 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Language-Independent Approach for Automatic Computation of Vowel Articulation Features in Dysarthric Speech Assessment
Aug 16, 2021
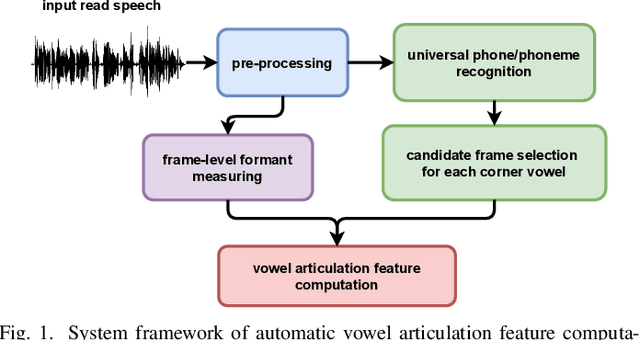
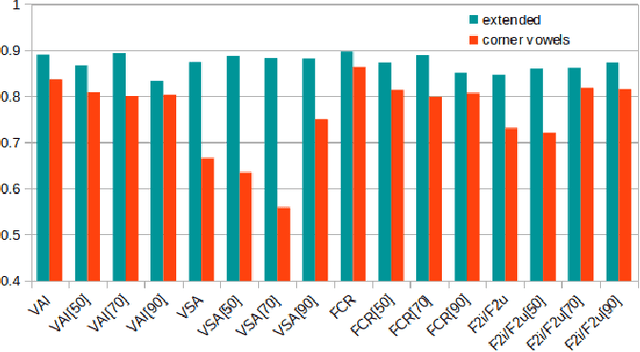
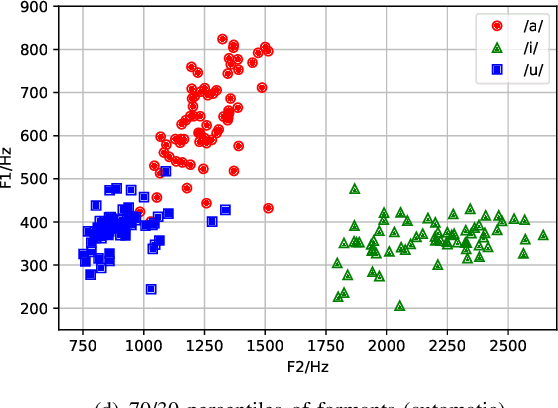
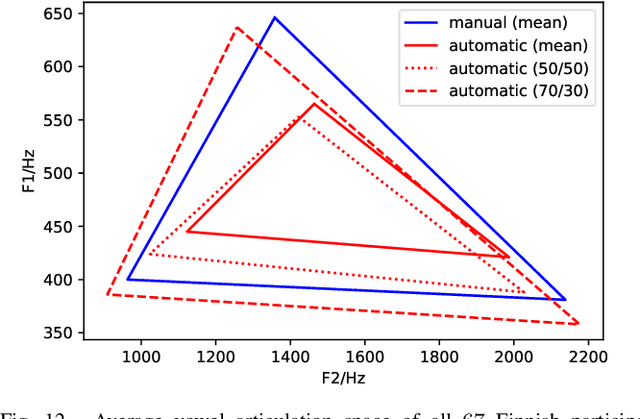
Imprecise vowel articulation can be observed in people with Parkinson's disease (PD). Acoustic features measuring vowel articulation have been demonstrated to be effective indicators of PD in its assessment. Standard clinical vowel articulation features of vowel working space area (VSA), vowel articulation index (VAI) and formants centralization ratio (FCR), are derived the first two formants of the three corner vowels /a/, /i/ and /u/. Conventionally, manual annotation of the corner vowels from speech data is required before measuring vowel articulation. This process is time-consuming. The present work aims to reduce human effort in clinical analysis of PD speech by proposing an automatic pipeline for vowel articulation assessment. The method is based on automatic corner vowel detection using a language universal phoneme recognizer, followed by statistical analysis of the formant data. The approach removes the restrictions of prior knowledge of speaking content and the language in question. Experimental results on a Finnish PD speech corpus demonstrate the efficacy and reliability of the proposed automatic method in deriving VAI, VSA, FCR and F2i/F2u (the second formant ratio for vowels /i/ and /u/). The automatically computed parameters are shown to be highly correlated with features computed with manual annotations of corner vowels. In addition, automatically and manually computed vowel articulation features have comparable correlations with experts' ratings on speech intelligibility, voice impairment and overall severity of communication disorder. Language-independence of the proposed approach is further validated on a Spanish PD database, PC-GITA, as well as on TORGO corpus of English dysarthric speech.
