 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork motifs in music sequences
Mar 04, 2011This paper has been withdrawn by the author because it needs a deep methodological revision.
Music, Complexity, Information
Jul 03, 2008These are the preparatory notes for a Science & Music essay, "Playing by numbers", appeared in Nature 453 (2008) 988-989.
Analytical approach to bit-string models of language evolution
Nov 08, 2007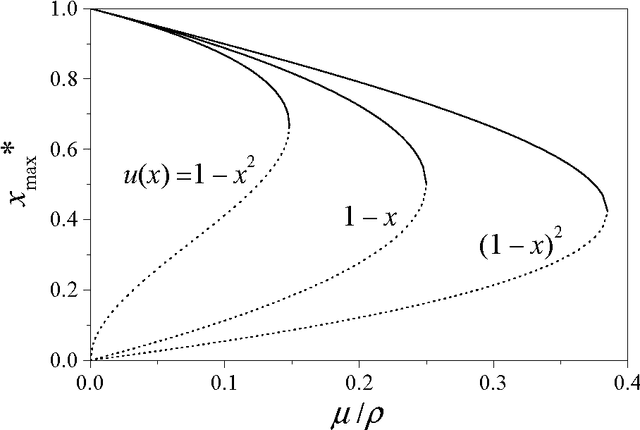
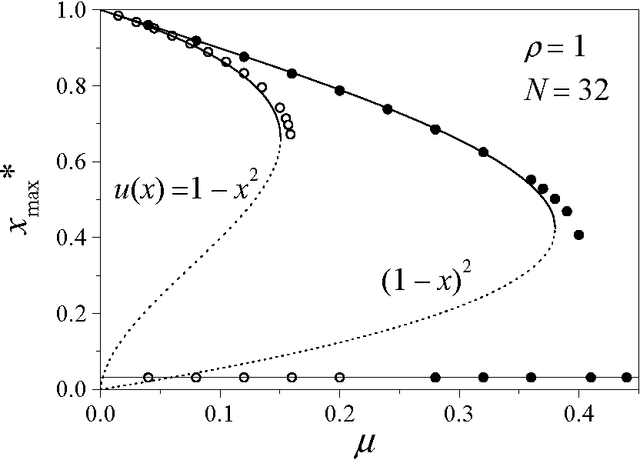
A formulation of bit-string models of language evolution, based on differential equations for the population speaking each language, is introduced and preliminarily studied. Connections with replicator dynamics and diffusion processes are pointed out. The stability of the dominance state, where most of the population speaks a single language, is analyzed within a mean-field-like approximation, while the homogeneous state, where the population is evenly distributed among languages, can be exactly studied. This analysis discloses the existence of a bistability region, where dominance coexists with homogeneity as possible asymptotic states. Numerical resolution of the differential system validates these findings.
