 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Human-Robot Co-Assembly: Leveraging Human Intention Prediction and Robust Safe Control
Jun 20, 2023



Human-robot collaboration (HRC) is one key component to achieving flexible manufacturing to meet the different needs of customers. However, it is difficult to build intelligent robots that can proactively assist humans in a safe and efficient way due to several challenges.First, it is challenging to achieve efficient collaboration due to diverse human behaviors and data scarcity. Second, it is difficult to ensure interactive safety due to uncertainty in human behaviors. This paper presents an integrated framework for proactive HRC. A robust intention prediction module, which leverages prior task information and human-in-the-loop training, is learned to guide the robot for efficient collaboration. The proposed framework also uses robust safe control to ensure interactive safety under uncertainty. The developed framework is applied to a co-assembly task using a Kinova Gen3 robot. The experiment demonstrates that our solution is robust to environmental changes as well as different human preferences and behaviors. In addition, it improves task efficiency by approximately 15-20%. Moreover, the experiment demonstrates that our solution can guarantee interactive safety during proactive collaboration.
General Place Recognition Survey: Towards the Real-world Autonomy Age
Sep 09, 2022
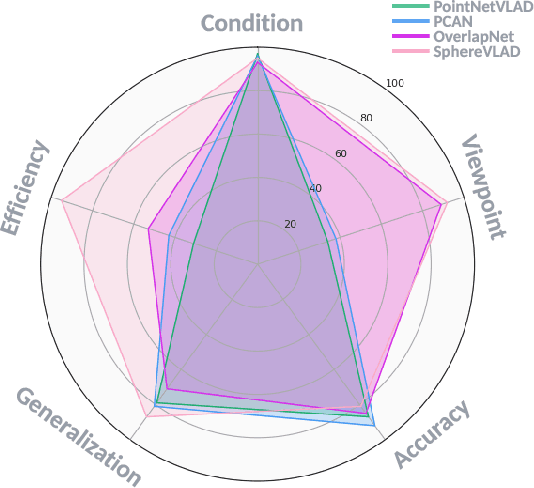

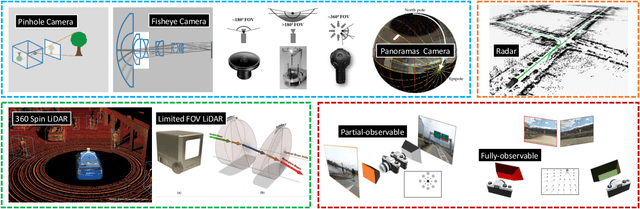
Place recognition is the fundamental module that can assist Simultaneous Localization and Mapping (SLAM) in loop-closure detection and re-localization for long-term navigation. The place recognition community has made astonishing progress over the last $20$ years, and this has attracted widespread research interest and application in multiple fields such as computer vision and robotics. However, few methods have shown promising place recognition performance in complex real-world scenarios, where long-term and large-scale appearance changes usually result in failures. Additionally, there is a lack of an integrated framework amongst the state-of-the-art methods that can handle all of the challenges in place recognition, which include appearance changes, viewpoint differences, robustness to unknown areas, and efficiency in real-world applications. In this work, we survey the state-of-the-art methods that target long-term localization and discuss future directions and opportunities. We start by investigating the formulation of place recognition in long-term autonomy and the major challenges in real-world environments. We then review the recent works in place recognition for different sensor modalities and current strategies for dealing with various place recognition challenges. Finally, we review the existing datasets for long-term localization and introduce our datasets and evaluation API for different approaches. This paper can be a tutorial for researchers new to the place recognition community and those who care about long-term robotics autonomy. We also provide our opinion on the frequently asked question in robotics: Do robots need accurate localization for long-term autonomy? A summary of this work and our datasets and evaluation API is publicly available to the robotics community at: https://github.com/MetaSLAM/GPRS.
