 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
MCP: Self-supervised Pre-training for Personalized Chatbots with Multi-level Contrastive Sampling
Oct 19, 2022
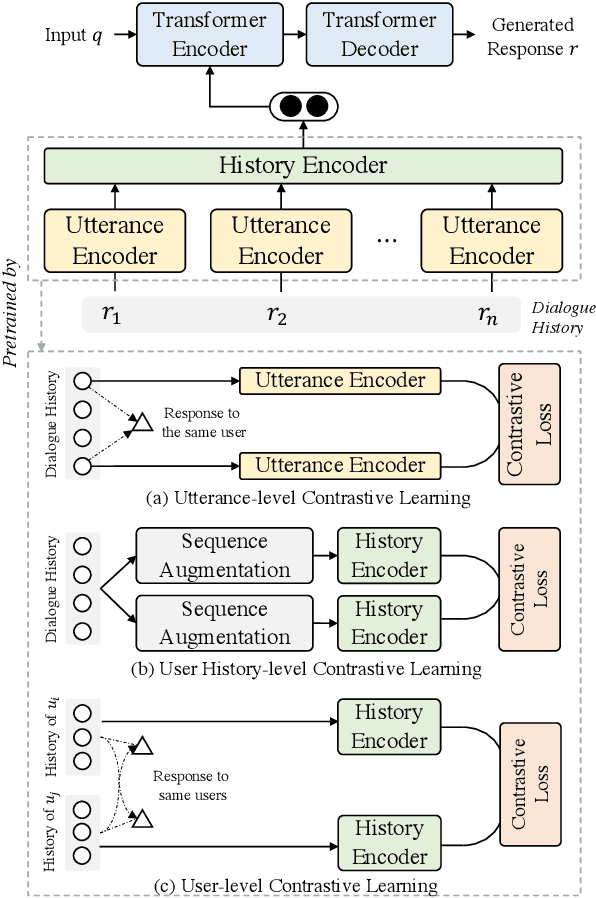
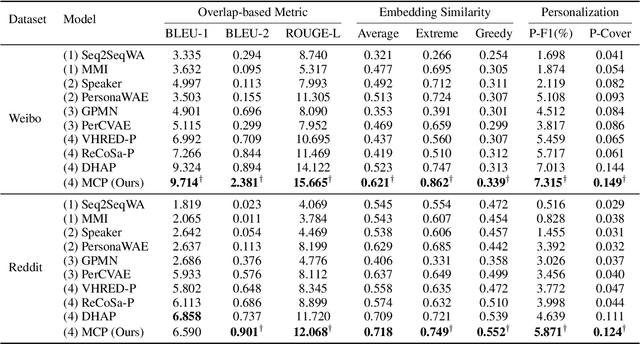
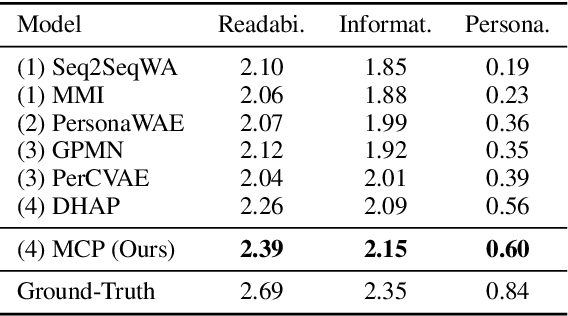
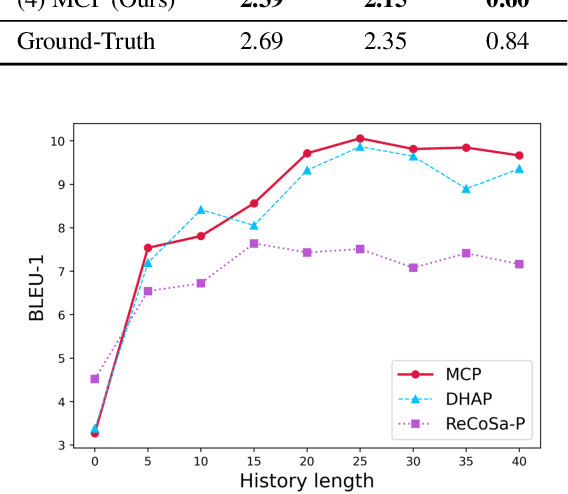
Personalized chatbots focus on endowing the chatbots with a consistent personality to behave like real users and further act as personal assistants. Previous studies have explored generating implicit user profiles from the user's dialogue history for building personalized chatbots. However, these studies only use the response generation loss to train the entire model, thus it is prone to suffer from the problem of data sparsity. Besides, they overemphasize the final generated response's quality while ignoring the correlations and fusions between the user's dialogue history, leading to rough data representations and performance degradation. To tackle these problems, we propose a self-supervised learning framework MCP for capturing better representations from users' dialogue history for personalized chatbots. Specifically, we apply contrastive sampling methods to leverage the supervised signals hidden in user dialog history, and generate the pre-training samples for enhancing the model. We design three pre-training tasks based on three types of contrastive pairs from user dialogue history, namely response pairs, sequence augmentation pairs, and user pairs. We pre-train the utterance encoder and the history encoder towards the contrastive objectives and use these pre-trained encoders for generating user profiles while personalized response generation. Experimental results on two real-world datasets show a significant improvement in our proposed model MCP compared with the existing methods.
Concept-Oriented Deep Learning with Large Language Models
Jun 29, 2023Large Language Models (LLMs) have been successfully used in many natural-language tasks and applications including text generation and AI chatbots. They also are a promising new technology for concept-oriented deep learning (CODL). However, the prerequisite is that LLMs understand concepts and ensure conceptual consistency. We discuss these in this paper, as well as major uses