Demographic growth and the distribution of language sizes
Oct 08, 2007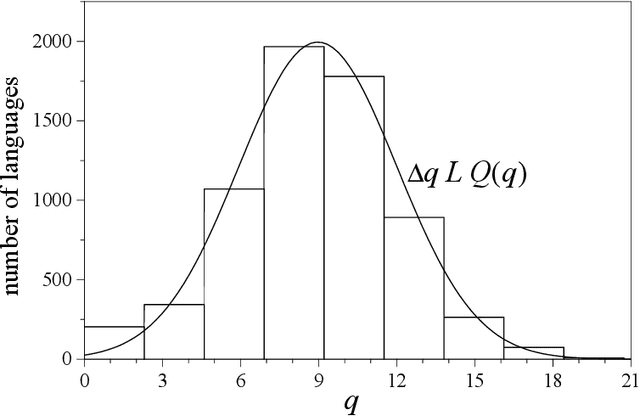
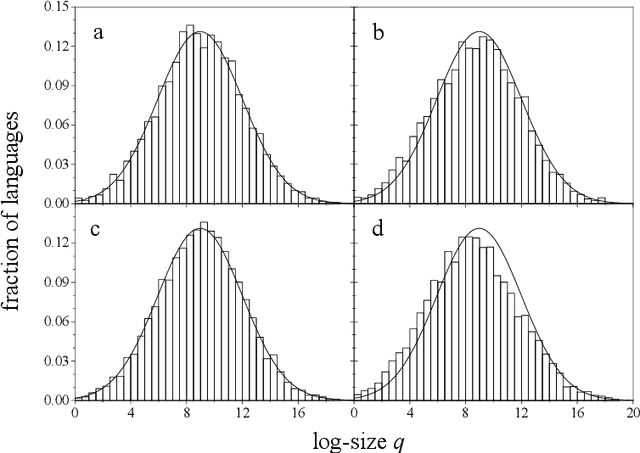
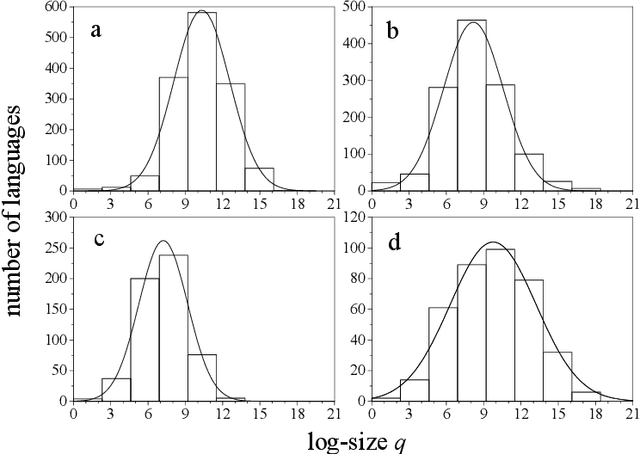
It is argued that the present log-normal distribution of language sizes is, to a large extent, a consequence of demographic dynamics within the population of speakers of each language. A two-parameter stochastic multiplicative process is proposed as a model for the population dynamics of individual languages, and applied over a period spanning the last ten centuries. The model disregards language birth and death. A straightforward fitting of the two parameters, which statistically characterize the population growth rate, predicts a distribution of language sizes in excellent agreement with empirical data. Numerical simulations, and the study of the size distribution within language families, validate the assumptions at the basis of the model.
Segmentation and Context of Literary and Musical Sequences
