 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Variational Bounds of Mutual Information
May 16, 2019



Estimating and optimizing Mutual Information (MI) is core to many problems in machine learning; however, bounding MI in high dimensions is challenging. To establish tractable and scalable objectives, recent work has turned to variational bounds parameterized by neural networks, but the relationships and tradeoffs between these bounds remains unclear. In this work, we unify these recent developments in a single framework. We find that the existing variational lower bounds degrade when the MI is large, exhibiting either high bias or high variance. To address this problem, we introduce a continuum of lower bounds that encompasses previous bounds and flexibly trades off bias and variance. On high-dimensional, controlled problems, we empirically characterize the bias and variance of the bounds and their gradients and demonstrate the effectiveness of our new bounds for estimation and representation learning.
Wasserstein Dependency Measure for Representation Learning
Mar 28, 2019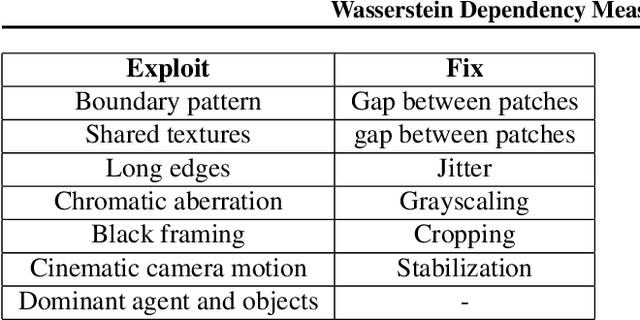
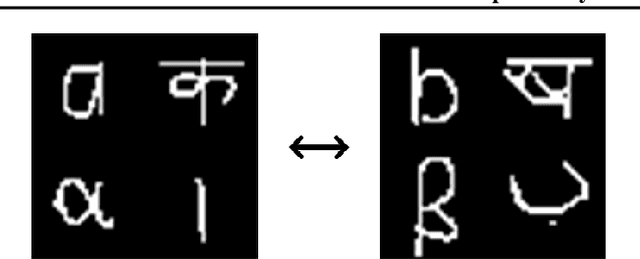

Mutual information maximization has emerged as a powerful learning objective for unsupervised representation learning obtaining state-of-the-art performance in applications such as object recognition, speech recognition, and reinforcement learning. However, such approaches are fundamentally limited since a tight lower bound of mutual information requires sample size exponential in the mutual information. This limits the applicability of these approaches for prediction tasks with high mutual information, such as in video understanding or reinforcement learning. In these settings, such techniques are prone to overfit, both in theory and in practice, and capture only a few of the relevant factors of variation. This leads to incomplete representations that are not optimal for downstream tasks. In this work, we empirically demonstrate that mutual information-based representation learning approaches do fail to learn complete representations on a number of designed and real-world tasks. To mitigate these problems we introduce the Wasserstein dependency measure, which learns more complete representations by using the Wasserstein distance instead of the KL divergence in the mutual information estimator. We show that a practical approximation to this theoretically motivated solution, constructed using Lipschitz constraint techniques from the GAN literature, achieves substantially improved results on tasks where incomplete representations are a major challenge.
