 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning GPT-5 for GPU Kernel Generation
Feb 11, 2026Developing efficient GPU kernels is essential for scaling modern AI systems, yet it remains a complex task due to intricate hardware architectures and the need for specialized optimization expertise. Although Large Language Models (LLMs) demonstrate strong capabilities in general sequential code generation, they face significant challenges in GPU code generation because of the scarcity of high-quality labeled training data, compiler biases when generating synthetic solutions, and limited generalization across hardware generations. This precludes supervised fine-tuning (SFT) as a scalable methodology for improving current LLMs. In contrast, reinforcement learning (RL) offers a data-efficient and adaptive alternative but requires access to relevant tools, careful selection of training problems, and a robust evaluation environment. We present Makora's environment and tools for reinforcement learning finetuning of frontier models and report our results from fine-tuning GPT-5 for Triton code generation. In the single-attempt setting, our fine-tuned model improves kernel correctness from 43.7% to 77.0% (+33.3 percentage points) and increases the fraction of problems outperforming TorchInductor from 14.8% to 21.8% (+7 percentage points) compared to baseline GPT-5, while exceeding prior state-of-the-art models on KernelBench. When integrated into a full coding agent, it is able to solve up to 97.4% of problems in an expanded KernelBench suite, outperforming the PyTorch TorchInductor compiler on 72.9% of problems with a geometric mean speedup of 2.12x. Our work demonstrates that targeted post-training with reinforcement learning can unlock LLM capabilities in highly specialized technical domains where traditional supervised learning is limited by data availability, opening new pathways for AI-assisted accelerator programming.
Software Defect Prediction Based On Deep Learning Models: Performance Study
Apr 02, 2020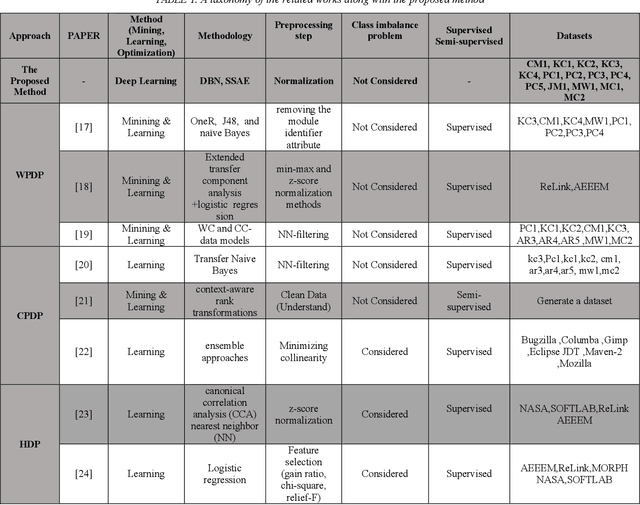
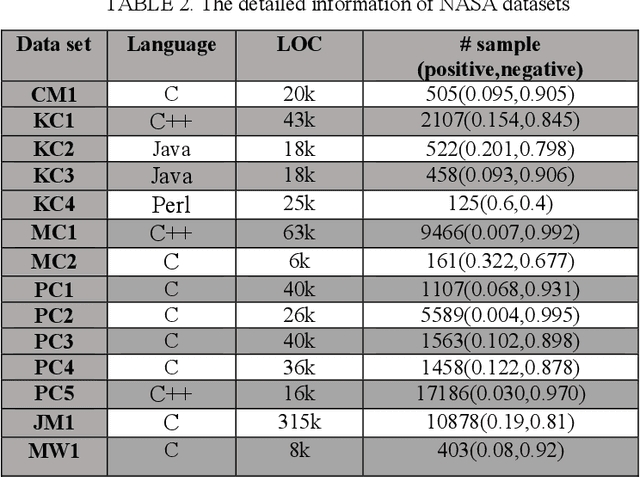


In recent years, defect prediction, one of the major software engineering problems, has been in the focus of researchers since it has a pivotal role in estimating software errors and faulty modules. Researchers with the goal of improving prediction accuracy have developed many models for software defect prediction. However, there are a number of critical conditions and theoretical problems in order to achieve better results. In this paper, two deep learning models, Stack Sparse Auto-Encoder (SSAE) and Deep Belief Network (DBN), are deployed to classify NASA datasets, which are unbalanced and have insufficient samples. According to the conducted experiment, the accuracy for the datasets with sufficient samples is enhanced and beside this SSAE model gains better results in comparison to DBN model in the majority of evaluation metrics.