Jul 06, 2007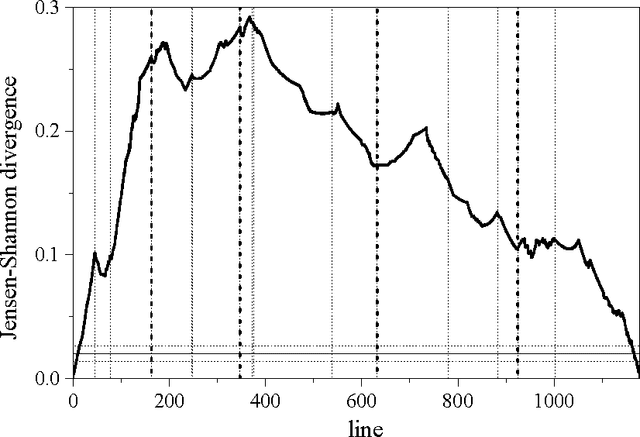
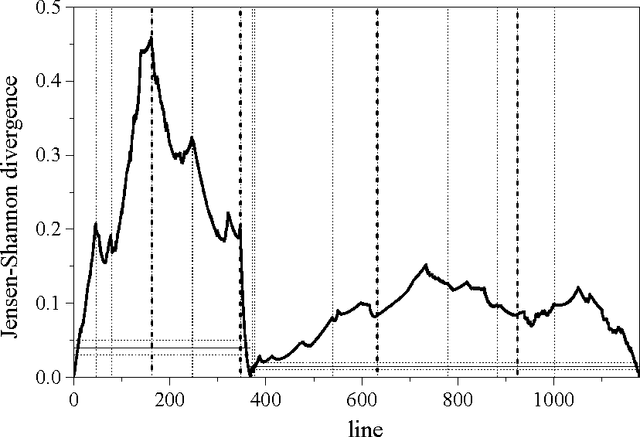
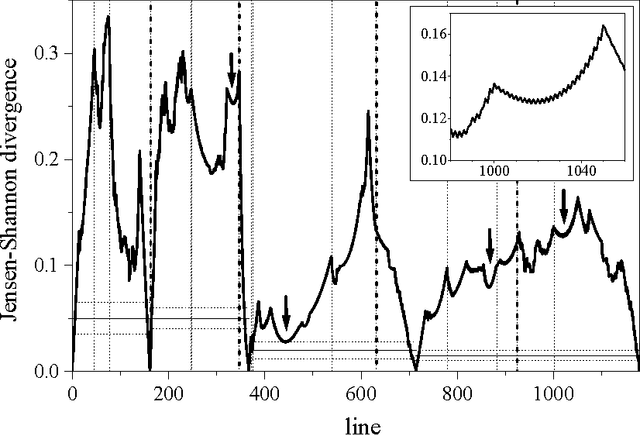
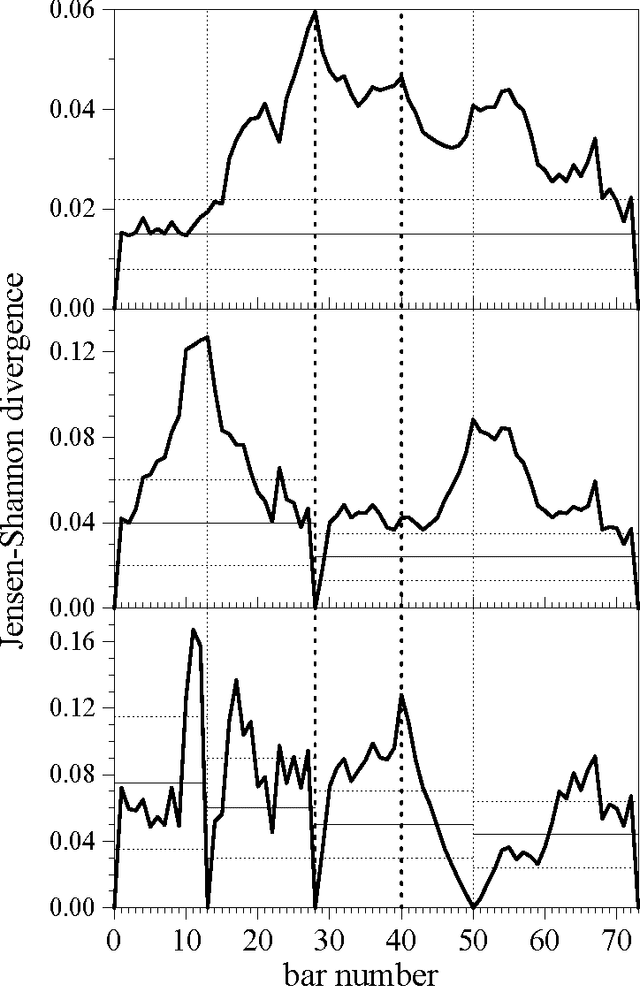
We test a segmentation algorithm, based on the calculation of the Jensen-Shannon divergence between probability distributions, to two symbolic sequences of literary and musical origin. The first sequence represents the successive appearance of characters in a theatrical play, and the second represents the succession of tones from the twelve-tone scale in a keyboard sonata. The algorithm divides the sequences into segments of maximal compositional divergence between them. For the play, these segments are related to changes in the frequency of appearance of different characters and in the geographical setting of the action. For the sonata, the segments correspond to tonal domains and reveal in detail the characteristic tonal progression of such kind of musical composition.
