 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Full-Body Cardiovascular Sensing with Remote Photoplethysmography
Mar 16, 2023
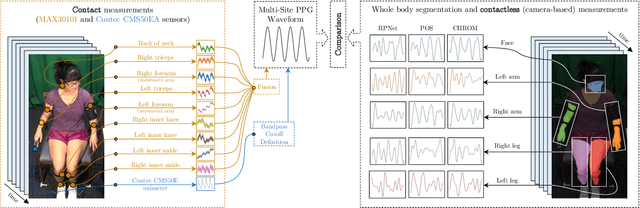


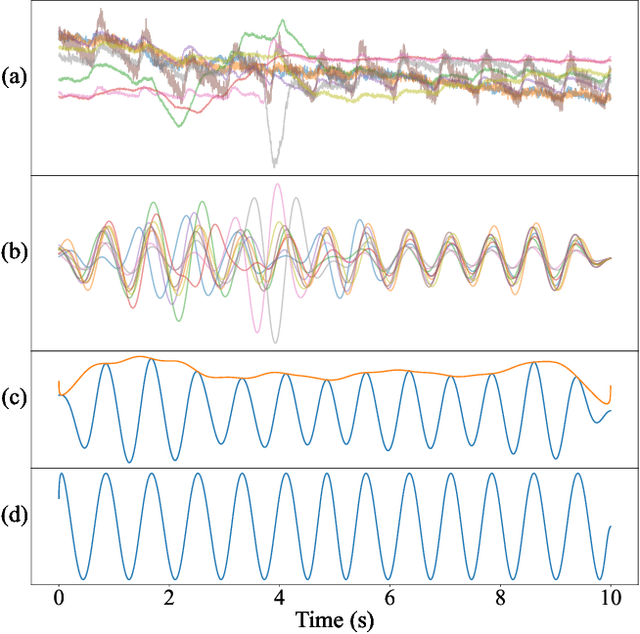
Remote photoplethysmography (rPPG) allows for noncontact monitoring of blood volume changes from a camera by detecting minor fluctuations in reflected light. Prior applications of rPPG focused on face videos. In this paper we explored the feasibility of rPPG from non-face body regions such as the arms, legs, and hands. We collected a new dataset titled Multi-Site Physiological Monitoring (MSPM), which will be released with this paper. The dataset consists of 90 frames per second video of exposed arms, legs, and face, along with 10 synchronized PPG recordings. We performed baseline heart rate estimation experiments from non-face regions with several state-of-the-art rPPG approaches, including chrominance-based (CHROM), plane-orthogonal-to-skin (POS) and RemotePulseNet (RPNet). To our knowledge, this is the first evaluation of the fidelity of rPPG signals simultaneously obtained from multiple regions of a human body. Our experiments showed that skin pixels from arms, legs, and hands are all potential sources of the blood volume pulse. The best-performing approach, POS, achieved a mean absolute error peaking at 7.11 beats per minute from non-facial body parts compared to 1.38 beats per minute from the face. Additionally, we performed experiments on pulse transit time (PTT) from both the contact PPG and rPPG signals. We found that remote PTT is possible with moderately high frame rate video when distal locations on the body are visible. These findings and the supporting dataset should facilitate new research on non-face rPPG and monitoring blood flow dynamics over the whole body with a camera.
