 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Subject-Invariant Representations from Speech-Evoked EEG Using Variational Autoencoders
Jul 01, 2022
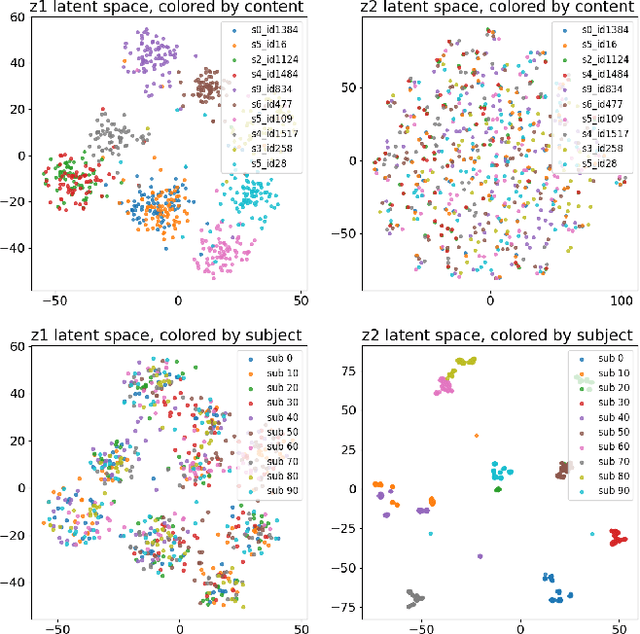
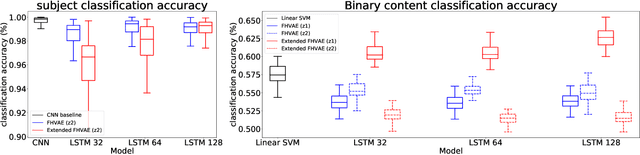
The electroencephalogram (EEG) is a powerful method to understand how the brain processes speech. Linear models have recently been replaced for this purpose with deep neural networks and yield promising results. In related EEG classification fields, it is shown that explicitly modeling subject-invariant features improves generalization of models across subjects and benefits classification accuracy. In this work, we adapt factorized hierarchical variational autoencoders to exploit parallel EEG recordings of the same stimuli. We model EEG into two disentangled latent spaces. Subject accuracy reaches 98.96% and 1.60% on respectively the subject and content latent space, whereas binary content classification experiments reach an accuracy of 51.51% and 62.91% on respectively the subject and content latent space.
LiteLSTM Architecture Based on Weights Sharing for Recurrent Neural Networks
Jan 12, 2023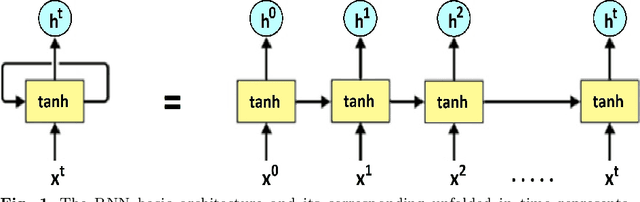

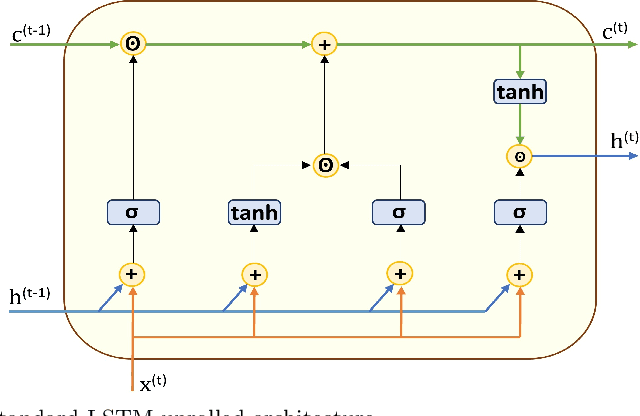
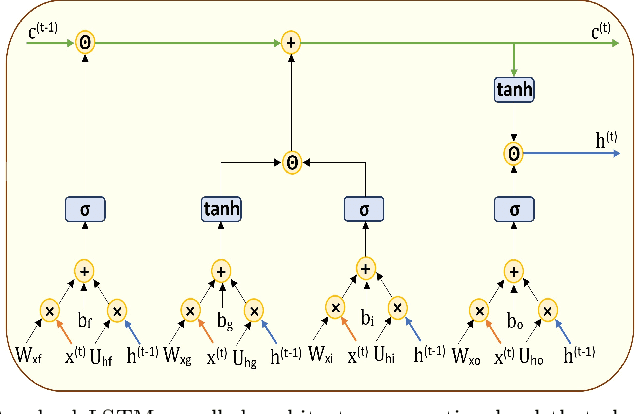
Long short-term memory (LSTM) is one of the robust recurrent neural network architectures for learning sequential data. However, it requires considerable computational power to learn and implement both software and hardware aspects. This paper proposed a novel LiteLSTM architecture based on reducing the LSTM computation components via the weights sharing concept to reduce the overall architecture computation cost and maintain the architecture performance. The proposed LiteLSTM can be significant for processing large data where time-consuming is crucial while hardware resources