 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Revisiting Self-Supervised Contrastive Learning for Facial Expression Recognition
Oct 08, 2022
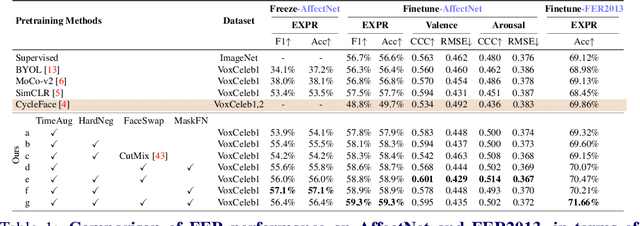


The success of most advanced facial expression recognition works relies heavily on large-scale annotated datasets. However, it poses great challenges in acquiring clean and consistent annotations for facial expression datasets. On the other hand, self-supervised contrastive learning has gained great popularity due to its simple yet effective instance discrimination training strategy, which can potentially circumvent the annotation issue. Nevertheless, there remain inherent disadvantages of instance-level discrimination, which are even more challenging when faced with complicated facial representations. In this paper, we revisit the use of self-supervised contrastive learning and explore three core strategies to enforce expression-specific representations and to minimize the interference from other facial attributes, such as identity and face styling. Experimental results show that our proposed method outperforms the current state-of-the-art self-supervised learning methods, in terms of both categorical and dimensional facial expression recognition tasks.
Facial Expression Video Generation Based-On Spatio-temporal Convolutional GAN: FEV-GAN
Oct 20, 2022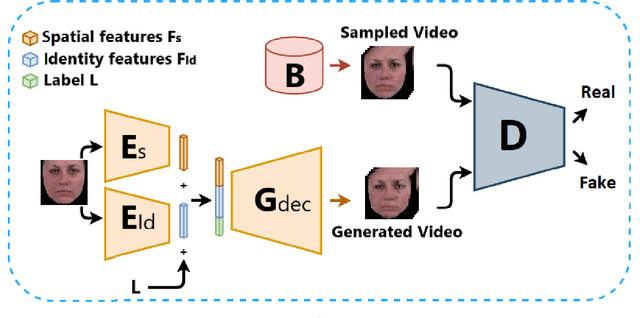
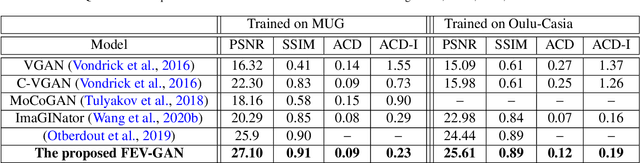

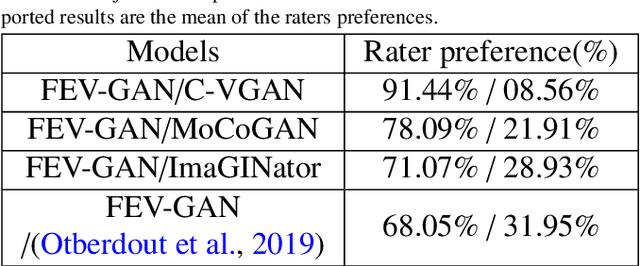
Facial expression generation has always been an intriguing task for scientists and researchers all over the globe. In this context, we present our novel approach for generating videos of the six basic facial expressions. Starting from a single neutral facial image and a label indicating the desired facial expression, we aim to synthesize a video of the given identity performing the specified facial expression. Our approach, referred to as FEV-GAN (Facial Expression Video GAN), is based on Spatio-temporal Convolutional GANs, that are known to model both content and motion in the same network. Previous methods based on such a network have shown a good ability to generate coherent videos with smooth temporal evolution. However, they still suffer from low image quality and low identity preservation capability. In this work, we address this problem by using a generator composed of two image encoders. The first one is pre-trained for facial identity feature extraction and the second for spatial feature extraction. We have qualitatively and quantitatively evaluated our model on two international facial expression benchmark databases: MUG and Oulu-CASIA NIR&VIS. The experimental results analysis demonstrates the effectiveness of our approach in generating videos of the six basic facial expressions while preserving the input identity. The analysis also proves that the use of both identity and spatial features enhances the decoder ability to better preserve the identity and generate high-quality videos. The code and the pre-trained model will soon be made publicly available.