BioSLAM: A Bio-inspired Lifelong Memory System for General Place Recognition
Aug 30, 2022
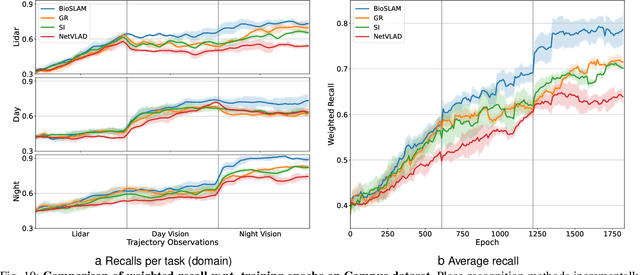
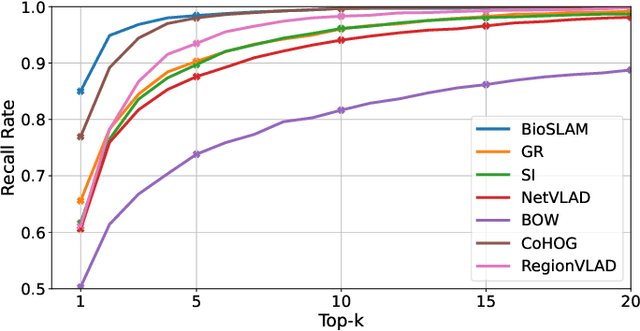
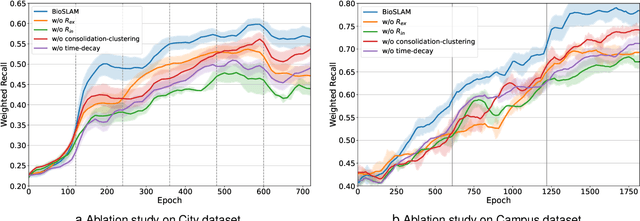
We present BioSLAM, a lifelong SLAM framework for learning various new appearances incrementally and maintaining accurate place recognition for previously visited areas. Unlike humans, artificial neural networks suffer from catastrophic forgetting and may forget the previously visited areas when trained with new arrivals. For humans, researchers discover that there exists a memory replay mechanism in the brain to keep the neuron active for previous events. Inspired by this discovery, BioSLAM designs a gated generative replay to control the robot's learning behavior based on the feedback rewards. Specifically, BioSLAM provides a novel dual-memory mechanism for maintenance: 1) a dynamic memory to efficiently learn new observations and 2) a static memory to balance new-old knowledge. When combined with a visual-/LiDAR- based SLAM system, the complete processing pipeline can help the agent incrementally update the place recognition ability, robust to the increasing complexity of long-term place recognition. We demonstrate BioSLAM in two incremental SLAM scenarios. In the first scenario, a LiDAR-based agent continuously travels through a city-scale environment with a 120km trajectory and encounters different types of 3D geometries (open streets, residential areas, commercial buildings). We show that BioSLAM can incrementally update the agent's place recognition ability and outperform the state-of-the-art incremental approach, Generative Replay, by 24%. In the second scenario, a LiDAR-vision-based agent repeatedly travels through a campus-scale area on a 4.5km trajectory. BioSLAM can guarantee the place recognition accuracy to outperform 15\% over the state-of-the-art approaches under different appearances. To our knowledge, BioSLAM is the first memory-enhanced lifelong SLAM system to help incremental place recognition in long-term navigation tasks.
