 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Semi-supervised Facial Action Unit Intensity Estimation with Contrastive Learning
Nov 04, 2020
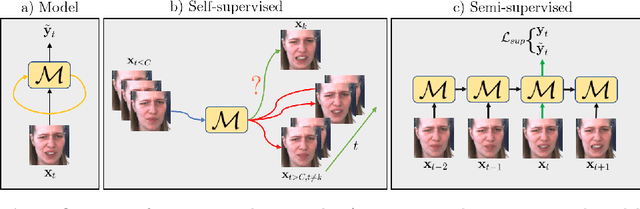
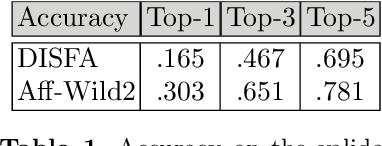
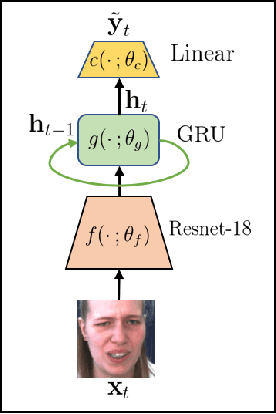
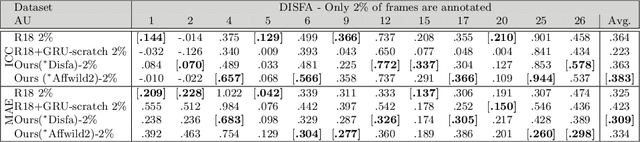
This paper tackles the challenging problem of estimating the intensity of Facial Action Units with few labeled images. Contrary to previous works, our method does not require to manually select key frames, and produces state-of-the-art results with as little as $2\%$ of annotated frames, which are \textit{randomly chosen}. To this end, we propose a semi-supervised learning approach where a spatio-temporal model combining a feature extractor and a temporal module are learned in two stages. The first stage uses datasets of unlabeled videos to learn a strong spatio-temporal representation of facial behavior dynamics based on contrastive learning. To our knowledge we are the first to build upon this framework for modeling facial behavior in an unsupervised manner. The second stage uses another dataset of randomly chosen labeled frames to train a regressor on top of our spatio-temporal model for estimating the AU intensity. We show that although backpropagation through time is applied only with respect to the output of the network for extremely sparse and randomly chosen labeled frames, our model can be effectively trained to estimate AU intensity accurately, thanks to the unsupervised pre-training of the first stage. We experimentally validate that our method outperforms existing methods when working with as little as $2\%$ of randomly chosen data for both DISFA and BP4D datasets, without a careful choice of labeled frames, a time-consuming task still required in previous approaches.
Emotion pattern detection on facial videos using functional statistics
Mar 01, 2021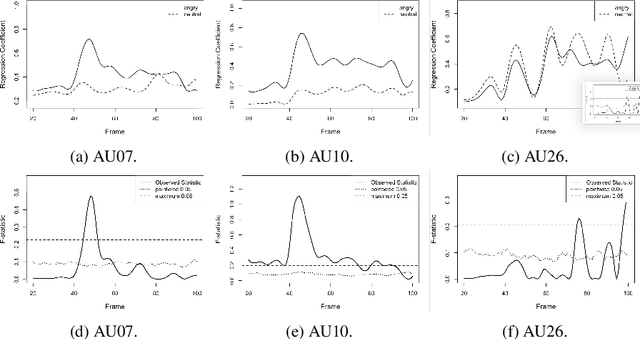
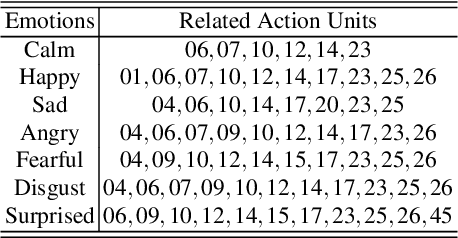
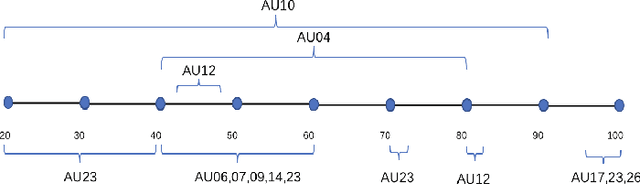
There is an increasing scientific interest in automatically analysing and understanding human behavior, with particular reference to the evolution of facial expressions and the recognition of the corresponding emotions. In this paper we propose a technique based on Functional ANOVA to extract significant patterns of face muscles movements, in order to identify the emotions expressed by actors in recorded videos. We determine if there are time-related differences on expressions among emotional groups by using a functional F-test. Such results are the first step towards the construction of a reliable automatic emotion recognition system