FaceAtlasAR: Atlas of Facial Acupuncture Points in Augmented Reality
Nov 29, 2021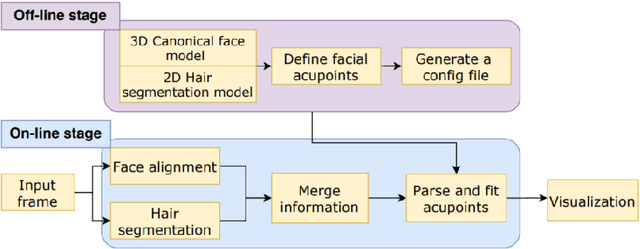
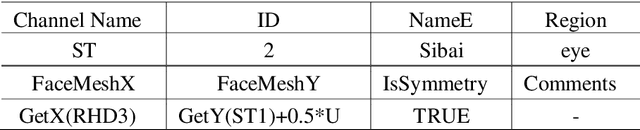
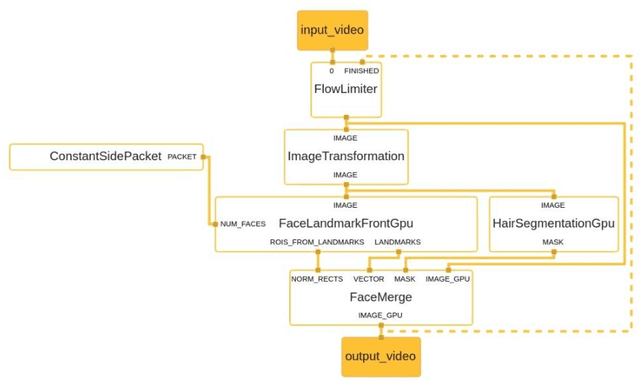

Acupuncture is a technique in which practitioners stimulate specific points on the body. These points, called acupuncture points (or acupoints), anatomically define areas on the skin relative to some landmarks on the body. Traditional acupuncture treatment relies on experienced acupuncturists for precise positioning of acupoints. A novice typically finds it difficult because of the lack of visual cues. This project presents FaceAtlasAR, a prototype system that localizes and visualizes facial acupoints in an augmented reality (AR) context. The system aims to 1) localize facial acupoints and auricular zone map in an anatomical yet feasible way, 2) overlay the requested acupoints by category in AR, and 3) show auricular zone map on the ears. We adopt Mediapipe, a cross-platform machine learning framework, to build the pipeline that runs on desktop and Android phones. We perform experiments on different benchmarks, including "In-the-wild", AMI ear datasets, and our own annotated datasets. Results show the localization accuracy of 95% for facial acupoints, 99% / 97% ("In-the-wild" / AMI) for auricular zone map, and high robustness. With this system, users, even not professionals, can position the acupoints quickly for their self-acupressure treatments.
DeepFake MNIST+: A DeepFake Facial Animation Dataset
Aug 18, 2021
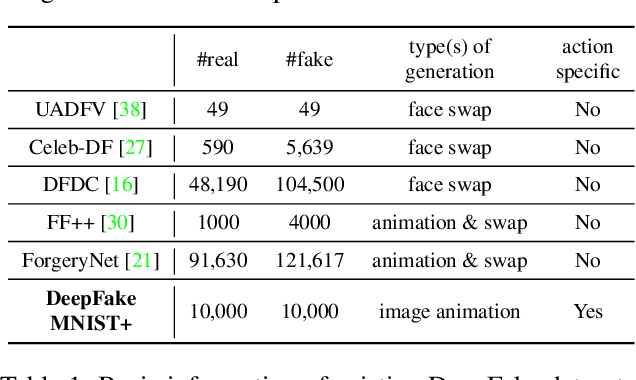
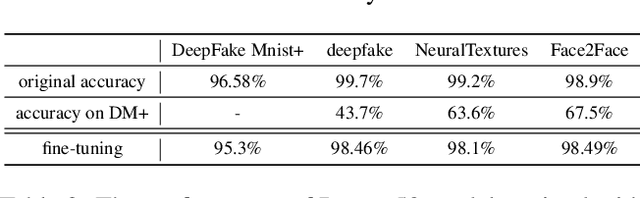
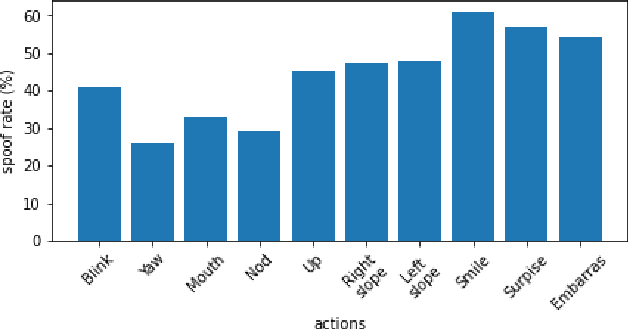
The DeepFakes, which are the facial manipulation techniques, is the emerging threat to digital society. Various DeepFake detection methods and datasets are proposed for detecting such data, especially for face-swapping. However, recent researches less consider facial animation, which is also important in the DeepFake attack side. It tries to animate a face image with actions provided by a driving video, which also leads to a concern about the security of recent payment systems that reply on liveness detection to authenticate real users via recognising a sequence of user facial actions. However, our