An Optical Controlling Environment and Reinforcement Learning Benchmarks
Mar 23, 2022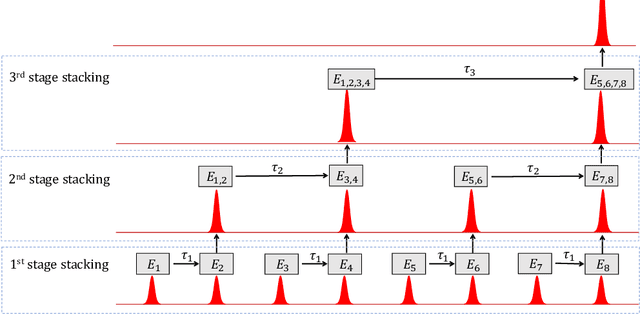
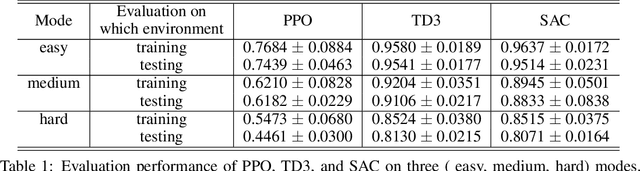
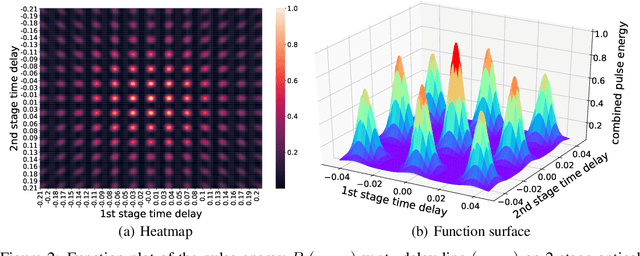
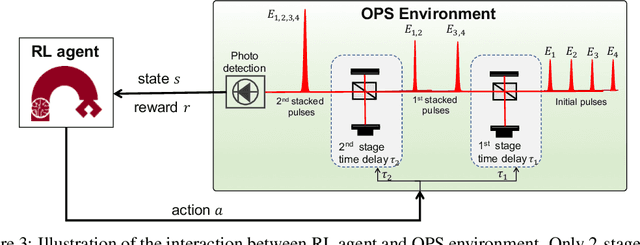
Deep reinforcement learning has the potential to address various scientific problems. In this paper, we implement an optics simulation environment for reinforcement learning based controllers. The environment incorporates nonconvex and nonlinear optical phenomena as well as more realistic time-dependent noise. Then we provide the benchmark results of several state-of-the-art reinforcement learning algorithms on the proposed simulation environment. In the end, we discuss the difficulty of controlling the real-world optical environment with reinforcement learning algorithms.
Property-aware Adaptive Relation Networks for Molecular Property Prediction
Jul 16, 2021
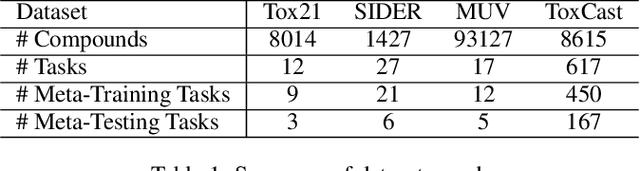
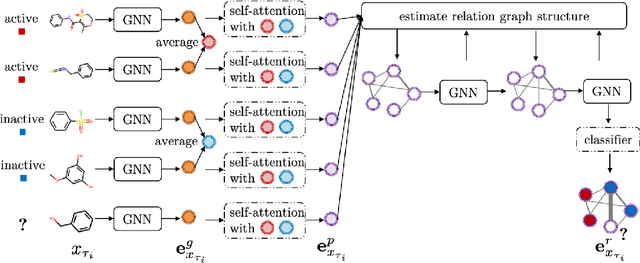
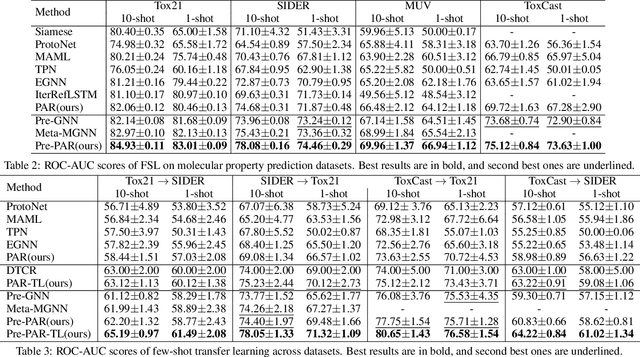
Molecular property prediction plays a fundamental role in drug discovery to discover candidate molecules with target properties. However, molecular property prediction is essentially a few-shot problem which makes it hard to obtain regular models. In this paper, we propose a property-aware adaptive relation networks (PAR) for the few-shot molecular property prediction problem. In comparison to existing works, we leverage the facts that both substructures and relationships among molecules are different considering various molecular properties. Our PAR is compatible with existing graph-based molecular encoders, and are further equipped with the ability to obtain property-aware molecular embedding and model molecular relation graph adaptively. The resultant relation graph also facilitates effective label propagation within each task. Extensive experiments on benchmark molecular property prediction datasets show that our method consistently outperforms state-of-the-art methods and is able to obtain property-aware molecular embedding and model molecular relation graph properly.