* 13 pages, 8 figures, accepted in ISWA journal
ArtFacePoints: High-resolution Facial Landmark Detection in Paintings and Prints
Oct 17, 2022

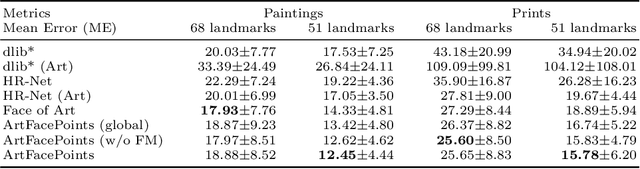
Facial landmark detection plays an important role for the similarity analysis in artworks to compare portraits of the same or similar artists. With facial landmarks, portraits of different genres, such as paintings and prints, can be automatically aligned using control-point-based image registration. We propose a deep-learning-based method for facial landmark detection in high-resolution images of paintings and prints. It divides the task into a global network for coarse landmark prediction and multiple region networks for precise landmark refinement in regions of the eyes, nose, and mouth that are automatically determined based on the predicted global landmark coordinates. We created a synthetically augmented facial landmark art dataset including artistic style transfer and geometric landmark shifts. Our method demonstrates an accurate detection of the inner facial landmarks for our high-resolution dataset of artworks while being comparable for a public low-resolution artwork dataset in comparison to competing methods.
Learning Full-Head 3D GANs from a Single-View Portrait Dataset
Jul 27, 2023



33D-aware face generators are commonly trained on 2D real-life face image datasets. Nevertheless, existing facial recognition methods often struggle to extract face data captured from various camera angles. Furthermore, in-the-wild images with diverse body poses introduce a high-dimensional challenge for 3D-aware generators, making it difficult to utilize data that contains complete neck and shoulder regions. Consequently, these face image datasets often contain only near-frontal face data, which poses challenges for 3D-aware face generators to construct \textit{full-head} 3D portraits. To this end, we first create the dataset {$\it{360}^{\circ}$}-\textit{Portrait}-\textit{HQ} (\textit{$\it{360}^{\circ}$PHQ}), which consists of high-quality single-view real portraits annotated with a variety of camera parameters {(the yaw angles span the entire $360^{\circ}$ range)} and body poses. We then propose \textit{3DPortraitGAN}, the first 3D-aware full-head portrait generator that learns a canonical 3D avatar distribution from the body-pose-various \textit{$\it{360}^{\circ}$PHQ} dataset with body pose self-learning. Our model can generate view-consistent portrait images from all camera angles (${360}^{\circ}$) with a full-head 3D representation. We incorporate a mesh-guided deformation field into volumetric rendering to produce deformed results to generate portrait images that conform to the body pose distribution of the dataset using our canonical generator. We integrate two pose predictors into our framework to predict more accurate body poses to address the issue of inaccurately estimated body poses in our dataset. Our experiments show that the proposed framework can generate view-consistent, realistic portrait images with complete geometry from all camera angles and accurately predict portrait body pose.