Representation Learning with Contrastive Predictive Coding
Jul 10, 2018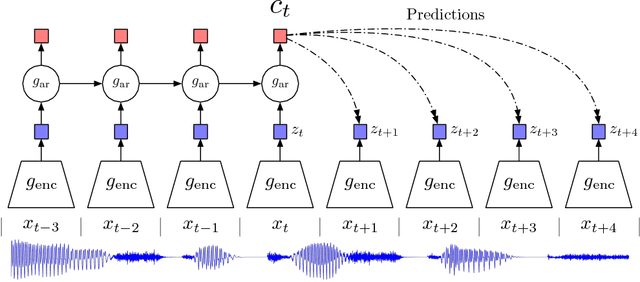
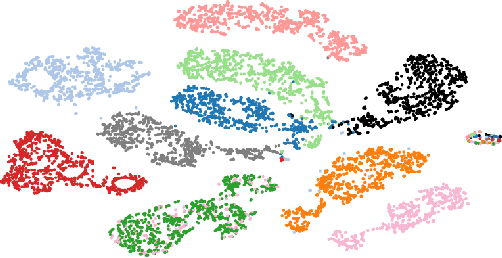
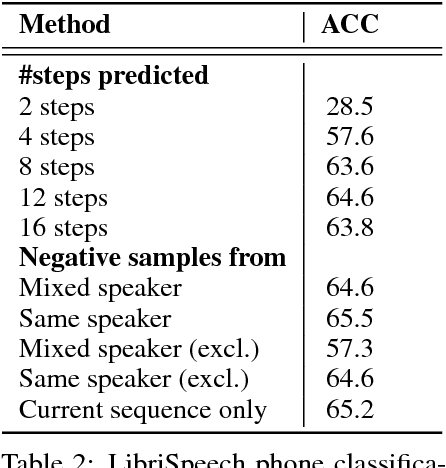
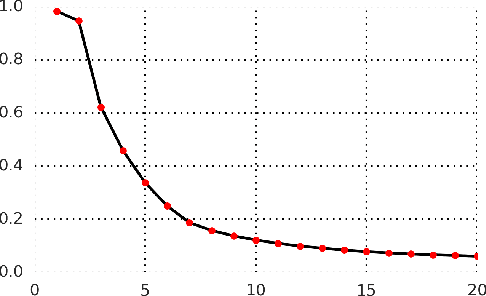
While supervised learning has enabled great progress in many applications, unsupervised learning has not seen such widespread adoption, and remains an important and challenging endeavor for artificial intelligence. In this work, we propose a universal unsupervised learning approach to extract useful representations from high-dimensional data, which we call Contrastive Predictive Coding. The key insight of our model is to learn such representations by predicting the future in latent space by using powerful autoregressive models. We use a probabilistic contrastive loss which induces the latent space to capture information that is maximally useful to predict future samples. It also makes the model tractable by using negative sampling. While most prior work has focused on evaluating representations for a particular modality, we demonstrate that our approach is able to learn useful representations achieving strong performance on four distinct domains: speech, images, text and reinforcement learning in 3D environments.
Efficient Neural Audio Synthesis
Jun 25, 2018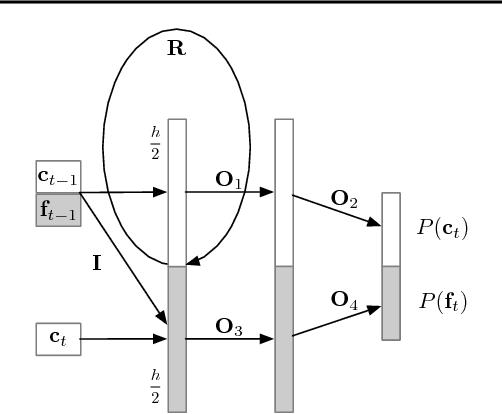

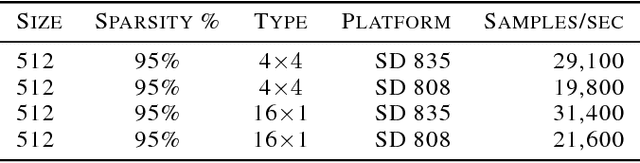
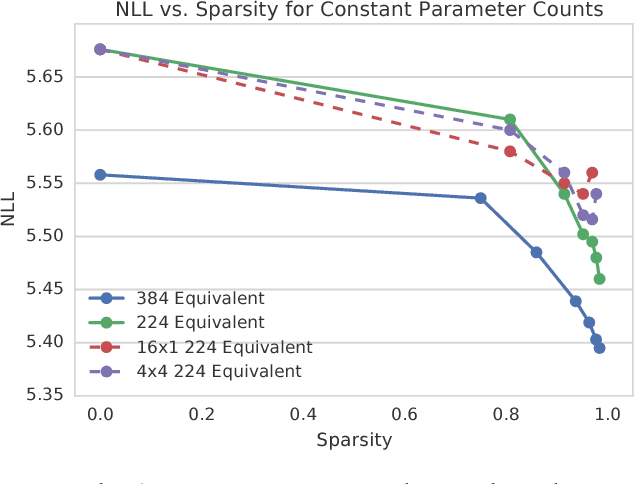
Sequential models achieve state-of-the-art results in audio, visual and textual domains with respect to both estimating the data distribution and generating high-quality samples. Efficient sampling for this class of models has however remained an elusive problem. With a focus on text-to-speech synthesis, we describe a set of general techniques for reducing sampling time while maintaining high output quality. We first describe a single-layer recurrent neural network, the WaveRNN, with a dual softmax layer that matches the quality of the state-of-the-art WaveNet model. The compact form of the network makes it possible to generate 24kHz 16-bit audio 4x faster than real time on a GPU. Second, we apply a weight pruning technique to reduce the number of weights in the WaveRNN. We find that, for a constant number of parameters, large sparse networks perform better than small dense networks and this relationship holds for sparsity levels beyond 96%. The small number of weights in a Sparse WaveRNN makes it possible to sample high-fidelity audio on a mobile CPU in real time. Finally, we propose a new generation scheme based on subscaling that folds a long sequence into a batch of shorter sequences and allows one to generate multiple samples at once. The Subscale WaveRNN produces 16 samples per step without loss of quality and offers an orthogonal method for increasing sampling efficiency.
