 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Graph-Based Context-Aware Model to Understand Online Conversations
Nov 16, 2022
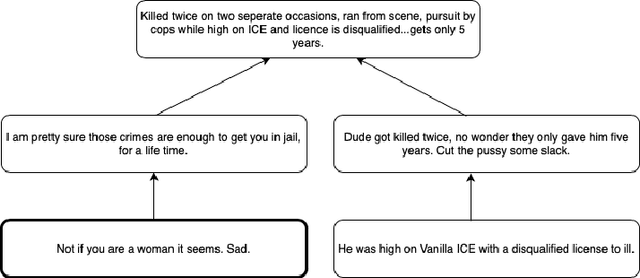
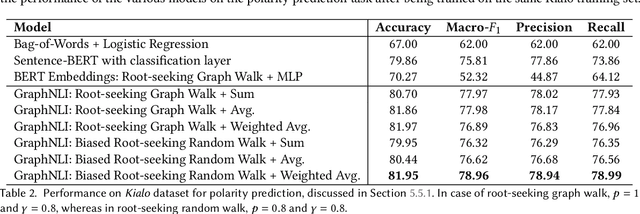
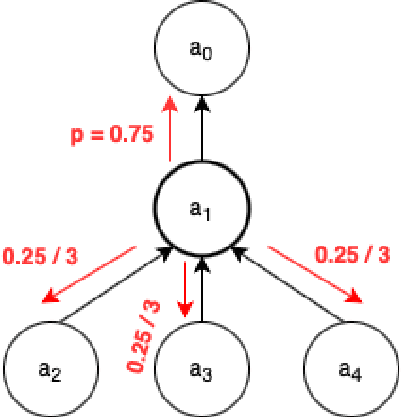
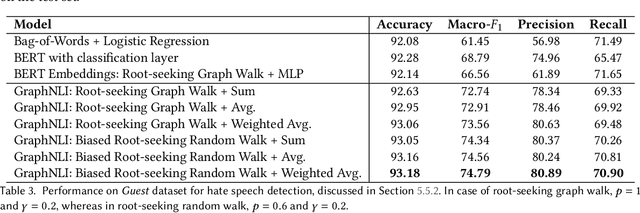
Online forums that allow for participatory engagement between users have been transformative for the public discussion of many important issues. However, such conversations can sometimes escalate into full-blown exchanges of hate and misinformation. Existing approaches in natural language processing (NLP), such as deep learning models for classification tasks, use as inputs only a single comment or a pair of comments depending upon whether the task concerns the inference of properties of the individual comments or the replies between pairs of comments, respectively. But in online conversations, comments and replies may be based on external context beyond the immediately relevant information that is input to the model. Therefore, being aware of the conversations' surrounding contexts should improve the model's performance for the inference task at hand. We propose GraphNLI, a novel graph-based deep learning architecture that uses graph walks to incorporate the wider context of a conversation in a principled manner. Specifically, a graph walk starts from a given comment and samples "nearby" comments in the same or parallel conversation threads, which results in additional embeddings that are aggregated together with the initial comment's embedding. We then use these enriched embeddings for downstream NLP prediction tasks that are important for online conversations. We evaluate GraphNLI on two such tasks - polarity prediction and misogynistic hate speech detection - and found that our model consistently outperforms all relevant baselines for both tasks. Specifically, GraphNLI with a biased root-seeking random walk performs with a macro-F1 score of 3 and 6 percentage points better than the best-performing BERT-based baselines for the polarity prediction and hate speech detection tasks, respectively.