Face Image Quality Enhancement Study for Face Recognition
Jul 08, 2023
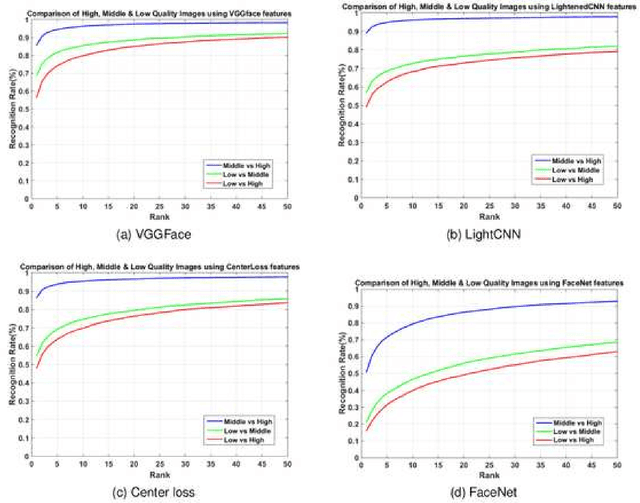
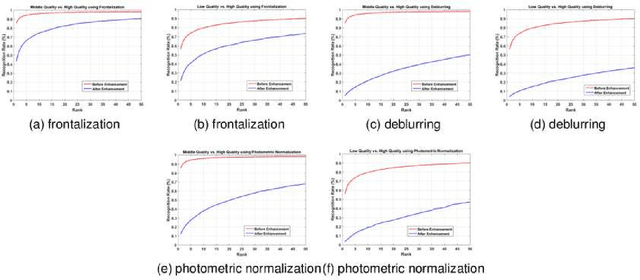
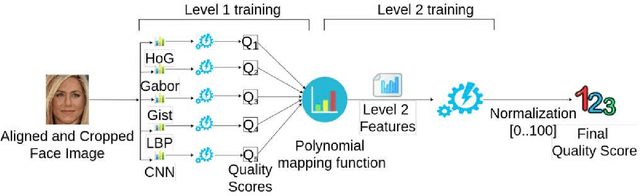
Unconstrained face recognition is an active research area among computer vision and biometric researchers for many years now. Still the problem of face recognition in low quality photos has not been well-studied so far. In this paper, we explore the face recognition performance on low quality photos, and we try to improve the accuracy in dealing with low quality face images. We assemble a large database with low quality photos, and examine the performance of face recognition algorithms for three different quality sets. Using state-of-the-art facial image enhancement approaches, we explore the face recognition performance for the enhanced face images. To perform this without experimental bias, we have developed a new protocol for recognition with low quality face photos and validate the performance experimentally. Our designed protocol for face recognition with low quality face images can be useful to other researchers. Moreover, experiment results show some of the challenging aspects of this problem.
Distributed Solution of the Inverse Rig Problem in Blendshape Facial Animation
Mar 11, 2023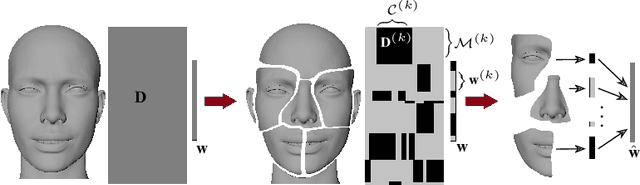
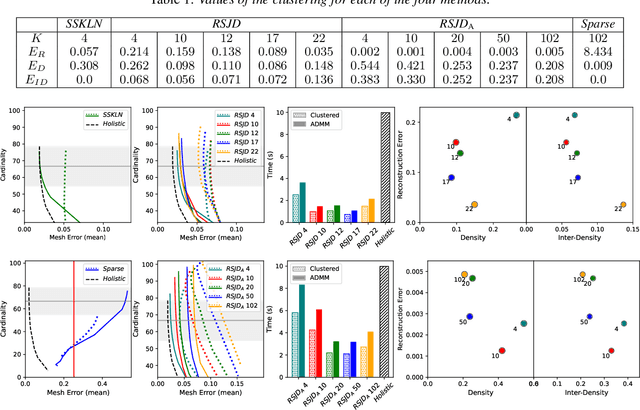

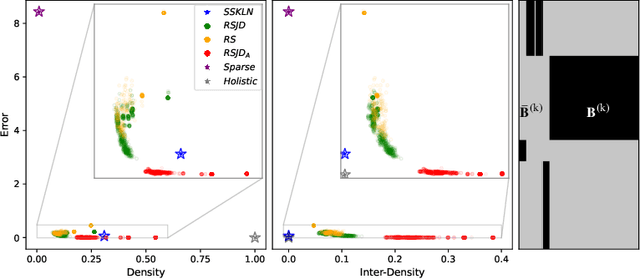
The problem of rig inversion is central in facial animation as it allows for a realistic and appealing performance of avatars. With the increasing complexity of modern blendshape models, execution times increase beyond practically feasible solutions. A possible approach towards a faster solution is clustering, which exploits the spacial nature of the face, leading to a distributed method. In this paper, we go a step further, involving cluster coupling to get more confident estimates of the overlapping components. Our algorithm applies the Alternating Direction Method of Multipliers, sharing the overlapping weights between the subproblems. The results obtained with this technique show a clear advantage over the naive clustered approach, as measured in different metrics of success and visual inspection. The method applies to an arbitrary clustering of the face. We also introduce a novel method for choosing the number of clusters in a data-free manner. The method tends to find a clustering such that the resulting clustering graph is sparse but without losing essential information. Finally, we give a new variant of a data-free clustering algorithm that produces good scores with respect to the mentioned strategy for choosing the optimal clustering.
