 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Symbolic Music Structure Analysis with Graph Representations and Changepoint Detection Methods
Mar 24, 2023
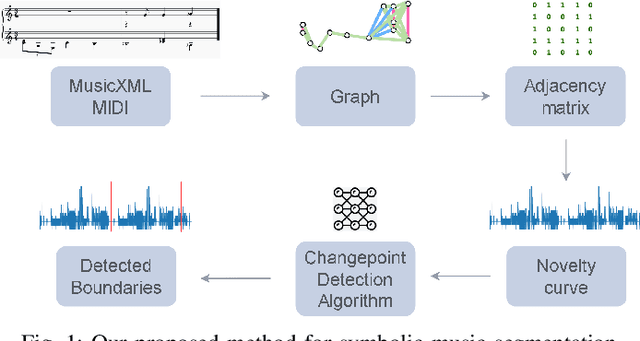


Music Structure Analysis is an open research task in Music Information Retrieval (MIR). In the past, there have been several works that attempt to segment music into the audio and symbolic domains, however, the identification and segmentation of the music structure at different levels is still an open research problem in this area. In this work we propose three methods, two of which are novel graph-based algorithms that aim to segment symbolic music by its form or structure: Norm, G-PELT and G-Window. We performed an ablation study with two public datasets that have different forms or structures in order to compare such methods varying their parameter values and comparing the performance against different music styles. We have found that encoding symbolic music with graph representations and computing the novelty of Adjacency Matrices obtained from graphs represent the structure of symbolic music pieces well without the need to extract features from it. We are able to detect the boundaries with an online unsupervised changepoint detection method with a F_1 of 0.5640 for a 1 bar tolerance in one of the public datasets that we used for testing our methods. We also provide the performance results of the algorithms at different levels of structure, high, medium and low, to show how the parameters of the proposed methods have to be adjusted depending on the level. We added the best performing method with its parameters for each structure level to musicaiz, an open source python package, to facilitate the reproducibility and usability of this work. We hope that this methods could be used to improve other MIR tasks such as music generation with structure, music classification or key changes detection.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023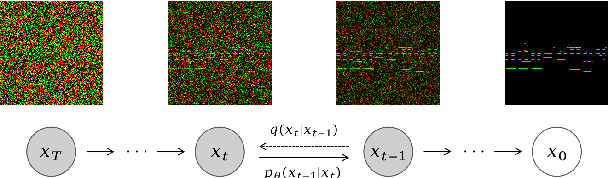

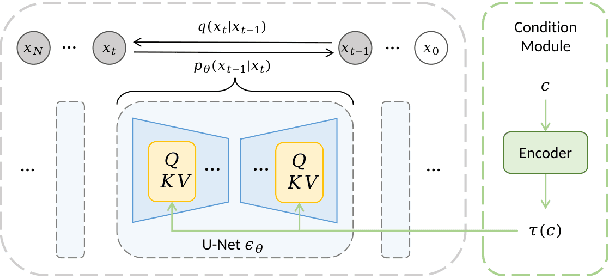
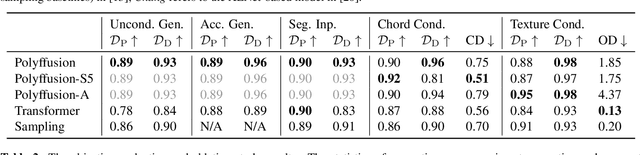
We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.
AIoT-Based Drum Transcription Robot using Convolutional Neural Networks
Aug 29, 2023With the development of information technology, robot technology has made great progress in various fields. These new technologies enable robots to be used in industry, agriculture, education and other aspects. In this paper, we propose a drum robot that can automatically complete music transcription in real-time, which is based on AIoT and fog computing technology. Specifically, this drum robot system consists of a cloud node for data storage, edge nodes for real-time computing, and data-oriented execution application nodes. In order to analyze drumming music and realize drum transcription, we further propose a light-weight convolutional neural network model to classify drums, which can be more effectively deployed in terminal devices for fast edge calculations. The experimental results show that the proposed system can achieve more competitive performance and enjoy a variety of smart applications and services.
