 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Descriptors for Human Interaction Recognition In Still Images
Sep 17, 2015

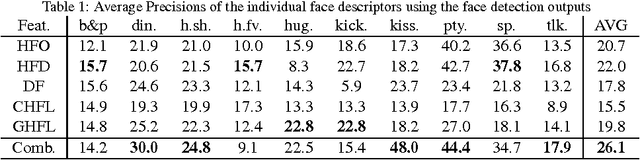
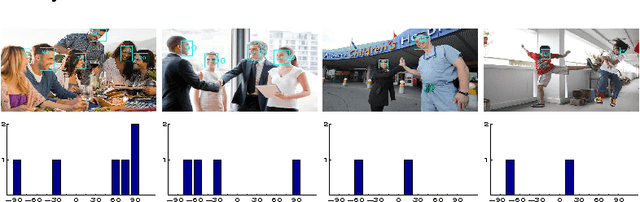
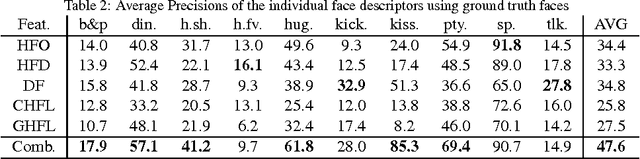
This paper presents a novel approach in a rarely studied area of computer vision: Human interaction recognition in still images. We explore whether the facial regions and their spatial configurations contribute to the recognition of interactions. In this respect, our method involves extraction of several visual features from the facial regions, as well as incorporation of scene characteristics and deep features to the recognition. Extracted multiple features are utilized within a discriminative learning framework for recognizing interactions between people. Our designed facial descriptors are based on the observation that relative positions, size and locations of the faces are likely to be important for characterizing human interactions. Since there is no available dataset in this relatively new domain, a comprehensive new dataset which includes several images of human interactions is collected. Our experimental results show that faces and scene characteristics contain important information to recognize interactions between people.
Objective Micro-Facial Movement Detection Using FACS-Based Regions and Baseline Evaluation
Dec 15, 2016

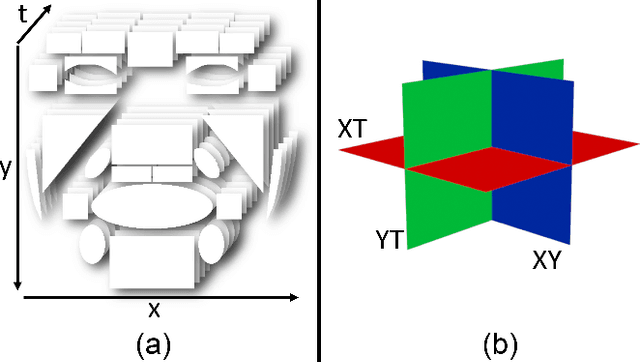
Micro-facial expressions are regarded as an important human behavioural event that can highlight emotional deception. Spotting these movements is difficult for humans and machines, however research into using computer vision to detect subtle facial expressions is growing in popularity. This paper proposes an individualised baseline micro-movement detection method using 3D Histogram of Oriented Gradients (3D HOG) temporal difference method. We define a face template consisting of 26 regions based on the Facial Action Coding System (FACS). We extract the temporal features of each region using 3D HOG. Then, we use Chi-square distance to find subtle facial motion in the local regions. Finally, an automatic peak detector is used to detect micro-movements above the newly proposed adaptive baseline threshold. The performance is validated on two FACS coded datasets: SAMM and CASME II. This objective method focuses on the movement of the 26 face regions. When comparing with the ground truth, the best result was an AUC of 0.7512 and 0.7261 on SAMM and CASME II, respectively. The results show that 3D HOG outperformed for micro-movement detection, compared to state-of-the-art feature representations: Local Binary Patterns in Three Orthogonal Planes and Histograms of Oriented Optical Flow.
