 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Understanding and Compressing Music with Maximal Transformable Patterns
Jan 26, 2022
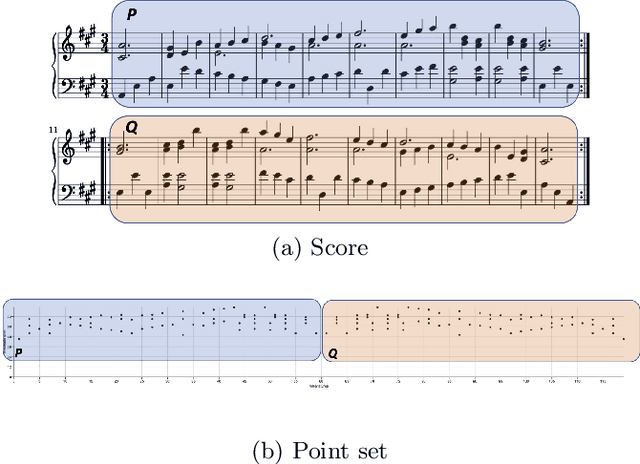
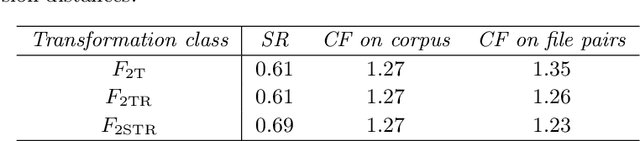
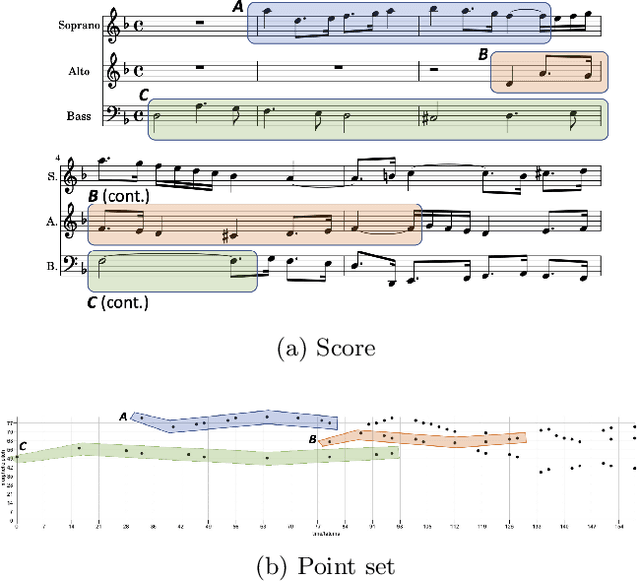

We present a polynomial-time algorithm that discovers all maximal patterns in a point set, $D\in\mathbb{R}^k$, that are related by transformations in a user-specified class, $F$, of bijections over $\mathbb{R}^k$. We also present a second algorithm that discovers the set of occurrences for each of these maximal patterns and then uses compact encodings of these occurrence sets to compute a losslessly compressed encoding of the input point set. This encoding takes the form of a set of pairs, $E=\left\lbrace\left\langle P_1, T_1\right\rangle,\left\langle P_2, T_2\right\rangle,\ldots\left\langle P_{\ell}, T_{\ell}\right\rangle\right\rbrace$, where each $\langle P_i,T_i\rangle$ consists of a maximal pattern, $P_i\subseteq D$, and a set, $T_i\subset F$, of transformations that map $P_i$ onto other subsets of $D$. Each transformation is encoded by a vector of real values that uniquely identifies it within $F$ and the length of this vector is used as a measure of the complexity of $F$. We evaluate the new compression algorithm with three transformation classes of differing complexity, on the task of classifying folk-song melodies into tune families. The most complex of the classes tested includes all combinations of the musical transformations of transposition, inversion, retrograde, augmentation and diminution. We found that broadening the transformation class improved performance on this task. However, it did not, on average, improve compression factor, which may be due to the datasets (in this case, folk-song melodies) being too short and simple to benefit from the potentially greater number of pattern relationships that are discoverable with larger transformation classes.
