 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Identification and Control of a Low-Cost Wheeled Mobile Robot Using Differentiable Physics
Sep 24, 2020

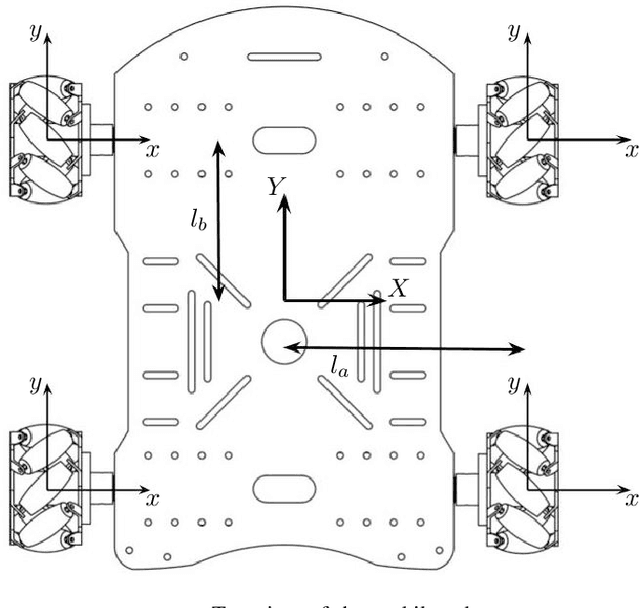
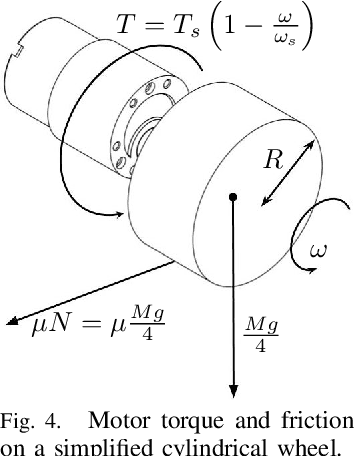
We present the design of a low-cost wheeled mobile robot, and an analytical model for predicting its motion under the influence of motor torques and friction forces. Using our proposed model, we show how to analytically compute the gradient of an appropriate loss function, that measures the deviation between predicted motion trajectories and real-world trajectories, which are estimated using Apriltags and an overhead camera. These analytical gradients allow us to automatically infer the unknown friction coefficients, by minimizing the loss function using gradient descent. Motion trajectories that are predicted by the optimized model are in excellent agreement with their real-world counterparts. Experiments show that our proposed approach is computationally superior to existing black-box system identification methods and other data-driven techniques, and also requires very few real-world samples for accurate trajectory prediction. The proposed approach combines the data efficiency of analytical models based on first principles, with the flexibility of data-driven methods, which makes it appropriate for low-cost robots. Using the learned model and our gradient-based optimization approach, we show how to automatically compute motor control signals for driving the robot along pre-specified curves.