Pose Guided Image Generation from Misaligned Sources via Residual Flow Based Correction
Feb 02, 2022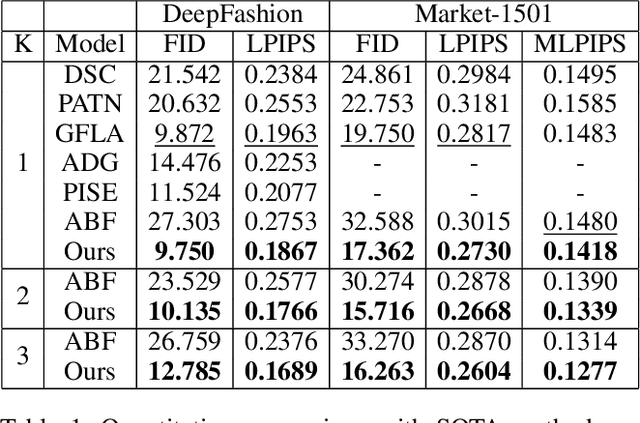
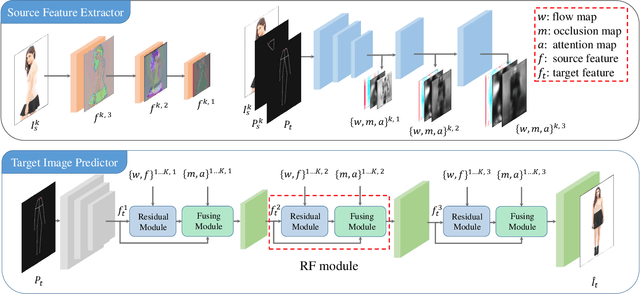
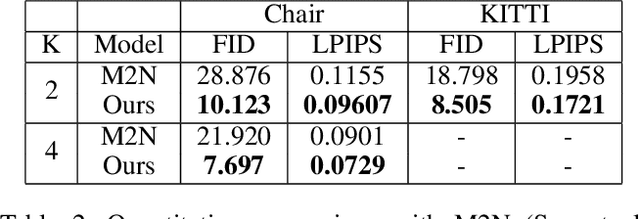
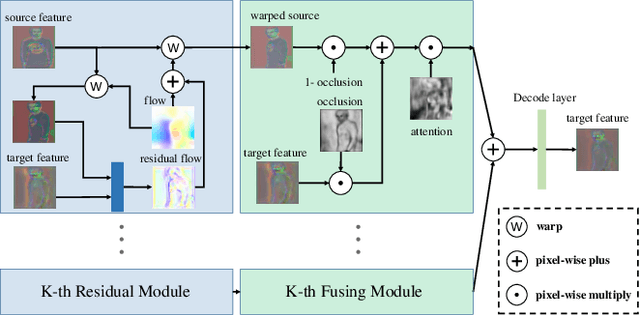
Generating new images with desired properties (e.g. new view/poses) from source images has been enthusiastically pursued recently, due to its wide range of potential applications. One way to ensure high-quality generation is to use multiple sources with complementary information such as different views of the same object. However, as source images are often misaligned due to the large disparities among the camera settings, strong assumptions have been made in the past with respect to the camera(s) or/and the object in interest, limiting the application of such techniques. Therefore, we propose a new general approach which models multiple types of variations among sources, such as view angles, poses, facial expressions, in a unified framework, so that it can be employed on datasets of vastly different nature. We verify our approach on a variety of data including humans bodies, faces, city scenes and 3D objects. Both the qualitative and quantitative results demonstrate the better performance of our method than the state of the art.