Zipf's law and the creation of musical context
Jun 07, 2004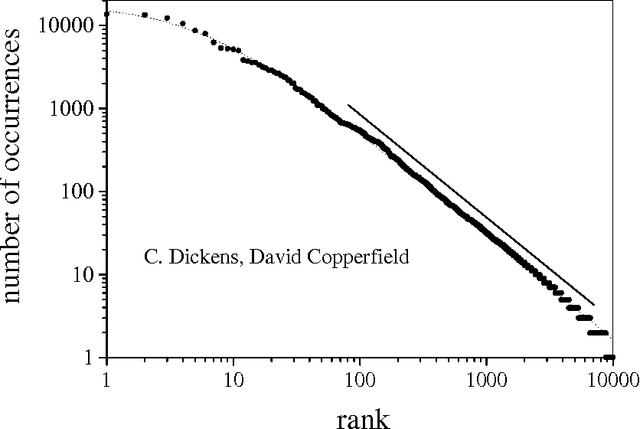
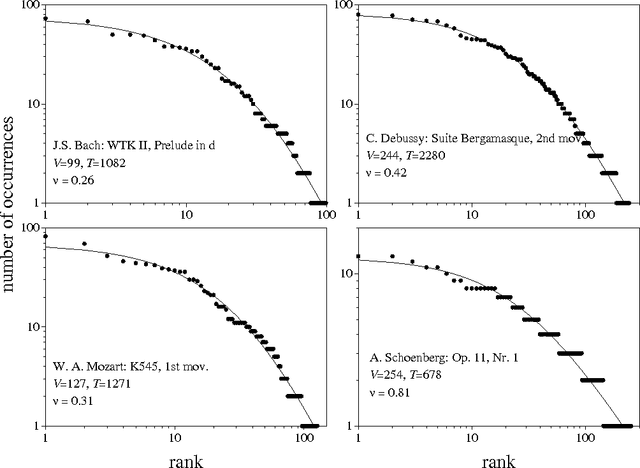
This article discusses the extension of the notion of context from linguistics to the domain of music. In language, the statistical regularity known as Zipf's law -which concerns the frequency of usage of different words- has been quantitatively related to the process of text generation. This connection is established by Simon's model, on the basis of a few assumptions regarding the accompanying creation of context. Here, it is shown that the statistics of note usage in musical compositions are compatible with the predictions of Simon's model. This result, which gives objective support to the conceptual likeness of context in language and music, is obtained through automatic analysis of the digital versions of several compositions. As a by-product, a quantitative measure of context definiteness is introduced and used to compare tonal and atonal works.