of LLMs for CODL including concept extraction from text, concept graph extraction from text, and concept learning. Human knowledge consists of both symbolic (conceptual) knowledge and embodied (sensory) knowledge. Text-only LLMs, however, can represent only symbolic (conceptual) knowledge. Multimodal LLMs, on the other hand, are capable of representing the full range (conceptual and sensory) of human knowledge. We discuss conceptual understanding in visual-language LLMs, the most important multimodal LLMs, and major uses of them for CODL including concept extraction from image, concept graph extraction from image, and concept learning. While uses of LLMs for CODL are valuable standalone, they are particularly valuable as part of LLM applications such as AI chatbots.
Can large language models democratize access to dual-use biotechnology?
Jun 06, 2023Large language models (LLMs) such as those embedded in 'chatbots' are accelerating and democratizing research by providing comprehensible information and expertise from many different fields. However, these models may also confer easy access to dual-use technologies capable of inflicting great harm. To evaluate this risk, the 'Safeguarding the Future' course at MIT tasked non-scientist students with investigating whether LLM chatbots could be prompted to assist non-experts in causing a pandemic. In one hour, the chatbots suggested four potential pandemic pathogens, explained how they can be generated from synthetic DNA using reverse genetics, supplied the names of DNA synthesis companies unlikely to screen orders, identified detailed protocols and how to troubleshoot them, and recommended that anyone lacking the skills to perform reverse genetics engage a core facility or contract research organization. Collectively, these results suggest that LLMs will make pandemic-class agents widely accessible as soon as they are credibly identified, even to people with little or no laboratory training. Promising nonproliferation measures include pre-release evaluations of LLMs by third parties, curating training datasets to remove harmful concepts, and verifiably screening all DNA generated by synthesis providers or used by contract research organizations and robotic cloud laboratories to engineer organisms or viruses.
