 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MuLanTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2023
Sep 12, 2023
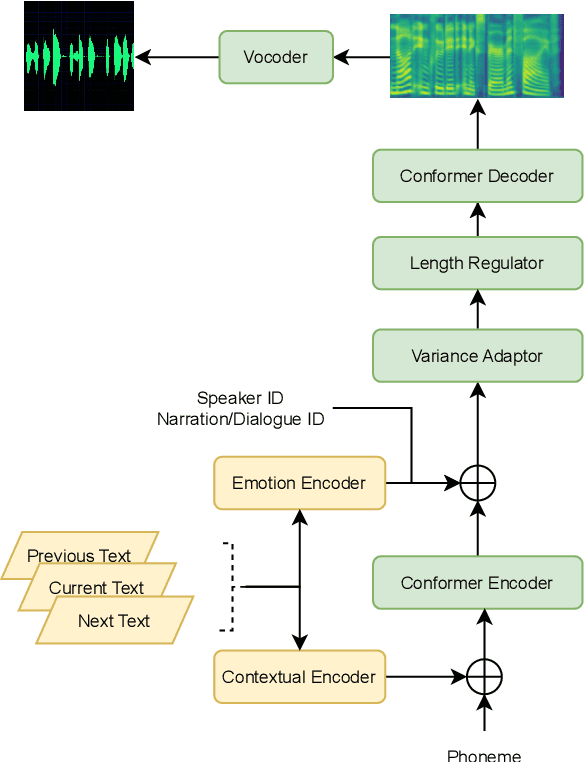
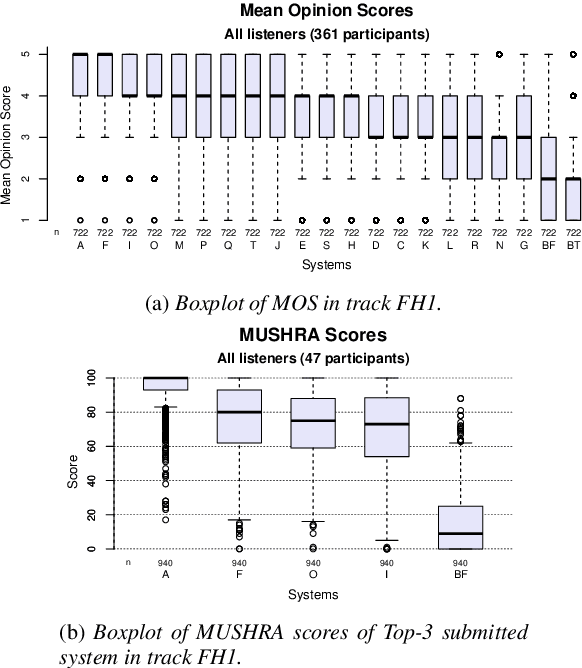
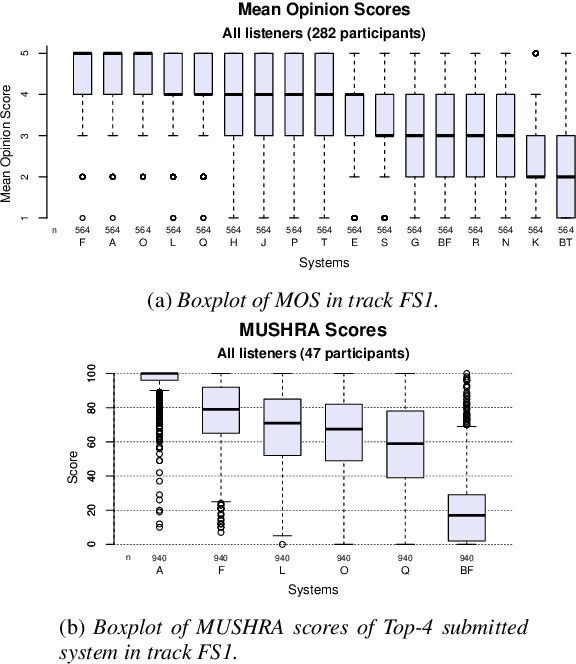
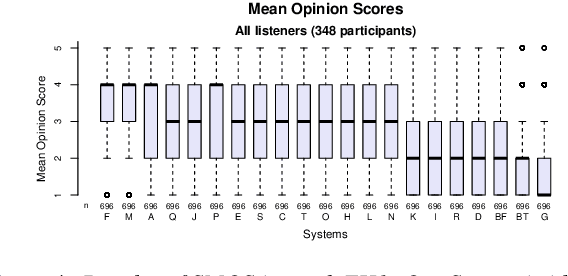
In this paper, we present MuLanTTS, the Microsoft end-to-end neural text-to-speech (TTS) system designed for the Blizzard Challenge 2023. About 50 hours of audiobook corpus for French TTS as hub task and another 2 hours of speaker adaptation as spoke task are released to build synthesized voices for different test purposes including sentences, paragraphs, homographs, lists, etc. Building upon DelightfulTTS, we adopt contextual and emotion encoders to adapt the audiobook data to enrich beyond sentences for long-form prosody and dialogue expressiveness. Regarding the recording quality, we also apply denoise algorithms and long audio processing for both corpora. For the hub task, only the 50-hour single speaker data is used for building the TTS system, while for the spoke task, a multi-speaker source model is used for target speaker fine tuning. MuLanTTS achieves mean scores of quality assessment 4.3 and 4.5 in the respective tasks, statistically comparable with natural speech while keeping good similarity according to similarity assessment. The excellent and similarity in this year's new and dense statistical evaluation show the effectiveness of our proposed system in both tasks.
Exploring the Potential of Large Language Models in Computational Argumentation
Nov 15, 2023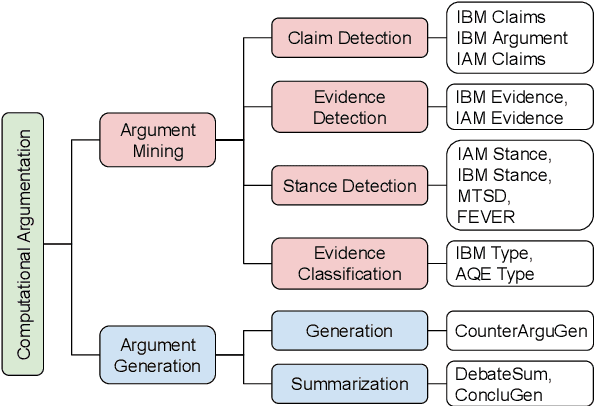
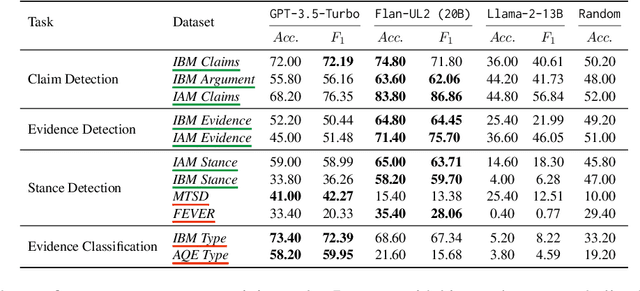

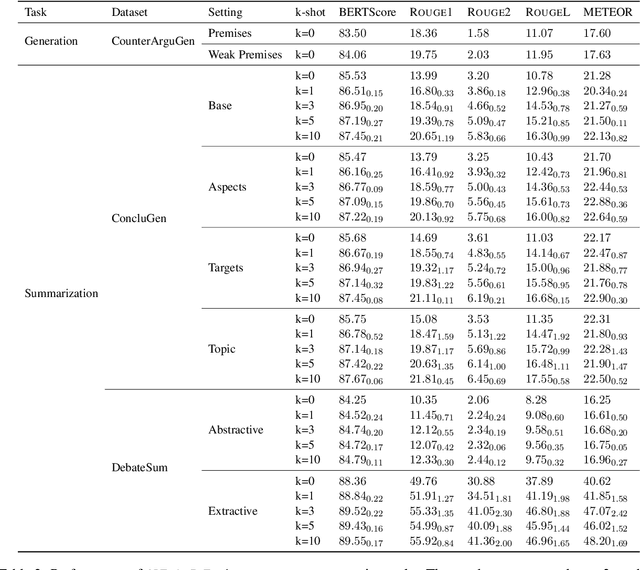