are limited, such as the security of IoT devices and medical data processing. The proposed model was evaluated and tested empirically on three different datasets from the computer vision, cybersecurity, speech emotion recognition domains. The proposed LiteLSTM has comparable accuracy to the other state-of-the-art recurrent architecture while using a smaller computation budget.
Single-Channel Speech Dereverberation using Subband Network with A Reverberation Time Shortening Target
Apr 19, 2022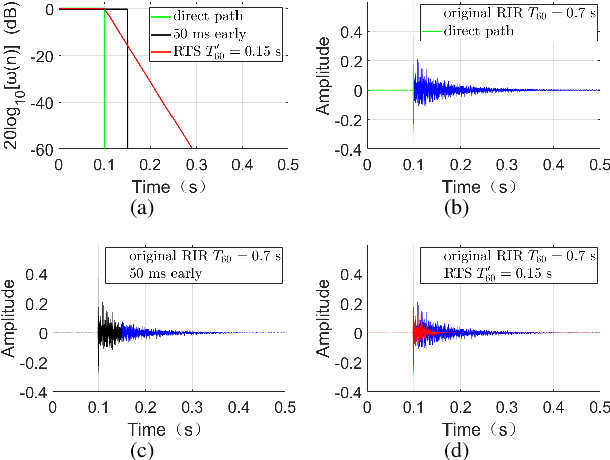
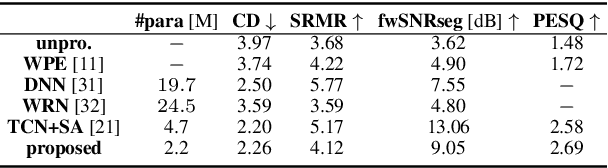
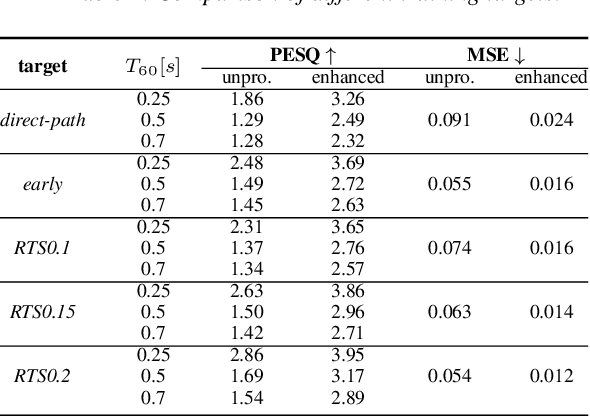
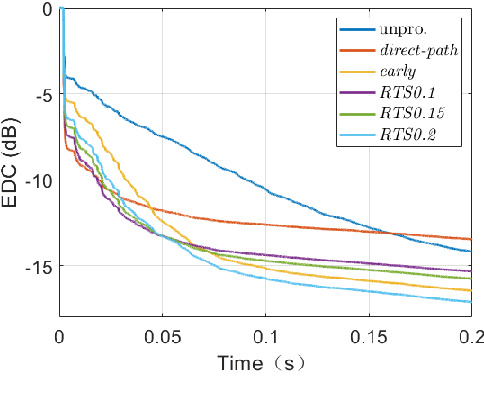
This work proposes a subband network for single-channel speech dereverberation, and also a new learning target based on reverberation time shortening (RTS). In the time-frequency domain, we propose to use a subband network to perform dereverberation for different frequency bands independently. The time-domain convolution can be well decomposed to subband convolutions, thence it is reasonable to train the subband network to perform subband deconvolution. The learning target for dereverberation is usually set as the direct-path speech or optionally with some early reflections. This type of target suddenly truncates the reverberation, and thus it may not be suitable for network training, and leads to a large prediction error. In this work, we propose a RTS learning target to suppress reverberation and meanwhile maintain the exponential decaying property of reverberation, which will ease the network training, and thus reduce the prediction error and signal distortions. Experiments show that the subband network can achieve outstanding dereverberation performance, and the proposed target has a smaller prediction error than the target of direct-path speech and early reflections.