Adversarial Risk and the Dangers of Evaluating Against Weak Attacks
Jun 12, 2018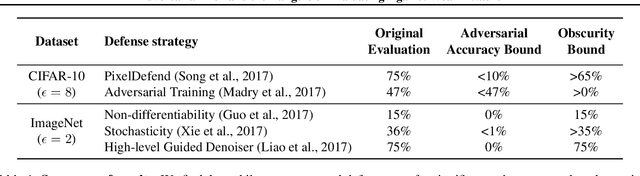
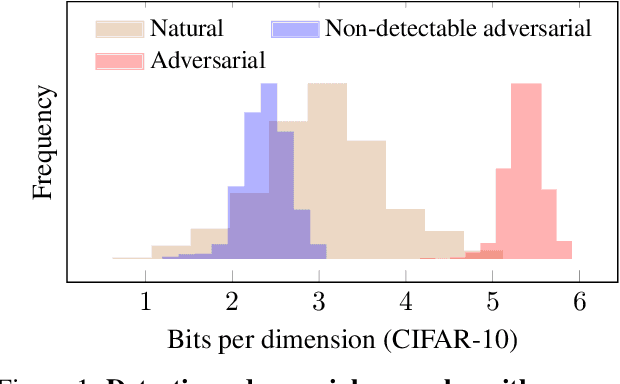
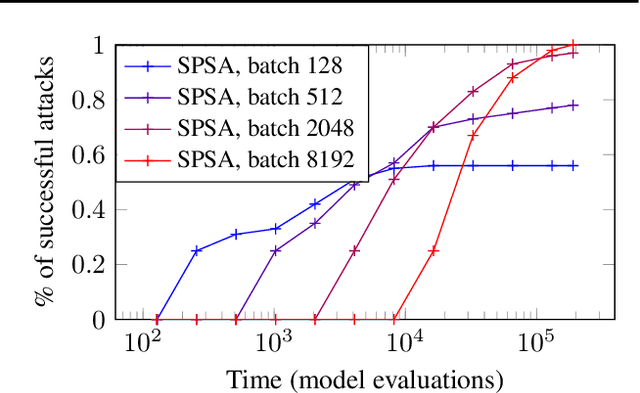
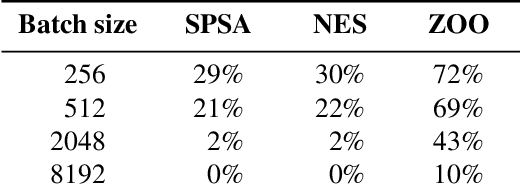
This paper investigates recently proposed approaches for defending against adversarial examples and evaluating adversarial robustness. We motivate 'adversarial risk' as an objective for achieving models robust to worst-case inputs. We then frame commonly used attacks and evaluation metrics as defining a tractable surrogate objective to the true adversarial risk. This suggests that models may optimize this surrogate rather than the true adversarial risk. We formalize this notion as 'obscurity to an adversary,' and develop tools and heuristics for identifying obscured models and designing transparent models. We demonstrate that this is a significant problem in practice by repurposing gradient-free optimization techniques into adversarial attacks, which we use to decrease the accuracy of several recently proposed defenses to near zero. Our hope is that our formulations and results will help researchers to develop more powerful defenses.