Computational argumentation has become an essential tool in various fields, including artificial intelligence, law, and public policy. It is an emerging research field in natural language processing (NLP) that attracts increasing attention. Research on computational argumentation mainly involves two types of tasks: argument mining and argument generation. As large language models (LLMs) have demonstrated strong abilities in understanding context and generating natural language, it is worthwhile to evaluate the performance of LLMs on various computational argumentation tasks. This work aims to embark on an assessment of LLMs, such as ChatGPT, Flan models and LLaMA2 models, under zero-shot and few-shot settings within the realm of computational argumentation. We organize existing tasks into 6 main classes and standardise the format of 14 open-sourced datasets. In addition, we present a new benchmark dataset on counter speech generation, that aims to holistically evaluate the end-to-end performance of LLMs on argument mining and argument generation. Extensive experiments show that LLMs exhibit commendable performance across most of these datasets, demonstrating their capabilities in the field of argumentation. We also highlight the limitations in evaluating computational argumentation and provide suggestions for future research directions in this field.
DPATD: Dual-Phase Audio Transformer for Denoising
Oct 30, 2023Recent high-performance transformer-based speech enhancement models demonstrate that time domain methods could achieve similar performance as time-frequency domain methods. However, time-domain speech enhancement systems typically receive input audio sequences consisting of a large number of time steps, making it challenging to model extremely long sequences and train models to perform adequately. In this paper, we utilize smaller audio chunks as input to achieve efficient utilization of audio information to address the above challenges. We propose a dual-phase audio transformer for denoising (DPATD), a novel model to organize transformer layers in a deep structure to learn clean audio sequences for denoising. DPATD splits the audio input into smaller chunks, where the input length can be proportional to the square root of the original sequence length. Our memory-compressed explainable attention is efficient and converges faster compared to the frequently used self-attention module. Extensive experiments demonstrate that our model outperforms state-of-the-art methods.
CLARA: Multilingual Contrastive Learning for Audio Representation Acquisition
Oct 18, 2023This paper proposes a novel framework for multilingual speech and sound representation learning using contrastive learning. The lack of sizeable labelled datasets hinders speech-processing research across languages. Recent advances in contrastive learning provide self-supervised techniques to learn from unlabelled data. Motivated by reducing data dependence and improving generalisation across diverse languages and conditions, we develop a multilingual contrastive framework. This framework enables models to acquire shared representations across languages, facilitating cross-lingual transfer with limited target language data. Additionally, capturing emotional cues within speech is challenging due to subjective perceptual assessments. By learning expressive representations from diverse, multilingual data in a self-supervised manner, our approach aims to develop speech representations that encode emotive dimensions. Our method trains encoders on a large corpus of multi-lingual audio data. Data augmentation techniques are employed to expand the dataset. The contrastive learning approach trains the model to maximise agreement between positive pairs and minimise agreement between negative pairs. Extensive experiments demonstrate state-of-the-art performance of the proposed model on emotion recognition, audio classification, and retrieval benchmarks under zero-shot and few-shot conditions. This provides an effective approach for acquiring shared and generalised speech representations across languages and acoustic conditions while encoding latent emotional dimensions.