Universal versus system-specific features of punctuation usage patterns in~major Western~languages
Dec 21, 2022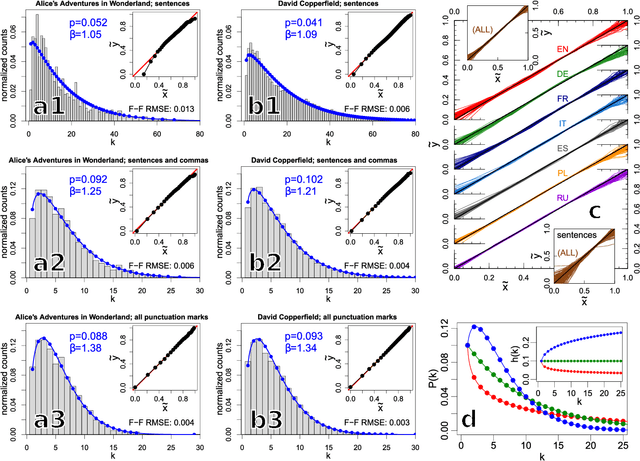
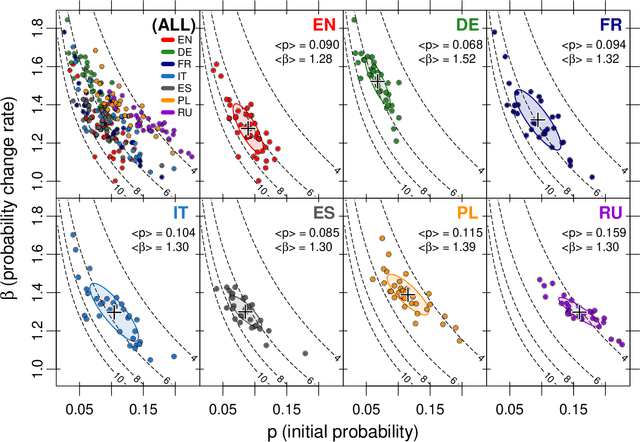
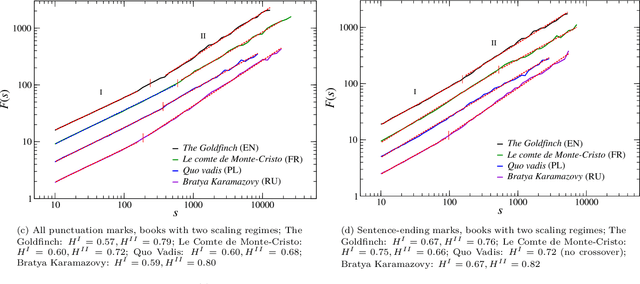
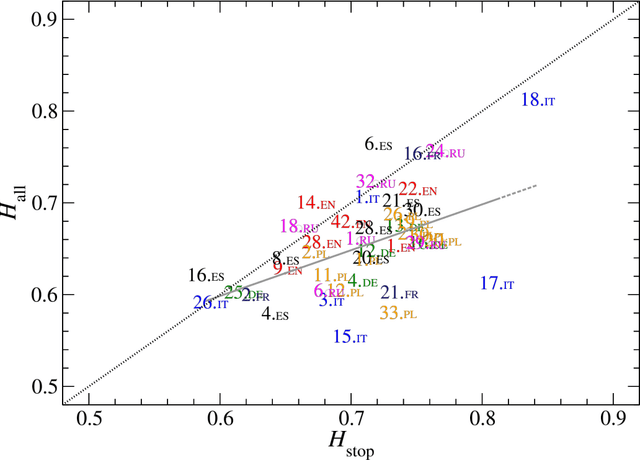
The celebrated proverb that "speech is silver, silence is golden" has a long multinational history and multiple specific meanings. In written texts punctuation can in fact be considered one of its manifestations. Indeed, the virtue of effectively speaking and writing involves - often decisively - the capacity to apply the properly placed breaks. In the present study, based on a large corpus of world-famous and representative literary texts in seven major Western languages, it is shown that the distribution of intervals between consecutive punctuation marks in almost all texts can universally be characterised by only two parameters of the discrete Weibull distribution which can be given an intuitive interpretation in terms of the so-called hazard function. The values of these two parameters tend to be language-specific, however, and even appear to navigate translations. The properties of the computed hazard functions indicate that among the studied languages, English turns out to be the least constrained by the necessity to place a consecutive punctuation mark to partition a sequence of words. This may suggest that when compared to other studied languages, English is more flexible, in the sense of allowing longer uninterrupted sequences of words. Spanish reveals similar tendency to only a bit lesser extent.