A Real Time Facial Expression Classification System Using Local Binary Patterns
May 15, 2015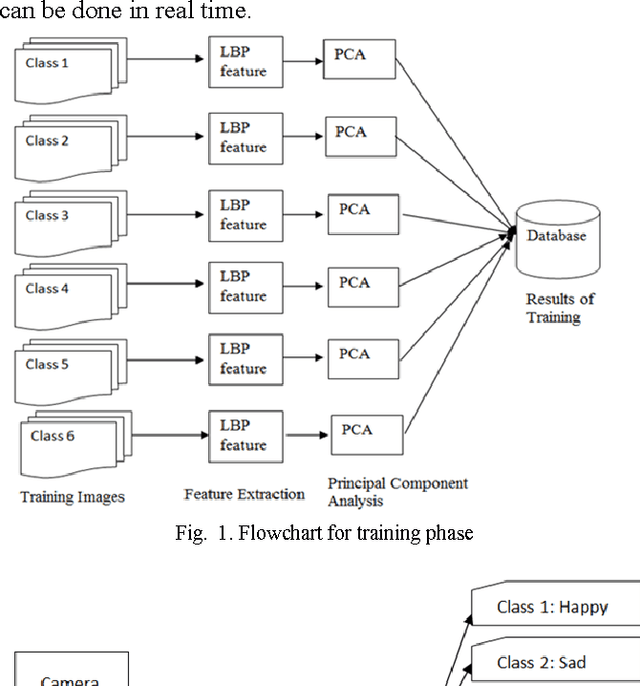
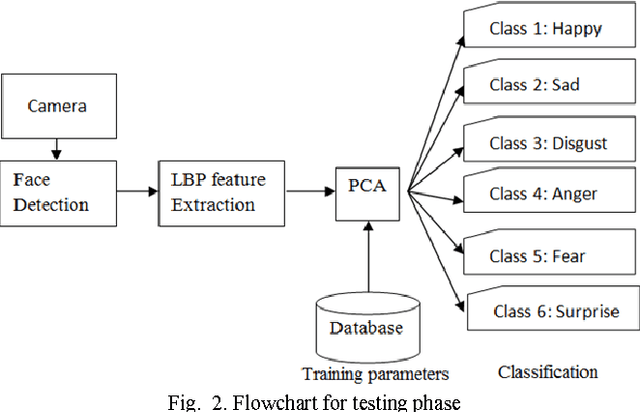
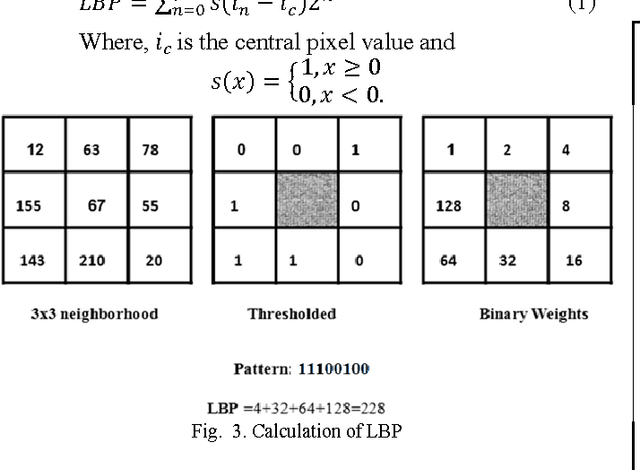

Facial expression analysis is one of the popular fields of research in human computer interaction (HCI). It has several applications in next generation user interfaces, human emotion analysis, behavior and cognitive modeling. In this paper, a facial expression classification algorithm is proposed which uses Haar classifier for face detection purpose, Local Binary Patterns (LBP) histogram of different block sizes of a face image as feature vectors and classifies various facial expressions using Principal Component Analysis (PCA). The algorithm is implemented in real time for expression classification since the computational complexity of the algorithm is small. A customizable approach is proposed for facial expression analysis, since the various expressions and intensity of expressions vary from person to person. The system uses grayscale frontal face images of a person to classify six basic emotions namely happiness, sadness, disgust, fear, surprise and anger.
