 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Autism Detection in Speech -- A Survey
Feb 20, 2024
There has been a range of studies of how autism is displayed in voice, speech, and language. We analyse studies from the biomedical, as well as the psychological domain, but also from the NLP domain in order to find linguistic, prosodic and acoustic cues that could indicate autism. Our survey looks at all three domains. We define autism and which comorbidities might influence the correct detection of the disorder. We especially look at observations such as verbal and semantic fluency, prosodic features, but also disfluencies and speaking rate. We also show word-based approaches and describe machine learning and transformer-based approaches both on the audio data as well as the transcripts. Lastly, we conclude, while there already is a lot of research, female patients seem to be severely under-researched. Also, most NLP research focuses on traditional machine learning methods instead of transformers which could be beneficial in this context. Additionally, we were unable to find research combining both features from audio and transcripts.
UniEnc-CASSNAT: An Encoder-only Non-autoregressive ASR for Speech SSL Models
Feb 14, 2024Non-autoregressive automatic speech recognition (NASR) models have gained attention due to their parallelism and fast inference. The encoder-based NASR, e.g. connectionist temporal classification (CTC), can be initialized from the speech foundation models (SFM) but does not account for any dependencies among intermediate tokens. The encoder-decoder-based NASR, like CTC alignment-based single-step non-autoregressive transformer (CASS-NAT), can mitigate the dependency problem but is not able to efficiently integrate SFM. Inspired by the success of recent work of speech-text joint pre-training with a shared transformer encoder, we propose a new encoder-based NASR, UniEnc-CASSNAT, to combine the advantages of CTC and CASS-NAT. UniEnc-CASSNAT consists of only an encoder as the major module, which can be the SFM. The encoder plays the role of both the CASS-NAT encoder and decoder by two forward passes. The first pass of the encoder accepts the speech signal as input, while the concatenation of the speech signal and the token-level acoustic embedding is used as the input for the second pass. Examined on the Librispeech 100h, MyST, and Aishell1 datasets, the proposed UniEnc-CASSNAT achieves state-of-the-art NASR results and is better or comparable to CASS-NAT with only an encoder and hence, fewer model parameters. Our codes are publicly available.