Algorithmic Clustering of Music
Mar 24, 2003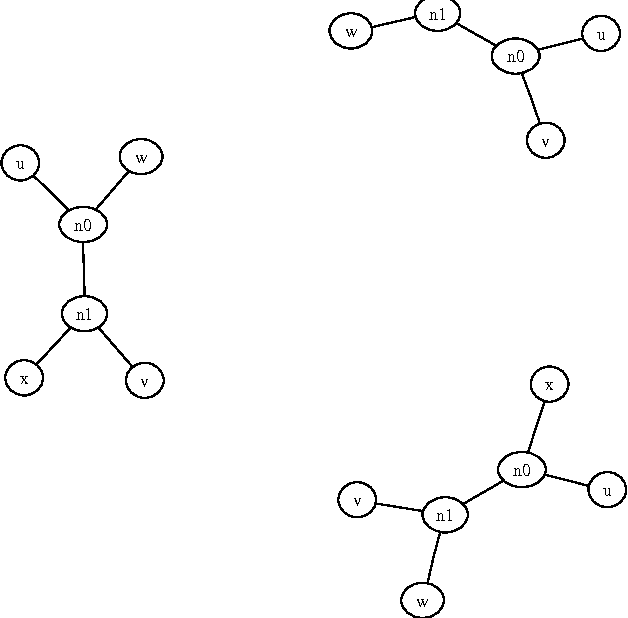

We present a fully automatic method for music classification, based only on compression of strings that represent the music pieces. The method uses no background knowledge about music whatsoever: it is completely general and can, without change, be used in different areas like linguistic classification and genomics. It is based on an ideal theory of the information content in individual objects (Kolmogorov complexity), information distance, and a universal similarity metric. Experiments show that the method distinguishes reasonably well between various musical genres and can even cluster pieces by composer.
Expressive Singing Synthesis Using Local Style Token and Dual-path Pitch Encoder
Apr 07, 2022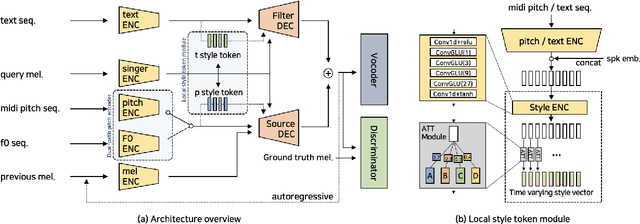
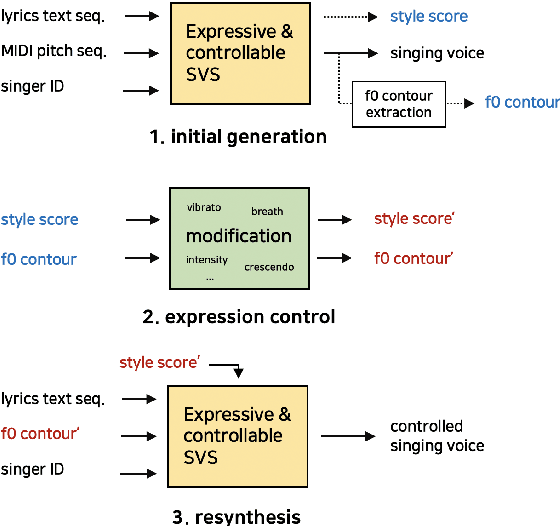
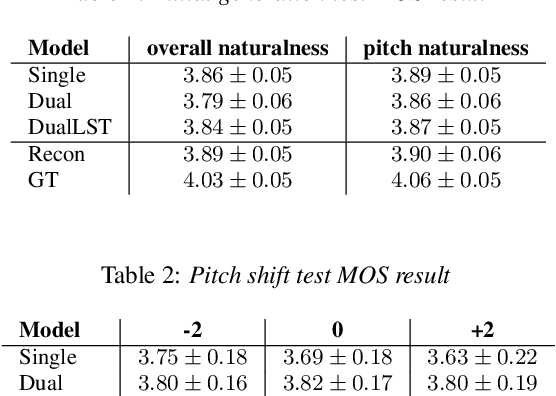
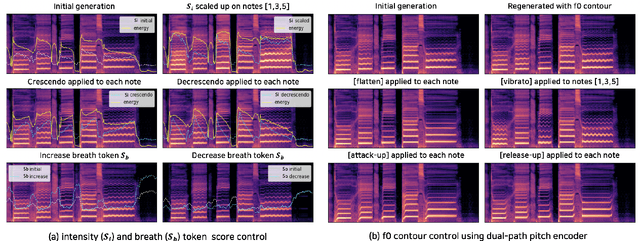
This paper proposes a controllable singing voice synthesis system capable of generating expressive singing voice with two novel methodologies. First, a local style token module, which predicts frame-level style tokens from an input pitch and text sequence, is proposed to allow the singing voice system to control musical expression often unspecified in sheet music (e.g., breathing and intensity). Second, we propose a dual-path pitch encoder with a choice of two different pitch inputs: MIDI pitch sequence or f0 contour. Because the initial generation of a singing voice is usually executed by taking a MIDI pitch sequence, one can later extract an f0 contour from the generated singing voice and modify the f0 contour to a finer level as desired. Through quantitative and qualitative evaluations, we confirmed that the proposed model could control various musical expressions while not sacrificing the sound quality of the singing voice synthesis system.