On the Convergence of Stochastic Gradient Descent in Low-precision Number Formats
Jan 09, 2023
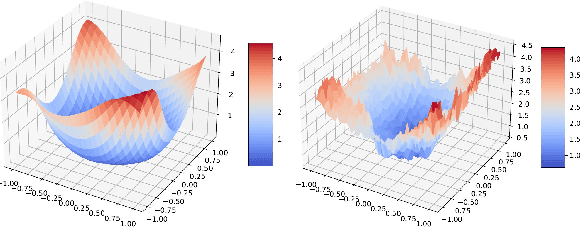
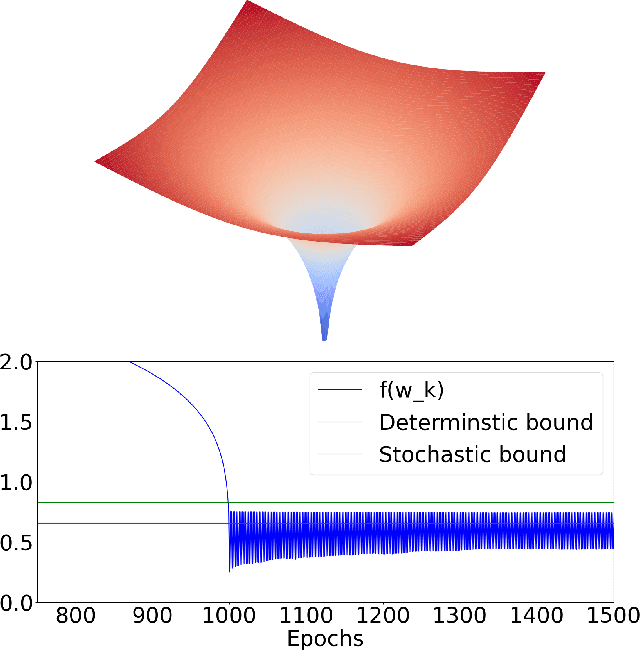
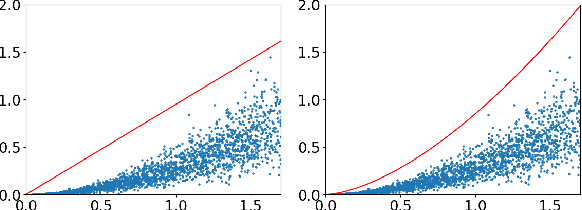
Deep learning models are dominating almost all artificial intelligence tasks such as vision, text, and speech processing. Stochastic Gradient Descent (SGD) is the main tool for training such models, where the computations are usually performed in single-precision floating-point number format. The convergence of single-precision SGD is normally aligned with the theoretical results of real numbers since they exhibit negligible error. However, the numerical error increases when the computations are performed in low-precision number formats. This provides compelling reasons to study the SGD convergence adapted for low-precision computations. We present both deterministic and stochastic analysis of the SGD algorithm, obtaining bounds that show the effect of number format. Such bounds can provide guidelines as to how SGD convergence is affected when constraints render the possibility of performing high-precision computations remote.
