 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Manipulation Learning with Visual Kinematic Chain Prediction
Jun 12, 2024



Learning general-purpose models from diverse datasets has achieved great success in machine learning. In robotics, however, existing methods in multi-task learning are typically constrained to a single robot and workspace, while recent work such as RT-X requires a non-trivial action normalization procedure to manually bridge the gap between different action spaces in diverse environments. In this paper, we propose the visual kinematics chain as a precise and universal representation of quasi-static actions for robot learning over diverse environments, which requires no manual adjustment since the visual kinematic chains can be automatically obtained from the robot's model and camera parameters. We propose the Visual Kinematics Transformer (VKT), a convolution-free architecture that supports an arbitrary number of camera viewpoints, and that is trained with a single objective of forecasting kinematic structures through optimal point-set matching. We demonstrate the superior performance of VKT over BC transformers as a general agent on Calvin, RLBench, Open-X, and real robot manipulation tasks. Video demonstrations can be found at https://mlzxy.github.io/visual-kinetic-chain.
A3VLM: Actionable Articulation-Aware Vision Language Model
Jun 11, 2024Vision Language Models (VLMs) have received significant attention in recent years in the robotics community. VLMs are shown to be able to perform complex visual reasoning and scene understanding tasks, which makes them regarded as a potential universal solution for general robotics problems such as manipulation and navigation. However, previous VLMs for robotics such as RT-1, RT-2, and ManipLLM~ have focused on directly learning robot-centric actions. Such approaches require collecting a significant amount of robot interaction data, which is extremely costly in the real world. Thus, we propose A3VLM, an object-centric, actionable, articulation-aware vision language model. A3VLM focuses on the articulation structure and action affordances of objects. Its representation is robot-agnostic and can be translated into robot actions using simple action primitives. Extensive experiments in both simulation benchmarks and real-world settings demonstrate the effectiveness and stability of A3VLM. We release our code and other materials at https://github.com/changhaonan/A3VLM.
One-Shot Imitation Learning with Invariance Matching for Robotic Manipulation
May 21, 2024Learning a single universal policy that can perform a diverse set of manipulation tasks is a promising new direction in robotics. However, existing techniques are limited to learning policies that can only perform tasks that are encountered during training, and require a large number of demonstrations to learn new tasks. Humans, on the other hand, often can learn a new task from a single unannotated demonstration. In this work, we propose the Invariance-Matching One-shot Policy Learning (IMOP) algorithm. In contrast to the standard practice of learning the end-effector's pose directly, IMOP first learns invariant regions of the state space for a given task, and then computes the end-effector's pose through matching the invariant regions between demonstrations and test scenes. Trained on the 18 RLBench tasks, IMOP achieves a success rate that outperforms the state-of-the-art consistently, by 4.5% on average over the 18 tasks. More importantly, IMOP can learn a novel task from a single unannotated demonstration, and without any fine-tuning, and achieves an average success rate improvement of $11.5\%$ over the state-of-the-art on 22 novel tasks selected across nine categories. IMOP can also generalize to new shapes and learn to manipulate objects that are different from those in the demonstration. Further, IMOP can perform one-shot sim-to-real transfer using a single real-robot demonstration.
OVIR-3D: Open-Vocabulary 3D Instance Retrieval Without Training on 3D Data
Nov 06, 2023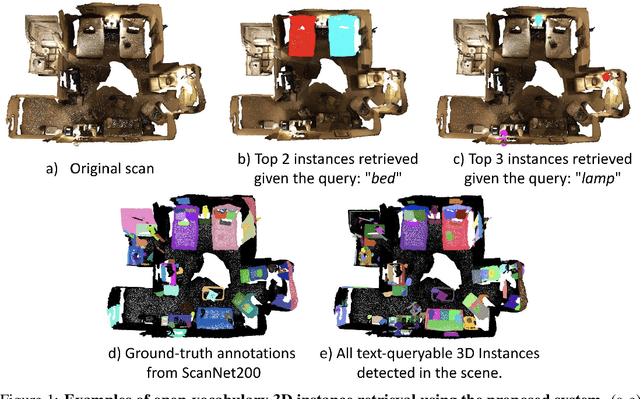
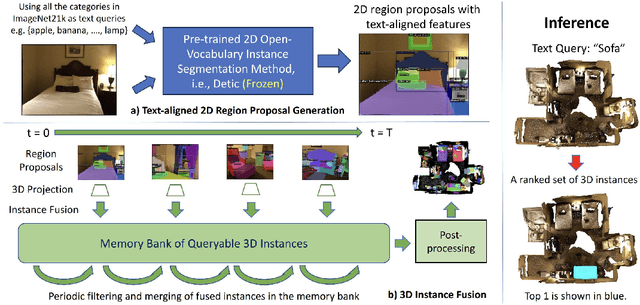
This work presents OVIR-3D, a straightforward yet effective method for open-vocabulary 3D object instance retrieval without using any 3D data for training. Given a language query, the proposed method is able to return a ranked set of 3D object instance segments based on the feature similarity of the instance and the text query. This is achieved by a multi-view fusion of text-aligned 2D region proposals into 3D space, where the 2D region proposal network could leverage 2D datasets, which are more accessible and typically larger than 3D datasets. The proposed fusion process is efficient as it can be performed in real-time for most indoor 3D scenes and does not require additional training in 3D space. Experiments on public datasets and a real robot show the effectiveness of the method and its potential for applications in robot navigation and manipulation.
Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs
Sep 27, 2023