SALTTS: Leveraging Self-Supervised Speech Representations for improved Text-to-Speech Synthesis
Aug 02, 2023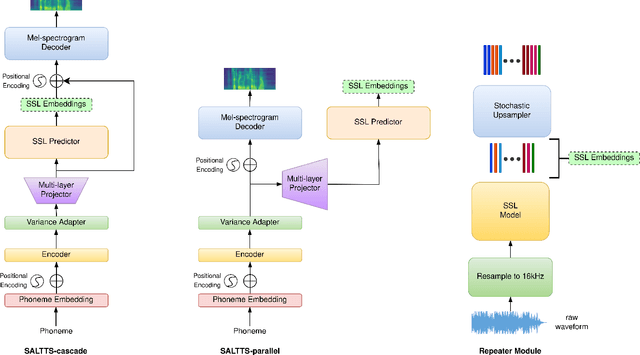
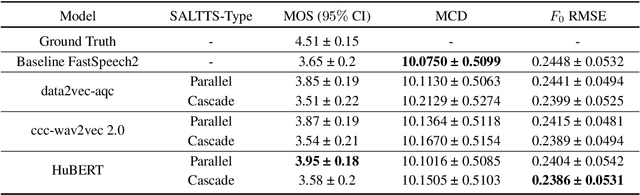
While FastSpeech2 aims to integrate aspects of speech such as pitch, energy, and duration as conditional inputs, it still leaves scope for richer representations. As a part of this work, we leverage representations from various Self-Supervised Learning (SSL) models to enhance the quality of the synthesized speech. In particular, we pass the FastSpeech2 encoder's length-regulated outputs through a series of encoder layers with the objective of reconstructing the SSL representations. In the SALTTS-parallel implementation, the representations from this second encoder are used for an auxiliary reconstruction loss with the SSL features. The SALTTS-cascade implementation, however, passes these representations through the decoder in addition to having the reconstruction loss. The richness of speech characteristics from the SSL features reflects in the output speech quality, with the objective and subjective evaluation measures of the proposed approach outperforming the baseline FastSpeech2.
SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT
Oct 16, 2023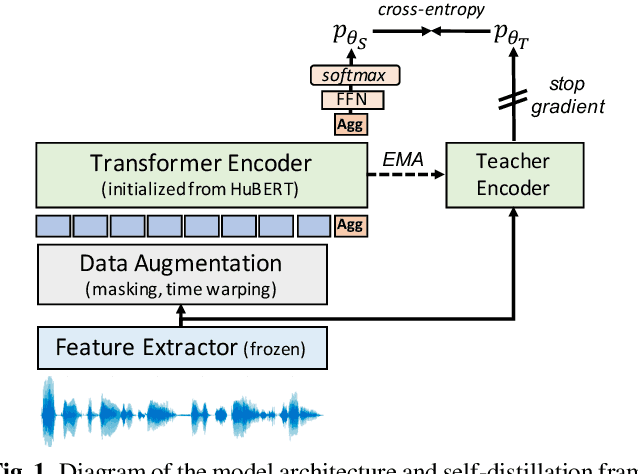
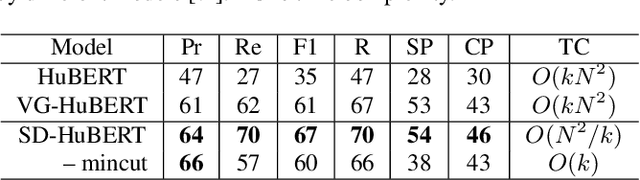
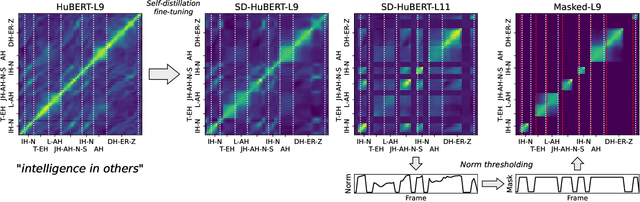
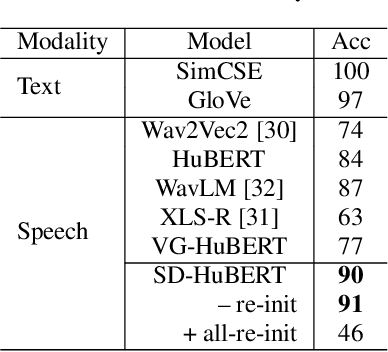
Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space, limiting the utility of SSL representations. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames show salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
How Far Can We Extract Diverse Perspectives from Large Language Models? Criteria-Based Diversity Prompting!