Escaping the Big Data Paradigm with Compact Transformers
Apr 12, 2021
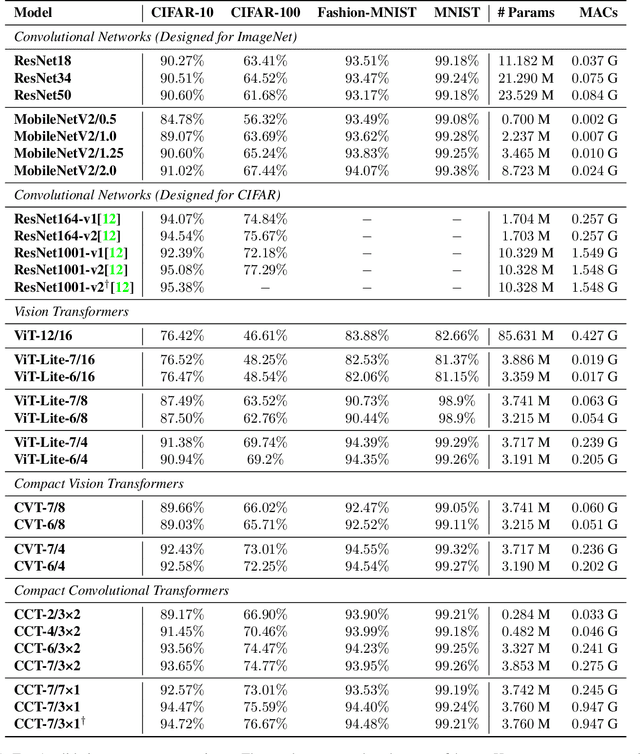
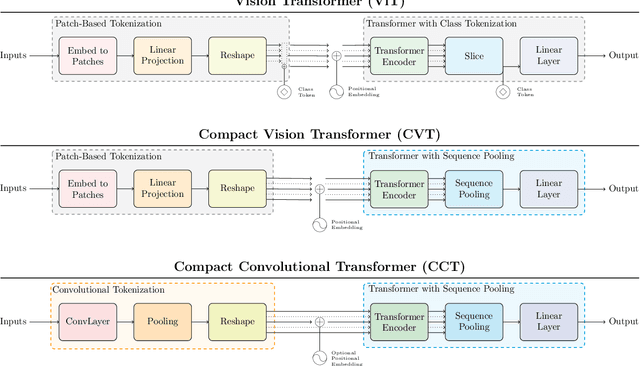
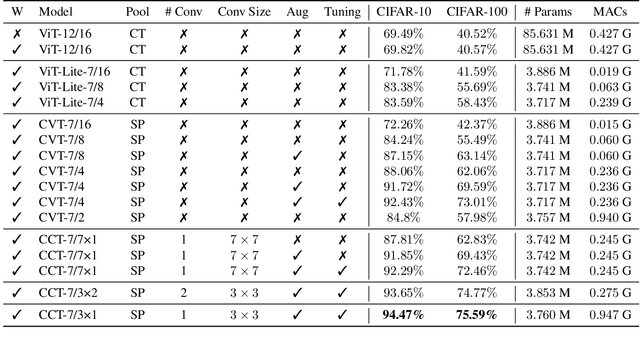
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, along with their unprecedented size and amounts of training data, many have come to believe that they are not suitable for small sets of data. This trend leads to great concerns, including but not limited to: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we dispel the myth that transformers are "data hungry" and therefore can only be applied to large sets of data. We show for the first time that with the right size and tokenization, transformers can perform head-to-head with state-of-the-art CNNs on small datasets. Our model eliminates the requirement for class token and positional embeddings through a novel sequence pooling strategy and the use of convolutions. We show that compared to CNNs, our compact transformers have fewer parameters and MACs, while obtaining similar accuracies. Our method is flexible in terms of model size, and can have as little as 0.28M parameters and achieve reasonable results. It can reach an accuracy of 94.72% when training from scratch on CIFAR-10, which is comparable with modern CNN based approaches, and a significant improvement over previous Transformer based models. Our simple and compact design democratizes transformers by making them accessible to those equipped with basic computing resources and/or dealing with important small datasets. Our code and pre-trained models will be made publicly available at https://github.com/SHI-Labs/Compact-Transformers.