Neural Discrete Representation Learning
May 30, 2018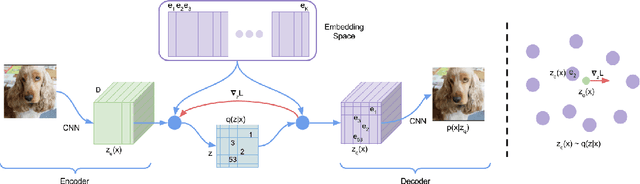



Learning useful representations without supervision remains a key challenge in machine learning. In this paper, we propose a simple yet powerful generative model that learns such discrete representations. Our model, the Vector Quantised-Variational AutoEncoder (VQ-VAE), differs from VAEs in two key ways: the encoder network outputs discrete, rather than continuous, codes; and the prior is learnt rather than static. In order to learn a discrete latent representation, we incorporate ideas from vector quantisation (VQ). Using the VQ method allows the model to circumvent issues of "posterior collapse" -- where the latents are ignored when they are paired with a powerful autoregressive decoder -- typically observed in the VAE framework. Pairing these representations with an autoregressive prior, the model can generate high quality images, videos, and speech as well as doing high quality speaker conversion and unsupervised learning of phonemes, providing further evidence of the utility of the learnt representations.
Associative Compression Networks for Representation Learning
Apr 26, 2018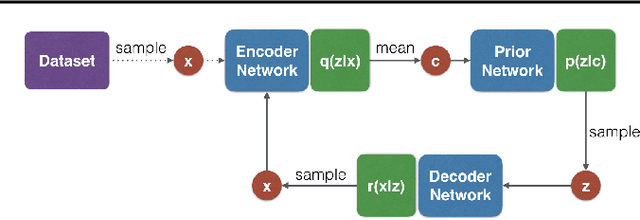
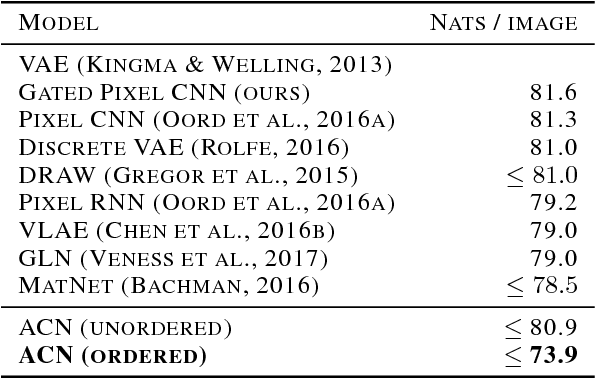

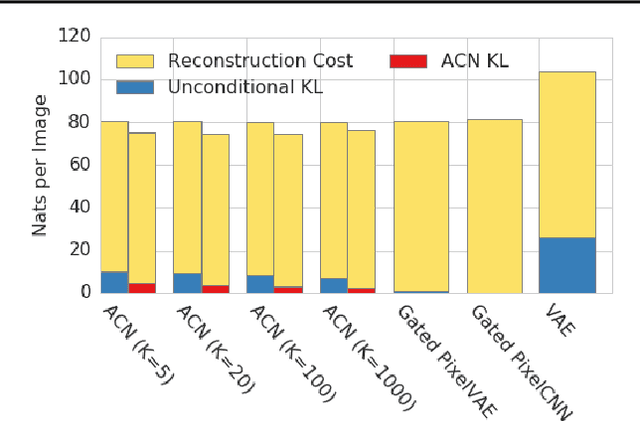
This paper introduces Associative Compression Networks (ACNs), a new framework for variational autoencoding with neural networks. The system differs from existing variational autoencoders (VAEs) in that the prior distribution used to model each code is conditioned on a similar code from the dataset. In compression terms this equates to sequentially transmitting the dataset using an ordering determined by proximity in latent space. Since the prior need only account for local, rather than global variations in the latent space, the coding cost is greatly reduced, leading to rich, informative codes. Crucially, the codes remain informative when powerful, autoregressive decoders are used, which we argue is fundamentally difficult with normal VAEs. Experimental results on MNIST, CIFAR-10, ImageNet and CelebA show that ACNs discover high-level latent features such as object class, writing style, pose and facial expression, which can be used to cluster and classify the data, as well as to generate diverse and convincing samples. We conclude that ACNs are a promising new direction for representation learning: one that steps away from IID modelling, and towards learning a structured description of the dataset as a whole.