Collaborative Song Dataset (CoSoD): An annotated dataset of multi-artist collaborations in popular music
Jul 10, 2023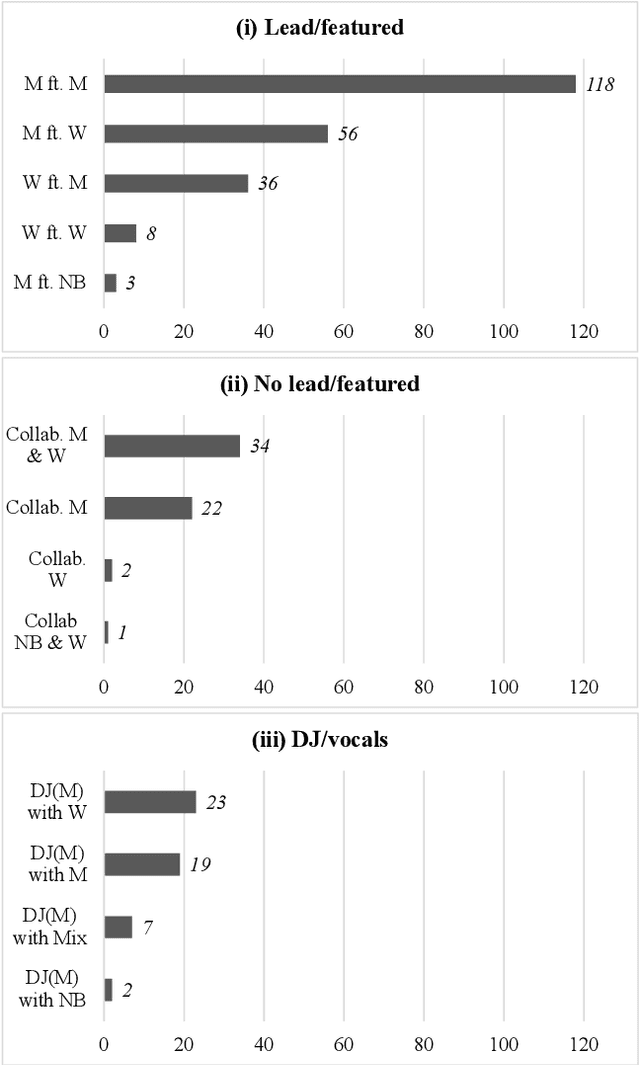
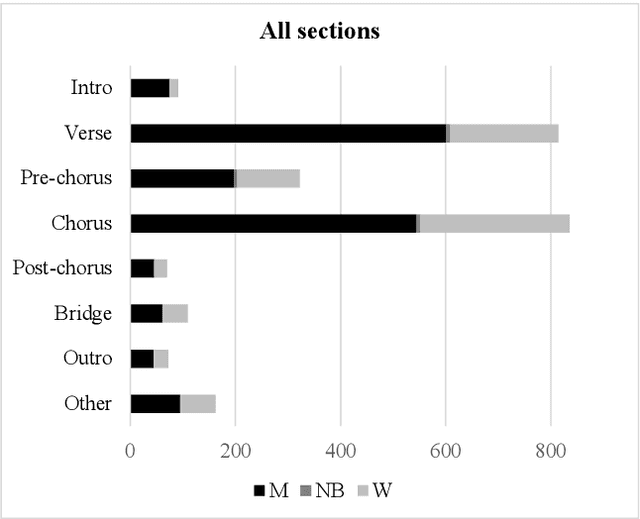
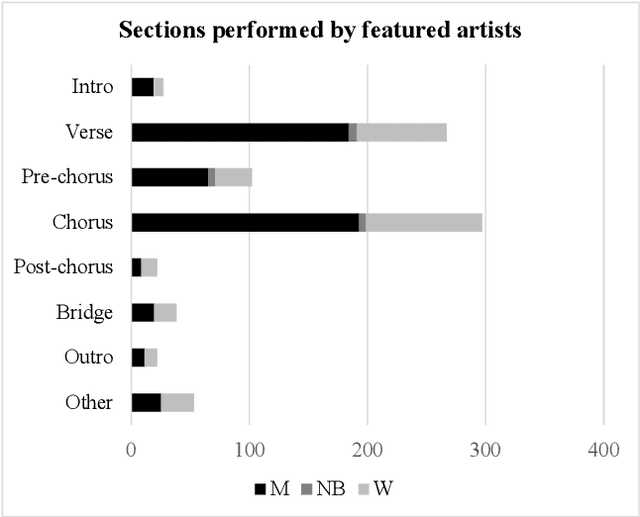
The Collaborative Song Dataset (CoSoD) is a corpus of 331 multi-artist collaborations from the 2010-2019 Billboard "Hot 100" year-end charts. The corpus is annotated with formal sections, aspects of vocal production (including reverberation, layering, panning, and gender of the performers), and relevant metadata. CoSoD complements other popular music datasets by focusing exclusively on musical collaborations between independent acts. In addition to facilitating the study of song form and vocal production, CoSoD allows for the in-depth study of gender as it relates to various timbral, pitch, and formal parameters in musical collaborations. In this paper, we detail the contents of the dataset and outline the annotation process. We also present an experiment using CoSoD that examines how the use of reverberation, layering, and panning are related to the gender of the artist. In this experiment, we find that men's voices are on average treated with less reverberation and occupy a more narrow position in the stereo mix than women's voices.
TM2D: Bimodality Driven 3D Dance Generation via Music-Text Integration
Apr 05, 2023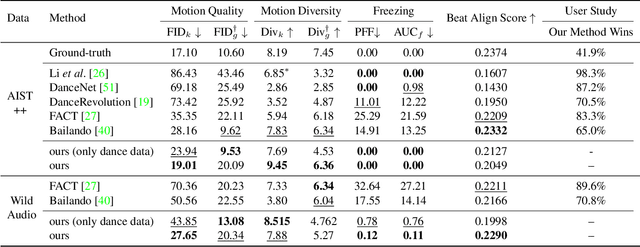
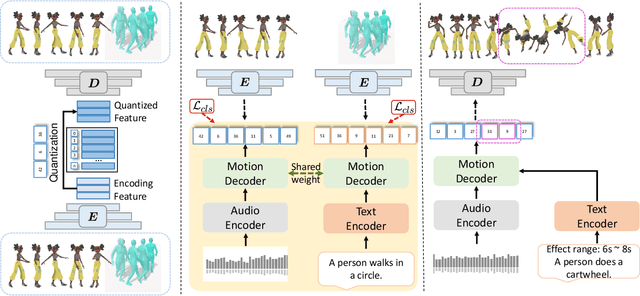
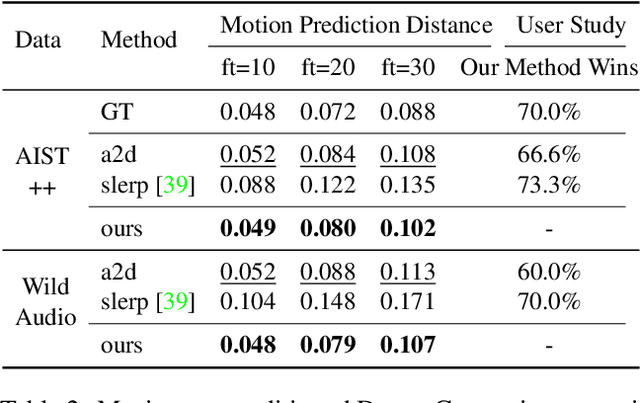
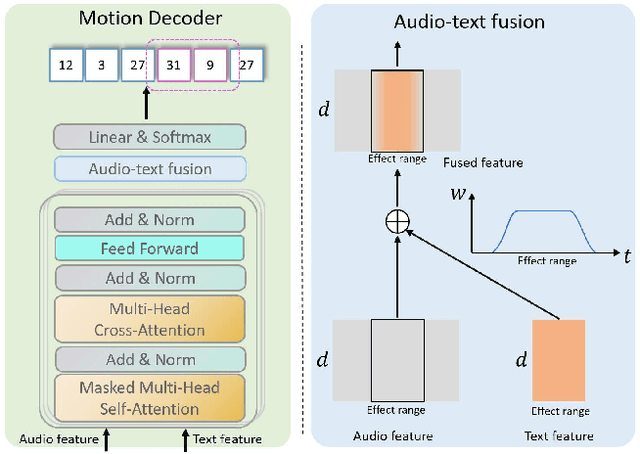