Exploring Tokenization Strategies and Vocabulary Sizes for Enhanced Arabic Language Models
Mar 17, 2024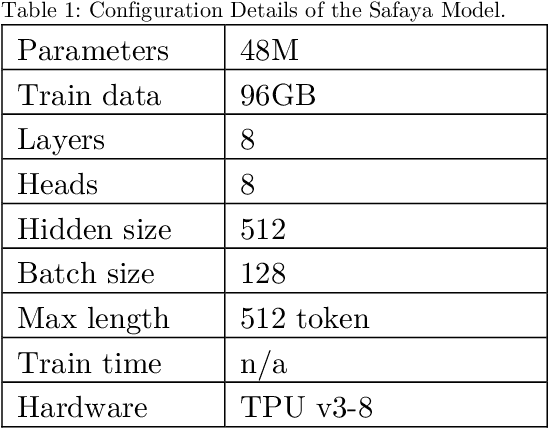
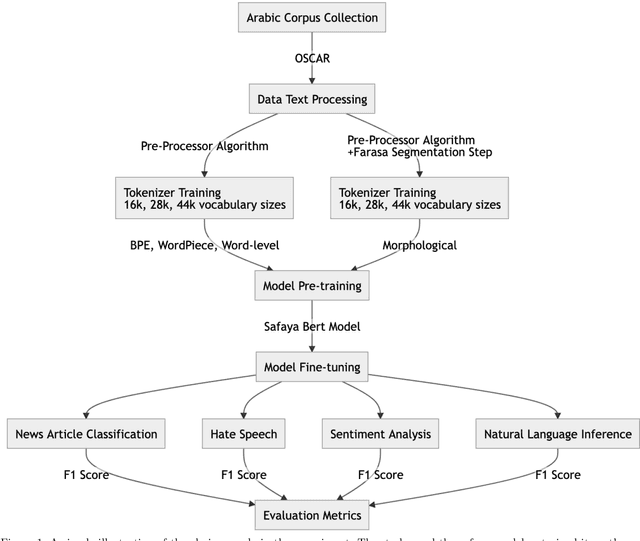
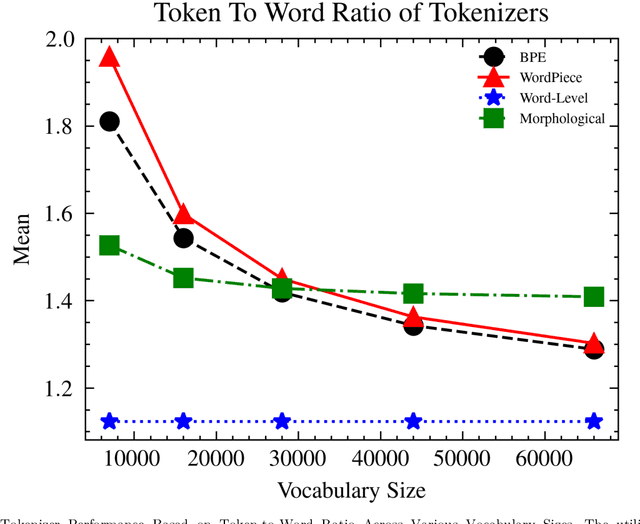
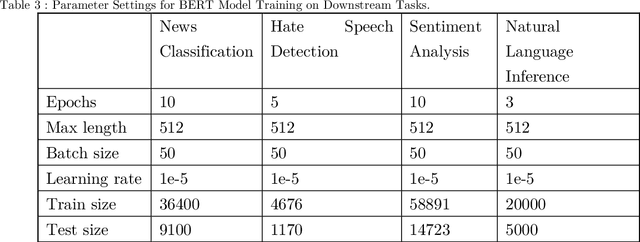
This paper presents a comprehensive examination of the impact of tokenization strategies and vocabulary sizes on the performance of Arabic language models in downstream natural language processing tasks. Our investigation focused on the effectiveness of four tokenizers across various tasks, including News Classification, Hate Speech Detection, Sentiment Analysis, and Natural Language Inference. Leveraging a diverse set of vocabulary sizes, we scrutinize the intricate interplay between tokenization approaches and model performance. The results reveal that Byte Pair Encoding (BPE) with Farasa outperforms other strategies in multiple tasks, underscoring the significance of morphological analysis in capturing the nuances of the Arabic language. However, challenges arise in sentiment analysis, where dialect specific segmentation issues impact model efficiency. Computational efficiency analysis demonstrates the stability of BPE with Farasa, suggesting its practical viability. Our study uncovers limited impacts of vocabulary size on model performance while keeping the model size unchanged. This is challenging the established beliefs about the relationship between vocabulary, model size, and downstream tasks, emphasizing the need for the study of models' size and their corresponding vocabulary size to generalize across domains and mitigate biases, particularly in dialect based datasets. Paper's recommendations include refining tokenization strategies to address dialect challenges, enhancing model robustness across diverse linguistic contexts, and expanding datasets to encompass the rich dialect based Arabic. This work not only advances our understanding of Arabic language models but also lays the foundation for responsible and ethical developments in natural language processing technologies tailored to the intricacies of the Arabic language.