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Mar 03, 2021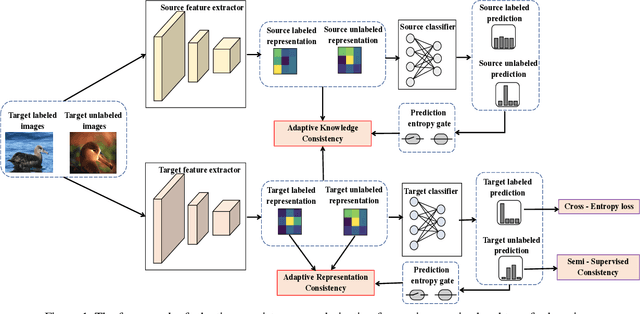
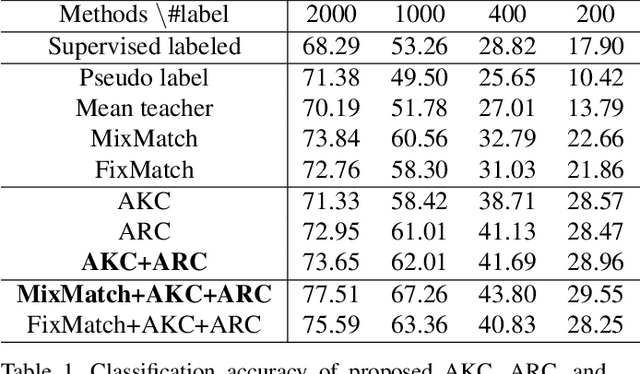
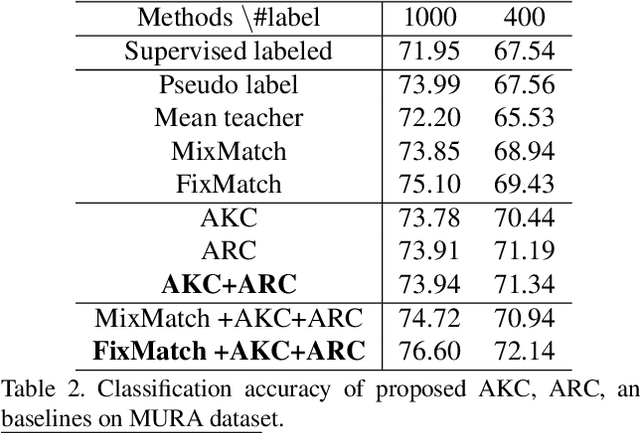
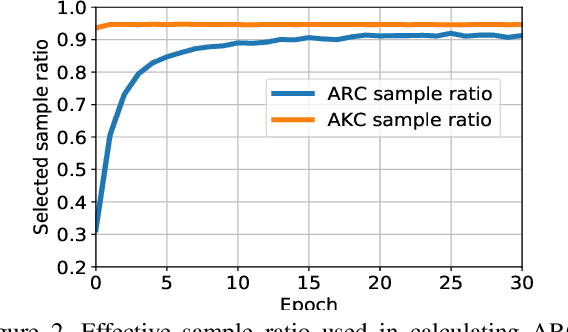
While recent studies on semi-supervised learning have shown remarkable progress in leveraging both labeled and unlabeled data, most of them presume a basic setting of the model is randomly initialized. In this work, we consider semi-supervised learning and transfer learning jointly, leading to a more practical and competitive paradigm that can utilize both powerful pre-trained models from source domain as well as labeled/unlabeled data in the target domain. To better exploit the value of both pre-trained weights and unlabeled target examples, we introduce adaptive consistency regularization that consists of two complementary components: Adaptive Knowledge Consistency (AKC) on the examples between the source and target model, and Adaptive Representation Consistency (ARC) on the target model between labeled and unlabeled examples. Examples involved in the consistency regularization are adaptively selected according to their potential contributions to the target task. We conduct extensive experiments on several popular benchmarks including CUB-200-2011, MIT Indoor-67, MURA, by fine-tuning the ImageNet pre-trained ResNet-50 model. Results show that our proposed adaptive consistency regularization outperforms state-of-the-art semi-supervised learning techniques such as Pseudo Label, Mean Teacher, and MixMatch. Moreover, our algorithm is orthogonal to existing methods and thus able to gain additional improvements on top of MixMatch and FixMatch. Our code is available at https://github.com/SHI-Labs/Semi-Supervised-Transfer-Learning.