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Oct 23, 2018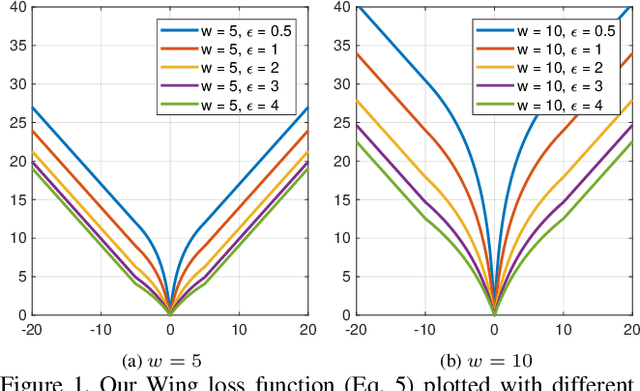
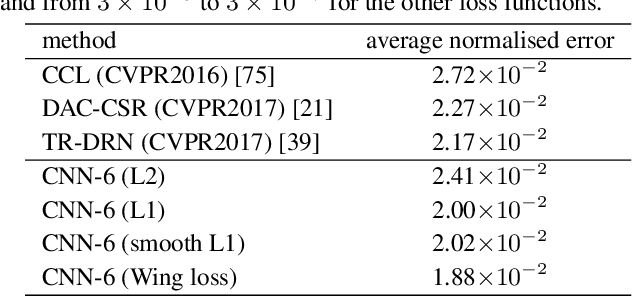
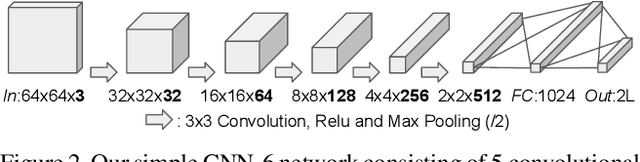
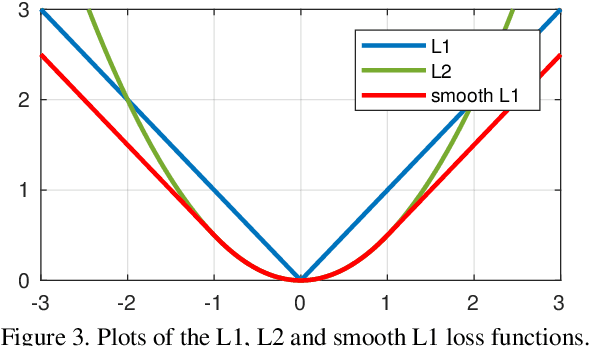
We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
EAC-Net: A Region-based Deep Enhancing and Cropping Approach for Facial Action Unit Detection
Feb 09, 2017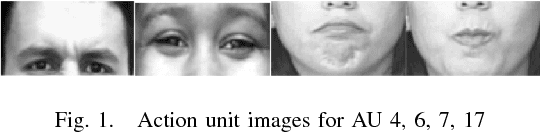
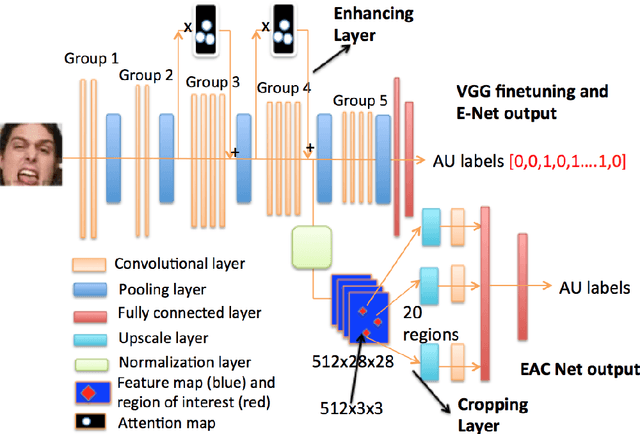
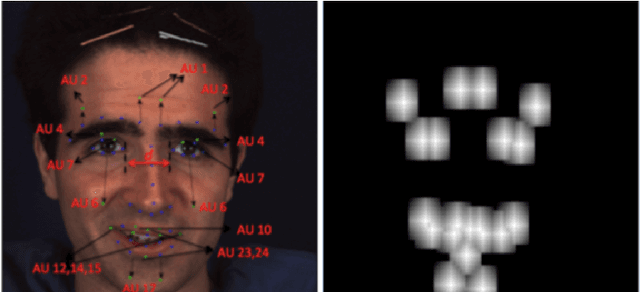
In this paper, we propose a deep learning based approach for facial action unit detection by enhancing and cropping the regions of interest. The approach is implemented by adding two novel nets (layers): the enhancing layers and the cropping layers, to a pretrained CNN model. For the enhancing layers, we designed an attention map based on facial landmark features and applied it to a pretrained neural network to conduct enhanced learning (The E-Net). For the cropping layers, we crop facial regions around the detected landmarks and design convolutional layers to learn deeper features for each facial region (C-Net). We then fuse the E-Net and the C-Net to obtain our Enhancing and Cropping (EAC) Net, which can learn both feature enhancing and region cropping functions. Our approach shows significant improvement in performance compared to the state-of-the-art methods applied to BP4D and DISFA AU datasets.