L3Cube-MahaHate: A Tweet-based Marathi Hate Speech Detection Dataset and BERT models
Mar 25, 2022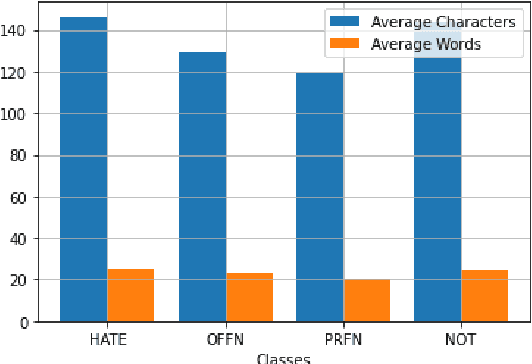
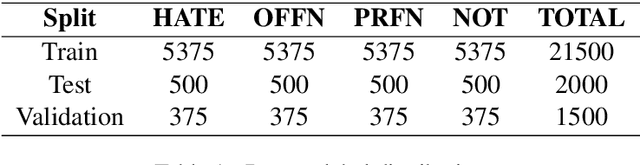
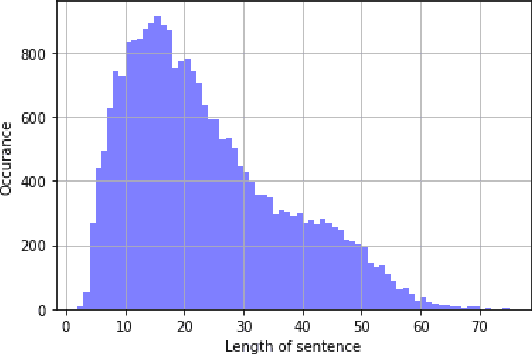
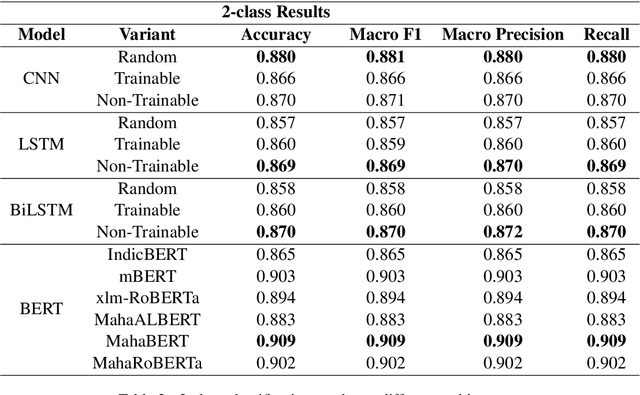
Social media platforms are used by a large number of people prominently to express their thoughts and opinions. However, these platforms have contributed to a substantial amount of hateful and abusive content as well. Therefore, it is important to curb the spread of hate speech on these platforms. In India, Marathi is one of the most popular languages used by a wide audience. In this work, we present L3Cube-MahaHate, the first major Hate Speech Dataset in Marathi. The dataset is curated from Twitter, annotated manually. Our dataset consists of over 25000 distinct tweets labeled into four major classes i.e hate, offensive, profane, and not. We present the approaches used for collecting and annotating the data and the challenges faced during the process. Finally, we present baseline classification results using deep learning models based on CNN, LSTM, and Transformers. We explore mono-lingual and multi-lingual variants of BERT like MahaBERT, IndicBERT, mBERT, and xlm-RoBERTa and show that mono-lingual models perform better than their multi-lingual counterparts. The MahaBERT model provides the best results on L3Cube-MahaHate Corpus. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Pre-Avatar: An Automatic Presentation Generation Framework Leveraging Talking Avatar
Oct 13, 2022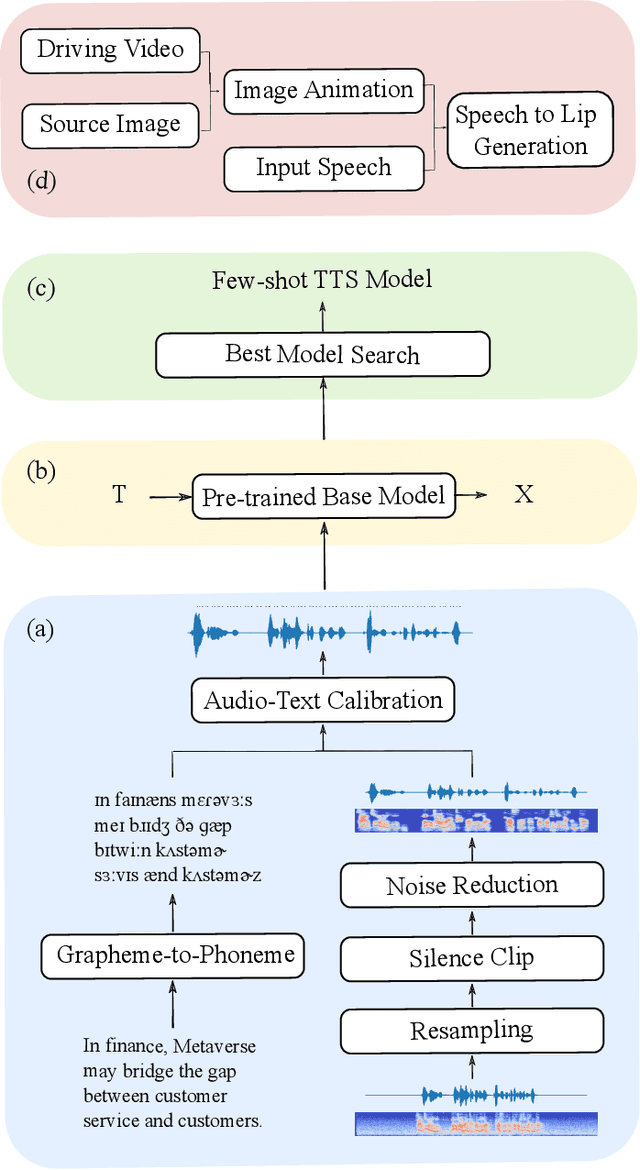
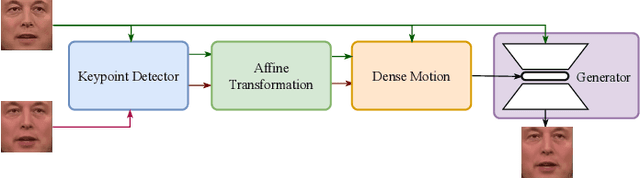

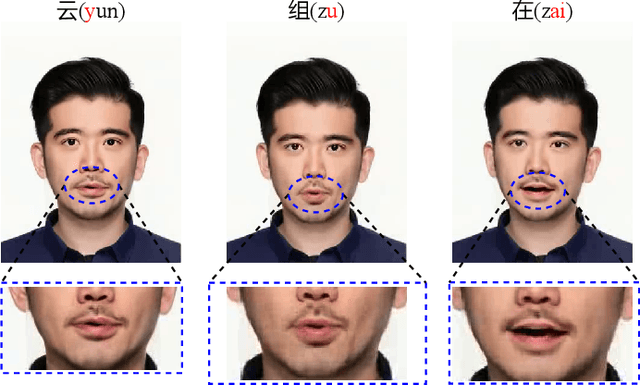
Since the beginning of the COVID-19 pandemic, remote conferencing and school-teaching have become important tools. The previous applications aim to save the commuting cost with real-time interactions. However, our application is going to lower the production and reproduction costs when preparing the communication materials. This paper proposes a system called Pre-Avatar, generating a presentation video with a talking face of a target speaker with 1 front-face photo and a 3-minute voice recording. Technically, the system consists of three main modules, user experience interface (UEI), talking face module and few-shot text-to-speech (TTS) module. The system firstly clones the target speaker's voice, and then generates the speech, and finally generate an avatar with appropriate lip and head movements. Under any scenario, users only need to replace slides with different notes to generate another new video. The demo has been released here and will be published as free software for use.