Training of SSD(Single Shot Detector) for Facial Detection using Nvidia Jetson Nano
May 28, 2021


In this project, we have used the computer vision algorithm SSD (Single Shot detector) computer vision algorithm and trained this algorithm from the dataset which consists of 139 Pictures. Images were labeled using Intel CVAT (Computer Vision Annotation Tool) We trained this model for facial detection. We have deployed our trained model and software in the Nvidia Jetson Nano Developer kit. Model code is written in Pytorch's deep learning framework. The programming language used is Python.
Recovering Facial Reflectance and Geometry from Multi-view Images
Nov 27, 2019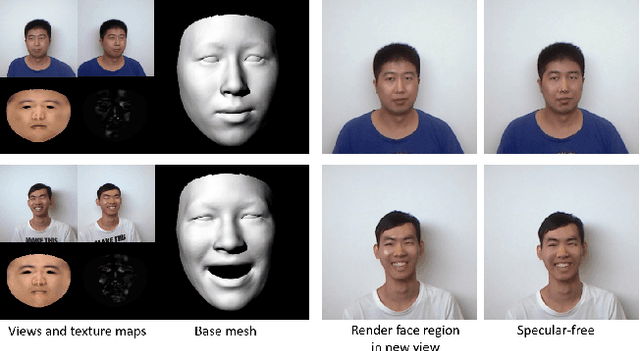

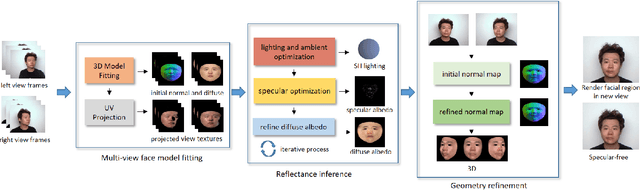
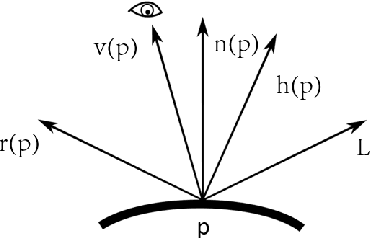
While the problem of estimating shapes and diffuse reflectances of human faces from images has been extensively studied, there is relatively less work done on recovering the specular albedo. This paper presents a lightweight solution for inferring photorealistic facial reflectance and geometry. Our system processes video streams from two views of a subject, and outputs two reflectance maps for diffuse and specular albedos, as well as a vector map of surface normals. A model-based optimization approach is used, consisting of the three stages of multi-view face model fitting, facial reflectance inference and facial geometry refinement. Our approach is based on a novel formulation built upon the 3D morphable model (3DMM) for representing 3D textured faces in conjunction with the Blinn-Phong reflection model. It has the advantage of requiring only a simple setup with two video streams, and is able to exploit the interaction between the diffuse and specular reflections across multiple views as well as time frames. As a result, the method is able to reliably recover high-fidelity facial reflectance and geometry, which facilitates various applications such as generating photorealistic facial images under new viewpoints or illumination conditions.