Neuromorphic spintronics accelerated by an unconventional data-driven Thiele equation approach
Jan 26, 2023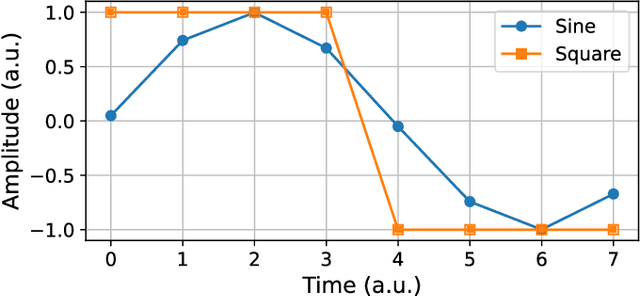
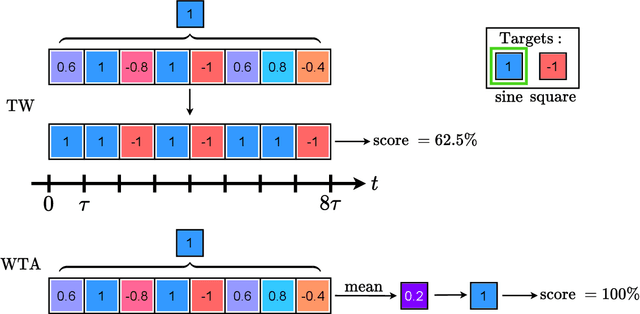
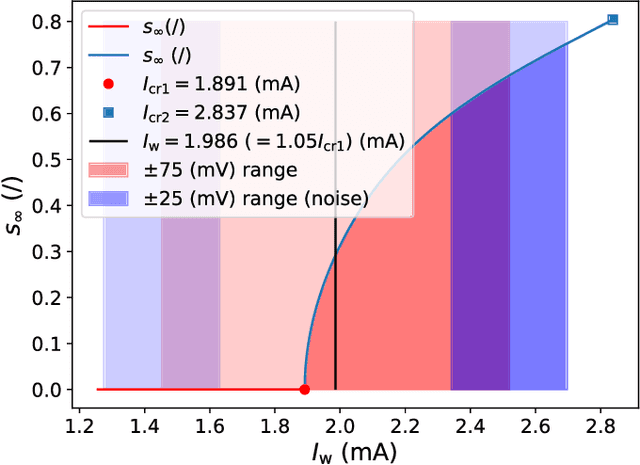
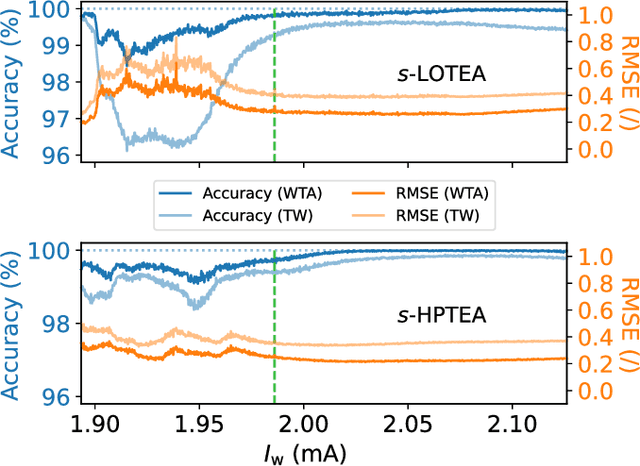
A hardware neural network based on a single spin-torque vortex nano-oscillator is designed using time-multiplexing. The behavior of the spin-torque vortex nano-oscillator is simulated with an improved ultra-fast and quantitative model based on the Thiele equation approach. Different mathematical and numerical adaptations are brought to the model in order to increase the accuracy and the speed of the simulations. A benchmark task of waveform classification is designed to assess the performance of the neural network in the framework of reservoir computing and compare two different versions of the model. The obtained results allow to conclude on the ability of the system to effectively classify sine and square signals with high accuracy and low root-mean-square error, reflecting high confidence cognition. Given the high throughput of the simulations, two innovative parametric studies on the dc bias current intensity and the level of noise in the system are performed to demonstrate the value of our models. The efficiency of our system is also tested during speech recognition and shows the agreement between these models and the corresponding experimental measurements.