Label-free Knowledge Distillation with Contrastive Loss for Light-weight Speaker Recognition
Dec 06, 2022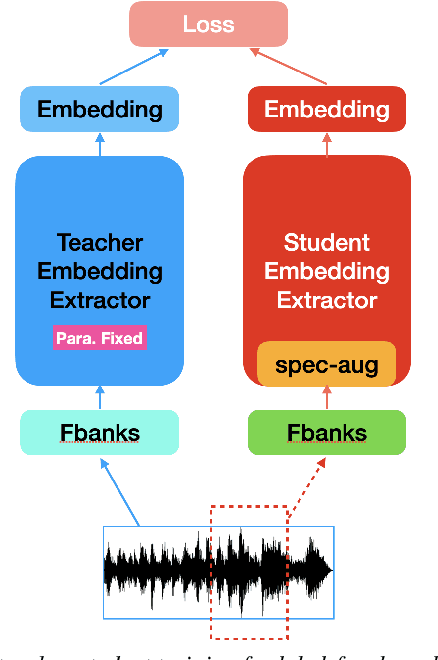
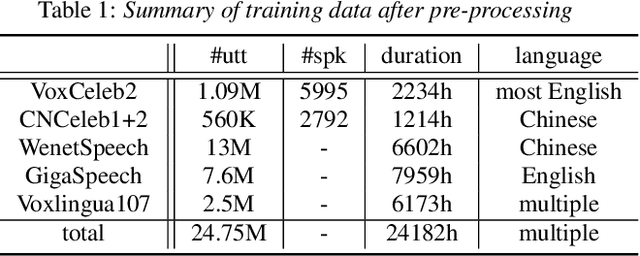
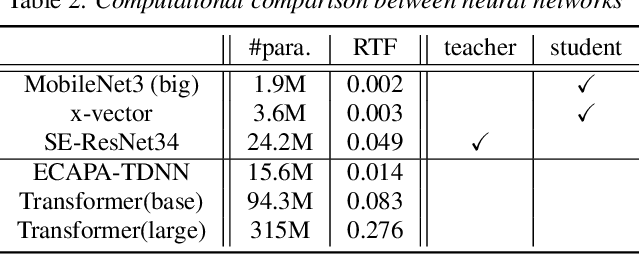
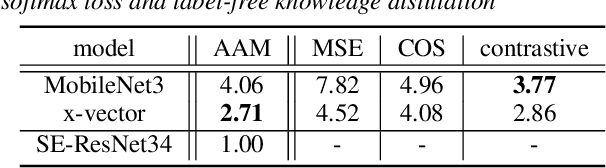
Very deep models for speaker recognition (SR) have demonstrated remarkable performance improvement in recent research. However, it is impractical to deploy these models for on-device applications with constrained computational resources. On the other hand, light-weight models are highly desired in practice despite their sub-optimal performance. This research aims to improve light-weight SR models through large-scale label-free knowledge distillation (KD). Existing KD approaches for SR typically require speaker labels to learn task-specific knowledge, due to the inefficiency of conventional loss for distillation. To address the inefficiency problem and achieve label-free KD, we propose to employ the contrastive loss from self-supervised learning for distillation. Extensive experiments are conducted on a collection of public speech datasets from diverse sources. Results on light-weight SR models show that the proposed approach of label-free KD with contrastive loss consistently outperforms both conventional distillation methods and self-supervised learning methods by a significant margin.
Learning the joint distribution of two sequences using little or no paired data
Dec 06, 2022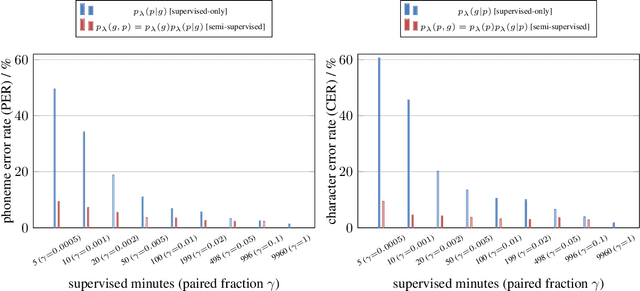
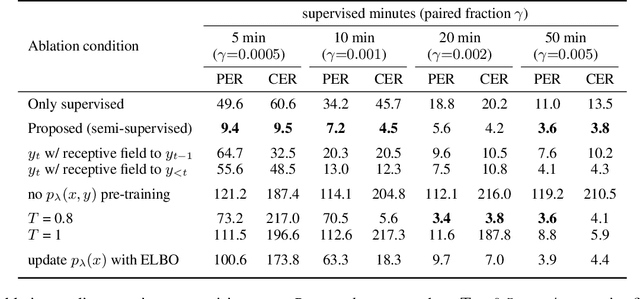

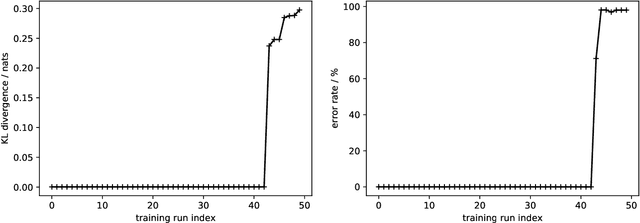
We present a noisy channel generative model of two sequences, for example text and speech, which enables uncovering the association between the two modalities when limited paired data is available. To address the intractability of the exact model under a realistic data setup, we propose a variational inference approximation. To train this variational model with categorical data, we propose a KL encoder loss approach which has connections to the wake-sleep algorithm. Identifying the joint or conditional distributions by only observing unpaired samples from the marginals is only possible under certain conditions in the data distribution and we discuss under what type of conditional independence assumptions that might be achieved, which guides the architecture designs. Experimental results show that even tiny amount of paired data (5 minutes) is sufficient to learn to relate the two modalities (graphemes and phonemes here) when a massive amount of unpaired data is available, paving the path to adopting this principled approach for all seq2seq models in low data resource regimes.