We propose a novel task for generating 3D dance movements that simultaneously incorporate both text and music modalities. Unlike existing works that generate dance movements using a single modality such as music, our goal is to produce richer dance movements guided by the instructive information provided by the text. However, the lack of paired motion data with both music and text modalities limits the ability to generate dance movements that integrate both. To alleviate this challenge, we propose to utilize a 3D human motion VQ-VAE to project the motions of the two datasets into a latent space consisting of quantized vectors, which effectively mix the motion tokens from the two datasets with different distributions for training. Additionally, we propose a cross-modal transformer to integrate text instructions into motion generation architecture for generating 3D dance movements without degrading the performance of music-conditioned dance generation. To better evaluate the quality of the generated motion, we introduce two novel metrics, namely Motion Prediction Distance (MPD) and Freezing Score, to measure the coherence and freezing percentage of the generated motion. Extensive experiments show that our approach can generate realistic and coherent dance movements conditioned on both text and music while maintaining comparable performance with the two single modalities. Code will be available at: https://garfield-kh.github.io/TM2D/.
PitchNet: A Fully Convolutional Neural Network for Pitch Estimation
Aug 14, 2023In the domain of music and sound processing, pitch extraction plays a pivotal role. This research introduces "PitchNet", a convolutional neural network tailored for pitch extraction from the human singing voice, including acapella performances. Integrating autocorrelation with deep learning techniques, PitchNet aims to optimize the accuracy of pitch detection. Evaluation across datasets comprising synthetic sounds, opera recordings, and time-stretched vowels demonstrates its efficacy. This work paves the way for enhanced pitch extraction in both music and voice settings.
JEPOO: Highly Accurate Joint Estimation of Pitch, Onset and Offset for Music Information Retrieval
Jun 02, 2023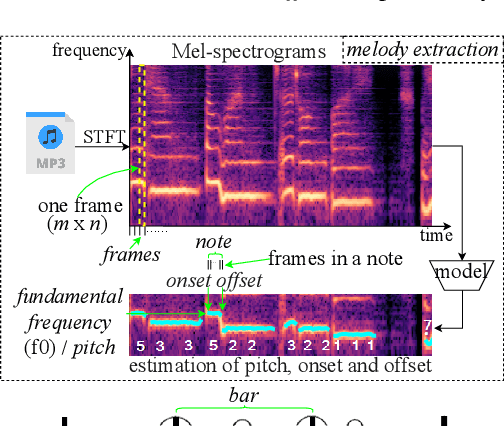
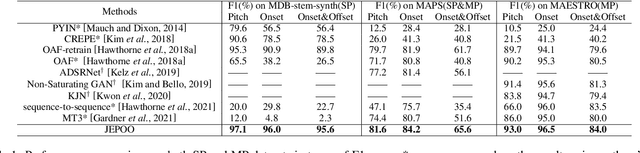
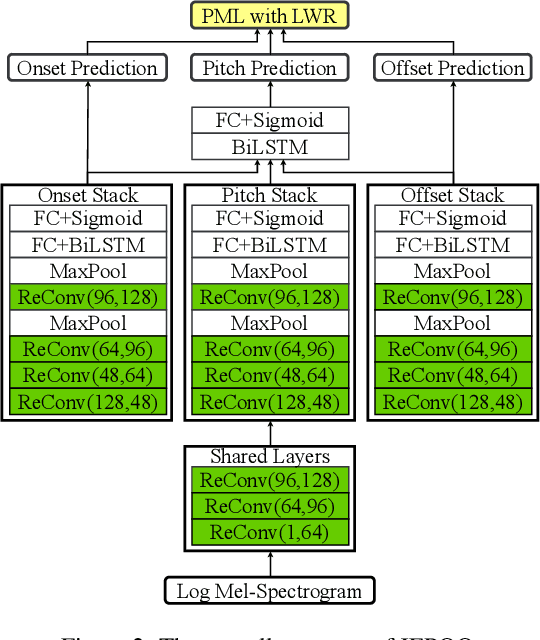
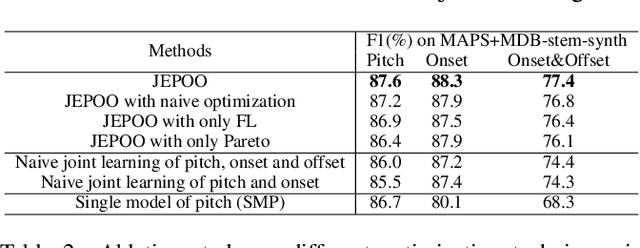
Melody extraction is a core task in music information retrieval, and the estimation of pitch, onset and offset are key sub-tasks in melody extraction. Existing methods have limited accuracy, and work for only one type of data, either single-pitch or multipitch. In this paper, we propose a highly accurate method for joint estimation of pitch, onset and offset, named JEPOO. We address the challenges of joint learning optimization and handling both single-pitch and multi-pitch data through novel model design and a new optimization technique named Pareto modulated loss with loss weight regularization. This is the first method that can accurately handle both single-pitch and multi-pitch music data, and even a mix of them. A comprehensive experimental study on a wide range of real datasets shows that JEPOO outperforms state-ofthe-art methods by up to 10.6%, 8.3% and 10.3% for the prediction of Pitch, Onset and Offset, respectively, and JEPOO is robust for various types of data and instruments. The ablation study shows the effectiveness of each component of JEPOO.