Improving the Security of Smartwatch Payment with Deep Learning
Jul 11, 2023
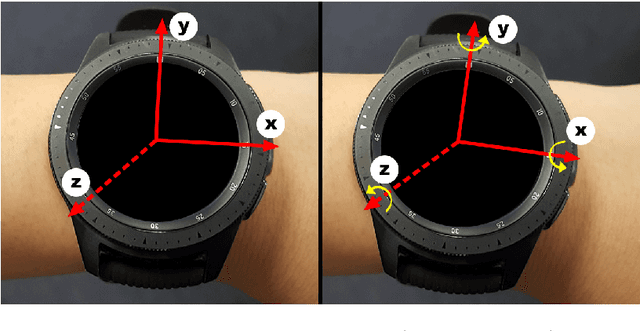

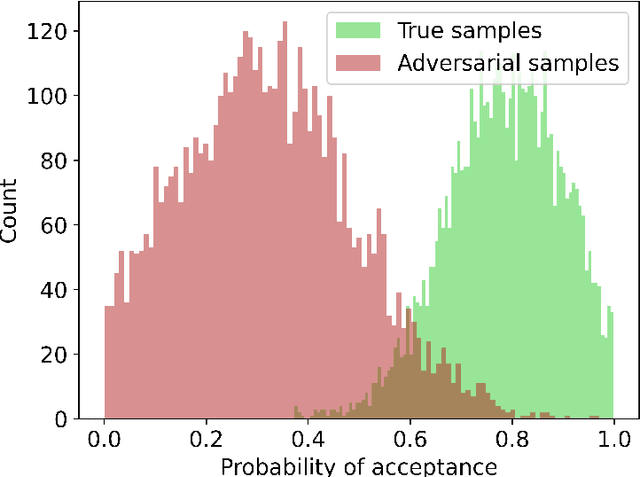
Making contactless payments using a smartwatch is increasingly popular, but this payment medium lacks traditional biometric security measures such as facial or fingerprint recognition. In 2022, Sturgess et al. proposed WatchAuth, a system for authenticating smartwatch payments using the physical gesture of reaching towards a payment terminal. While effective, the system requires the user to undergo a burdensome enrolment period to achieve acceptable error levels. In this dissertation, we explore whether applications of deep learning can reduce the number of gestures a user must provide to enrol into an authentication system for smartwatch payment. We firstly construct a deep-learned authentication system that outperforms the current state-of-the-art, including in a scenario where the target user has provided a limited number of gestures. We then develop a regularised autoencoder model for generating synthetic user-specific gestures. We show that using these gestures in training improves classification ability for an authentication system. Through this technique we can reduce the number of gestures required to enrol a user into a WatchAuth-like system without negatively impacting its error rates.
The Florence 4D Facial Expression Dataset
Oct 30, 2022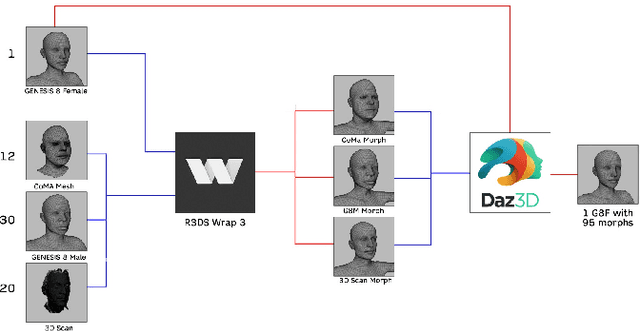
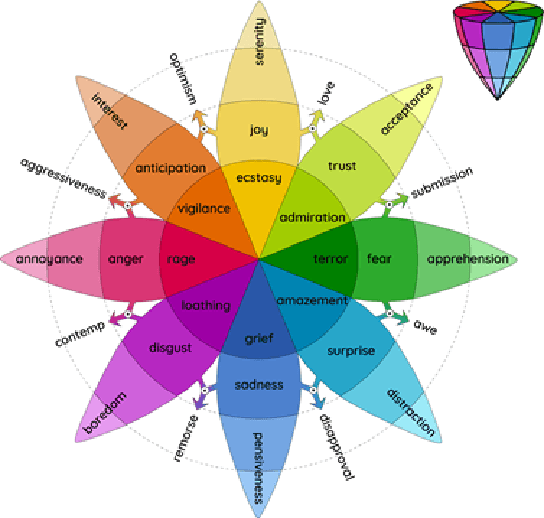
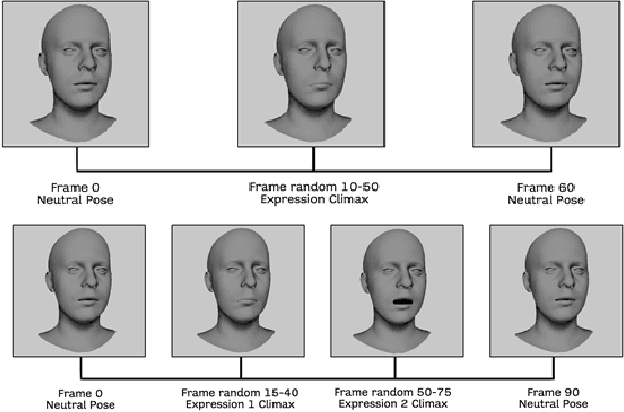

Human facial expressions change dynamically, so their recognition / analysis should be conducted by accounting for the temporal evolution of face deformations either in 2D or 3D. While abundant 2D video data do exist, this is not the case in 3D, where few 3D dynamic (4D) datasets were released for public use. The negative consequence