A Probabilistic Model for Planar Sliding of Objects with Unknown Material Properties: Identification and Robust Planning
Aug 05, 2020
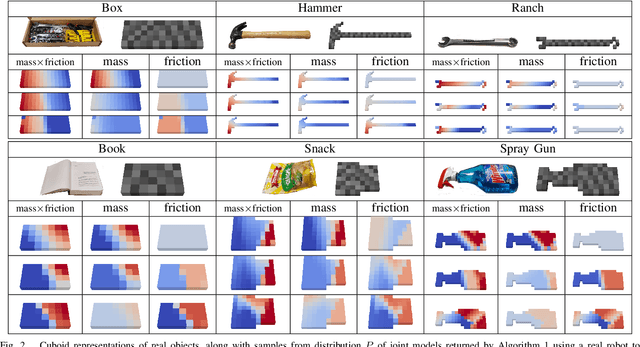
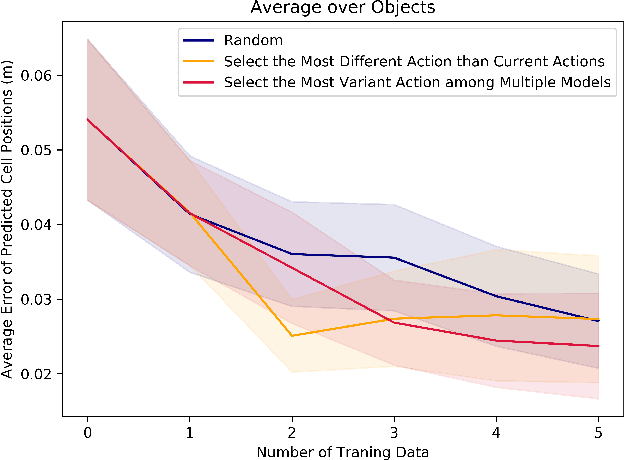
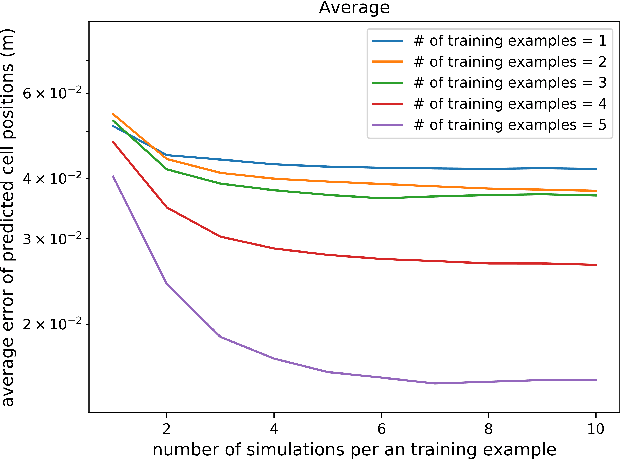
This paper introduces a new technique for learning probabilistic models of mass and friction distributions of unknown objects, and performing robust sliding actions by using the learned models. The proposed method is executed in two consecutive phases. In the exploration phase, a table-top object is poked by a robot from different angles. The observed motions of the object are compared against simulated motions with various hypothesized mass and friction models. The simulation-to-reality gap is then differentiated with respect to the unknown mass and friction parameters, and the analytically computed gradient is used to optimize those parameters. Since it is difficult to disentangle the mass from the friction coefficients in low-data and quasi-static motion regimes, our approach retains a set of locally optimal pairs of mass and friction models. A probability distribution on the models is computed based on the relative accuracy of each pair of models. In the exploitation phase, a probabilistic planner is used to select a goal configuration and waypoints that are stable with a high confidence. The proposed technique is evaluated on real objects and using a real manipulator. The results show that this technique can not only identify accurately mass and friction coefficients of non-uniform heterogeneous objects, but can also be used to successfully slide an unknown object to the edge of a table and pick it up from there, without any human assistance or feedback.
Learning Transition Models with Time-delayed Causal Relations
Aug 04, 2020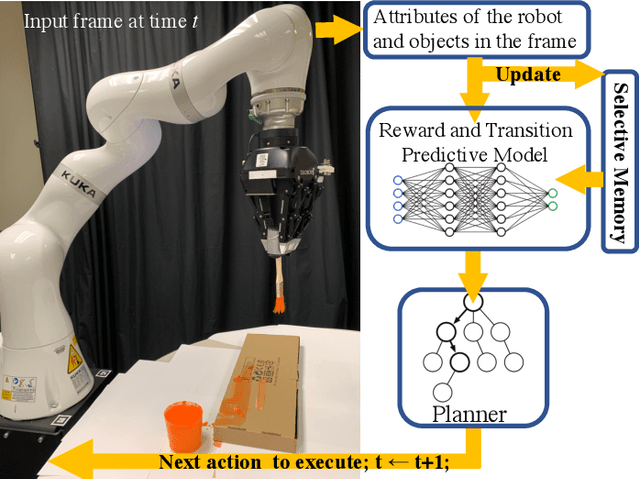
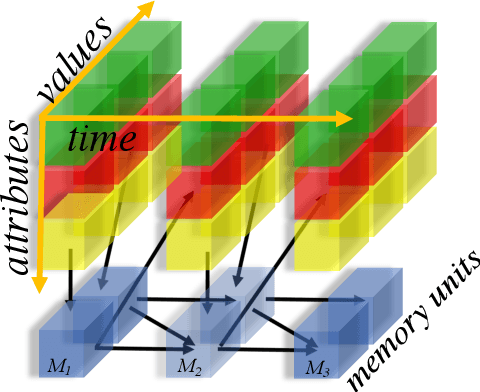

This paper introduces an algorithm for discovering implicit and delayed causal relations between events observed by a robot at arbitrary times, with the objective of improving data-efficiency and interpretability of model-based reinforcement learning (RL) techniques. The proposed algorithm initially predicts observations with the Markov assumption, and incrementally introduces new hidden variables to explain and reduce the stochasticity of the observations. The hidden variables are memory units that keep track of pertinent past events. Such events are systematically identified by their information gains. The learned transition and reward models are then used for planning. Experiments on simulated and real robotic tasks show that this method significantly improves over current RL techniques.