SLICER: Learning universal audio representations using low-resource self-supervised pre-training
Nov 02, 2022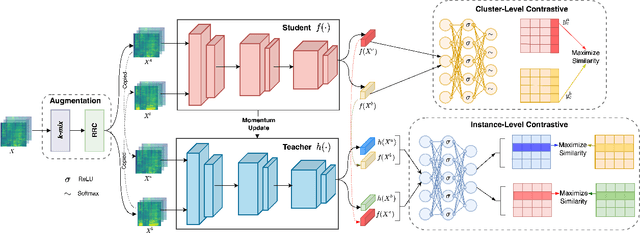
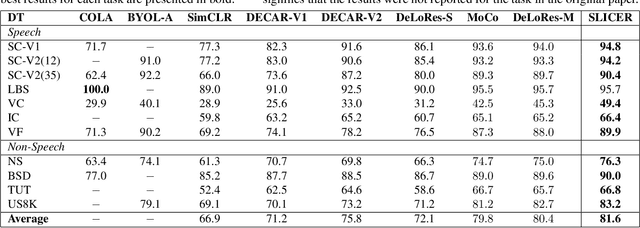
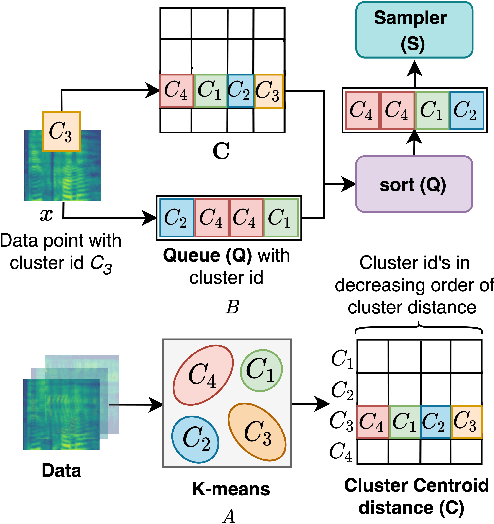

We present a new Self-Supervised Learning (SSL) approach to pre-train encoders on unlabeled audio data that reduces the need for large amounts of labeled data for audio and speech classification. Our primary aim is to learn audio representations that can generalize across a large variety of speech and non-speech tasks in a low-resource un-labeled audio pre-training setting. Inspired by the recent success of clustering and contrasting learning paradigms for SSL-based speech representation learning, we propose SLICER (Symmetrical Learning of Instance and Cluster-level Efficient Representations), which brings together the best of both clustering and contrasting learning paradigms. We use a symmetric loss between latent representations from student and teacher encoders and simultaneously solve instance and cluster-level contrastive learning tasks. We obtain cluster representations online by just projecting the input spectrogram into an output subspace with dimensions equal to the number of clusters. In addition, we propose a novel mel-spectrogram augmentation procedure, k-mix, based on mixup, which does not require labels and aids unsupervised representation learning for audio. Overall, SLICER achieves state-of-the-art results on the LAPE Benchmark \cite{9868132}, significantly outperforming DeLoRes-M and other prior approaches, which are pre-trained on $10\times$ larger of unsupervised data. We will make all our codes available on GitHub.