experiments show that the existed datasets are not sufficient to develop reliable detection methods. While the current liveness detector cannot defend such videos as the attack. As a response, we propose a new human face animation dataset, called DeepFake MNIST+, generated by a SOTA image animation generator. It includes 10,000 facial animation videos in ten different actions, which can spoof the recent liveness detectors. A baseline detection method and a comprehensive analysis of the method is also included in this paper. In addition, we analyze the proposed dataset's properties and reveal the difficulty and importance of detecting animation datasets under different types of motion and compression quality.
Neural Emotion Director: Speech-preserving semantic control of facial expressions in "in-the-wild" videos
Dec 01, 2021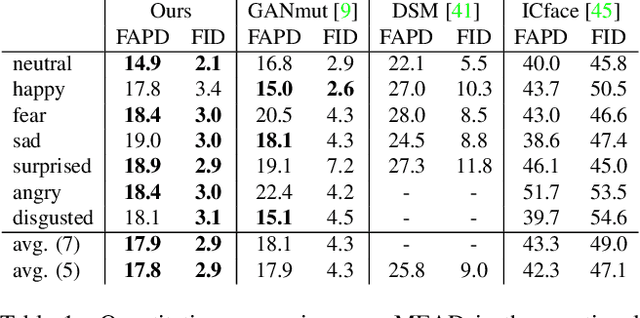
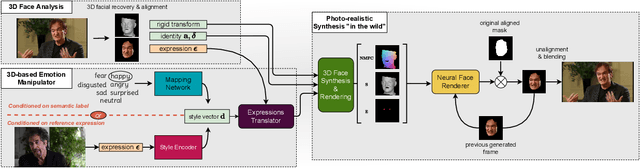


In this paper, we introduce a novel deep learning method for photo-realistic manipulation of the emotional state of actors in "in-the-wild" videos. The proposed method is based on a parametric 3D face representation of the actor in the input scene that offers a reliable disentanglement of the facial identity from the head pose and facial expressions. It then uses a novel deep domain translation framework that alters the facial expressions in a consistent and plausible manner, taking into account their dynamics. Finally, the altered facial expressions are used to photo-realistically manipulate the facial region in the input scene based on an especially-designed neural face renderer. To the best of our knowledge, our method is the first to be capable of controlling the actor's facial expressions by even using as a sole input the semantic labels of the manipulated emotions, while at the same time preserving the speech-related lip movements. We conduct extensive qualitative and quantitative evaluations and comparisons, which demonstrate the effectiveness of our approach and the especially promising results that we obtain. Our method opens a plethora of new possibilities for useful applications of neural rendering technologies, ranging from movie post-production and video games to photo-realistic affective avatars.