Task-driven Perception and Manipulation for Constrained Placement of Unknown Objects
Jun 28, 2020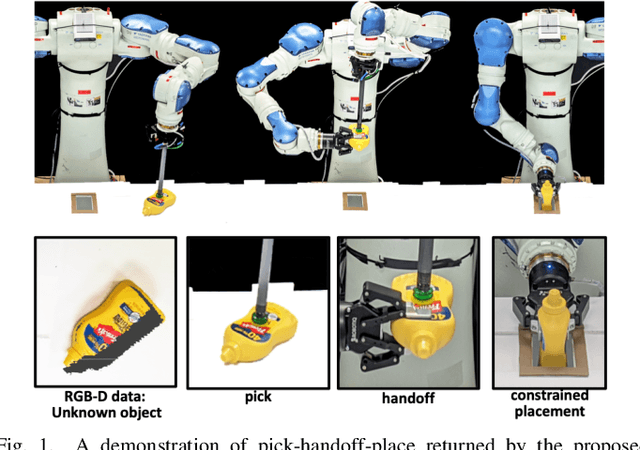
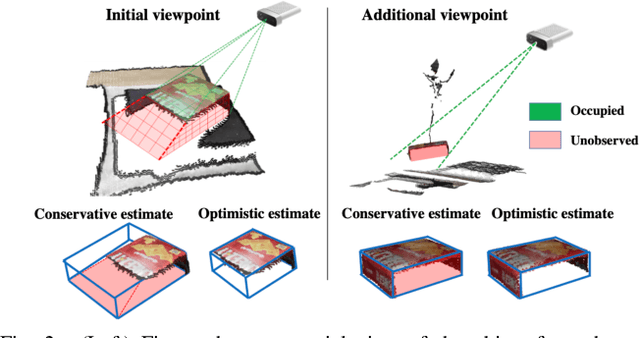
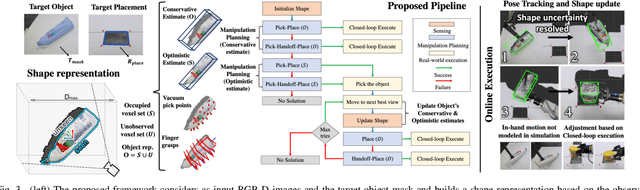
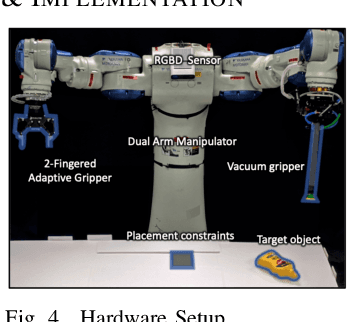
Recent progress in robotic manipulation has dealt with the case of previously unknown objects in the context of relatively simple tasks, such as bin-picking. Existing methods for more constrained problems, however, such as deliberate placement in a tight region, depend more critically on shape information to achieve safe execution. This work deals with pick-and-constrained placement of objects without access to geometric models. The objective is to pick an object and place it safely inside a desired goal region without any collisions, while minimizing the time and the sensing operations required to complete the task. An algorithmic framework is proposed for this purpose, which performs manipulation planning simultaneously over a conservative and an optimistic estimate of the object's volume. The conservative estimate ensures that the manipulation is safe while the optimistic estimate guides the sensor-based manipulation process when no solution can be found for the conservative estimate. To maintain these estimates and dynamically update them during manipulation, objects are represented by a simple volumetric representation, which stores sets of occupied and unseen voxels. The effectiveness of the proposed approach is demonstrated by developing a robotic system that picks a previously unseen object from a table-top and places it in a constrained space. The system comprises of a dual-arm manipulator with heterogeneous end-effectors and leverages hand-offs as a re-grasping strategy. Real-world experiments show that straightforward pick-sense-and-place alternatives frequently fail to solve pick-and-constrained placement problems. The proposed pipeline, however, achieves more than 95% success rate and faster execution times as evaluated over multiple physical experiments.