* 16 pages
Performance Evaluation of Deep Convolutional Maxout Neural Network in Speech Recognition
May 04, 2021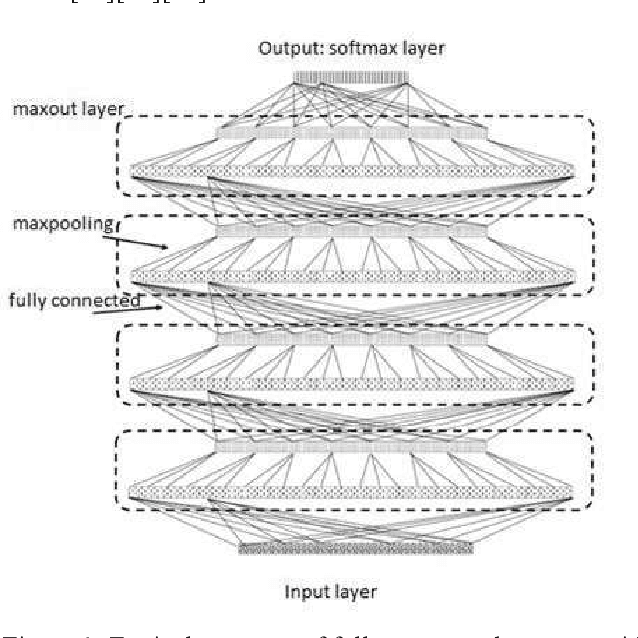
In this paper, various structures and methods of Deep Artificial Neural Networks (DNN) will be evaluated and compared for the purpose of continuous Persian speech recognition. One of the first models of neural networks used in speech recognition applications were fully connected Neural Networks (FCNNs) and, consequently, Deep Neural Networks (DNNs). Although these models have better performance compared to GMM / HMM models, they do not have the proper structure to model local speech information. Convolutional Neural Network (CNN) is a good option for modeling the local structure of biological signals, including speech signals. Another issue that Deep Artificial Neural Networks face, is the convergence of networks on training data. The main inhibitor of convergence is the presence of local minima in the process of training. Deep Neural Network Pre-training methods, despite a large amount of computing, are powerful tools for crossing the local minima. But the use of appropriate neuronal models in the network structure seems to be a better solution to this problem. The Rectified Linear Unit neuronal model and the Maxout model are the most suitable neuronal models presented to this date. Several experiments were carried out to evaluate the performance of the methods and structures mentioned. After verifying the proper functioning of these methods, a combination of all models was implemented on FARSDAT speech database for continuous speech recognition. The results obtained from the experiments show that the combined model (CMDNN) improves the performance of ANNs in speech recognition versus the pre-trained fully connected NNs with sigmoid neurons by about 3%.