Dataset Creation Pipeline for Camera-Based Heart Rate Estimation
Mar 02, 2023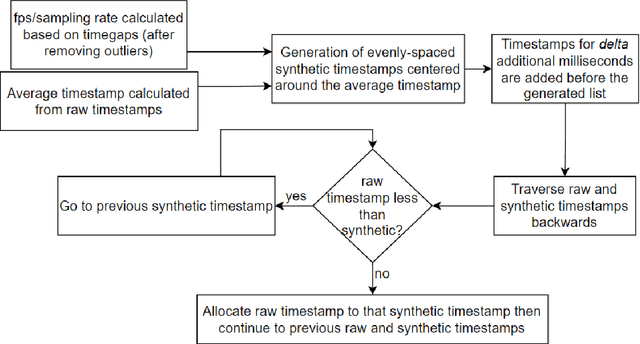
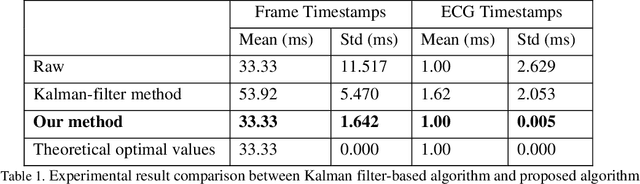
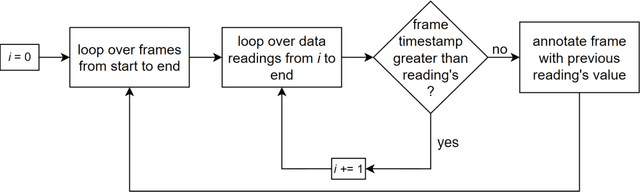
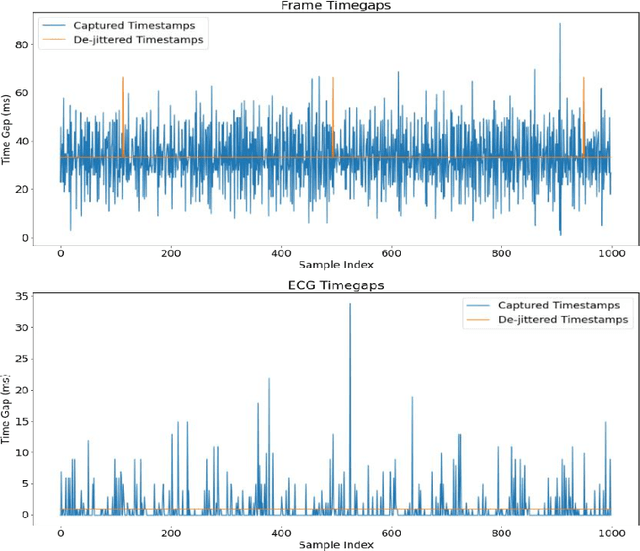
Heart rate is one of the most vital health metrics which can be utilized to investigate and gain intuitions into various human physiological and psychological information. Estimating heart rate without the constraints of contact-based sensors thus presents itself as a very attractive field of research as it enables well-being monitoring in a wider variety of scenarios. Consequently, various techniques for camera-based heart rate estimation have been developed ranging from classical image processing to convoluted deep learning models and architectures. At the heart of such research efforts lies health and visual data acquisition, cleaning, transformation, and annotation. In this paper, we discuss how to prepare data for the task of developing or testing an algorithm or machine learning model for heart rate estimation from images of facial regions. The data prepared is to include camera frames as well as sensor readings from an electrocardiograph sensor. The proposed pipeline is divided into four main steps, namely removal of faulty data, frame and electrocardiograph timestamp de-jittering, signal denoising and filtering, and frame annotation creation. Our main contributions are a novel technique of eliminating jitter from health sensor and camera timestamps and a method to accurately time align both visual frame and electrocardiogram sensor data which is also applicable to other sensor types.