Learning to Slide Unknown Objects with Differentiable Physics Simulations
Jun 04, 2020


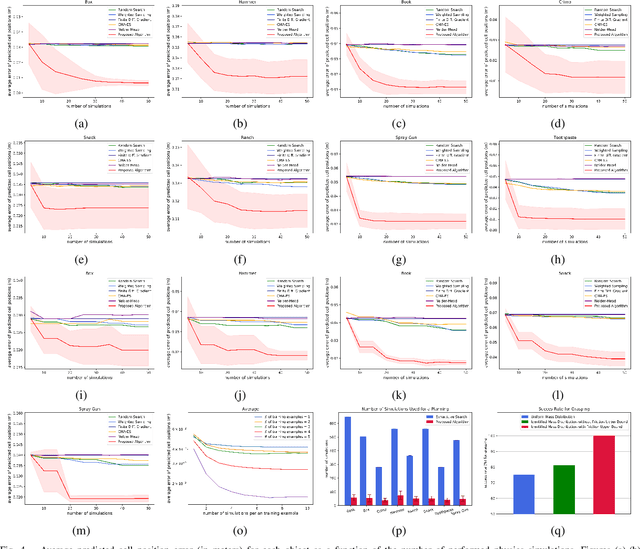
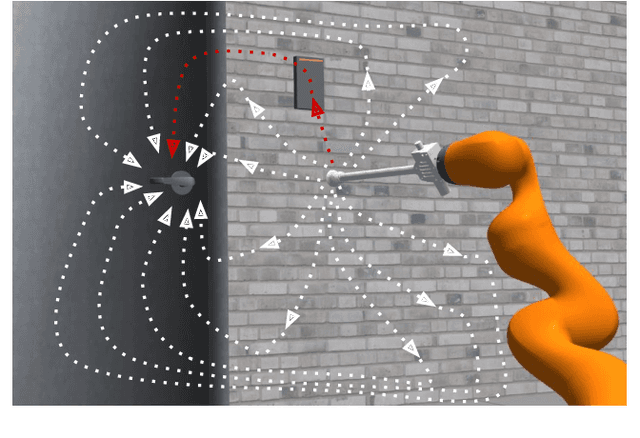
We propose a new technique for pushing an unknown object from an initial configuration to a goal configuration with stability constraints. The proposed method leverages recent progress in differentiable physics models to learn unknown mechanical properties of pushed objects, such as their distributions of mass and coefficients of friction. The proposed learning technique computes the gradient of the distance between predicted poses of objects and their actual observed poses and utilizes that gradient to search for values of the mechanical properties that reduce the reality gap. The proposed approach is also utilized to optimize a policy to efficiently push an object toward the desired goal configuration. Experiments with real objects using a real robot to gather data show that the proposed approach can identify the mechanical properties of heterogeneous objects from a small number of pushing actions.