Joint Audio-Text Model for Expressive Speech-Driven 3D Facial Animation
Dec 07, 2021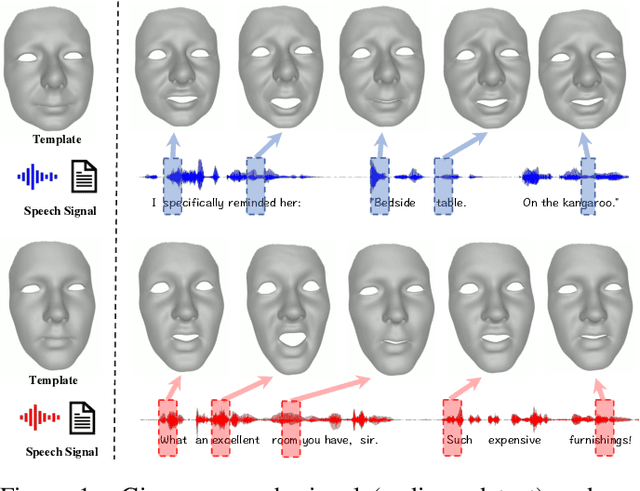
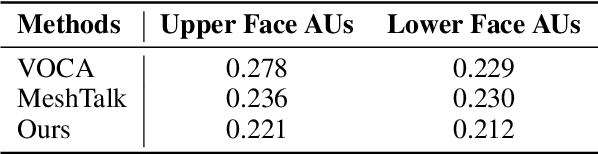
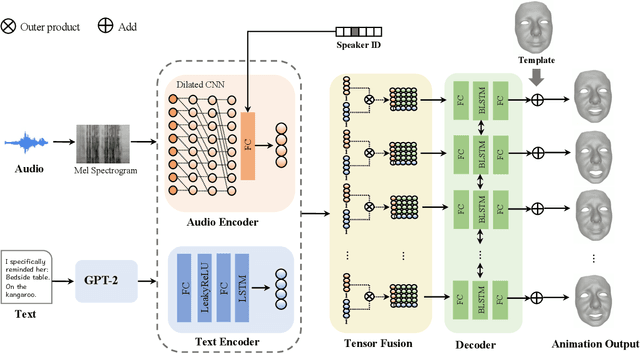
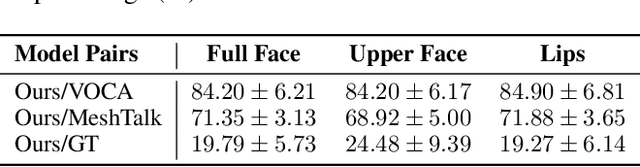
Speech-driven 3D facial animation with accurate lip synchronization has been widely studied. However, synthesizing realistic motions for the entire face during speech has rarely been explored. In this work, we present a joint audio-text model to capture the contextual information for expressive speech-driven 3D facial animation. The existing datasets are collected to cover as many different phonemes as possible instead of sentences, thus limiting the capability of the audio-based model to learn more diverse contexts. To address this, we propose to leverage the contextual text embeddings extracted from the powerful pre-trained language model that has learned rich contextual representations from large-scale text data. Our hypothesis is that the text features can disambiguate the variations in upper face expressions, which are not strongly correlated with the audio. In contrast to prior approaches which learn phoneme-level features from the text, we investigate the high-level contextual text features for speech-driven 3D facial animation. We show that the combined acoustic and textual modalities can synthesize realistic facial expressions while maintaining audio-lip synchronization. We conduct the quantitative and qualitative evaluations as well as the perceptual user study. The results demonstrate the superior performance of our model against existing state-of-the-art approaches.