The Role of Communication and Reference Songs in the Mixing Process: Insights from Professional Mix Engineers
Sep 08, 2023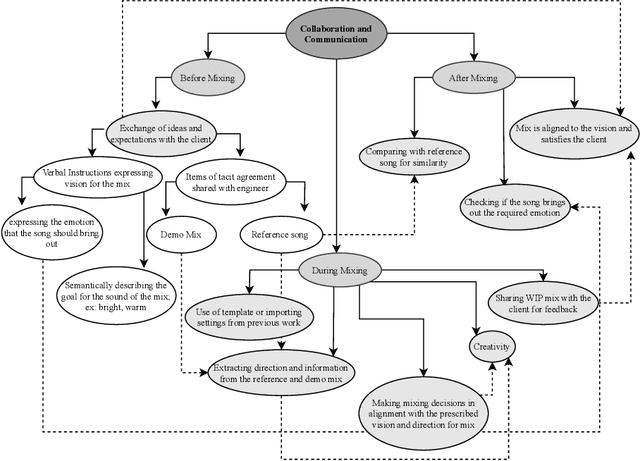
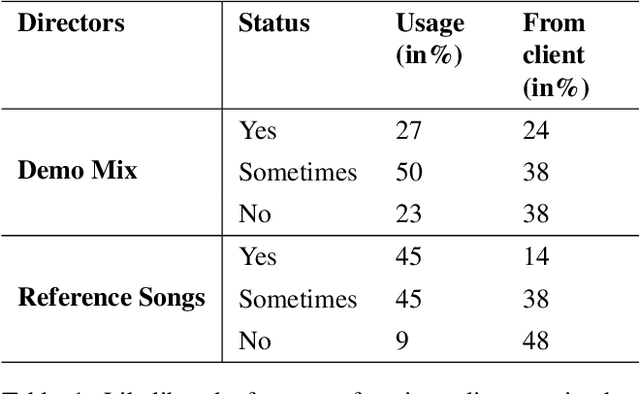
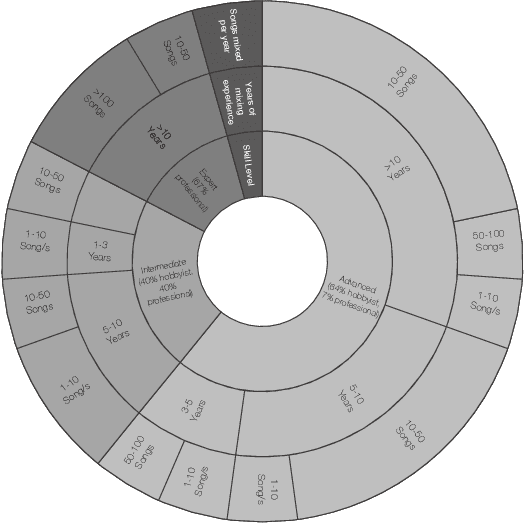
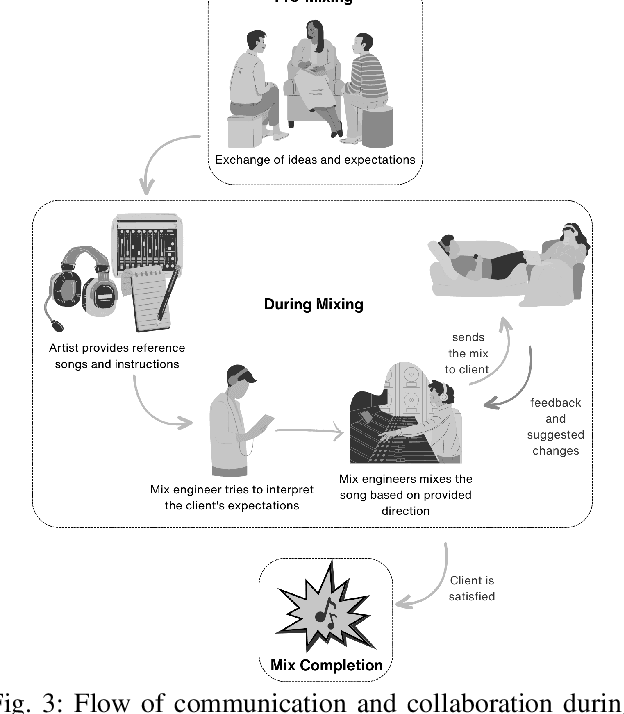
Effective music mixing requires technical and creative finesse, but clear communication with the client is crucial. The mixing engineer must grasp the client's expectations, and preferences, and collaborate to achieve the desired sound. The tacit agreement for the desired sound of the mix is often established using guides like reference songs and demo mixes exchanged between the artist and the engineer and sometimes verbalised using semantic terms. This paper presents the findings of a two-phased exploratory study aimed at understanding how professional mixing engineers interact with clients and use their feedback to guide the mixing process. For phase one, semi-structured interviews were conducted with five mixing engineers with the aim of gathering insights about their communication strategies, creative processes, and decision-making criteria. Based on the inferences from these interviews, an online questionnaire was designed and administered to a larger group of 22 mixing engineers during the second phase. The results of this study shed light on the importance of collaboration, empathy, and intention in the mixing process, and can inform the development of smart multi-track mixing systems that better support these practices. By highlighting the significance of these findings, this paper contributes to the growing body of research on the collaborative nature of music production and provides actionable recommendations for the design and implementation of innovative mixing tools.
DiffuseRoll: Multi-track multi-category music generation based on diffusion model
Mar 14, 2023Recent advancements in generative models have shown remarkable progress in music generation. However, most existing methods focus on generating monophonic or homophonic music, while the generation of polyphonic and multi-track music with rich attributes is still a challenging task. In this paper, we propose a novel approach for multi-track, multi-attribute symphonic music generation using the diffusion model. Specifically, we generate piano-roll representations with a diffusion model and map them to MIDI format for output. To capture rich attribute information, we introduce a color coding scheme to encode note sequences into color and position information that represents pitch,velocity, and instrument. This scheme enables a seamless mapping between discrete music sequences and continuous images. We also propose a post-processing method to optimize the generated scores for better performance. Experimental results show that our method outperforms state-of-the-art methods in terms of polyphonic music generation with rich attribute information compared to the figure methods.