Learning to Transfer Dynamic Models of Underactuated Soft Robotic Hands
May 21, 2020
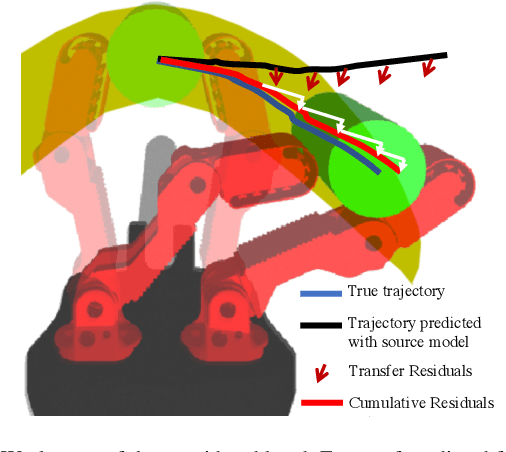
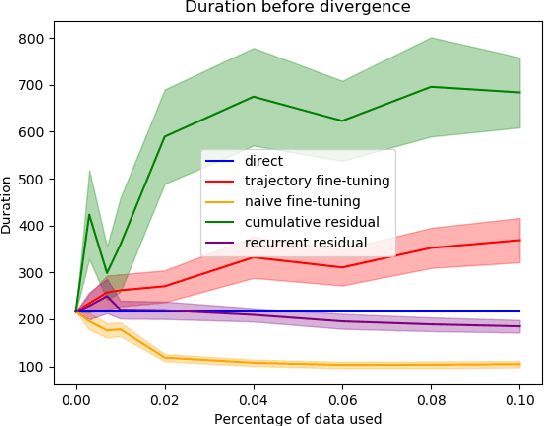
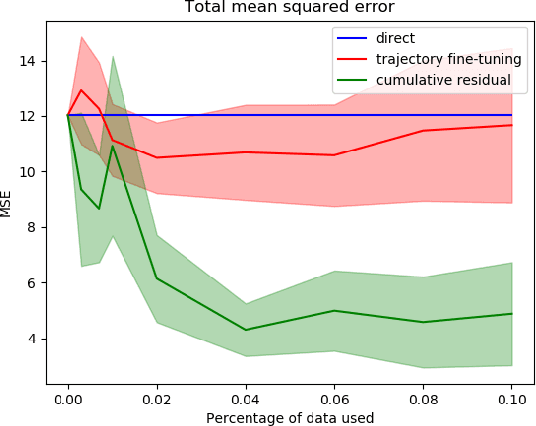
Transfer learning is a popular approach to bypassing data limitations in one domain by leveraging data from another domain. This is especially useful in robotics, as it allows practitioners to reduce data collection with physical robots, which can be time-consuming and cause wear and tear. The most common way of doing this with neural networks is to take an existing neural network, and simply train it more with new data. However, we show that in some situations this can lead to significantly worse performance than simply using the transferred model without adaptation. We find that a major cause of these problems is that models trained on small amounts of data can have chaotic or divergent behavior in some regions. We derive an upper bound on the Lyapunov exponent of a trained transition model, and demonstrate two approaches that make use of this insight. Both show significant improvement over traditional fine-tuning. Experiments performed on real underactuated soft robotic hands clearly demonstrate the capability to transfer a dynamic model from one hand to another.
