarm Rate (CFAR) detector in that it applies an affine transformation on the estimated noise level after which the parameters that minimize the estimation error can be learned. BFAR is an optimized combination between CFAR and fixed-level thresholding. Only a single parameter needs to be learned from a training dataset. We apply BFAR to the use case of radar odometry, and adapt a state-of-the-art odometry pipeline (CFEAR), replacing its original conservative filtering with BFAR. In this way we reduce the state-of-the-art translation/rotation odometry errors from 1.76%/0.5deg/100 m to 1.55%/0.46deg/100 m; an improvement of 12.5%.
CFEAR Radarodometry -- Conservative Filtering for Efficient and Accurate Radar Odometry
May 04, 2021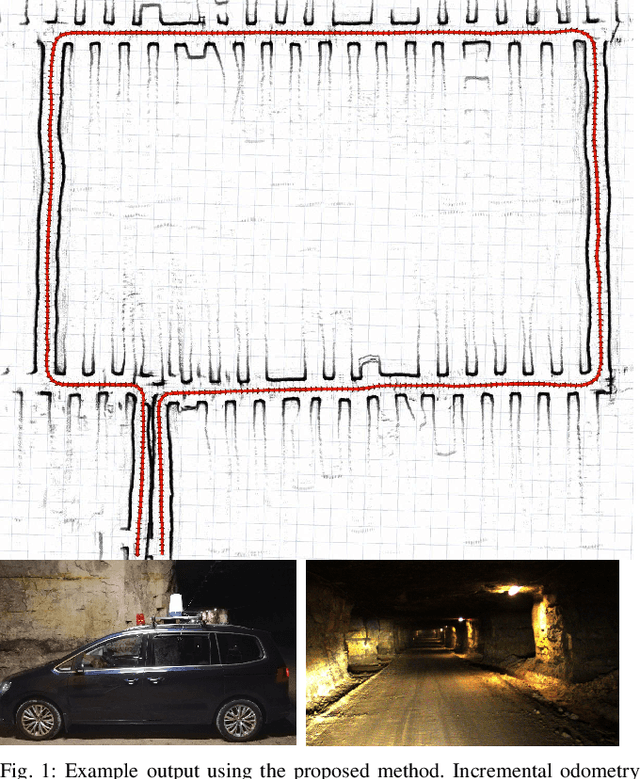

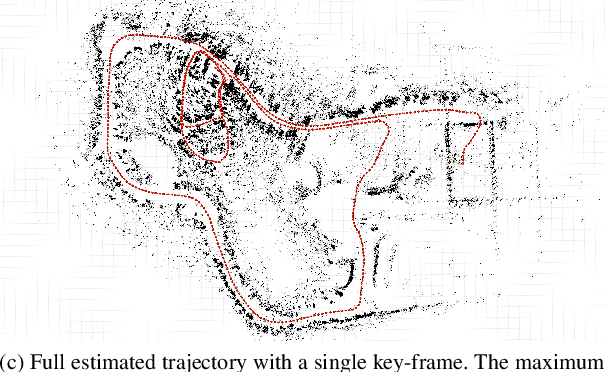
This paper presents the accurate, highly efficient, and learning-free method CFEAR Radarodometry for large-scale radar odometry estimation. By using a filtering technique that keeps the k strongest returns per azimuth and by additionally filtering the radar data in Cartesian space, we are able to compute a sparse set of oriented surface points for efficient and accurate scan matching. Registration is carried out by minimizing a point-to-line metric and robustness to outliers is achieved using a Huber loss. We were able to additionally reduce drift by jointly registering the latest scan to a history of keyframes and found that our odometry method generalizes to different sensor models and datasets without changing a single parameter. We evaluate our method in three widely different environments and demonstrate an improvement over spatially cross-validated state-of-the-art with an overall translation error of 1.76% in a public urban radar odometry benchmark, running at 55Hz merely on a single laptop CPU thread.