Facial Expression Recognition Using Human to Animated-Character Expression Translation
Oct 12, 2019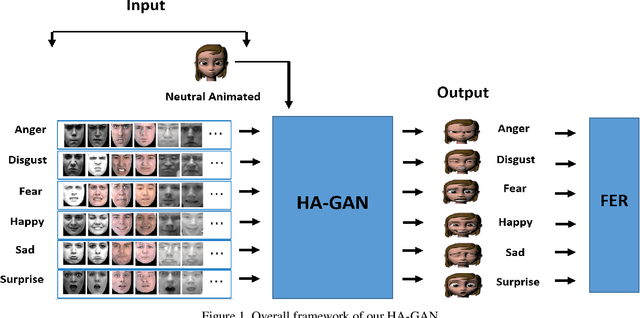
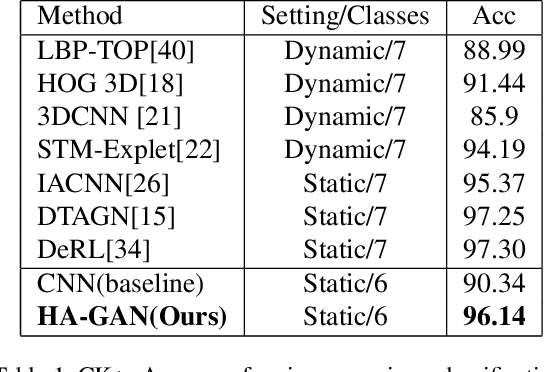
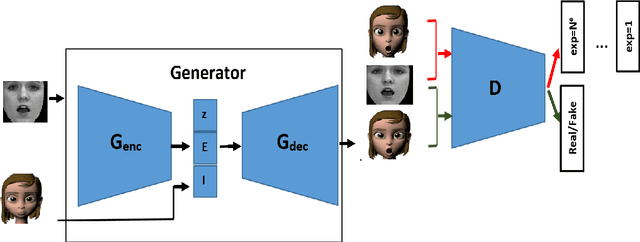
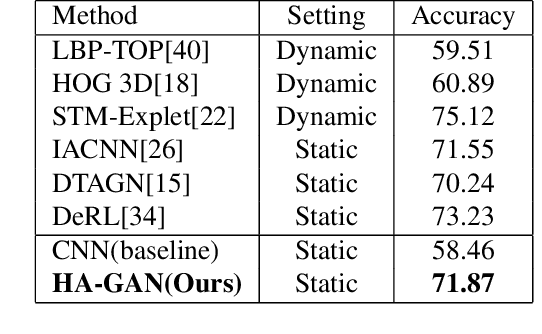
Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.
An Open-source Benchmark of Deep Learning Models for Audio-visual Apparent and Self-reported Personality Recognition
Oct 17, 2022
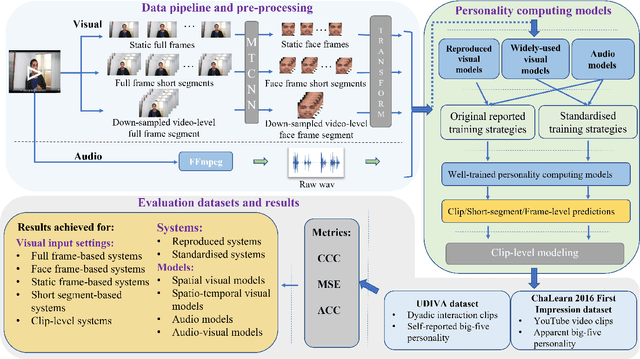
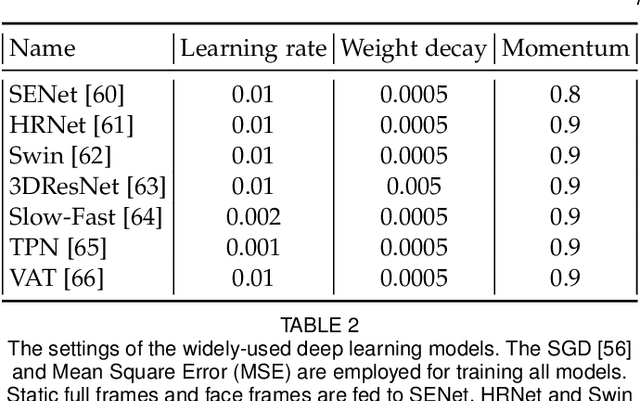
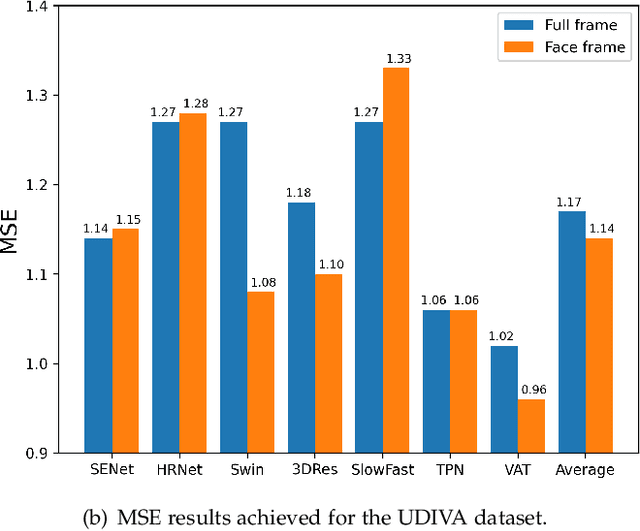
Personality is crucial for understanding human internal and external states. The majority of existing personality computing approaches suffer from complex and dataset-specific pre-processing steps and model training tricks. In the absence of a standardized benchmark with consistent experimental settings, it is not only impossible to fairly compare the real performances of these personality computing models but also makes them difficult to be reproduced. In this paper, we present the first reproducible audio-visual benchmarking framework to provide a fair and consistent evaluation of eight existing personality computing models (e.g., audio, visual and audio-visual) and seven standard deep learning models on both self-reported and apparent personality recognition tasks. We conduct a comprehensive investigation into all the benchmarked models to demonstrate their capabilities in modelling personality traits on two publicly available datasets, audio-visual apparent personality (ChaLearn First Impression) and self-reported personality (UDIVA) datasets. The experimental results conclude: (i) apparent personality traits, inferred from facial behaviours by most benchmarked deep learning models, show more reliability than self-reported ones; (ii) visual models frequently achieved superior performances than audio models on personality recognition; and (iii) non-verbal behaviours contribute differently in predicting different personality traits. We make the code publicly available at https://github.com/liaorongfan/DeepPersonality .
