 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Action Sequence Learning for Robotic Manipulation
Oct 04, 2024



Autoregressive models have demonstrated remarkable success in natural language processing. In this work, we design a simple yet effective autoregressive architecture for robotic manipulation tasks. We propose the Chunking Causal Transformer (CCT), which extends the next-single-token prediction of causal transformers to support multi-token prediction in a single pass. Further, we design a novel attention interleaving strategy that allows CCT to be trained efficiently with teacher-forcing. Based on CCT, we propose the Autoregressive Policy (ARP) model, which learns to generate action sequences autoregressively. We find that action sequence learning enables better leverage of the underlying causal relationships in robotic tasks. We evaluate ARP across diverse robotic manipulation environments, including Push-T, ALOHA, and RLBench, and show that it outperforms the state-of-the-art methods in all tested environments, while being more efficient in computation and parameter sizes. Video demonstrations, our source code, and the models of ARP can be found at http://github.com/mlzxy/arp.
DAP: Diffusion-based Affordance Prediction for Multi-modality Storage
Aug 31, 2024



Solving storage problem: where objects must be accurately placed into containers with precise orientations and positions, presents a distinct challenge that extends beyond traditional rearrangement tasks. These challenges are primarily due to the need for fine-grained 6D manipulation and the inherent multi-modality of solution spaces, where multiple viable goal configurations exist for the same storage container. We present a novel Diffusion-based Affordance Prediction (DAP) pipeline for the multi-modal object storage problem. DAP leverages a two-step approach, initially identifying a placeable region on the container and then precisely computing the relative pose between the object and that region. Existing methods either struggle with multi-modality issues or computation-intensive training. Our experiments demonstrate DAP's superior performance and training efficiency over the current state-of-the-art RPDiff, achieving remarkable results on the RPDiff benchmark. Additionally, our experiments showcase DAP's data efficiency in real-world applications, an advancement over existing simulation-driven approaches. Our contribution fills a gap in robotic manipulation research by offering a solution that is both computationally efficient and capable of handling real-world variability. Code and supplementary material can be found at: https://github.com/changhaonan/DPS.git.
Bellman Diffusion Models
Jul 16, 2024Diffusion models have seen tremendous success as generative architectures. Recently, they have been shown to be effective at modelling policies for offline reinforcement learning and imitation learning. We explore using diffusion as a model class for the successor state measure (SSM) of a policy. We find that enforcing the Bellman flow constraints leads to a simple Bellman update on the diffusion step distribution.
Provably Efficient Long-Horizon Exploration in Monte Carlo Tree Search through State Occupancy Regularization
Jul 07, 2024