* 6 pages, 2 figures, conference paper submitted to 2018 25th National and 3rd International Iranian Conference on Biomedical Engineering (ICBME)
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jul 01, 2021

This paper describes the winning approach in the Shared Task 3 at SwissText 2021 on Swiss German Speech to Standard German Text, a public competition on dialect recognition and translation. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Speaker activity driven neural speech extraction
Jan 14, 2021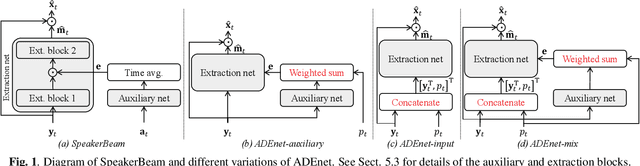

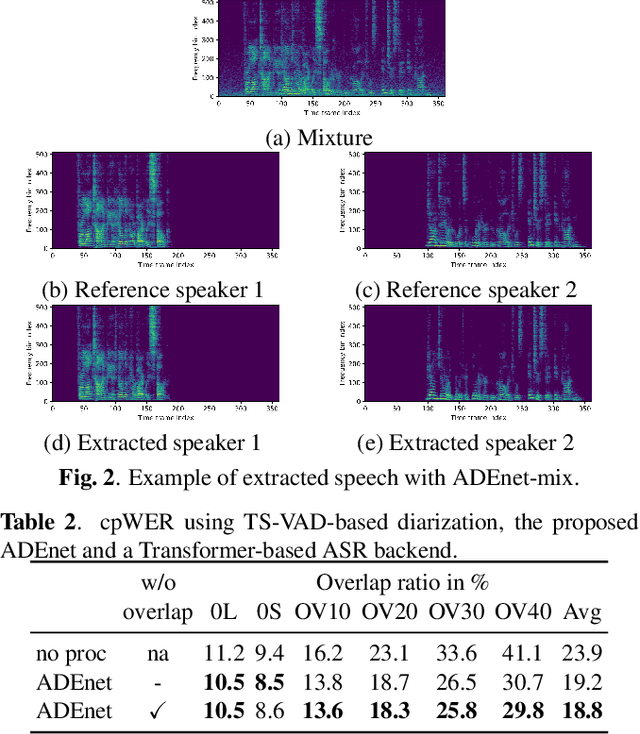
Target speech extraction, which extracts the speech of a target speaker in a mixture given auxiliary speaker clues, has recently received increased interest. Various clues have been investigated such as pre-recorded enrollment utterances, direction information, or video of the target speaker. In this paper, we explore the use of speaker activity information as an auxiliary clue for single-channel neural network-based speech extraction. We propose a speaker activity driven speech extraction neural network (ADEnet) and show that it can achieve performance levels competitive with enrollment-based approaches, without the need for pre-recordings. We further demonstrate the potential of the proposed approach for processing meeting-like recordings, where speaker activity obtained from a diarization system is used as a speaker clue for ADEnet. We show that this simple yet practical approach can successfully extract speakers after diarization, which leads to improved ASR performance when using a single microphone, especially in high overlapping conditions, with a relative word error rate reduction of up to 25 %.
Assessing the intelligibility of vocoded speech using a remote testing framework
May 28, 2021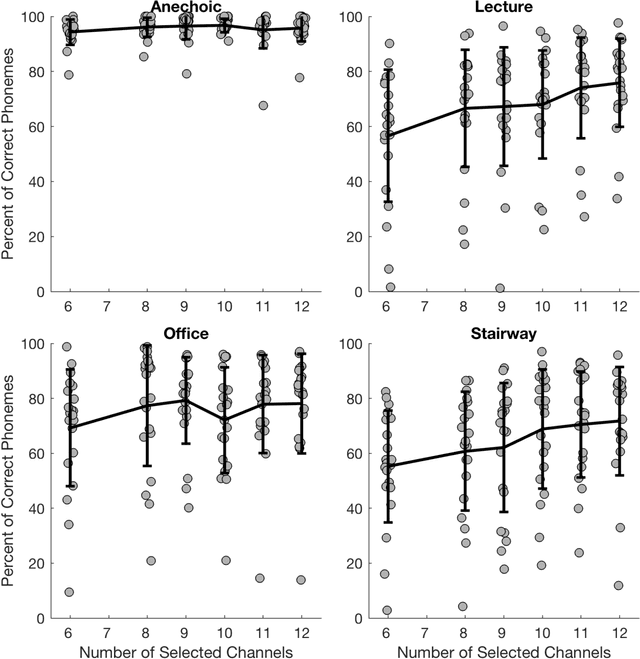
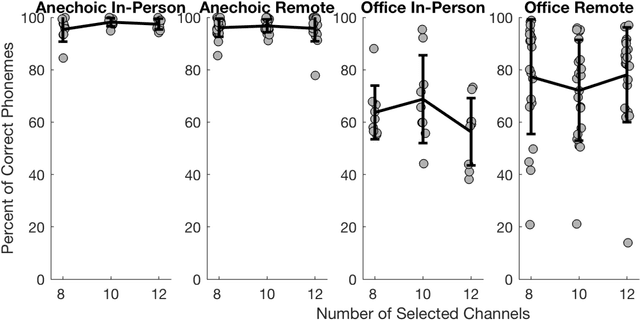
Over the past year, remote speech intelligibility testing has become a popular and necessary alternative to traditional in-person experiments due to the need for physical distancing during the COVID-19 pandemic. A remote framework was developed for conducting speech intelligibility tests with normal hearing listeners. In this study, subjects used their personal computers to complete sentence recognition tasks in anechoic and reverberant listening environments. The results obtained using this remote framework were compared with previously collected in-lab results, and showed higher levels of speech intelligibility among remote study participants than subjects who completed the test in the laboratory.