Toward an Automatic System for Computer-Aided Assessment in Facial Palsy
Oct 25, 2019
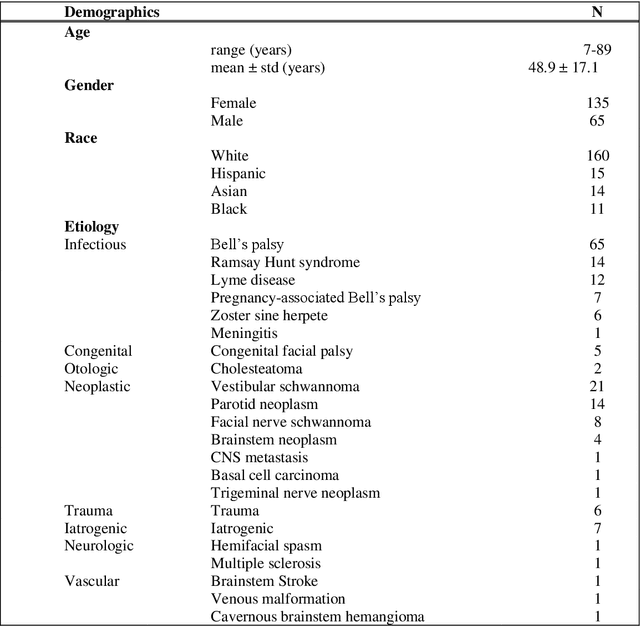
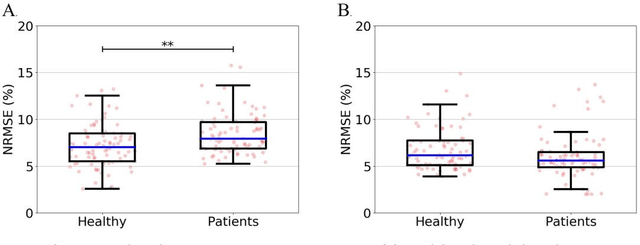
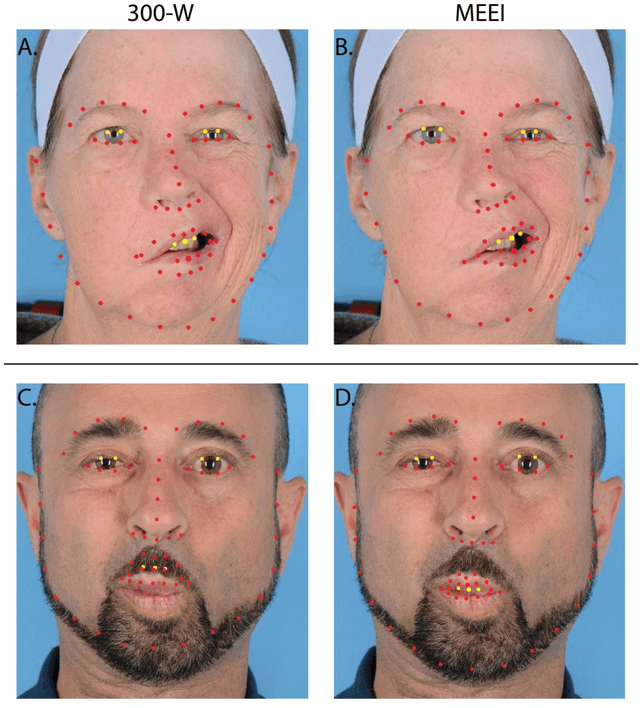
Importance: Machine learning (ML) approaches to facial landmark localization carry great clinical potential for quantitative assessment of facial function as they enable high-throughput automated quantification of relevant facial metrics from photographs. However, translation from research settings to clinical applications requires important improvements. Objective: To develop an ML algorithm for accurate facial landmarks localization in photographs of facial palsy patients, and use it as part of an automated computer-aided diagnosis system. Design, Setting, and Participants: Facial landmarks were manually localized in portrait photographs of eight expressions obtained from 200 facial palsy patients and 10 controls. A novel ML model for automated facial landmark localization was trained using this disease-specific database. Model output was compared to manual annotations and the output of a model trained using a larger database consisting only of healthy subjects. Model accuracy was evaluated by the normalized root mean square error (NRMSE) between algorithms' prediction and manual annotations. Results: Publicly available algorithms provide poor results when applied to patients compared to healthy controls (NRMSE, 8.56 +/- 2.16 vs. 7.09 +/- 2.34, p << 0.01). We found significant improvement in facial landmark localization accuracy for the