of this scarcity of data is amplified by current deep learning based-methods for facial expression analysis that require large quantities of variegate samples to be effectively trained. With the aim of smoothing such limitations, in this paper we propose a large dataset, named Florence 4D, composed of dynamic sequences of 3D face models, where a combination of synthetic and real identities exhibit an unprecedented variety of 4D facial expressions, with variations that include the classical neutral-apex transition, but generalize to expression-to-expression. All these characteristics are not exposed by any of the existing 4D datasets and they cannot even be obtained by combining more than one dataset. We strongly believe that making such a data corpora publicly available to the community will allow designing and experimenting new applications that were not possible to investigate till now. To show at some extent the difficulty of our data in terms of different identities and varying expressions, we also report a baseline experimentation on the proposed dataset that can be used as baseline.
State of the Art of Quality Assessment of Facial Images
Nov 15, 2022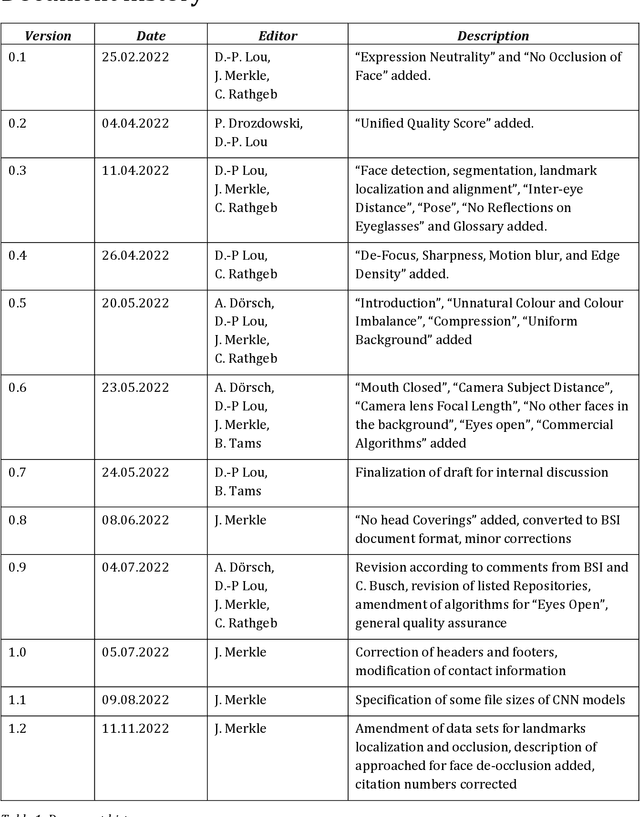

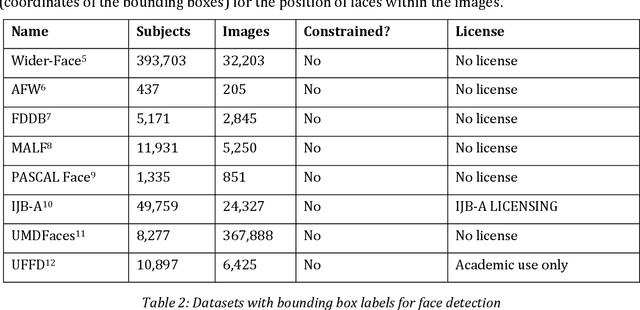

The goal of the project "Facial Metrics for EES" is to develop, implement and publish an open source algorithm for the quality assessment of facial images (OFIQ) for face recognition, in particular for border control scenarios.1 In order to stimulate the harmonization of the requirements and practices applied for QA for facial images, the insights gained and algorithms developed in the project will be contributed to the current (2022) revision of the ISO/IEC 29794-5 standard. Furthermore, the implemented quality metrics and algorithms will consider the recommendations and requirements from other relevant standards, in particular