Identifying Mechanical Models through Differentiable Simulations
May 11, 2020

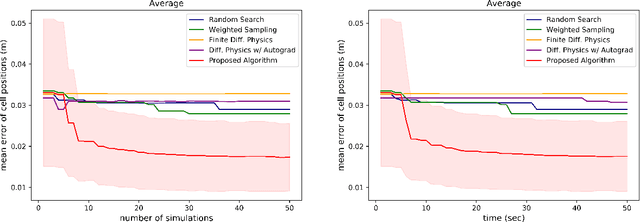
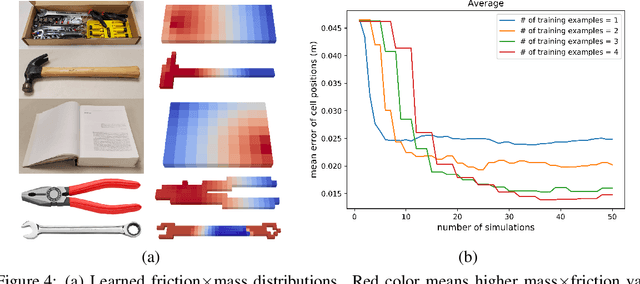
This paper proposes a new method for manipulating unknown objects through a sequence of non-prehensile actions that displace an object from its initial configuration to a given goal configuration on a flat surface. The proposed method leverages recent progress in differentiable physics models to identify unknown mechanical properties of manipulated objects, such as inertia matrix, friction coefficients and external forces acting on the object. To this end, a recently proposed differentiable physics engine for two-dimensional objects is adopted in this work and extended to deal forces in the three-dimensional space. The proposed model identification technique analytically computes the gradient of the distance between forecasted poses of objects and their actual observed poses and utilizes that gradient to search for values of the mechanical properties that reduce the reality gap. Experiments with real objects using a real robot to gather data show that the proposed approach can identify the mechanical properties of heterogeneous objects on the fly.
Scene-level Pose Estimation for Multiple Instances of Densely Packed Objects
Oct 11, 2019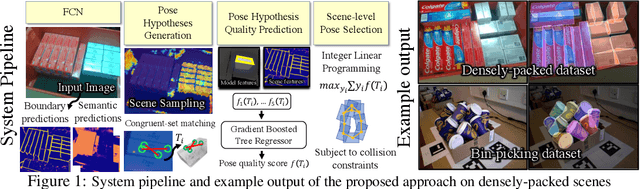

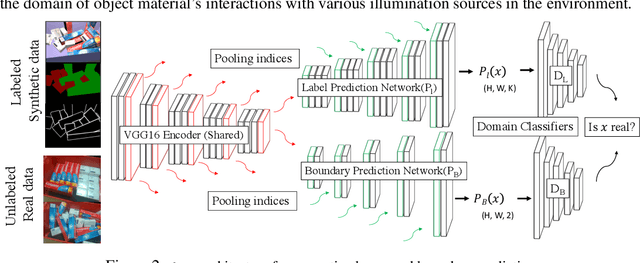

This paper introduces key machine learning operations that allow the realization of robust, joint 6D pose estimation of multiple instances of objects either densely packed or in unstructured piles from RGB-D data. The first objective is to learn semantic and instance-boundary detectors without manual labeling. An adversarial training framework in conjunction with physics-based simulation is used to achieve detectors that behave similarly in synthetic and real data. Given the stochastic output of such detectors, candidates for object poses are sampled. The second objective is to automatically learn a single score for each pose candidate that represents its quality in terms of explaining the entire scene via a gradient boosted tree. The proposed method uses features derived from surface and boundary alignment between the observed scene and the object model placed at hypothesized poses. Scene-level, multi-instance pose estimation is then achieved by an integer linear programming process that selects hypotheses that maximize the sum of the learned individual scores, while respecting constraints, such as avoiding collisions. To evaluate this method, a dataset of densely packed objects with challenging setups for state-of-the-art approaches is collected. Experiments on this dataset and a public one show that the method significantly outperforms alternatives in terms of 6D pose accuracy while trained only with synthetic datasets.