clinical population when using a model trained with a relatively small number patients' photographs (1440) compared to a model trained using several thousand more images of healthy faces (NRMSE, 6.03 +/- 2.43 vs. 8.56 +/- 2.16, p << 0.01). Conclusions: Retraining a landmark detection model with a small number of clinical images significantly improved landmark detection performance in frontal view photographs of the clinical population. These results represent the first steps towards an automatic system for computer-aided assessment in facial palsy.
Facial Action Unit Detection on ICU Data for Pain Assessment
Apr 24, 2020Current day pain assessment methods rely on patient self-report or by an observer like the Intensive Care Unit (ICU) nurses. Patient self-report is subjective to the individual and suffers due to poor recall. Pain assessment by manual observation is limited by the number of administrations per day and staff workload. Previous studies showed the feasibility of automatic pain assessment by detecting Facial Action Units (AUs). Pain is observed to be associated with certain facial action units (AUs). This method of pain assessment can overcome the pitfalls of present-day pain assessment techniques. All the previous studies are limited to controlled environment data. In this study, we evaluated the performance of OpenFace an open-source facial behavior analysis tool and AU R-CNN on the real-world ICU data. Presence of assisted breathing devices, variable lighting of ICUs, patient orientation with respect to camera significantly affected the performance of the models, although these showed the state-of-the-art results in facial behavior analysis tasks. In this study, we show the need for automated pain assessment system which is trained on real-world ICU data for clinically acceptable pain assessment system.