GoDP: Globally optimized dual pathway system for facial landmark localization in-the-wild
Dec 19, 2017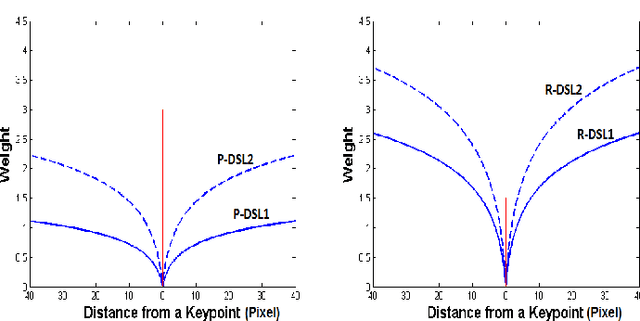

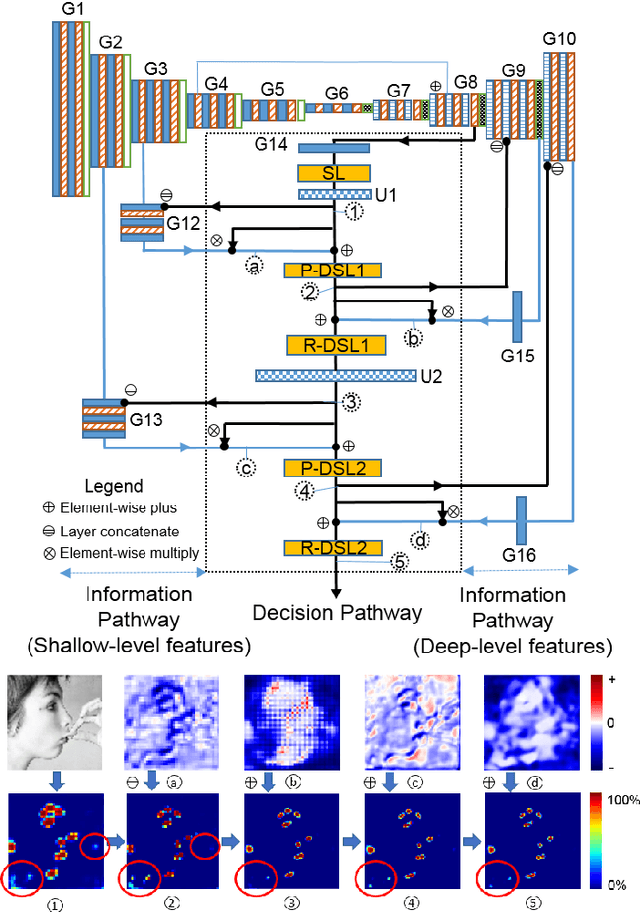
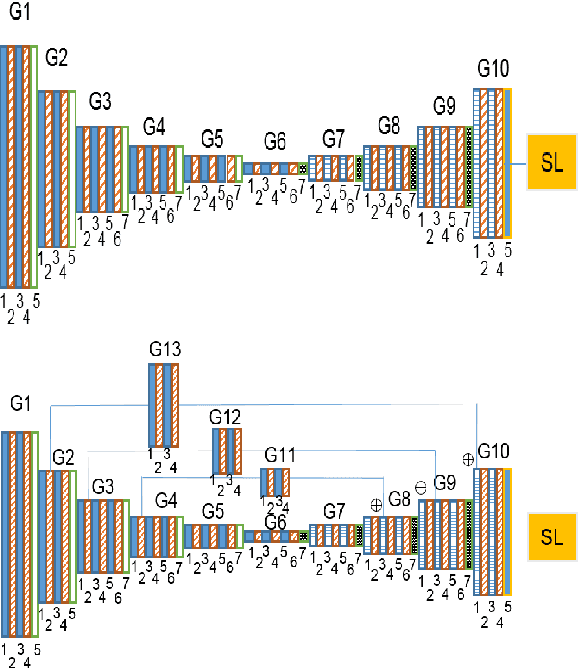
Facial landmark localization is a fundamental module for pose-invariant face recognition. The most common approach for facial landmark detection is cascaded regression, which is composed of two steps: feature extraction and facial shape regression. Recent methods employ deep convolutional networks to extract robust features for each step, while the whole system could be regarded as a deep cascaded regression architecture. In this work, instead of employing a deep regression network, a Globally Optimized Dual-Pathway (GoDP) deep architecture is proposed to identify the target pixels through solving a cascaded pixel labeling problem without resorting to high-level inference models or complex stacked architecture. The proposed end-to-end system relies on distance-aware softmax functions and dual-pathway proposal-refinement architecture. Results show that it outperforms the state-of-the-art cascaded regression-based methods on multiple in-the-wild face alignment databases. The model achieves 1.84 normalized mean error (NME) on the AFLW database, which outperforms 3DDFA by 61.8%. Experiments on face identification demonstrate that GoDP, coupled with DPM-headhunter, is able to improve rank-1 identification rate by 44.2% compared to Dlib toolbox on a challenging database.