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
Nov 28, 2017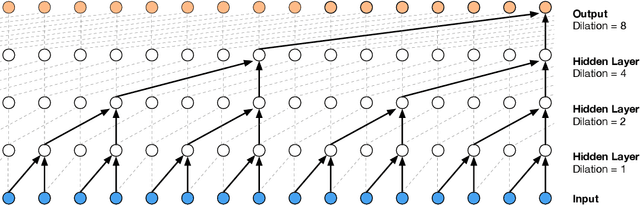
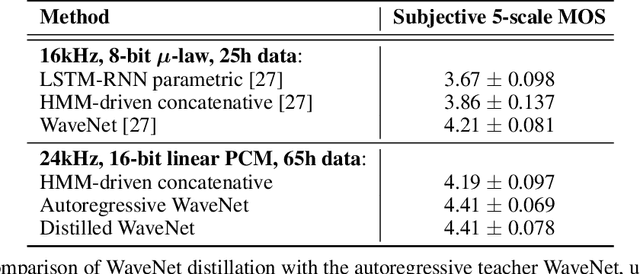
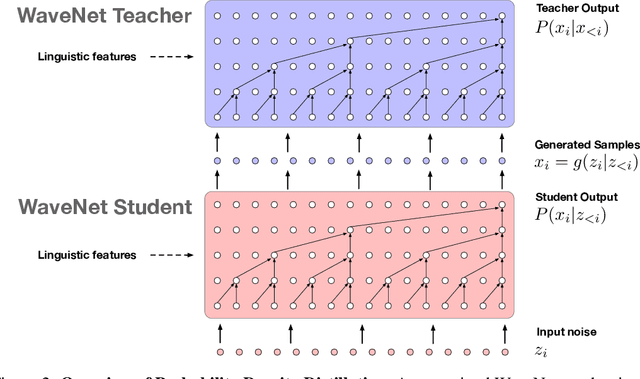
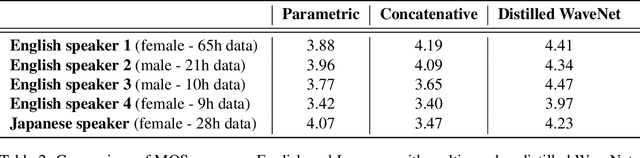
The recently-developed WaveNet architecture is the current state of the art in realistic speech synthesis, consistently rated as more natural sounding for many different languages than any previous system. However, because WaveNet relies on sequential generation of one audio sample at a time, it is poorly suited to today's massively parallel computers, and therefore hard to deploy in a real-time production setting. This paper introduces Probability Density Distillation, a new method for training a parallel feed-forward network from a trained WaveNet with no significant difference in quality. The resulting system is capable of generating high-fidelity speech samples at more than 20 times faster than real-time, and is deployed online by Google Assistant, including serving multiple English and Japanese voices.