DRAFT: A Novel Framework to Reduce Domain Shifting in Self-supervised Learning and Its Application to Children's ASR
Jun 16, 2022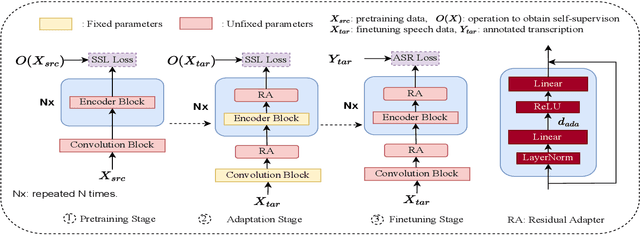
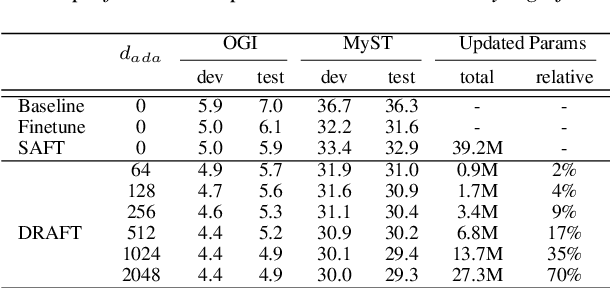
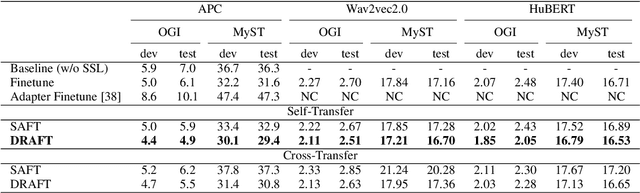
Self-supervised learning (SSL) in the pretraining stage using un-annotated speech data has been successful in low-resource automatic speech recognition (ASR) tasks. However, models trained through SSL are biased to the pretraining data which is usually different from the data used in finetuning tasks, causing a domain shifting problem, and thus resulting in limited knowledge transfer. We propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models through an additional adaptation stage. In DRAFT, residual adapters (RAs) are inserted in the pretrained model to learn domain-related information with the same SSL loss as the pretraining stage. Only RA parameters are updated during the adaptation stage. DRAFT is agnostic to the type of SSL method used and is evaluated with three widely used approaches: APC, Wav2vec2.0, and HuBERT. On two child ASR tasks (OGI and MyST databases), using SSL models trained with un-annotated adult speech data (Librispeech), relative WER improvements of up to 19.7% are observed when compared to the pretrained models without adaptation. Additional experiments examined the potential of cross knowledge transfer between the two datasets and the results are promising, showing a broader usage of the proposed DRAFT framework.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
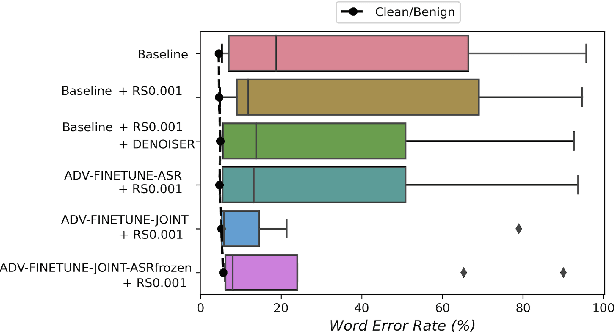

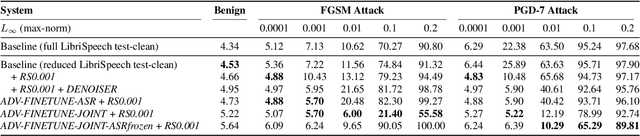
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
Read it to me: An emotionally aware Speech Narration Application
Sep 06, 2022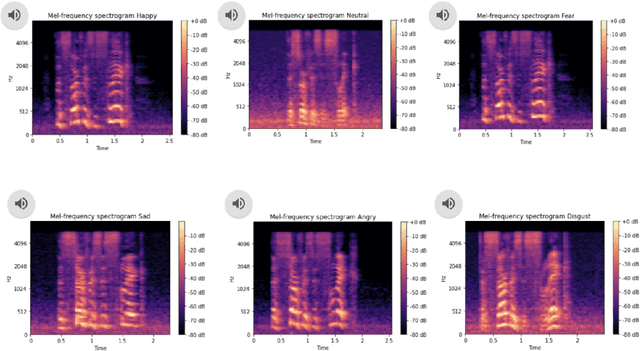

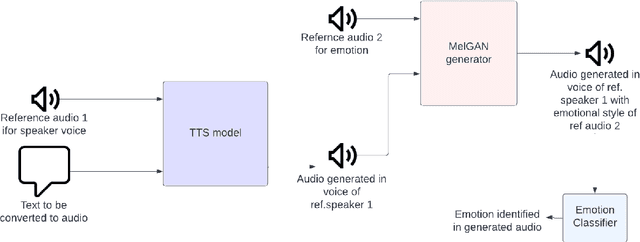
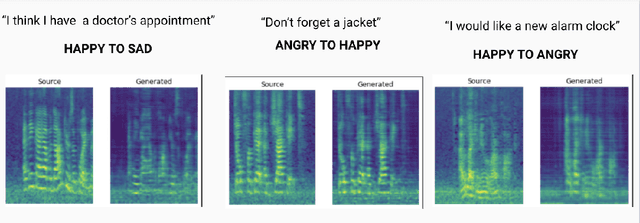
In this work we try to perform emotional style transfer on audios. In particular, MelGAN-VC architecture is explored for various emotion-pair transfers. The generated audio is then classified using an LSTM-based emotion classifier for audio. We find that "sad" audio is generated well as compared to "happy" or "anger" as people have similar expressions of sadness.