Nov 16, 2023Collecting diverse human data on subjective NLP topics is costly and challenging. As Large Language Models (LLMs) have developed human-like capabilities, there is a recent trend in collaborative efforts between humans and LLMs for generating diverse data, offering potential scalable and efficient solutions. However, the extent of LLMs' capability to generate diverse perspectives on subjective topics remains an unexplored question. In this study, we investigate LLMs' capacity for generating diverse perspectives and rationales on subjective topics, such as social norms and argumentative texts. We formulate this problem as diversity extraction in LLMs and propose a criteria-based prompting technique to ground diverse opinions and measure perspective diversity from the generated criteria words. Our results show that measuring semantic diversity through sentence embeddings and distance metrics is not enough to measure perspective diversity. To see how far we can extract diverse perspectives from LLMs, or called diversity coverage, we employ a step-by-step recall prompting for generating more outputs from the model in an iterative manner. As we apply our prompting method to other tasks (hate speech labeling and story continuation), indeed we find that LLMs are able to generate diverse opinions according to the degree of task subjectivity.
The Mason-Alberta Phonetic Segmenter: A forced alignment system based on deep neural networks and interpolation
Oct 24, 2023Forced alignment systems automatically determine boundaries between segments in speech data, given an orthographic transcription. These tools are commonplace in phonetics to facilitate the use of speech data that would be infeasible to manually transcribe and segment. In the present paper, we describe a new neural network-based forced alignment system, the Mason-Alberta Phonetic Segmenter (MAPS). The MAPS aligner serves as a testbed for two possible improvements we pursue for forced alignment systems. The first is treating the acoustic model in a forced aligner as a tagging task, rather than a classification task, motivated by the common understanding that segments in speech are not truly discrete and commonly overlap. The second is an interpolation technique to allow boundaries more precise than the common 10 ms limit in modern forced alignment systems. We compare configurations of our system to a state-of-the-art system, the Montreal Forced Aligner. The tagging approach did not generally yield improved results over the Montreal Forced Aligner. However, a system with the interpolation technique had a 27.92% increase relative to the Montreal Forced Aligner in the amount of boundaries within 10 ms of the target on the test set. We also reflect on the task and training process for acoustic modeling in forced alignment, highlighting how the output targets for these models do not match phoneticians' conception of similarity between phones and that reconciliation of this tension may require rethinking the task and output targets or how speech itself should be segmented.
Bit Cipher -- A Simple yet Powerful Word Representation System that Integrates Efficiently with Language Models
Nov 18, 2023While Large Language Models (LLMs) become ever more dominant, classic pre-trained word embeddings sustain their relevance through computational efficiency and nuanced linguistic interpretation. Drawing from recent studies demonstrating that the convergence of GloVe and word2vec optimizations all tend towards log-co-occurrence matrix variants, we construct a novel word representation system called Bit-cipher that eliminates the need of backpropagation while leveraging contextual information and hyper-efficient dimensionality reduction techniques based on unigram frequency, providing strong interpretability, alongside efficiency. We use the bit-cipher algorithm to train word vectors via a two-step process that critically relies on a hyperparameter -- bits -- that controls the vector dimension. While the first step trains the bit-cipher, the second utilizes it under two different aggregation modes -- summation or concatenation -- to produce contextually rich representations from word co-occurrences. We extend our investigation into bit-cipher's efficacy, performing probing experiments on part-of-speech (POS) tagging and named entity recognition (NER) to assess its competitiveness with classic embeddings like word2vec and GloVe. Additionally, we explore its applicability in LM training and fine-tuning. By replacing embedding layers with cipher embeddings, our experiments illustrate the notable efficiency of cipher in accelerating the training process and attaining better optima compared to conventional training paradigms. Experiments on the integration of bit-cipher embedding layers with Roberta, T5, and OPT, prior to or as a substitute for fine-tuning, showcase a promising enhancement to transfer learning, allowing rapid model convergence while preserving competitive performance.