Count-Based Exploration with Neural Density Models
Jun 14, 2017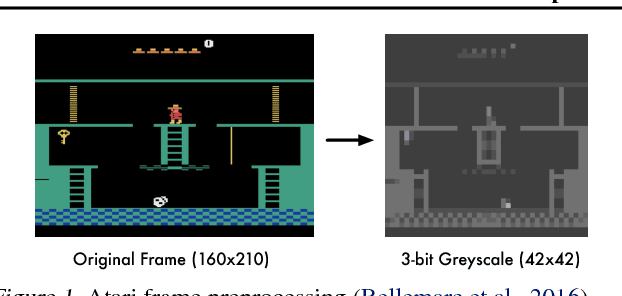
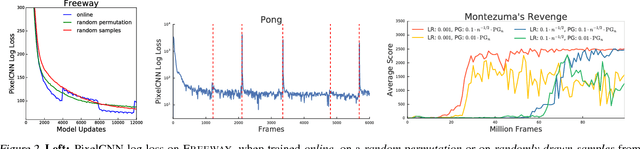
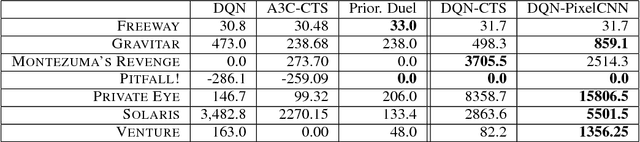
Bellemare et al. (2016) introduced the notion of a pseudo-count, derived from a density model, to generalize count-based exploration to non-tabular reinforcement learning. This pseudo-count was used to generate an exploration bonus for a DQN agent and combined with a mixed Monte Carlo update was sufficient to achieve state of the art on the Atari 2600 game Montezuma's Revenge. We consider two questions left open by their work: First, how important is the quality of the density model for exploration? Second, what role does the Monte Carlo update play in exploration? We answer the first question by demonstrating the use of PixelCNN, an advanced neural density model for images, to supply a pseudo-count. In particular, we examine the intrinsic difficulties in adapting Bellemare et al.'s approach when assumptions about the model are violated. The result is a more practical and general algorithm requiring no special apparatus. We combine PixelCNN pseudo-counts with different agent architectures to dramatically improve the state of the art on several hard Atari games. One surprising finding is that the mixed Monte Carlo update is a powerful facilitator of exploration in the sparsest of settings, including Montezuma's Revenge.
Neural Machine Translation in Linear Time
Mar 15, 2017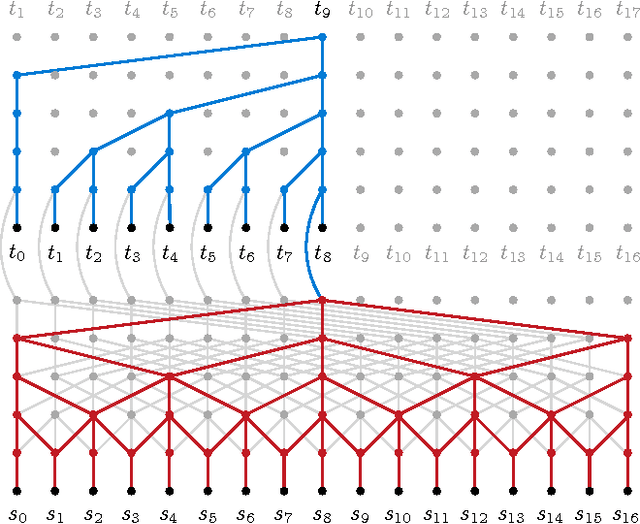
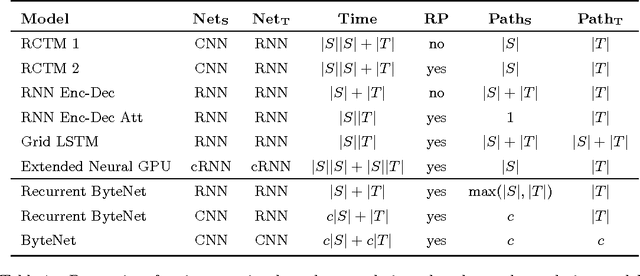


We present a novel neural network for processing sequences. The ByteNet is a one-dimensional convolutional neural network that is composed of two parts, one to encode the source sequence and the other to decode the target sequence. The two network parts are connected by stacking the decoder on top of the encoder and preserving the temporal resolution of the sequences. To address the differing lengths of the source and the target, we introduce an efficient mechanism by which the decoder is dynamically unfolded over the representation of the encoder. The ByteNet uses dilation in the convolutional layers to increase its receptive field. The resulting network has two core properties: it runs in time that is linear in the length of the sequences and it sidesteps the need for excessive memorization. The ByteNet decoder attains state-of-the-art performance on character-level language modelling and outperforms the previous best results obtained with recurrent networks. The ByteNet also achieves state-of-the-art performance on character-to-character machine translation on the English-to-German WMT translation task, surpassing comparable neural translation models that are based on recurrent networks with attentional pooling and run in quadratic time. We find that the latent alignment structure contained in the representations reflects the expected alignment between the tokens.