Ceasing hate withMoH: Hate Speech Detection in Hindi-English Code-Switched Language
Oct 18, 2021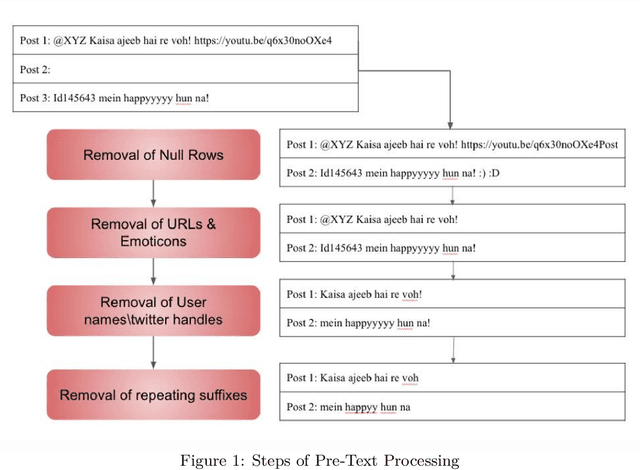


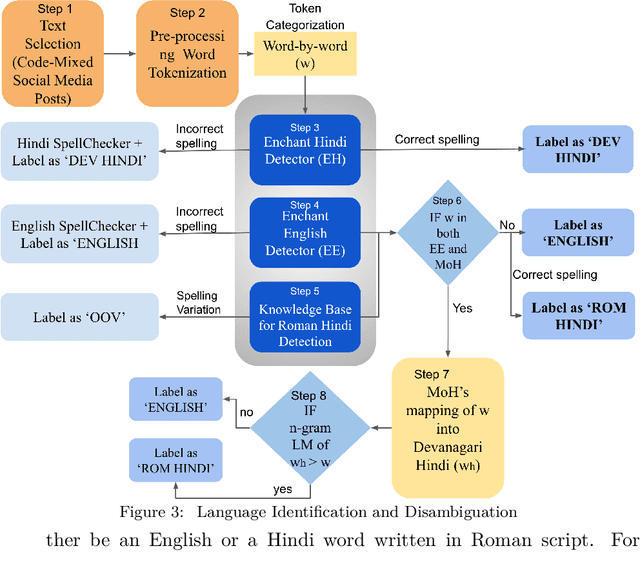
Social media has become a bedrock for people to voice their opinions worldwide. Due to the greater sense of freedom with the anonymity feature, it is possible to disregard social etiquette online and attack others without facing severe consequences, inevitably propagating hate speech. The current measures to sift the online content and offset the hatred spread do not go far enough. One factor contributing to this is the prevalence of regional languages in social media and the paucity of language flexible hate speech detectors. The proposed work focuses on analyzing hate speech in Hindi-English code-switched language. Our method explores transformation techniques to capture precise text representation. To contain the structure of data and yet use it with existing algorithms, we developed MoH or Map Only Hindi, which means "Love" in Hindi. MoH pipeline consists of language identification, Roman to Devanagari Hindi transliteration using a knowledge base of Roman Hindi words. Finally, it employs the fine-tuned Multilingual Bert and MuRIL language models. We conducted several quantitative experiment studies on three datasets and evaluated performance using Precision, Recall, and F1 metrics. The first experiment studies MoH mapped text's performance with classical machine learning models and shows an average increase of 13% in F1 scores. The second compares the proposed work's scores with those of the baseline models and offers a rise in performance by 6%. Finally, the third reaches the proposed MoH technique with various data simulations using the existing transliteration library. Here, MoH outperforms the rest by 15%. Our results demonstrate a significant improvement in the state-of-the-art scores on all three datasets.