Disentangled Speech Representation Learning Based on Factorized Hierarchical Variational Autoencoder with Self-Supervised Objective
Apr 05, 2022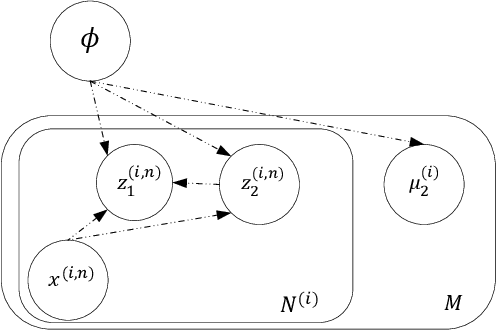

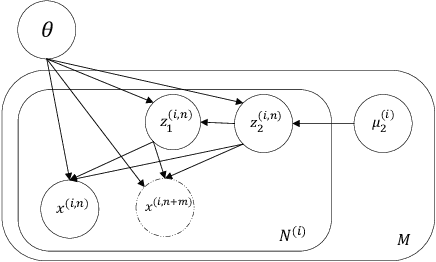
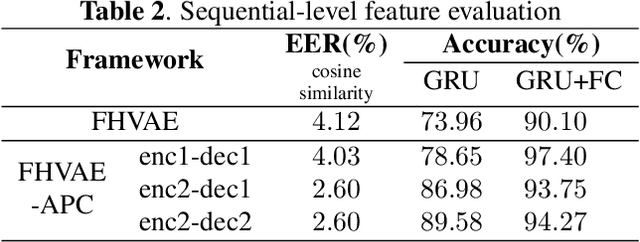
Disentangled representation learning aims to extract explanatory features or factors and retain salient information. Factorized hierarchical variational autoencoder (FHVAE) presents a way to disentangle a speech signal into sequential-level and segmental-level features, which represent speaker identity and speech content information, respectively. As a self-supervised objective, autoregressive predictive coding (APC), on the other hand, has been used in extracting meaningful and transferable speech features for multiple downstream tasks. Inspired by the success of these two representation learning methods, this paper proposes to integrate the APC objective into the FHVAE framework aiming at benefiting from the additional self-supervision target. The main proposed method requires neither more training data nor more computational cost at test time, but obtains improved meaningful representations while maintaining disentanglement. The experiments were conducted on the TIMIT dataset. Results demonstrate that FHVAE equipped with the additional self-supervised objective is able to learn features providing superior performance for tasks including speech recognition and speaker recognition. Furthermore, voice conversion, as one application of disentangled representation learning, has been applied and evaluated. The results show performance similar to baseline of the new framework on voice conversion.
Modernizing Open-Set Speech Language Identification
May 20, 2022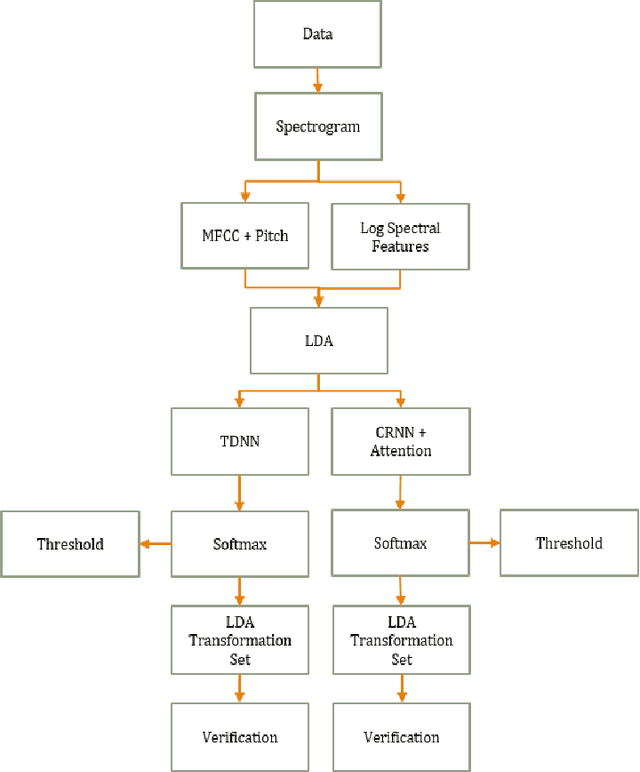
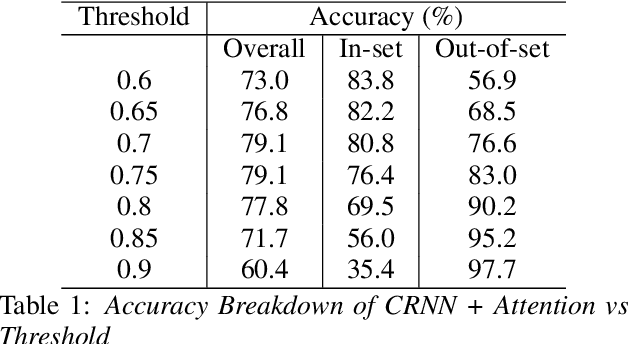
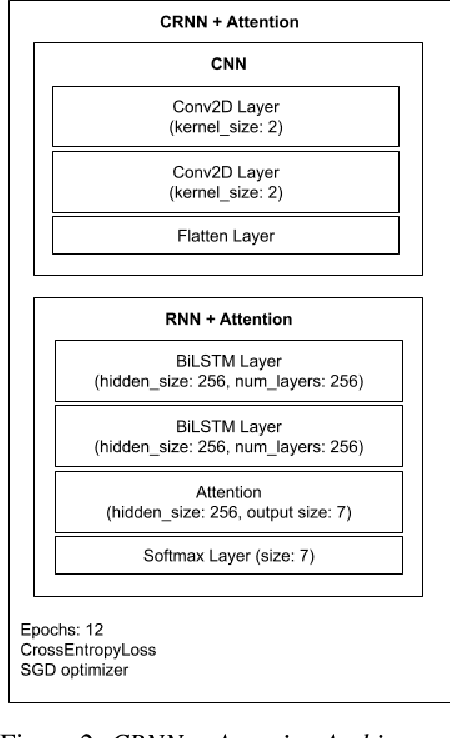

