 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Abstract Sim2Real through Approximate Information States
Apr 16, 2026In recent years, reinforcement learning (RL) has shown remarkable success in robotics when a fast and accurate simulator is available for a given task. When using RL and simulation, more simulator realism is generally beneficial but becomes harder to obtain as robots are deployed in increasingly complex and widescale domains. In such settings, simulators will likely fail to model all relevant details of a given target task and this observation motivates the study of sim2real with simulators that leave out key task details. In this paper, we formalize and study the abstract sim2real problem: given an abstract simulator that models a target task at a coarse level of abstraction, how can we train a policy with RL in the abstract simulator and successfully transfer it to the real-world? Our first contribution is to formalize this problem using the language of state abstraction from the RL literature. This framing shows that an abstract simulator can be grounded to match the target task if the grounded abstract dynamics take the history of states into account. Based on the formalism, we then introduce a method that uses real-world task data to correct the dynamics of the abstract simulator. We then show that this method enables successful policy transfer both in sim2sim and sim2real evaluation.
Self-Supervised Learning of Object Segmentation from Unlabeled RGB-D Videos
Apr 09, 2023



This work proposes a self-supervised learning system for segmenting rigid objects in RGB images. The proposed pipeline is trained on unlabeled RGB-D videos of static objects, which can be captured with a camera carried by a mobile robot. A key feature of the self-supervised training process is a graph-matching algorithm that operates on the over-segmentation output of the point cloud that is reconstructed from each video. The graph matching, along with point cloud registration, is able to find reoccurring object patterns across videos and combine them into 3D object pseudo labels, even under occlusions or different viewing angles. Projected 2D object masks from 3D pseudo labels are used to train a pixel-wise feature extractor through contrastive learning. During online inference, a clustering method uses the learned features to cluster foreground pixels into object segments. Experiments highlight the method's effectiveness on both real and synthetic video datasets, which include cluttered scenes of tabletop objects. The proposed method outperforms existing unsupervised methods for object segmentation by a large margin.
USHER: Unbiased Sampling for Hindsight Experience Replay
Jul 03, 2022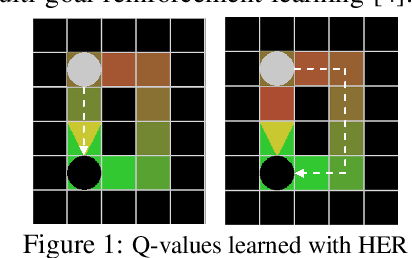
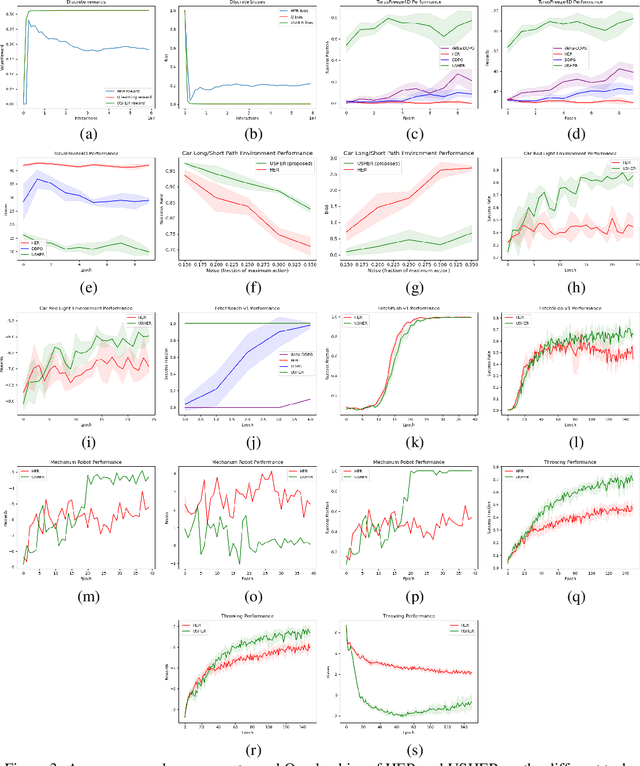
Dealing with sparse rewards is a long-standing challenge in reinforcement learning (RL). Hindsight Experience Replay (HER) addresses this problem by reusing failed trajectories for one goal as successful trajectories for another. This allows for both a minimum density of reward and for generalization across multiple goals. However, this strategy is known to result in a biased value function, as the update rule underestimates the likelihood of bad outcomes in a stochastic environment. We propose an asymptotically unbiased importance-sampling-based algorithm to address this problem without sacrificing performance on deterministic environments. We show its effectiveness on a range of robotic systems, including challenging high dimensional stochastic environments.