* Accepted by Image and Vision Computing in December, 2017
End-to-End Speech-Driven Facial Animation with Temporal GANs
Jul 19, 2018

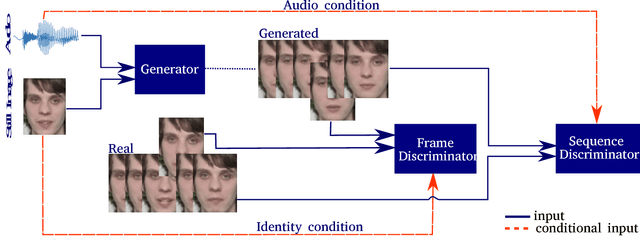

Speech-driven facial animation is the process which uses speech signals to automatically synthesize a talking character. The majority of work in this domain creates a mapping from audio features to visual features. This often requires post-processing using computer graphics techniques to produce realistic albeit subject dependent results. We present a system for generating videos of a talking head, using a still image of a person and an audio clip containing speech, that doesn't rely on any handcrafted intermediate features. To the best of our knowledge, this is the first method capable of generating subject independent realistic videos directly from raw audio. Our method can generate videos which have (a) lip movements that are in sync with the audio and (b) natural facial expressions such as blinks and eyebrow movements. We achieve this by using a temporal GAN with 2 discriminators, which are capable of capturing different aspects of the video. The effect of each component in our system is quantified through an ablation study. The generated videos are evaluated based on their sharpness, reconstruction quality, and lip-reading accuracy. Finally, a user study is conducted, confirming that temporal GANs lead to more natural sequences than a static GAN-based approach.