We present an Open-Vocabulary 3D Scene Graph (OVSG), a formal framework for grounding a variety of entities, such as object instances, agents, and regions, with free-form text-based queries. Unlike conventional semantic-based object localization approaches, our system facilitates context-aware entity localization, allowing for queries such as ``pick up a cup on a kitchen table" or ``navigate to a sofa on which someone is sitting". In contrast to existing research on 3D scene graphs, OVSG supports free-form text input and open-vocabulary querying. Through a series of comparative experiments using the ScanNet dataset and a self-collected dataset, we demonstrate that our proposed approach significantly surpasses the performance of previous semantic-based localization techniques. Moreover, we highlight the practical application of OVSG in real-world robot navigation and manipulation experiments.
LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement
Sep 27, 2023



We introduce a novel approach to the executable semantic object rearrangement problem. In this challenge, a robot seeks to create an actionable plan that rearranges objects within a scene according to a pattern dictated by a natural language description. Unlike existing methods such as StructFormer and StructDiffusion, which tackle the issue in two steps by first generating poses and then leveraging a task planner for action plan formulation, our method concurrently addresses pose generation and action planning. We achieve this integration using a Language-Guided Monte-Carlo Tree Search (LGMCTS). Quantitative evaluations are provided on two simulation datasets, and complemented by qualitative tests with a real robot.
Detect Every Thing with Few Examples
Sep 22, 2023



Open-set object detection aims at detecting arbitrary categories beyond those seen during training. Most recent advancements have adopted the open-vocabulary paradigm, utilizing vision-language backbones to represent categories with language. In this paper, we introduce DE-ViT, an open-set object detector that employs vision-only DINOv2 backbones and learns new categories through example images instead of language. To improve general detection ability, we transform multi-classification tasks into binary classification tasks while bypassing per-class inference, and propose a novel region propagation technique for localization. We evaluate DE-ViT on open-vocabulary, few-shot, and one-shot object detection benchmark with COCO and LVIS. For COCO, DE-ViT outperforms the open-vocabulary SoTA by 6.9 AP50 and achieves 50 AP50 in novel classes. DE-ViT surpasses the few-shot SoTA by 15 mAP on 10-shot and 7.2 mAP on 30-shot and one-shot SoTA by 2.8 AP50. For LVIS, DE-ViT outperforms the open-vocabulary SoTA by 2.2 mask AP and reaches 34.3 mask APr. Code is available at https://github.com/mlzxy/devit.
Optical Flow boosts Unsupervised Localization and Segmentation
Jul 25, 2023Unsupervised localization and segmentation are long-standing robot vision challenges that describe the critical ability for an autonomous robot to learn to decompose images into individual objects without labeled data. These tasks are important because of the limited availability of dense image manual annotation and the promising vision of adapting to an evolving set of object categories in lifelong learning. Most recent methods focus on using visual appearance continuity as object cues by spatially clustering features obtained from self-supervised vision transformers (ViT). In this work, we leverage motion cues, inspired by the common fate principle that pixels that share similar movements tend to belong to the same object. We propose a new loss term formulation that uses optical flow in unlabeled videos to encourage self-supervised ViT features to become closer to each other if their corresponding spatial locations share similar movements, and vice versa. We use the proposed loss function to finetune vision transformers that were originally trained on static images. Our fine-tuning procedure outperforms state-of-the-art techniques for unsupervised semantic segmentation through linear probing, without the use of any labeled data. This procedure also demonstrates increased performance over original ViT networks across unsupervised object localization and semantic segmentation benchmarks.
Self-Supervised Learning of Object Segmentation from Unlabeled RGB-D Videos
Apr 09, 2023



This work proposes a self-supervised learning system for segmenting rigid objects in RGB images. The proposed pipeline is trained on unlabeled RGB-D videos of static objects, which can be captured with a camera carried by a mobile robot. A key feature of the self-supervised training process is a graph-matching algorithm that operates on the over-segmentation output of the point cloud that is reconstructed from each video. The graph matching, along with point cloud registration, is able to find reoccurring object patterns across videos and combine them into 3D object pseudo labels, even under occlusions or different viewing angles. Projected 2D object masks from 3D pseudo labels are used to train a pixel-wise feature extractor through contrastive learning. During online inference, a clustering method uses the learned features to cluster foreground pixels into object segments. Experiments highlight the method's effectiveness on both real and synthetic video datasets, which include cluttered scenes of tabletop objects. The proposed method outperforms existing unsupervised methods for object segmentation by a large margin.
Mono-STAR: Mono-camera Scene-level Tracking and Reconstruction
Jan 30, 2023



We present Mono-STAR, the first real-time 3D reconstruction system that simultaneously supports semantic fusion, fast motion tracking, non-rigid object deformation, and topological change under a unified framework. The proposed system solves a new optimization problem incorporating optical-flow-based 2D constraints to deal with fast motion and a novel semantic-aware deformation graph (SAD-graph) for handling topology change. We test the proposed system under various challenging scenes and demonstrate that it significantly outperforms existing state-of-the-art methods.