Superconducting qubits as musical synthesizers for live performance
Mar 11, 2022

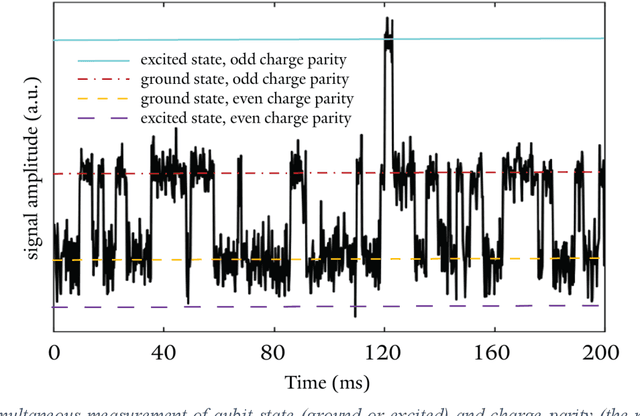
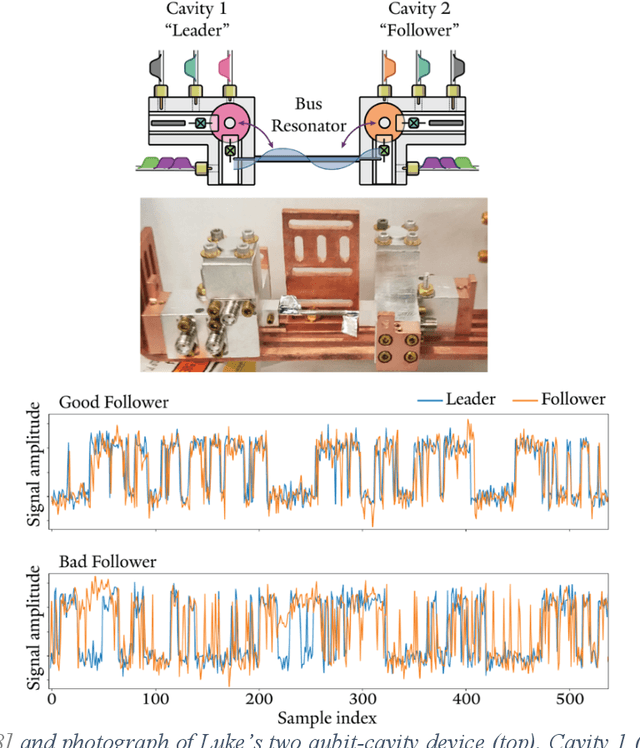
In the frame of a year-long artistic residency at the Yale Quantum Institute in 2019, artist and technologist Spencer Topel and quantum physicists Kyle Serniak and Luke Burkhart collaborated to create Quantum Sound, the first-ever music created and performed directly from measurements of superconducting quantum devices. Using analog- and digital-signal-processing sonification techniques, the team transformed GHz-frequency signals from experiments inside dilution refrigerators into audible sounds. The project was performed live at the International Festival of Arts and Ideas in New Haven, Connecticut on June 14, 2019 as a structured improvisation using the synthesis methods described in this chapter. At the interface between research and art, Quantum Sound represents an earnest attempt to produce a sonic reflection of the quantum realm.
