 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-Consistency: Improving Non-autoregressive and Semi-supervised ASR with Consistency Regularization
Feb 26, 2026Consistency regularization (CR) improves the robustness and accuracy of Connectionist Temporal Classification (CTC) by ensuring predictions remain stable across input perturbations. In this work, we propose Align-Consistency, an extension of CR designed for Align-Refine -- a non-autoregressive (non-AR) model that performs iterative refinement of frame-level hypotheses. This method leverages the speed of parallel inference while significantly boosting recognition performance. The effectiveness of Align-Consistency is demonstrated in two settings. First, in the fully supervised setting, our results indicate that applying CR to both the base CTC model and the subsequent refinement steps is critical, and the accuracy improvements from non-AR decoding and CR are mutually additive. Second, for semi-supervised ASR, we employ fast non-AR decoding to generate online pseudo-labels on unlabeled data, which are used to further refine the supervised model and lead to substantial gains.
The Atlas Benchmark: an Automated Evaluation Framework for Human Motion Prediction
Jul 20, 2022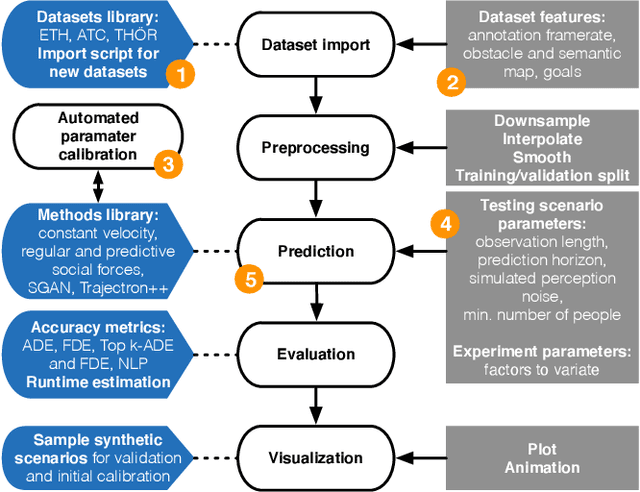
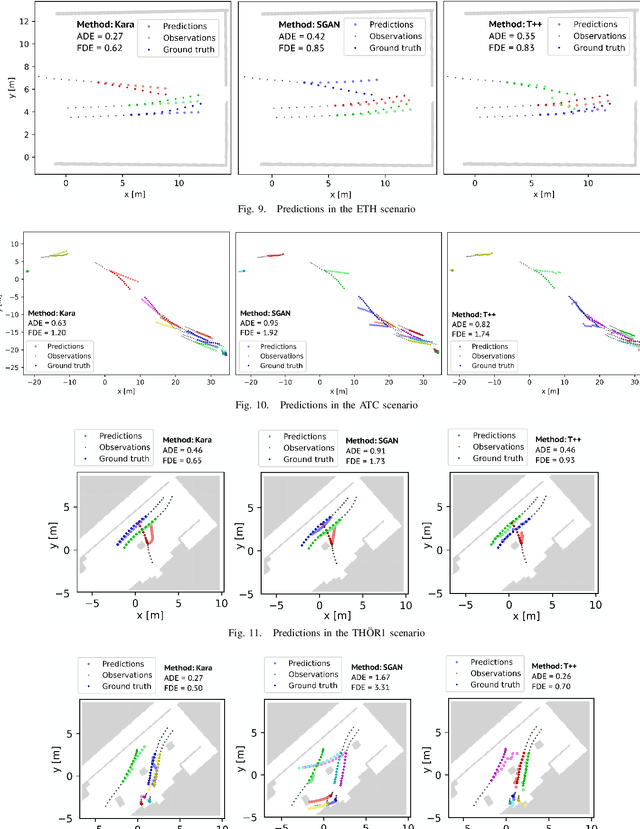
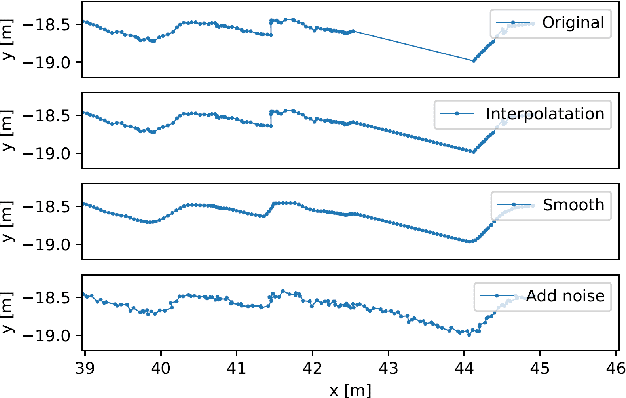
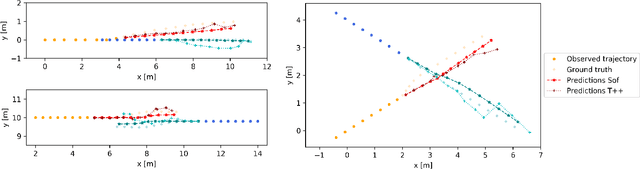
Human motion trajectory prediction, an essential task for autonomous systems in many domains, has been on the rise in recent years. With a multitude of new methods proposed by different communities, the lack of standardized benchmarks and objective comparisons is increasingly becoming a major limitation to assess progress and guide further research. Existing benchmarks are limited in their scope and flexibility to conduct relevant experiments and to account for contextual cues of agents and environments. In this paper we present Atlas, a benchmark to systematically evaluate human motion trajectory prediction algorithms in a unified framework. Atlas offers data preprocessing functions, hyperparameter optimization, comes with popular datasets and has the flexibility to setup and conduct underexplored yet relevant experiments to analyze a method's accuracy and robustness. In an example application of Atlas, we compare five popular model- and learning-based predictors and find that, when properly applied, early physics-based approaches are still remarkably competitive. Such results confirm the necessity of benchmarks like Atlas.