Monte Carlo tree search (MCTS) has been successful in a variety of domains, but faces challenges with long-horizon exploration when compared to sampling-based motion planning algorithms like Rapidly-Exploring Random Trees. To address these limitations of MCTS, we derive a tree search algorithm based on policy optimization with state occupancy measure regularization, which we call {\it Volume-MCTS}. We show that count-based exploration and sampling-based motion planning can be derived as approximate solutions to this state occupancy measure regularized objective. We test our method on several robot navigation problems, and find that Volume-MCTS outperforms AlphaZero and displays significantly better long-horizon exploration properties.
USHER: Unbiased Sampling for Hindsight Experience Replay
Jul 03, 2022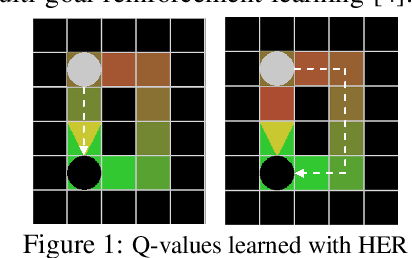
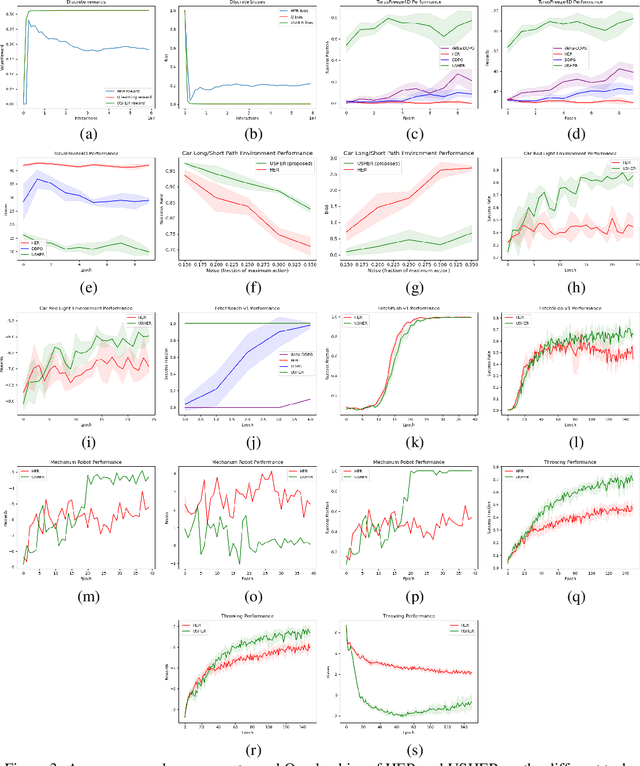
Dealing with sparse rewards is a long-standing challenge in reinforcement learning (RL). Hindsight Experience Replay (HER) addresses this problem by reusing failed trajectories for one goal as successful trajectories for another. This allows for both a minimum density of reward and for generalization across multiple goals. However, this strategy is known to result in a biased value function, as the update rule underestimates the likelihood of bad outcomes in a stochastic environment. We propose an asymptotically unbiased importance-sampling-based algorithm to address this problem without sacrificing performance on deterministic environments. We show its effectiveness on a range of robotic systems, including challenging high dimensional stochastic environments.
Learning to Transfer Dynamic Models of Underactuated Soft Robotic Hands
May 21, 2020
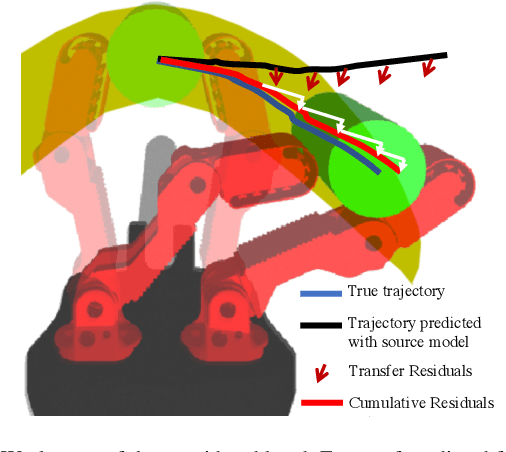
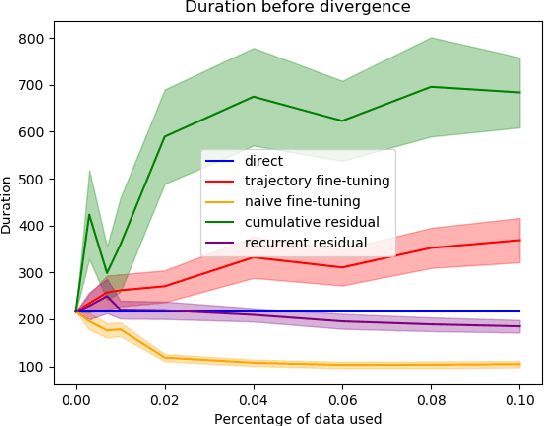
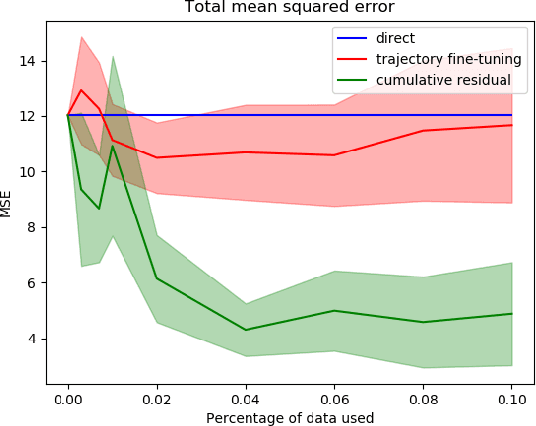
Transfer learning is a popular approach to bypassing data limitations in one domain by leveraging data from another domain. This is especially useful in robotics, as it allows practitioners to reduce data collection with physical robots, which can be time-consuming and cause wear and tear. The most common way of doing this with neural networks is to take an existing neural network, and simply train it more with new data. However, we show that in some situations this can lead to significantly worse performance than simply using the transferred model without adaptation. We find that a major cause of these problems is that models trained on small amounts of data can have chaotic or divergent behavior in some regions. We derive an upper bound on the Lyapunov exponent of a trained transition model, and demonstrate two approaches that make use of this insight. Both show significant improvement over traditional fine-tuning. Experiments performed on real underactuated soft robotic hands clearly demonstrate the capability to transfer a dynamic model from one hand to another.