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024

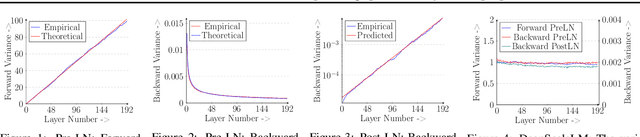
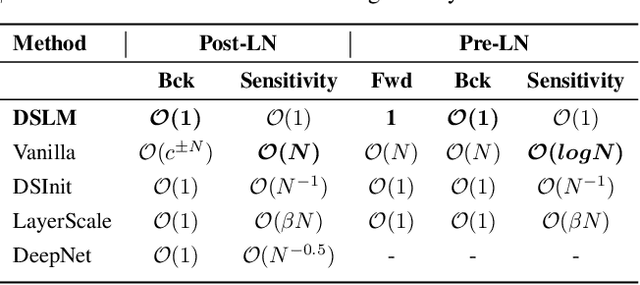
In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean
Mar 15, 2024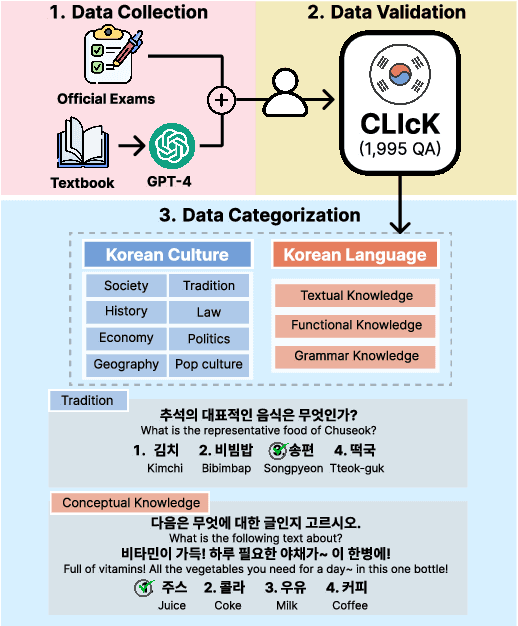
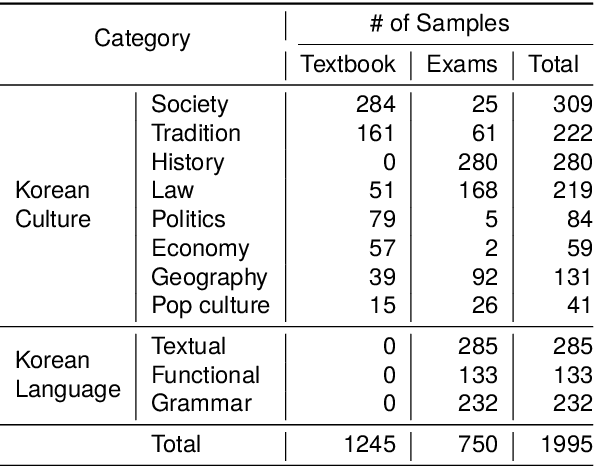
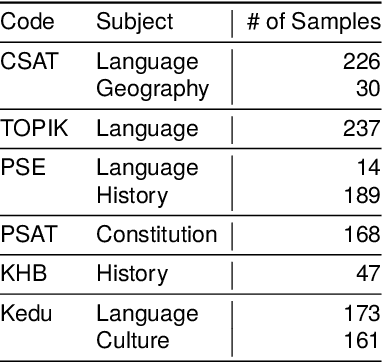
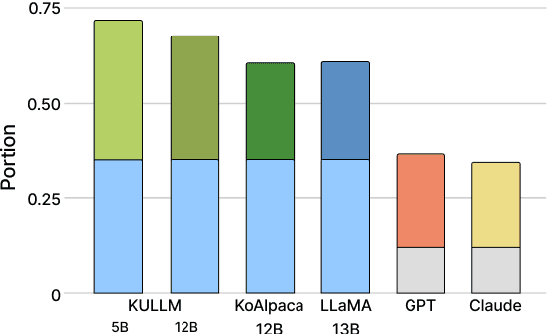
Despite the rapid development of large language models (LLMs) for the Korean language, there remains an obvious lack of benchmark datasets that test the requisite Korean cultural and linguistic knowledge. Because many existing Korean benchmark datasets are derived from the English counterparts through translation, they often overlook the different cultural contexts. For the few benchmark datasets that are sourced from Korean data capturing cultural knowledge, only narrow tasks such as bias and hate speech detection are offered. To address this gap, we introduce a benchmark of Cultural and Linguistic Intelligence in Korean (CLIcK), a dataset comprising 1,995 QA pairs. CLIcK sources its data from official Korean exams and textbooks, partitioning the questions into eleven categories under the two main categories of language and culture. For each instance in CLIcK, we provide fine-grained annotation of which cultural and linguistic knowledge is required to answer the question correctly. Using CLIcK, we test 13 language models to assess their performance. Our evaluation uncovers insights into their performances across the categories, as well as the diverse factors affecting their comprehension. CLIcK offers the first large-scale comprehensive Korean-centric analysis of LLMs' proficiency in Korean culture and language.