Real-time Facial Expression Recognition "In The Wild'' by Disentangling 3D Expression from Identity
May 12, 2020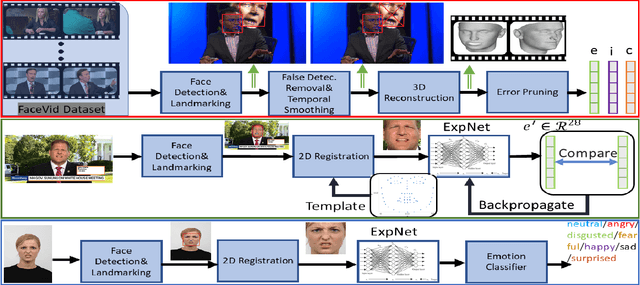
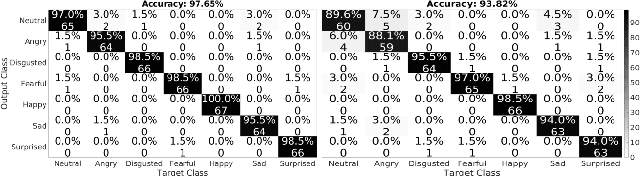

Human emotions analysis has been the focus of many studies, especially in the field of Affective Computing, and is important for many applications, e.g. human-computer intelligent interaction, stress analysis, interactive games, animations, etc. Solutions for automatic emotion analysis have also benefited from the development of deep learning approaches and the availability of vast amount of visual facial data on the internet. This paper proposes a novel method for human emotion recognition from a single RGB image. We construct a large-scale dataset of facial videos (\textbf{FaceVid}), rich in facial dynamics, identities, expressions, appearance and 3D pose variations. We use this dataset to train a deep Convolutional Neural Network for estimating expression parameters of a 3D Morphable Model and combine it with an effective back-end emotion classifier. Our proposed framework runs at 50 frames per second and is capable of robustly estimating parameters of 3D expression variation and accurately recognizing facial expressions from in-the-wild images. We present extensive experimental evaluation that shows that the proposed method outperforms the compared techniques in estimating the 3D expression parameters and achieves state-of-the-art performance in recognising the basic emotions from facial images, as well as recognising stress from facial videos. %compared to the current state of the art in emotion recognition from facial images.
Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation
May 08, 2022Virtual facial avatars will play an increasingly important role in immersive communication, games and the metaverse, and it is therefore critical that they be inclusive. This requires accurate recovery of the appearance, represented by albedo, regardless of age, sex, or ethnicity. While significant progress has been made on estimating 3D facial geometry, albedo estimation has received less attention. The task is fundamentally ambiguous because the observed color is a function of albedo and lighting, both of which are unknown. We find that current methods are biased towards light skin tones due to (1) strongly biased priors that prefer lighter pigmentation and (2) algorithmic solutions that disregard the light/albedo ambiguity. To address this, we propose a new evaluation dataset (FAIR) and an algorithm (TRUST) to improve albedo estimation and, hence, fairness. Specifically, we create the first facial albedo evaluation benchmark where subjects are balanced in terms of skin color, and measure accuracy using the Individual Typology Angle (ITA) metric. We then address the light/albedo ambiguity by building on a key observation: the image of the full scene -- as opposed to a cropped image of the face -- contains important information about lighting that can be used for disambiguation. TRUST regresses facial albedo by conditioning both on the face region and a global illumination signal obtained from the scene image. Our experimental results show significant improvement compared to state-of-the-art methods on albedo estimation, both in terms of accuracy and fairness. The evaluation benchmark and code will be made available for research purposes at https://trust.is.tue.mpg.de.