Text-based LSTM networks for Automatic Music Composition
Apr 18, 2016

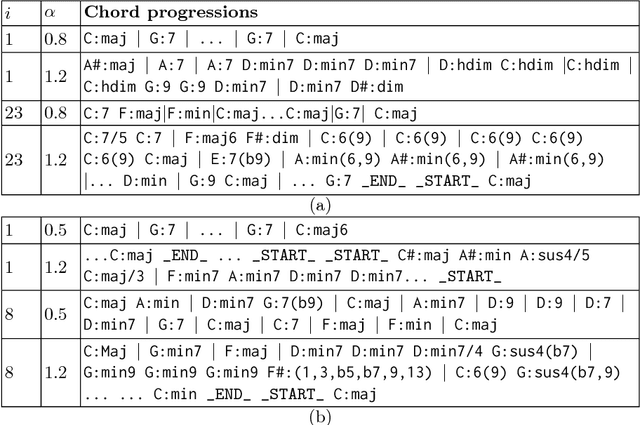
In this paper, we introduce new methods and discuss results of text-based LSTM (Long Short-Term Memory) networks for automatic music composition. The proposed network is designed to learn relationships within text documents that represent chord progressions and drum tracks in two case studies. In the experiments, word-RNNs (Recurrent Neural Networks) show good results for both cases, while character-based RNNs (char-RNNs) only succeed to learn chord progressions. The proposed system can be used for fully automatic composition or as semi-automatic systems that help humans to compose music by controlling a diversity parameter of the model.
BacHMMachine: An Interpretable and Scalable Model for Algorithmic Harmonization for Four-part Baroque Chorales
Sep 15, 2021

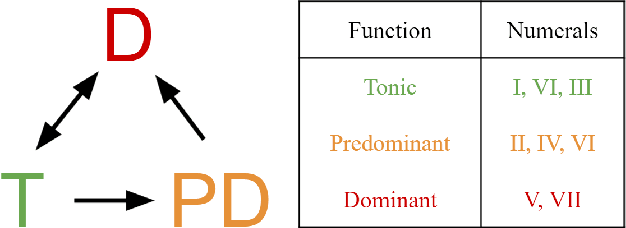

Algorithmic harmonization - the automated harmonization of a musical piece given its melodic line - is a challenging problem that has garnered much interest from both music theorists and computer scientists. One genre of particular interest is the four-part Baroque chorales of J.S. Bach. Methods for algorithmic chorale harmonization typically adopt a black-box, "data-driven" approach: they do not explicitly integrate principles from music theory but rely on a complex learning model trained with a large amount of chorale data. We propose instead a new harmonization model, called BacHMMachine, which employs a "theory-driven" framework guided by music composition principles, along with a "data-driven" model for learning compositional features within this framework. As its name suggests, BacHMMachine uses a novel Hidden Markov Model based on key and chord transitions, providing a probabilistic framework for learning key modulations and chordal progressions from a given melodic line. This allows for the generation of creative, yet musically coherent chorale harmonizations; integrating compositional principles allows for a much simpler model that results in vast decreases in computational burden and greater interpretability compared to state-of-the-art algorithmic harmonization methods, at no penalty to quality of harmonization or musicality. We demonstrate this improvement via comprehensive experiments and Turing tests comparing BacHMMachine to existing methods.