SkillFence: A Systems Approach to Practically Mitigating Voice-Based Confusion Attacks
Dec 16, 2022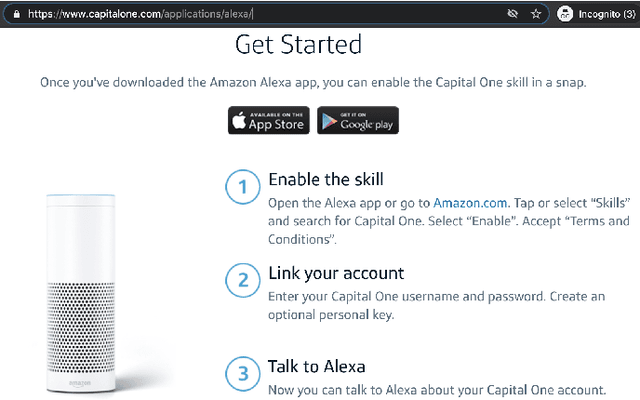
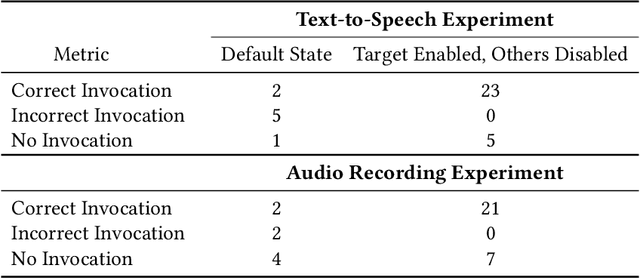
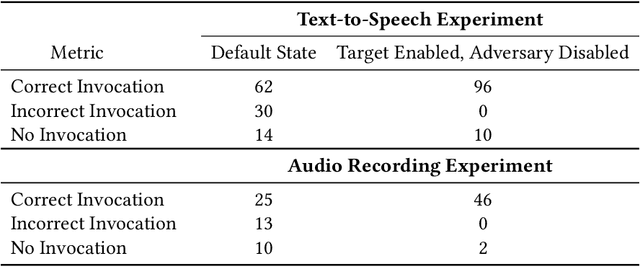
Voice assistants are deployed widely and provide useful functionality. However, recent work has shown that commercial systems like Amazon Alexa and Google Home are vulnerable to voice-based confusion attacks that exploit design issues. We propose a systems-oriented defense against this class of attacks and demonstrate its functionality for Amazon Alexa. We ensure that only the skills a user intends execute in response to voice commands. Our key insight is that we can interpret a user's intentions by analyzing their activity on counterpart systems of the web and smartphones. For example, the Lyft ride-sharing Alexa skill has an Android app and a website. Our work shows how information from counterpart apps can help reduce dis-ambiguities in the skill invocation process. We build SkilIFence, a browser extension that existing voice assistant users can install to ensure that only legitimate skills run in response to their commands. Using real user data from MTurk (N = 116) and experimental trials involving synthetic and organic speech, we show that SkillFence provides a balance between usability and security by securing 90.83% of skills that a user will need with a False acceptance rate of 19.83%.
The IWSLT 2021 BUT Speech Translation Systems
Jul 13, 2021
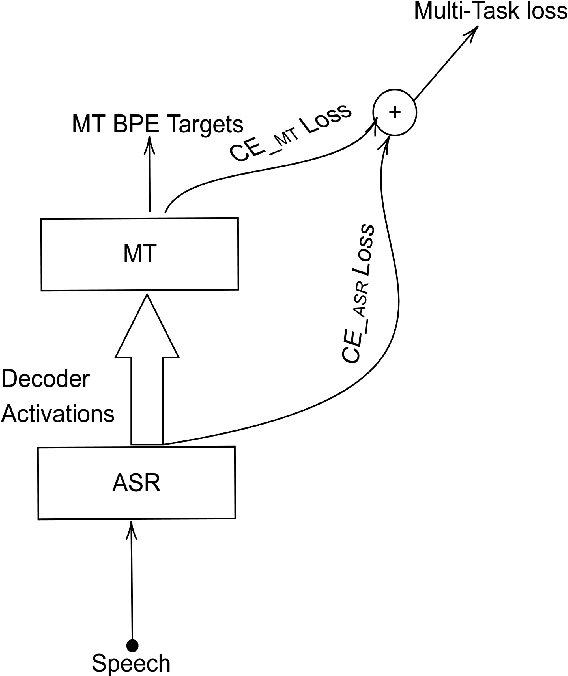
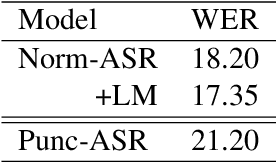
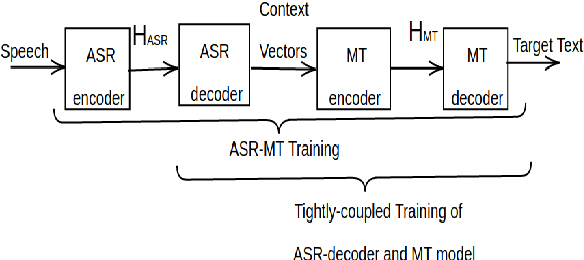
The paper describes BUT's English to German offline speech translation(ST) systems developed for IWSLT2021. They are based on jointly trained Automatic Speech Recognition-Machine Translation models. Their performances is evaluated on MustC-Common test set. In this work, we study their efficiency from the perspective of having a large amount of separate ASR training data and MT training data, and a smaller amount of speech-translation