While most modern speech Language Identification methods are closed-set, we want to see if they can be modified and adapted for the open-set problem. When switching to the open-set problem, the solution gains the ability to reject an audio input when it fails to match any of our known language options. We tackle the open-set task by adapting two modern-day state-of-the-art approaches to closed-set language identification: the first using a CRNN with attention and the second using a TDNN. In addition to enhancing our input feature embeddings using MFCCs, log spectral features, and pitch, we will be attempting two approaches to out-of-set language detection: one using thresholds, and the other essentially performing a verification task. We will compare both the performance of the TDNN and the CRNN, as well as our detection approaches.
Insights into Deep Non-linear Filters for Improved Multi-channel Speech Enhancement
Jun 27, 2022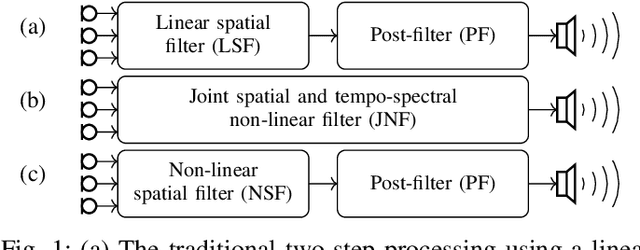
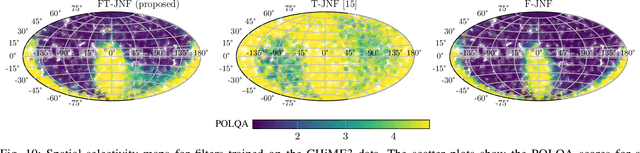
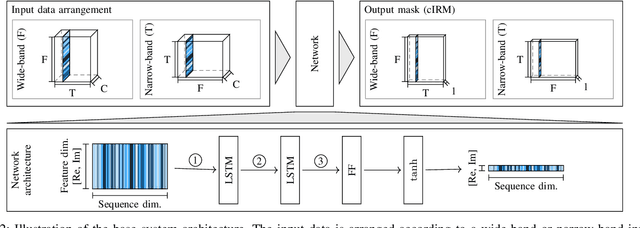
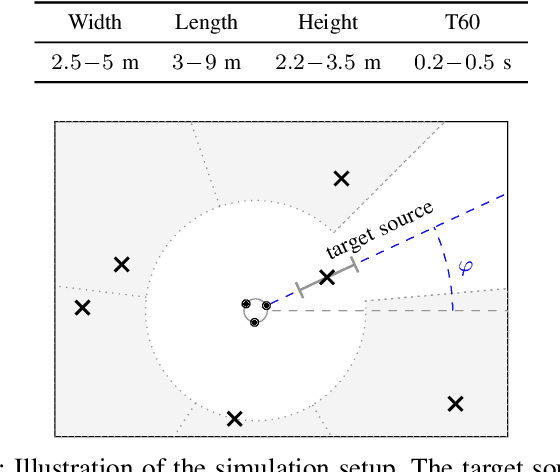
The key advantage of using multiple microphones for speech enhancement is that spatial filtering can be used to complement the tempo-spectral processing. In a traditional setting, linear spatial filtering (beamforming) and single-channel post-filtering are commonly performed separately. In contrast, there is a trend towards employing deep neural networks (DNNs) to learn a joint spatial and tempo-spectral non-linear filter, which means that the restriction of a linear processing model and that of a separate processing of spatial and tempo-spectral information can potentially be overcome. However, the internal mechanisms that lead to good performance of such data-driven filters for multi-channel speech enhancement are not well understood. Therefore, in this work, we