 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural personal sound zones with flexible bright zone control
Dec 11, 2025Personal sound zone (PSZ) reproduction system, which attempts to create distinct virtual acoustic scenes for different listeners at their respective positions within the same spatial area using one loudspeaker array, is a fundamental technology in the application of virtual reality. For practical applications, the reconstruction targets must be measured on the same fixed receiver array used to record the local room impulse responses (RIRs) from the loudspeaker array to the control points in each PSZ, which makes the system inconvenient and costly for real-world use. In this paper, a 3D convolutional neural network (CNN) designed for PSZ reproduction with flexible control microphone grid and alternative reproduction target is presented, utilizing the virtual target scene as inputs and the PSZ pre-filters as output. Experimental results of the proposed method are compared with the traditional method, demonstrating that the proposed method is able to handle varied reproduction targets on flexible control point grid using only one training session. Furthermore, the proposed method also demonstrates the capability to learn global spatial information from sparse sampling points distributed in PSZs.
Single-Channel Speech Dereverberation using Subband Network with A Reverberation Time Shortening Target
Apr 19, 2022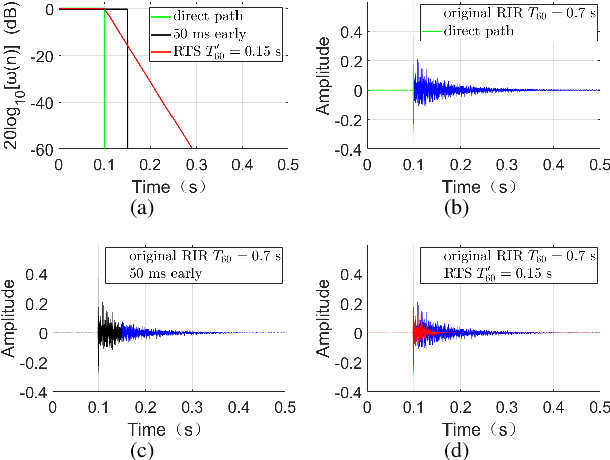
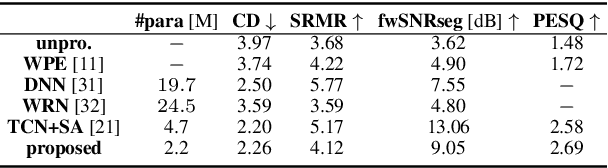
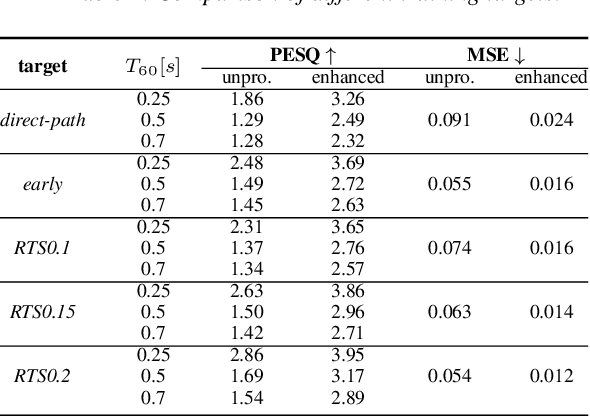
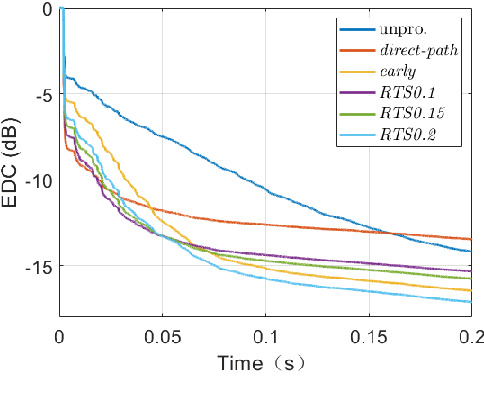
This work proposes a subband network for single-channel speech dereverberation, and also a new learning target based on reverberation time shortening (RTS). In the time-frequency domain, we propose to use a subband network to perform dereverberation for different frequency bands independently. The time-domain convolution can be well decomposed to subband convolutions, thence it is reasonable to train the subband network to perform subband deconvolution. The learning target for dereverberation is usually set as the direct-path speech or optionally with some early reflections. This type of target suddenly truncates the reverberation, and thus it may not be suitable for network training, and leads to a large prediction error. In this work, we propose a RTS learning target to suppress reverberation and meanwhile maintain the exponential decaying property of reverberation, which will ease the network training, and thus reduce the prediction error and signal distortions. Experiments show that the subband network can achieve outstanding dereverberation performance, and the proposed target has a smaller prediction error than the target of direct-path speech and early reflections.