Synergy between 3DMM and 3D Landmarks for Accurate 3D Facial Geometry
Oct 20, 2021
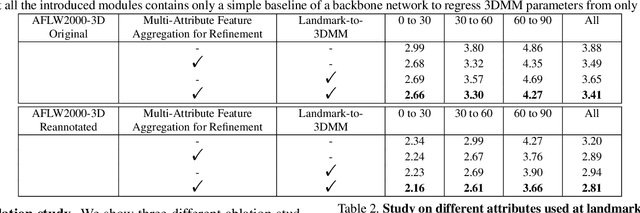
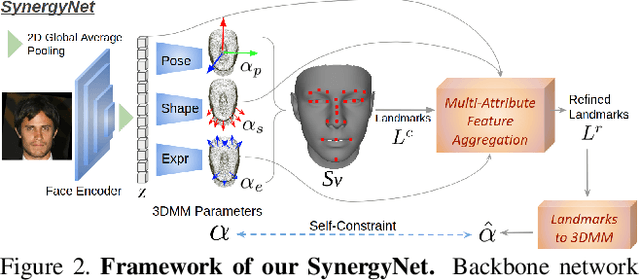
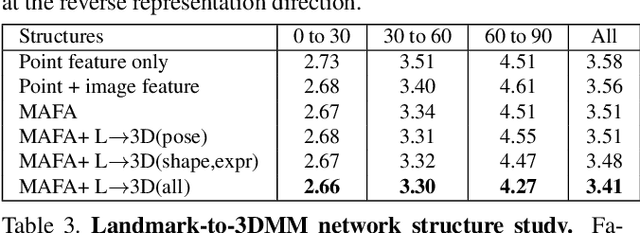
This work studies learning from a synergy process of 3D Morphable Models (3DMM) and 3D facial landmarks to predict complete 3D facial geometry, including 3D alignment, face orientation, and 3D face modeling. Our synergy process leverages a representation cycle for 3DMM parameters and 3D landmarks. 3D landmarks can be extracted and refined from face meshes built by 3DMM parameters. We next reverse the representation direction and show that predicting 3DMM parameters from sparse 3D landmarks improves the information flow. Together we create a synergy process that utilizes the relation between 3D landmarks and 3DMM parameters, and they collaboratively contribute to better performance. We extensively validate our contribution on full tasks of facial geometry prediction and show our superior and robust performance on these tasks for various scenarios. Particularly, we adopt only simple and widely-used network operations to attain fast and accurate facial geometry prediction. Codes and data: https://choyingw.github.io/works/SynergyNet/
Leveraging Deepfakes to Close the Domain Gap between Real and Synthetic Images in Facial Capture Pipelines
Apr 27, 2022



We propose an end-to-end pipeline for both building and tracking 3D facial models from personalized in-the-wild (cellphone, webcam, youtube clips, etc.) video data. First, we present a method for automatic data curation and retrieval based on a hierarchical clustering framework typical of collision detection algorithms in traditional computer graphics pipelines. Subsequently, we utilize synthetic turntables and leverage deepfake technology in order to build a synthetic multi-view stereo pipeline for appearance capture that is robust to imperfect synthetic geometry and image misalignment. The resulting model is fit with an animation rig, which is then used to track facial performances. Notably, our novel use of deepfake technology enables us to perform robust tracking of in-the-wild data using differentiable renderers despite a significant synthetic-to-real domain gap. Finally, we outline how we train a motion capture regressor, leveraging the aforementioned techniques to avoid the need for real-world ground truth data and/or a high-end calibrated camera capture setup.