Target Sensing with Intelligent Reflecting Surface: Architecture and Performance
Jan 22, 2022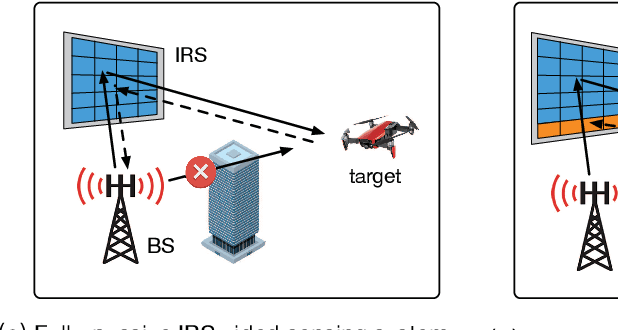
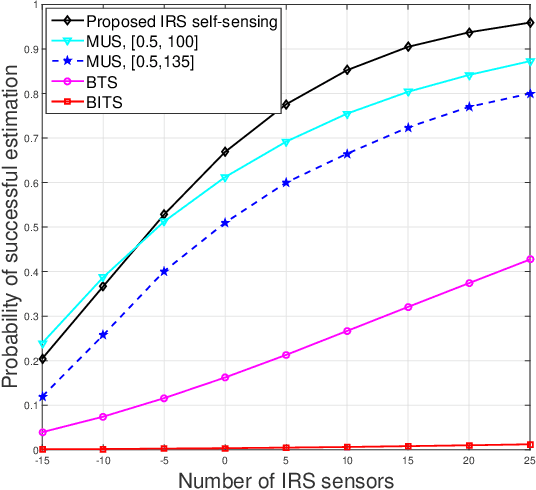
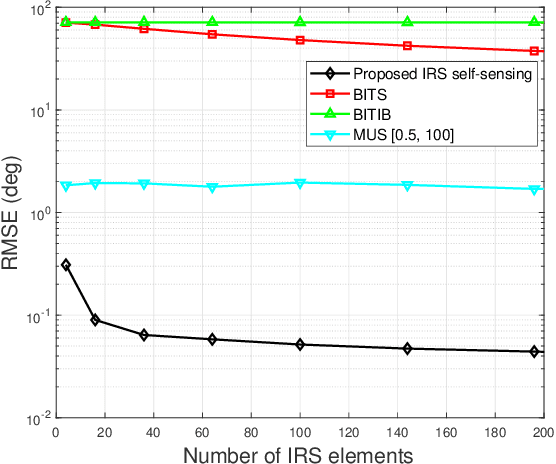
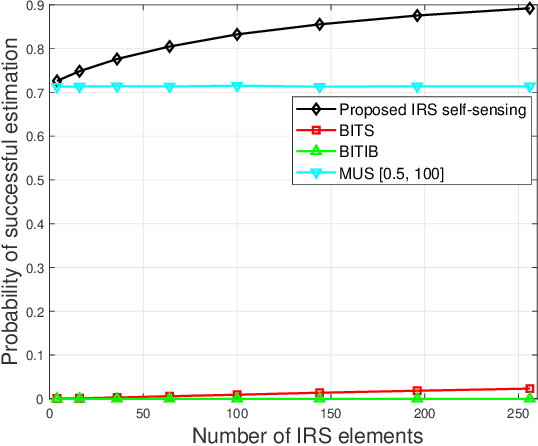
Intelligent reflecting surface (IRS) has emerged as a promising technology to reconfigure the radio propagation environment by dynamically controlling wireless signal's amplitude and/or phase via a large number of reflecting elements. In contrast to the vast literature on studying IRS's performance gains in wireless communications, we study in this paper a new application of IRS for sensing/localizing targets in wireless networks. Specifically, we propose a new self-sensing IRS architecture where the IRS controller is capable of transmitting probing signals that are not only directly reflected by the target (referred to as the direct echo link), but also consecutively reflected by the IRS and then the target (referred to as the IRS-reflected echo link). Moreover, dedicated sensors are installed at the IRS for receiving both the direct and IRS-reflected echo signals from the target, such that the IRS can sense the direction of its nearby target by applying a customized multiple signal classification (MUSIC) algorithm. However, since the angle estimation mean square error (MSE) by the MUSIC algorithm is intractable, we propose to optimize the IRS passive reflection for maximizing the average echo signals' total power at the IRS sensors and derive the resultant Cramer-Rao bound (CRB) of the angle estimation MSE. Last, numerical results are presented to show the effectiveness of the proposed new IRS sensing architecture and algorithm, as compared to other benchmark sensing systems/algorithms.
Music, Complexity, Information
Jul 03, 2008These are the preparatory notes for a Science & Music essay, "Playing by numbers", appeared in Nature 453 (2008) 988-989.