Robust Online Model Adaptation by Extended Kalman Filter with Exponential Moving Average and Dynamic Multi-Epoch Strategy
Dec 18, 2019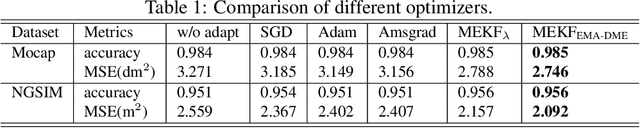

High fidelity behavior prediction of intelligent agents is critical in many applications. However, the prediction model trained on the training set may not generalize to the testing set due to domain shift and time variance. The challenge motivates the adoption of online adaptation algorithms to update prediction models in real-time to improve the prediction performance. Inspired by Extended Kalman Filter (EKF), this paper introduces a series of online adaptation methods, which are applicable to neural network-based models. A base adaptation algorithm Modified EKF with forgetting factor (MEKF$_\lambda$) is introduced first, followed by exponential moving average filtering techniques. Then this paper introduces a dynamic multi-epoch update strategy to effectively utilize samples received in real time. With all these extensions, we propose a robust online adaptation algorithm: MEKF with Exponential Moving Average and Dynamic Multi-Epoch strategy (MEKF$_{\text{EMA-DME}}$). The proposed algorithm outperforms existing methods as demonstrated in experiments.
Adaptable Human Intention and Trajectory Prediction for Human-Robot Collaboration
Sep 11, 2019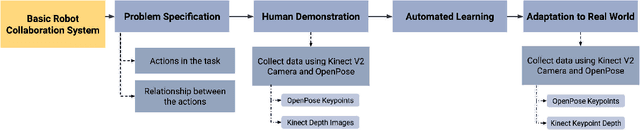
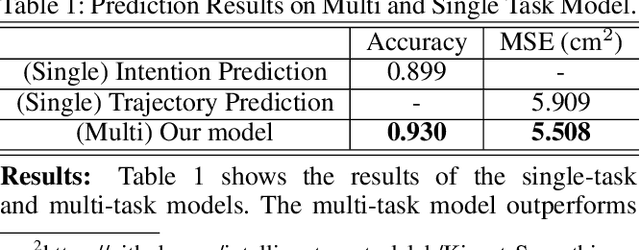
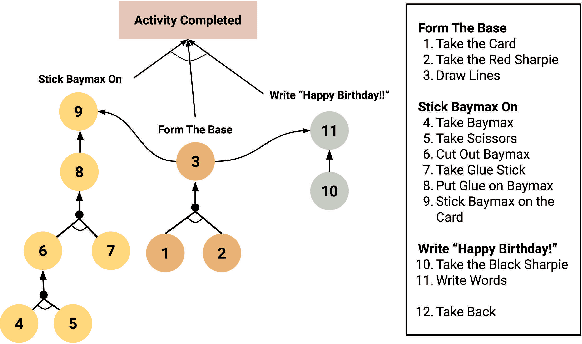
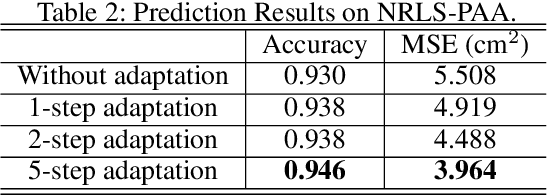
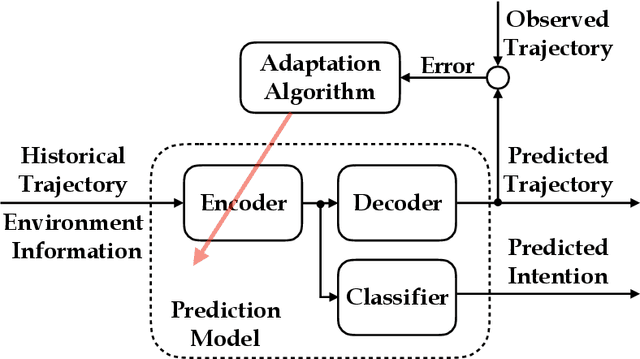
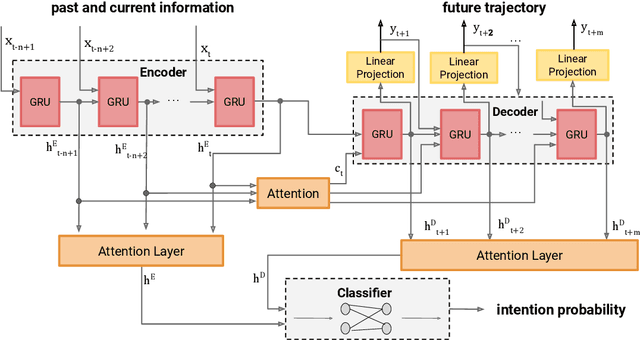