Designing a 3D-Aware StyleNeRF Encoder for Face Editing
Feb 19, 2023
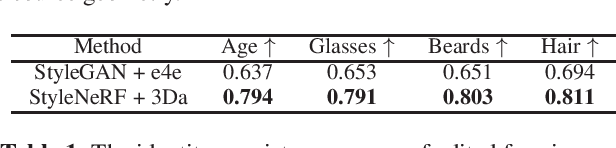
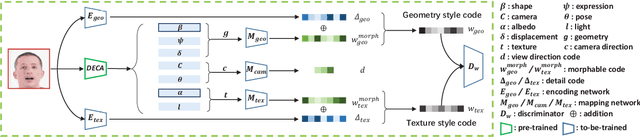
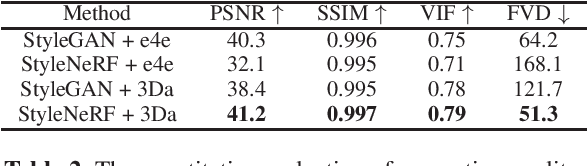
GAN inversion has been exploited in many face manipulation tasks, but 2D GANs often fail to generate multi-view 3D consistent images. The encoders designed for 2D GANs are not able to provide sufficient 3D information for the inversion and editing. Therefore, 3D-aware GAN inversion is proposed to increase the 3D editing capability of GANs. However, the 3D-aware GAN inversion remains under-explored. To tackle this problem, we propose a 3D-aware (3Da) encoder for GAN inversion and face editing based on the powerful StyleNeRF model. Our proposed 3Da encoder combines a parametric 3D face model with a learnable detail representation model to generate geometry, texture and view direction codes. For more flexible face manipulation, we then design a dual-branch StyleFlow module to transfer the StyleNeRF codes with disentangled geometry and texture flows. Extensive experiments demonstrate that we realize 3D consistent face manipulation in both facial attribute editing and texture transfer. Furthermore, for video editing, we make the sequence of frame codes share a common canonical manifold, which improves the temporal consistency of the edited attributes.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021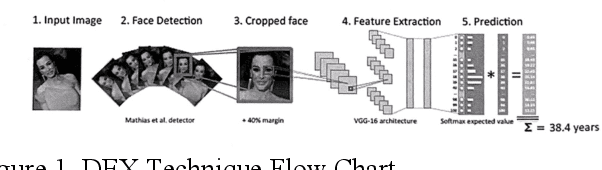
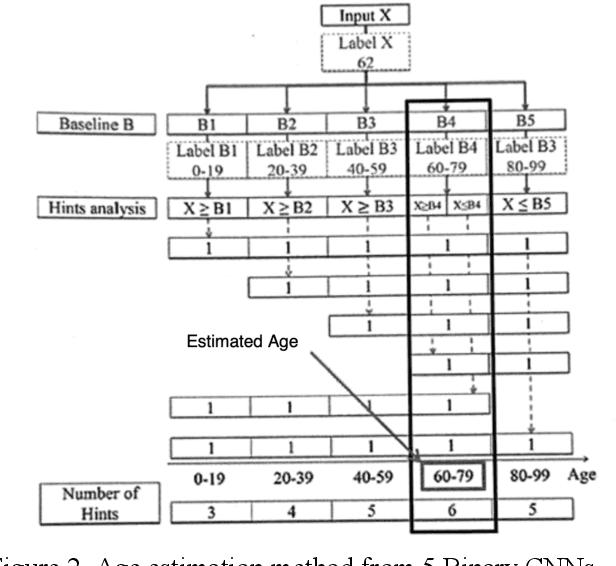
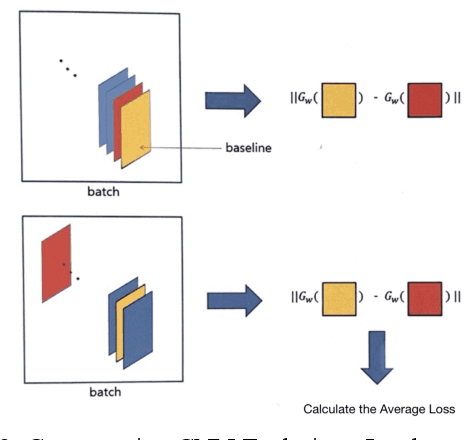
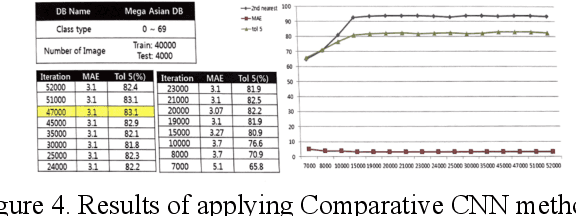
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.