Music Data Analysis: A State-of-the-art Survey
Nov 18, 2014
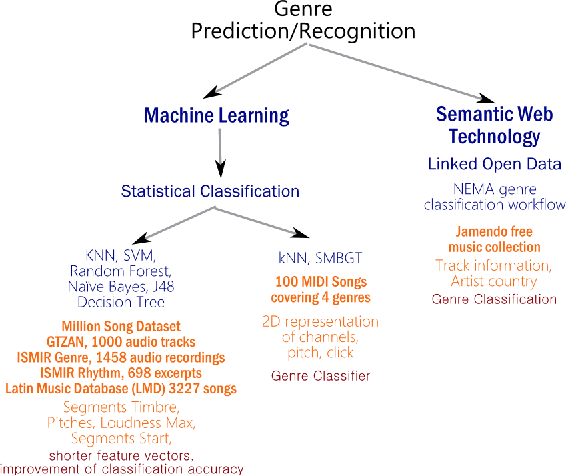
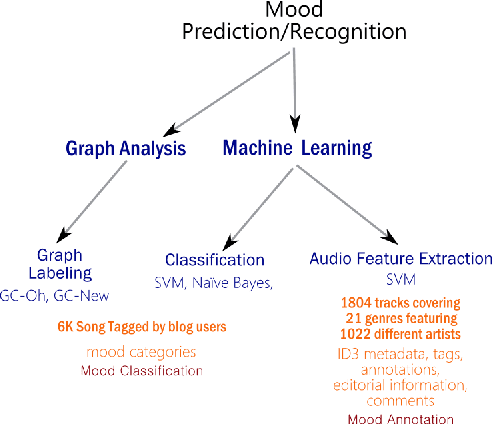
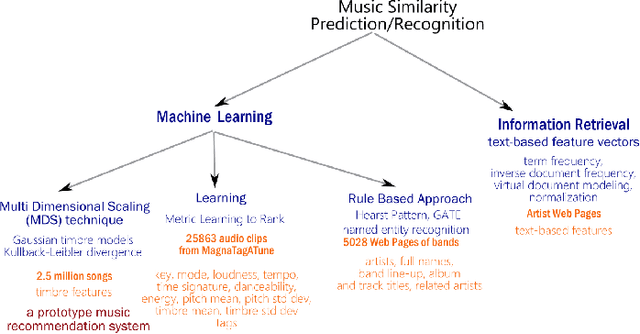
Music accounts for a significant chunk of interest among various online activities. This is reflected by wide array of alternatives offered in music related web/mobile apps, information portals, featuring millions of artists, songs and events attracting user activity at similar scale. Availability of large scale structured and unstructured data has attracted similar level of attention by data science community. This paper attempts to offer current state-of-the-art in music related analysis. Various approaches involving machine learning, information theory, social network analysis, semantic web and linked open data are represented in the form of taxonomy along with data sources and use cases addressed by the research community.
A Statistical Model for Melody Reduction
May 12, 2021


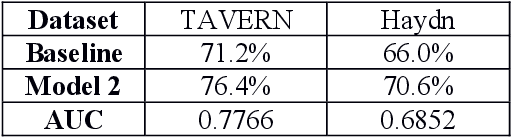
A commonly-cited reason for the poor performance of automatic chord estimation (ACE) systems within music information retrieval (MIR) is that non-chord tones (i.e., notes outside the supporting harmony) contribute to error during the labeling process. Despite the prevalence of machine learning approaches in MIR, there are cases where alternative approaches provide a simpler alternative while allowing for insights into musicological practices. In this project, we present a statistical model for predicting chord tones based on music theory rules. Our model is currently focused on predicting chord tones in classical music, since composition in this style is highly constrained, theoretically making the placement of chord tones highly predictable. Indeed, music theorists have labeling systems for every variety of non-chord tone, primarily classified by the note's metric position and intervals of approach and departure. Using metric position, duration, and melodic intervals as predictors, we build a statistical model for predicting chord tones using the TAVERN dataset. While our probabilistic approach is similar to other efforts in the domain of automatic harmonic analysis, our focus is on melodic reduction rather than predicting harmony. However, we hope to pursue applications for ACE in the future. Finally, we implement our melody reduction model using an existing symbolic visualization tool, to assist with melody reduction and non-chord tone identification for computational musicology researchers and music theorists.