analyse the properties of a non-linear spatial filter realized by a DNN as well as its interdependency with temporal and spectral processing by carefully controlling the information sources (spatial, spectral, and temporal) available to the network. We confirm the superiority of a non-linear spatial processing model, which outperforms an oracle linear spatial filter in a challenging speaker extraction scenario for a low number of microphones by 0.24 POLQA score. Our analyses reveal that in particular spectral information should be processed jointly with spatial information as this increases the spatial selectivity of the filter. Our systematic evaluation then leads to a simple network architecture, that outperforms state-of-the-art network architectures on a speaker extraction task by 0.22 POLQA score and by 0.32 POLQA score on the CHiME3 data.
Speech Toxicity Analysis: A New Spoken Language Processing Task
Nov 06, 2021
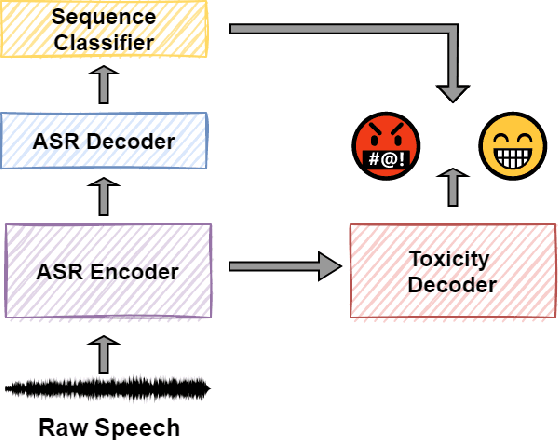
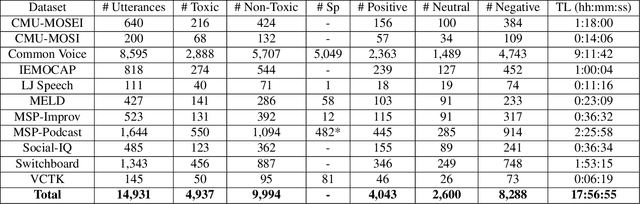
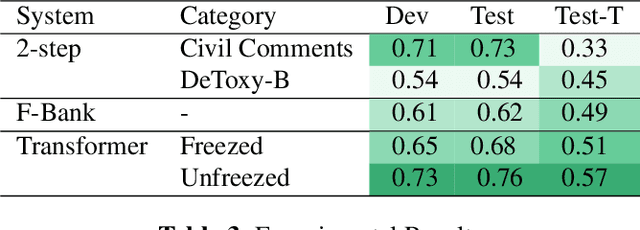
Toxic speech, also known as hate speech, is regarded as one of the crucial issues plaguing online social media today. Most recent work on toxic speech detection is constrained to the modality of text with no existing work on toxicity detection from spoken utterances. In this paper, we propose a new Spoken Language Processing task of detecting toxicity from spoken speech. We introduce DeToxy, the first publicly available toxicity annotated dataset for English speech, sourced from various openly available speech databases, consisting of over 2 million utterances. Finally, we also provide analysis on how a spoken speech corpus annotated for toxicity can help facilitate the development of E2E models which better capture various prosodic cues in speech, thereby boosting toxicity classification on spoken utterances.