Learning Occupancy Priors of Human Motion from Semantic Maps of Urban Environments
Feb 17, 2021
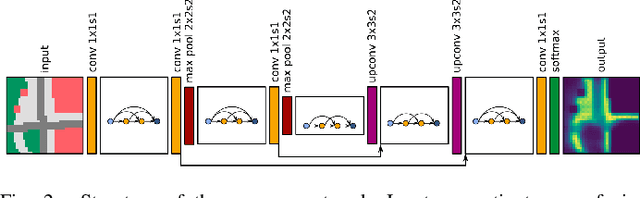
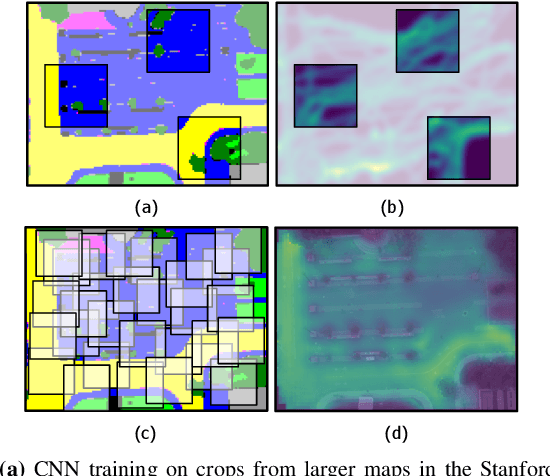

Understanding and anticipating human activity is an important capability for intelligent systems in mobile robotics, autonomous driving, and video surveillance. While learning from demonstrations with on-site collected trajectory data is a powerful approach to discover recurrent motion patterns, generalization to new environments, where sufficient motion data are not readily available, remains a challenge. In many cases, however, semantic information about the environment is a highly informative cue for the prediction of pedestrian motion or the estimation of collision risks. In this work, we infer occupancy priors of human motion using only semantic environment information as input. To this end we apply and discuss a traditional Inverse Optimal Control approach, and propose a novel one based on Convolutional Neural Networks (CNN) to predict future occupancy maps. Our CNN method produces flexible context-aware occupancy estimations for semantically uniform map regions and generalizes well already with small amounts of training data. Evaluated on synthetic and real-world data, it shows superior results compared to several baselines, marking a qualitative step-up in semantic environment assessment.
Robust Frequency-Based Structure Extraction
Apr 19, 2020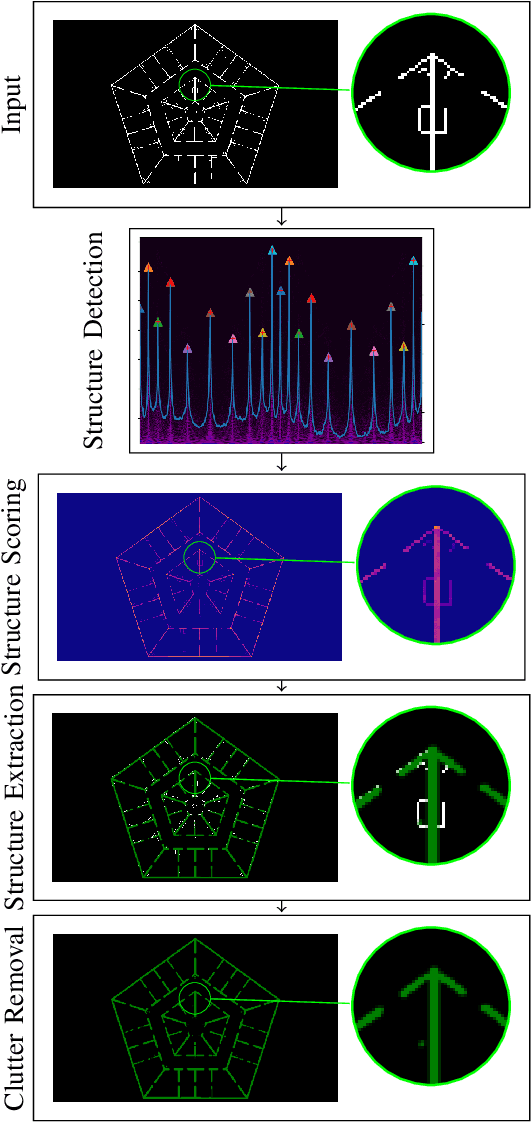
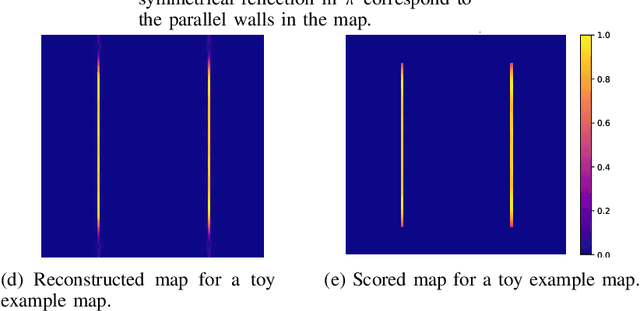
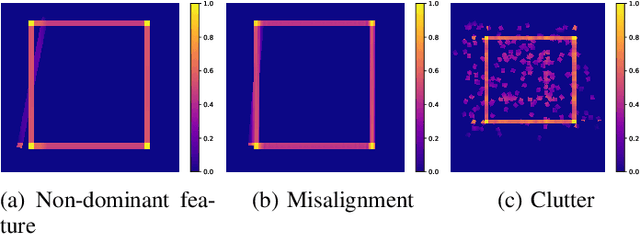
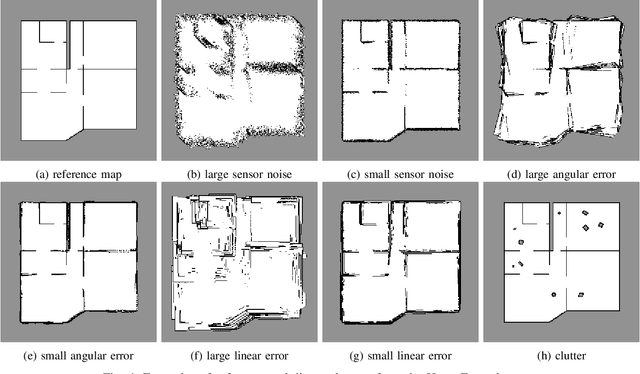
We propose a method for measuring how well each point in an indoor 2D robot map agrees with the underlying structure that governs the construction of the environment. This structure scoring has applications for, e. g., easier robot deployment and Cleaning of maps. In particular, we demonstrate its effectiveness for removing clutter and artifacts from real-world maps, which