TS-RIR: Translated synthetic room impulse responses for speech augmentation
Apr 03, 2021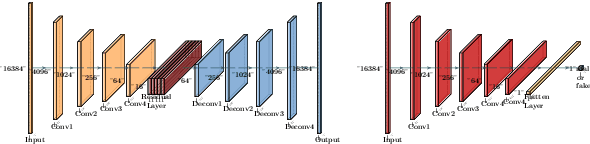
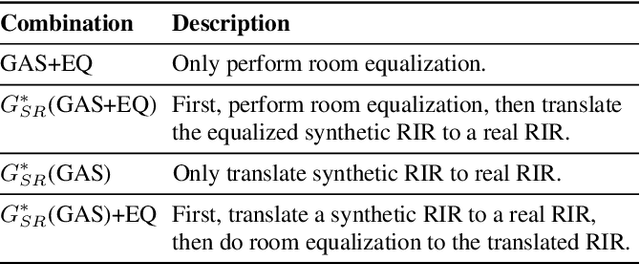
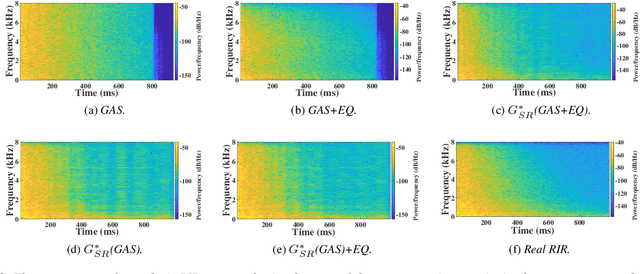
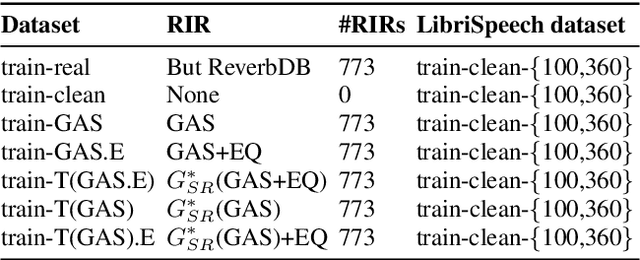
We present a method for improving the quality of synthetic room impulse responses for far-field speech recognition. We bridge the gap between the fidelity of synthetic room impulse responses (RIRs) and the real room impulse responses using our novel, TS-RIRGAN architecture. Given a synthetic RIR in the form of raw audio, we use TS-RIRGAN to translate it into a real RIR. We also perform real-world sub-band room equalization on the translated synthetic RIR. Our overall approach improves the quality of synthetic RIRs by compensating low-frequency wave effects, similar to those in real RIRs. We evaluate the performance of improved synthetic RIRs on a far-field speech dataset augmented by convolving the LibriSpeech clean speech dataset [1] with RIRs and adding background noise. We show that far-field speech augmented using our improved synthetic RIRs reduces the word error rate by up to 19.9% in Kaldi far-field automatic speech recognition benchmark [2].