training data. Large amounts of ASR and MT training data are utilized for pre-training the ASR and MT models. Speech-translation data is used to jointly optimize ASR-MT models by defining an end-to-end differentiable path from speech to translations. For this purpose, we use the internal continuous representations from the ASR-decoder as the input to MT module. We show that speech translation can be further improved by training the ASR-decoder jointly with the MT-module using large amount of text-only MT training data. We also show significant improvements by training an ASR module capable of generating punctuated text, rather than leaving the punctuation task to the MT module.
A Study of Slang Representation Methods
Dec 11, 2022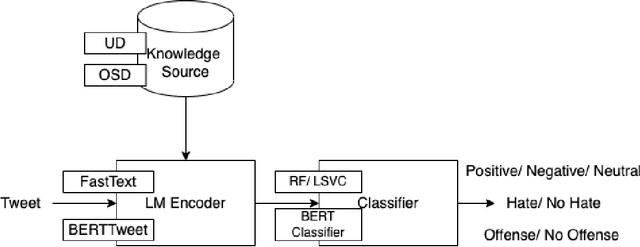

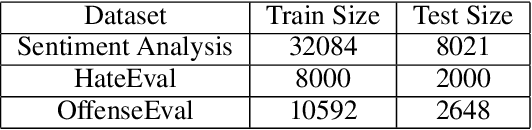
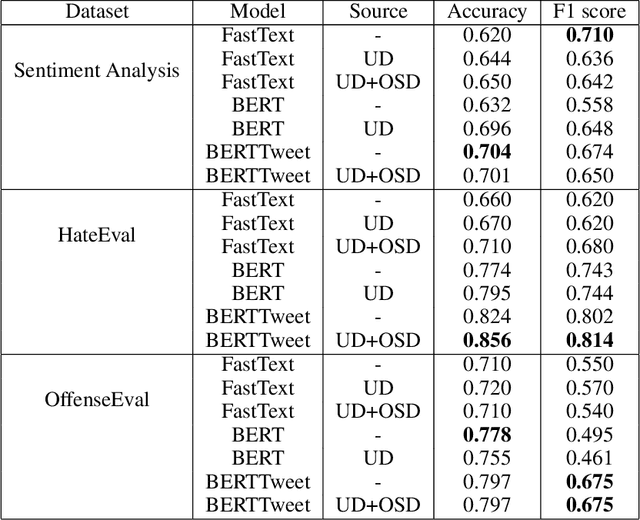
Warning: this paper contains content that may be offensive or upsetting. Considering the large amount of content created online by the minute, slang-aware automatic tools are critically needed to promote social good, and assist policymakers and moderators in restricting the spread of offensive language, abuse, and hate speech. Despite the success of large language models and the spontaneous emergence of slang dictionaries, it is unclear how far their combination goes in terms of slang understanding for downstream social good tasks. In this paper, we provide a framework to study different combinations of representation learning models and knowledge resources for a variety of downstream tasks that rely on slang understanding. Our experiments show the superiority of models that have been pre-trained on social media data, while the impact of dictionaries is positive only for static word embeddings. Our error analysis identifies core challenges for slang representation learning, including out-of-vocabulary words, polysemy, variance, and annotation disagreements, which can be traced to characteristics of slang as a quickly evolving and highly subjective language.