Unimodal Aggregation for CTC-based Speech Recognition
Sep 15, 2023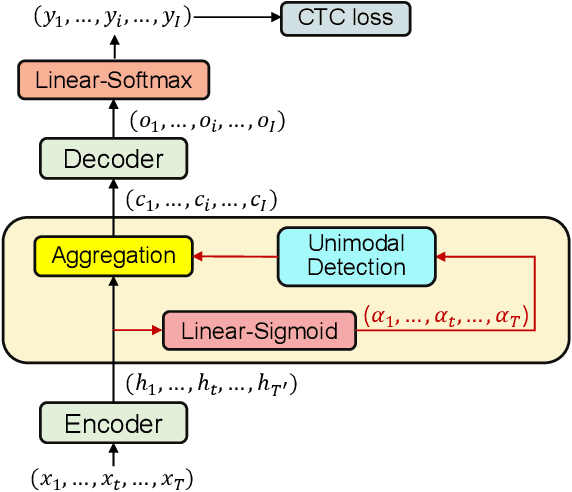
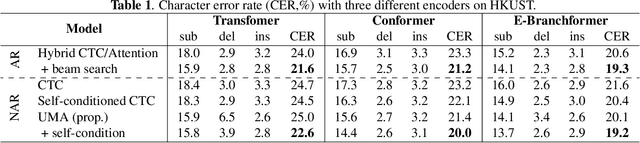
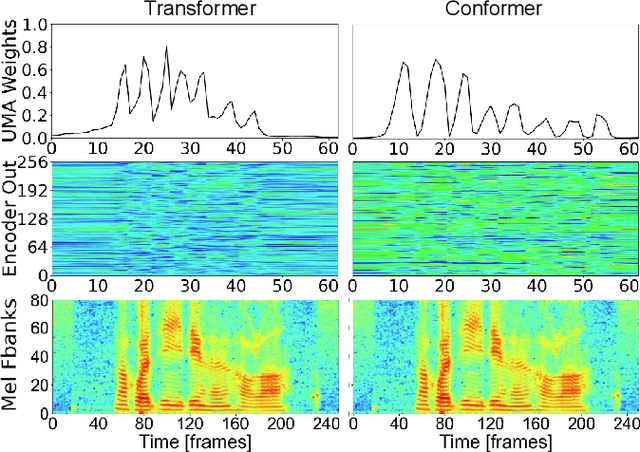
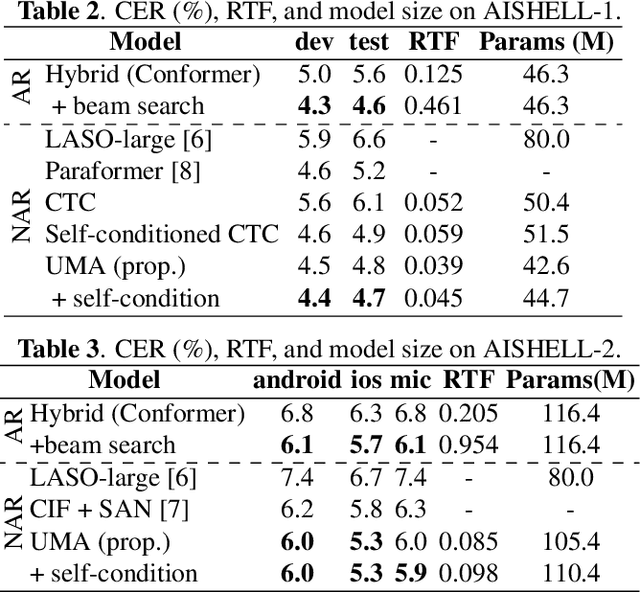
This paper works on non-autoregressive automatic speech recognition. A unimodal aggregation (UMA) is proposed to segment and integrate the feature frames that belong to the same text token, and thus to learn better feature representations for text tokens. The frame-wise features and weights are both derived from an encoder. Then, the feature frames with unimodal weights are integrated and further processed by a decoder. Connectionist temporal classification (CTC) loss is applied for training. Compared to the regular CTC, the proposed method learns better feature representations and shortens the sequence length, resulting in lower recognition error and computational complexity. Experiments on three Mandarin datasets show that UMA demonstrates superior or comparable performance to other advanced non-autoregressive methods, such as self-conditioned CTC. Moreover, by integrating self-conditioned CTC into the proposed framework, the performance can be further noticeably improved.