To engender safe and efficient human-robot collaboration, it is critical to generate high-fidelity predictions of human behavior. The challenges in making accurate predictions lie in the stochasticity and heterogeneity in human behaviors. This paper introduces a method for human trajectory and intention prediction through a multi-task model that is adaptable across different human subjects. We develop a nonlinear recursive least square parameter adaptation algorithm (NRLS-PAA) to achieve online adaptation. The effectiveness and flexibility of the proposed method has been validated in experiments. In particular, online adaptation can reduce the trajectory prediction error by more than 28% for a new human subject. The proposed human prediction method has high flexibility, data efficiency, and generalizability, which can support fast integration of HRC systems for user-specified tasks.
Efficient Method for Categorize Animals in the Wild
Jul 30, 2019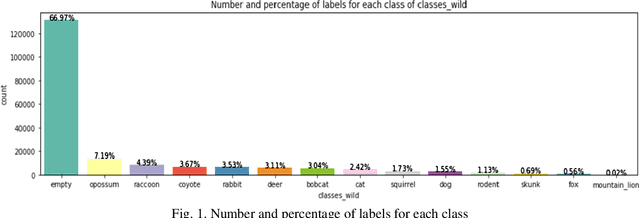
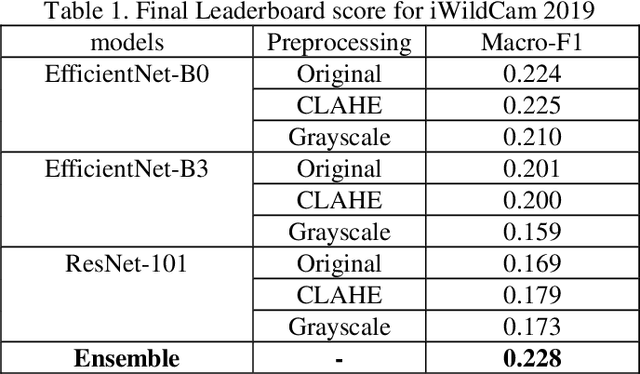


Automatic species classification in camera traps would greatly help the biodiversity monitoring and species analysis in the earth. In order to accelerate the development of automatic species classification task, "Microsoft AI for Earth" have prepared a challenge in FGVC6 workshop at CVPR 2019, which called "iWildCam 2019 competition". In this work, we propose an efficient method for categorizing animals in the wild. We transfer the state-of-the-art ImagaNet pretrained models to the problem. To improve the generalization and robustness of the model, we utilize efficient image augmentation and regularization strategies, like cutout, mixup and label-smoothing. Finally, we use ensemble learning to increase the performance of the model. Thanks to advanced regularization strategies and ensemble learning, we got top 7/336 places in the final leaderboard. Source code of this work is available at https://github.com/Walleclipse/iWildCam_2019_FGVC6