in turn is an enabler for other map processing components, e. g., room segmentation. Starting from the Fourier transform, we detect peaks in the unfolded frequency spectrum that correspond to a set of dominant directions. This allows us to reconstruct a nominal reference map and score the input map through its correspondence with this reference, without requiring access to a ground-truth map.
Object-RPE: Dense 3D Reconstruction and Pose Estimation with Convolutional Neural Networks for Warehouse Robots
Sep 30, 2019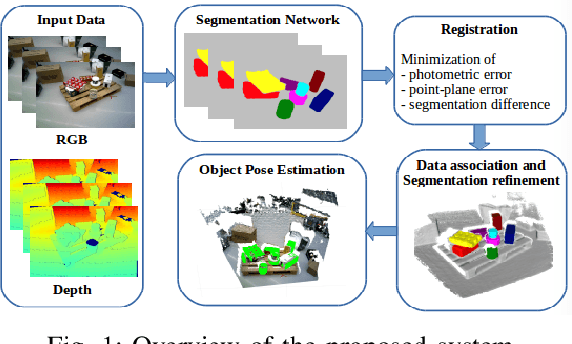
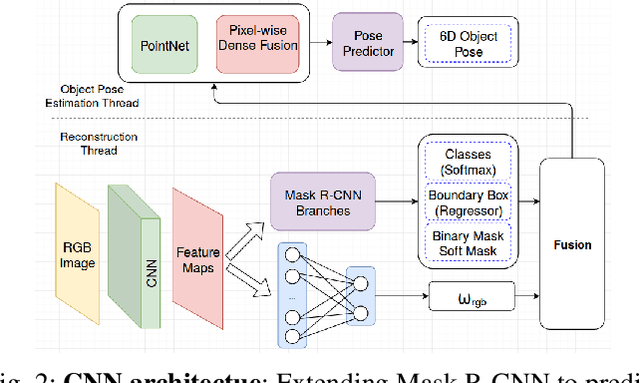
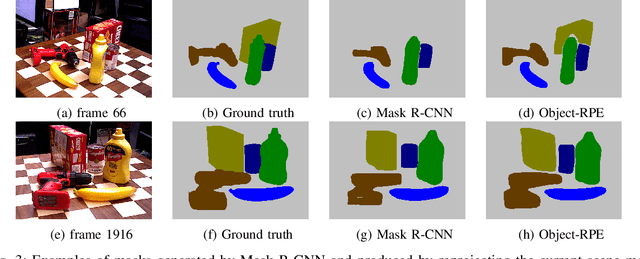

We present an approach for recognizing all objects in a scene and estimating their full pose from an accurate 3D instance-aware semantic reconstruction using an RGB-D camera. Our framework couples convolutional neural networks (CNNs) and a state-of-the-art dense Simultaneous Localisation and Mapping (SLAM) system, ElasticFusion, to achieve both high-quality semantic reconstruction as well as robust 6D pose estimation for relevant objects. While the main trend in CNN-based 6D pose estimation has been to infer object's position and orientation from single views of the scene, our approach explores performing pose estimation from multiple viewpoints, under the conjecture that combining multiple predictions can improve the robustness of an object detection system. The resulting system is capable of producing high-quality object-aware semantic reconstructions of room-sized environments, as well as accurately detecting objects and their 6D poses. The developed method has been verified through experimental validation on the YCB-Video dataset and a newly collected warehouse object dataset. Experimental results confirmed that the proposed system achieves improvements over state-of-the-art methods in terms of surface reconstruction and object pose prediction. Our code and video are available at https://sites.google.com/view/object-rpe.