Entropic analysis of the role of words in literary texts
Sep 12, 2001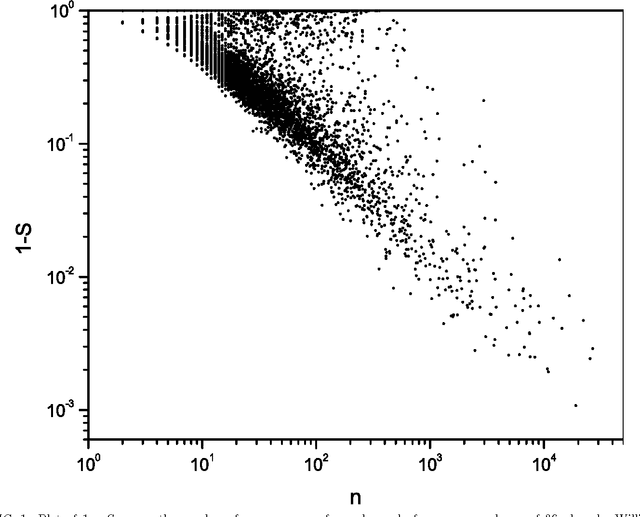
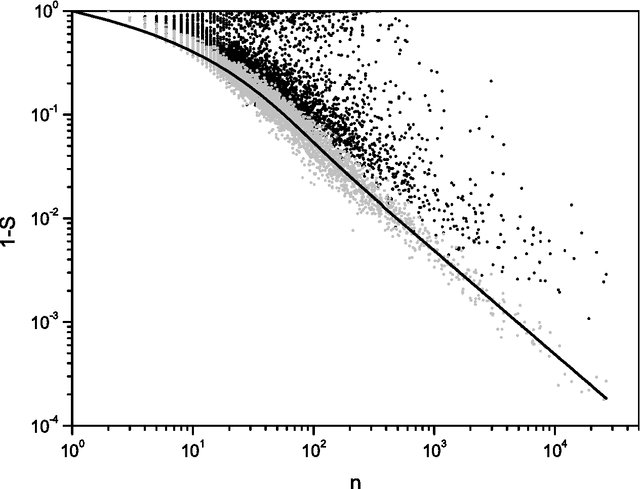
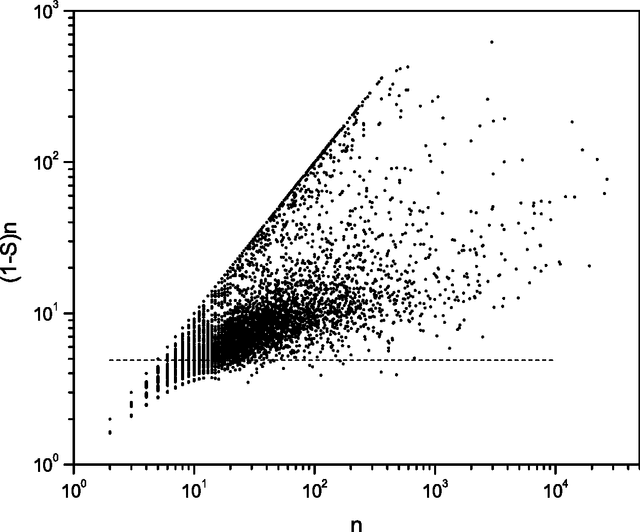
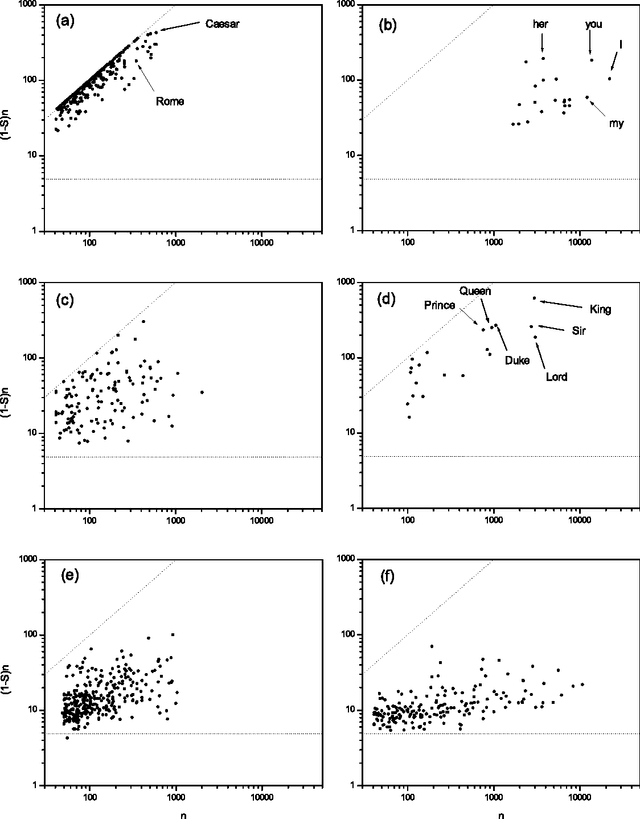
Beyond the local constraints imposed by grammar, words concatenated in long sequences carrying a complex message show statistical regularities that may reflect their linguistic role in the message. In this paper, we perform a systematic statistical analysis of the use of words in literary English corpora. We show that there is a quantitative relation between the role of content words in literary English and the Shannon information entropy defined over an appropriate probability distribution. Without assuming any previous knowledge about the syntactic structure of language, we are able to cluster certain groups of words according to their specific role in the text.