ISO/IEC 19794-5:2011, ISO/IEC 29794-5:2010, ISO/IEC 39794-5:2019 and Version 5.2 of the BSI Technical Guideline TR-03121 Part 3 Volume 1. In order to establish an informed basis for the selection of quality metrics and the development of corresponding quality assessment algorithms, the state of the art of methods and algorithms (defining a metric), implementations and datasets for quality assessment for facial images is surveyed. For all relevant quality aspects, this document summarizes the requirements of the aforementioned standards, known results on their impact on face recognition performance, publicly available datasets, proposed methods and algorithms and open source software implementations.
Discriminative Deep Feature Visualization for Explainable Face Recognition
Jun 01, 2023

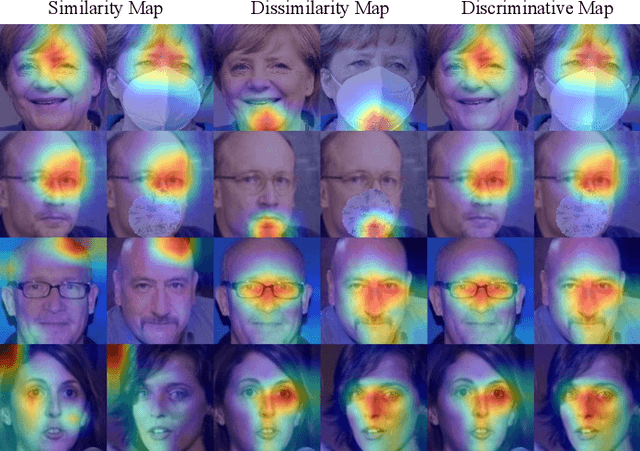
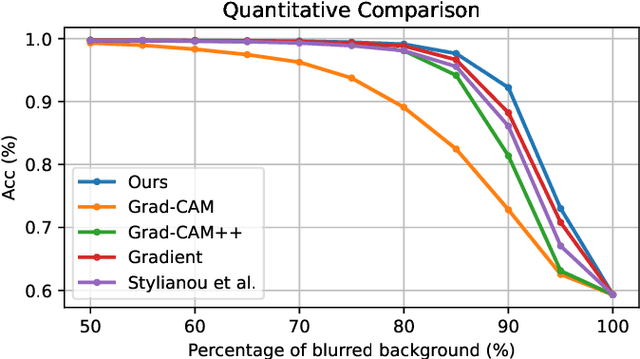
Despite the huge success of deep convolutional neural networks in face recognition (FR) tasks, current methods lack explainability for their predictions because of their "black-box" nature. In recent years, studies have been carried out to give an interpretation of the decision of a deep FR system. However, the affinity between the input facial image and the extracted deep features has not been explored. This paper contributes to the problem of explainable face recognition by first conceiving a face reconstruction-based explanation module, which reveals the correspondence between the deep feature and the facial regions. To further interpret the decision of an FR model, a novel visual saliency explanation algorithm has been proposed. It provides insightful explanation by producing visual saliency maps that represent similar and dissimilar regions between input faces. A detailed analysis has been presented for the generated visual explanation to show the effectiveness of the proposed method.