AI in Pursuit of Happiness, Finding Only Sadness: Multi-Modal Facial Emotion Recognition Challenge
Oct 24, 2019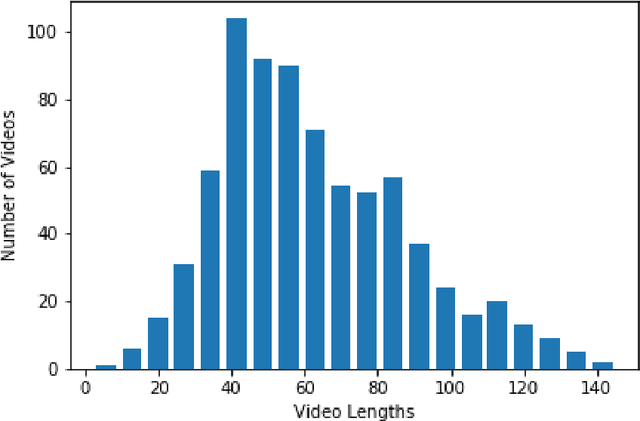
The importance of automated Facial Emotion Recognition (FER) grows the more common human-machine interactions become, which will only continue to increase dramatically with time. A common method to describe human sentiment or feeling is the categorical model the `7 basic emotions', consisting of `Angry', `Disgust', `Fear', `Happiness', `Sadness', `Surprise' and `Neutral'. The `Emotion Recognition in the Wild' (EmotiW) competition is now in its 7th year and has become the standard benchmark for measuring FER performance. The focus of this paper is the EmotiW sub-challenge of classifying videos in the `Acted Facial Expression in the Wild' (AFEW) dataset, consisting of both visual and audio modalities, into one of the above classes. Machine learning has exploded as a research topic in recent years, with advancements in `Deep Learning' a key part of this. Although Deep Learning techniques have been widely applied to the FER task by entrants in previous years, this paper has two main contributions: (i) to apply the latest `state-of-the-art' visual and temporal networks and (ii) exploring various methods of fusing features extracted from the visual and audio elements to enrich the information available to the final model making the prediction. There are a number of complex issues that arise when trying to classify emotions for `in-the-wild' video sequences, which the above two approaches attempt to directly address. There are some positive findings when comparing the results of this paper to past submissions, indicating that further research into the proposed methods and fine-tuning of the models deployed, could result in another step forwards in the field of automated FER.
Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?
Mar 16, 2017
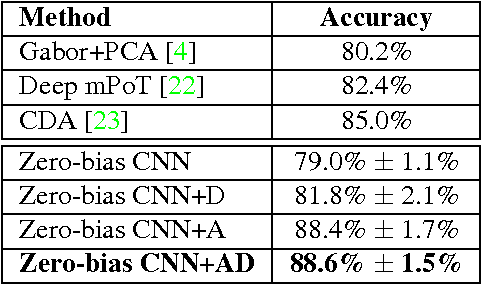
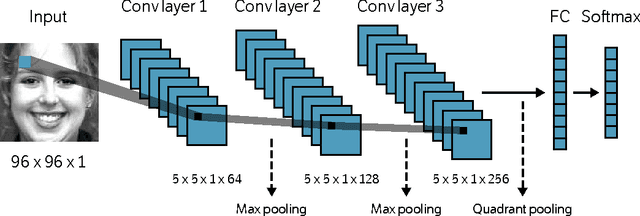
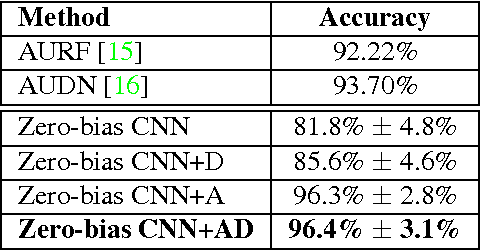
Despite being the appearance-based classifier of choice in recent years, relatively few works have examined how much convolutional neural networks (CNNs) can improve performance on accepted expression recognition benchmarks and, more importantly, examine what it is they actually learn. In this work, not only do we show that CNNs can achieve strong performance, but we also introduce an approach to decipher which portions of the face influence the CNN's predictions. First, we train a zero-bias CNN on facial expression data and achieve, to our knowledge, state-of-the-art performance on two expression recognition benchmarks: the extended Cohn-Kanade (CK+) dataset and the Toronto Face Dataset (TFD). We then qualitatively analyze the network by visualizing the spatial patterns that maximally excite different neurons in the convolutional layers and show how they resemble Facial Action Units (FAUs). Finally, we use the FAU labels provided in the CK+ dataset to verify that the FAUs observed in our filter visualizations indeed align with the subject's facial movements.