Object Rearrangement with Nested Nonprehensile Manipulation Actions
May 17, 2019


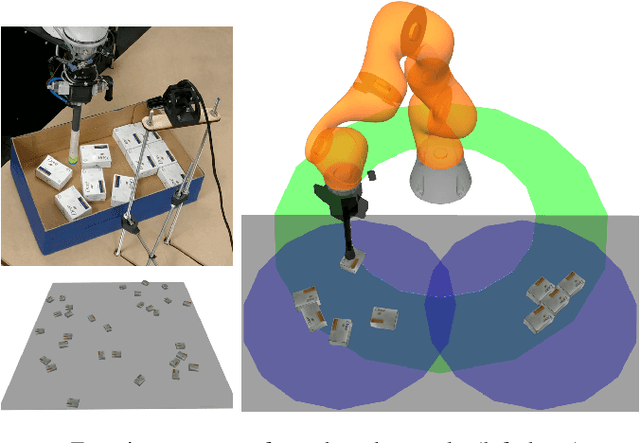
This paper considers the problem of rearrangement planning, i.e finding a sequence of manipulation actions that displace multiple objects from an initial configuration to a given goal configuration. Rearrangement is a critical skill for robots so that they can effectively operate in confined spaces that contain clutter. Examples of tasks that require rearrangement include packing objects inside a bin, wherein objects need to lay according to a predefined pattern. In tight bins, collision-free grasps are often unavailable. Nonprehensile actions, such as pushing and sliding, are preferred because they can be performed using minimalistic end-effectors that can easily be inserted in the bin. Rearrangement with nonprehensile actions is a challenging problem as it requires reasoning about object interactions in a combinatorially large configuration space of multiple objects. This work revisits several existing rearrangement planning techniques and introduces a new one that exploits nested nonprehensile actions by pushing several similar objects simultaneously along the same path, which removes the need to rearrange each object individually. Experiments in simulation and using a real Kuka robotic arm show the ability of the proposed approach to solve difficult rearrangement tasks while reducing the length of the end-effector's trajectories.
Physics-based Scene-level Reasoning for Object Pose Estimation in Clutter
Apr 01, 2019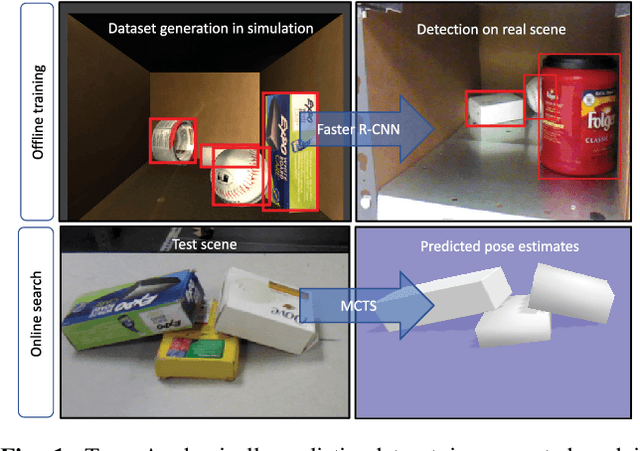


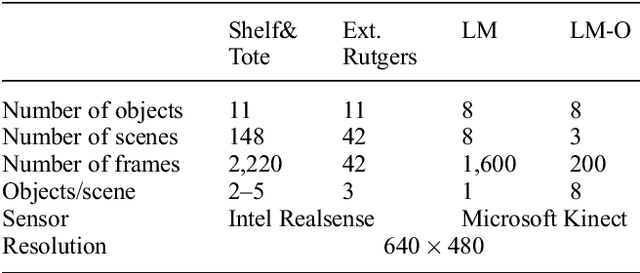
This paper focuses on vision-based pose estimation for multiple rigid objects placed in clutter, especially in cases involving occlusions and objects resting on each other. Progress has been achieved recently in object recognition given advancements in deep learning. Nevertheless, such tools typically require a large amount of training data and significant manual effort to label objects. This limits their applicability in robotics, where solutions must scale to a large number of objects and variety of conditions. Moreover, the combinatorial nature of the scenes that could arise from the placement of multiple objects is hard to capture in the training dataset. Thus, the learned models might not produce the desired level of precision required for tasks, such as robotic manipulation. This work proposes an autonomous process for pose estimation that spans from data generation to scene-level reasoning and self-learning. In particular, the proposed framework first generates a labeled dataset for training a Convolutional Neural Network (CNN) for object detection in clutter. These detections are used to guide a scene-level optimization process, which considers the interactions between the different objects present in the clutter to output pose estimates of high precision. Furthermore, confident estimates are used to label online real images from multiple views and re-train the process in a self-learning pipeline. Experimental results indicate that this process is quickly able to identify in cluttered scenes physically-consistent object poses that are more precise than the ones found by reasoning over individual instances of objects. Furthermore, the quality of pose estimates increases over time given the self-learning process.