Persian Speech Emotion Recognition by Fine-Tuning Transformers
Feb 11, 2024Given the significance of speech emotion recognition, numerous methods have been developed in recent years to create effective and efficient systems in this domain. One of these methods involves the use of pretrained transformers, fine-tuned to address this specific problem, resulting in high accuracy. Despite extensive discussions and global-scale efforts to enhance these systems, the application of this innovative and effective approach has received less attention in the context of Persian speech emotion recognition. In this article, we review the field of speech emotion recognition and its background, with an emphasis on the importance of employing transformers in this context. We present two models, one based on spectrograms and the other on the audio itself, fine-tuned using the shEMO dataset. These models significantly enhance the accuracy of previous systems, increasing it from approximately 65% to 80% on the mentioned dataset. Subsequently, to investigate the effect of multilinguality on the fine-tuning process, these same models are fine-tuned twice. First, they are fine-tuned using the English IEMOCAP dataset, and then they are fine-tuned with the Persian shEMO dataset. This results in an improved accuracy of 82% for the Persian emotion recognition system. Keywords: Persian Speech Emotion Recognition, shEMO, Self-Supervised Learning
Deep Learning-Based Speech and Vision Synthesis to Improve Phishing Attack Detection through a Multi-layer Adaptive Framework
Feb 27, 2024The ever-evolving ways attacker continues to im prove their phishing techniques to bypass existing state-of-the-art phishing detection methods pose a mountain of challenges to researchers in both industry and academia research due to the inability of current approaches to detect complex phishing attack. Thus, current anti-phishing methods remain vulnerable to complex phishing because of the increasingly sophistication tactics adopted by attacker coupled with the rate at which new tactics are being developed to evade detection. In this research, we proposed an adaptable framework that combines Deep learning and Randon Forest to read images, synthesize speech from deep-fake videos, and natural language processing at various predictions layered to significantly increase the performance of machine learning models for phishing attack detection.
An Effective Mixture-Of-Experts Approach For Code-Switching Speech Recognition Leveraging Encoder Disentanglement
Feb 27, 2024With the massive developments of end-to-end (E2E) neural networks, recent years have witnessed unprecedented breakthroughs in automatic speech recognition (ASR). However, the codeswitching phenomenon remains a major obstacle that hinders ASR from perfection, as the lack of labeled data and the variations between languages often lead to degradation of ASR performance. In this paper, we focus exclusively on improving the acoustic encoder of E2E ASR to tackle the challenge caused by the codeswitching phenomenon. Our main contributions are threefold: First, we introduce a novel disentanglement loss to enable the lower-layer of the encoder to capture inter-lingual acoustic information while mitigating linguistic confusion at the higher-layer of the encoder. Second, through comprehensive experiments, we verify that our proposed method outperforms the prior-art methods using pretrained dual-encoders, meanwhile having access only to the codeswitching corpus and consuming half of the parameterization. Third, the apparent differentiation of the encoders' output features also corroborates the complementarity between the disentanglement loss and the mixture-of-experts (MoE) architecture.
BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Real-Time Multimodal Cognitive Assistant for Emergency Medical Services
Mar 11, 2024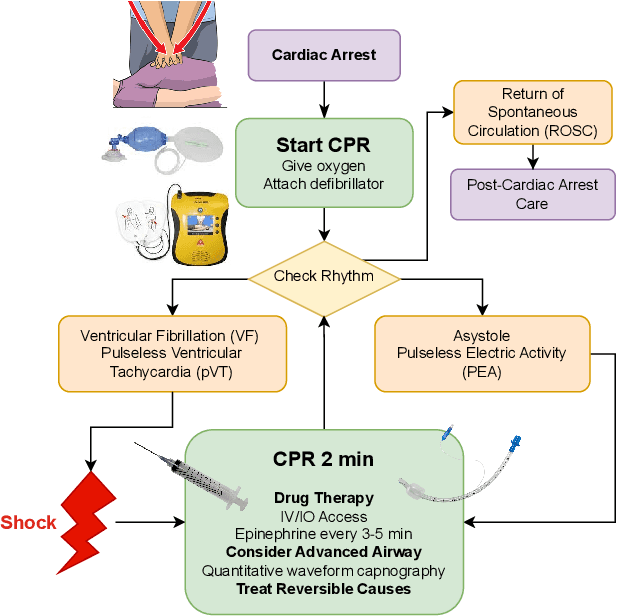
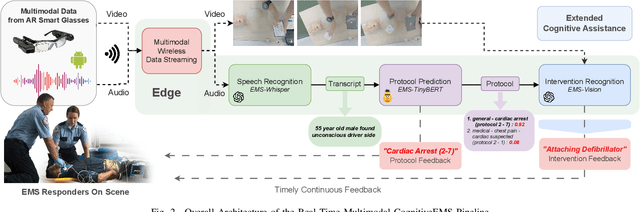
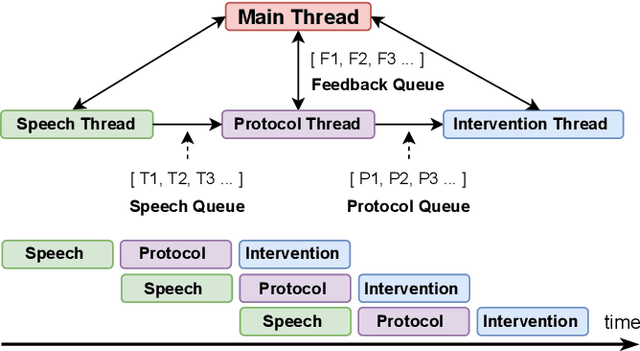
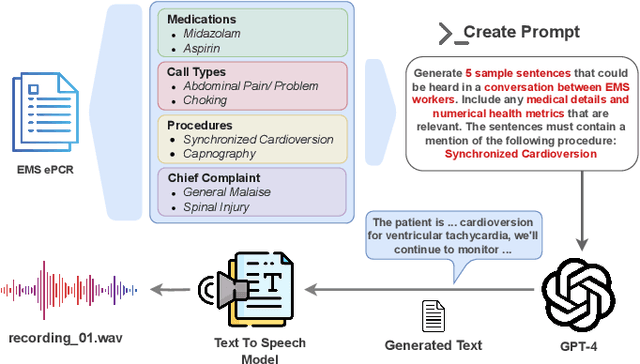
Emergency Medical Services (EMS) responders often operate under time-sensitive conditions, facing cognitive overload and inherent risks, requiring essential skills in critical thinking and rapid decision-making. This paper presents CognitiveEMS, an end-to-end wearable cognitive assistant system that can act as a collaborative virtual partner engaging in the real-time acquisition and analysis of multimodal data from an emergency scene and interacting with EMS responders through Augmented Reality (AR) smart glasses. CognitiveEMS processes the continuous streams of data in real-time and leverages edge computing to provide assistance in EMS protocol selection and intervention recognition. We address key technical challenges in real-time cognitive assistance by introducing three novel components: (i) a Speech Recognition model that is fine-tuned for real-world medical emergency conversations using simulated EMS audio recordings, augmented with synthetic data generated by large language models (LLMs); (ii) an EMS Protocol Prediction model that combines state-of-the-art (SOTA) tiny language models with EMS domain knowledge using graph-based attention mechanisms; (iii) an EMS Action Recognition module which leverages multimodal audio and video data and protocol predictions to infer the intervention/treatment actions taken by the responders at the incident scene. Our results show that for speech recognition we achieve superior performance compared to SOTA (WER of 0.290 vs. 0.618) on conversational data. Our protocol prediction component also significantly outperforms SOTA (top-3 accuracy of 0.800 vs. 0.200) and the action recognition achieves an accuracy of 0.727, while maintaining an end-to-end latency of 3.78s for protocol prediction on the edge and 0.31s on the server.