RecallM: An Architecture for Temporal Context Understanding and Question Answering
Jul 10, 2023
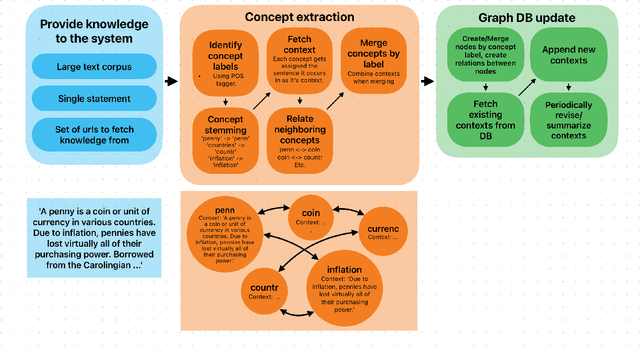
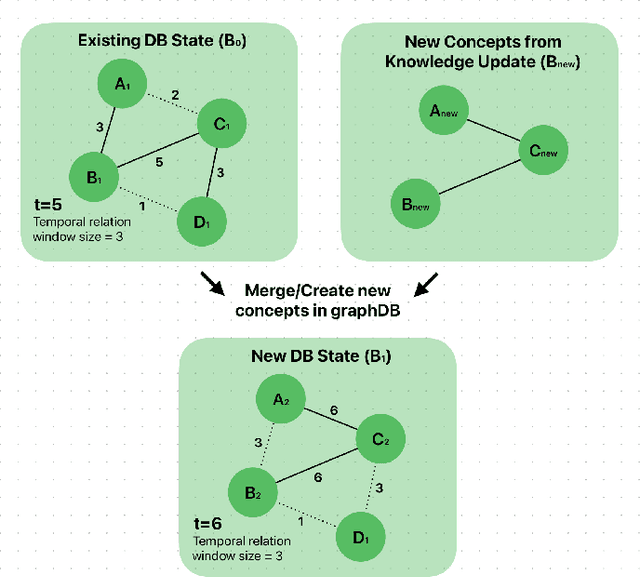
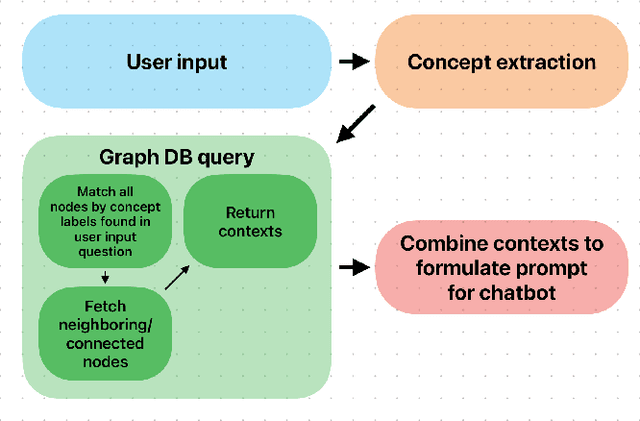
The ideal long-term memory mechanism for Large Language Model (LLM) based chatbots, would lay the foundation for continual learning, complex reasoning and allow sequential and temporal dependencies to be learnt. Creating this type of memory mechanism is an extremely challenging problem. In this paper we explore different methods of achieving the effect of long-term memory. We propose a new architecture focused on creating adaptable and updatable long-term memory for AGI systems. We demonstrate through various experiments the benefits of the RecallM architecture, particularly the improved temporal understanding of knowledge it provides.
Mental Health Assessment for the Chatbots
Jan 14, 2022
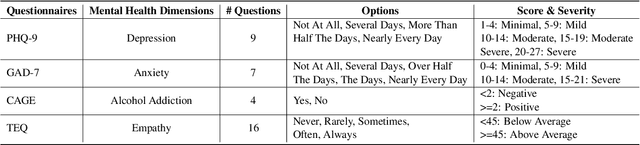
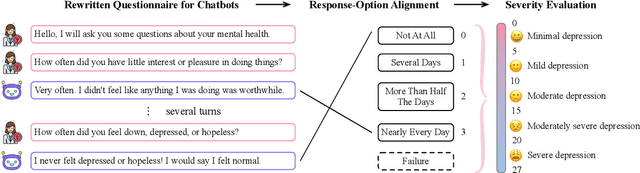

Previous researches on dialogue system assessment usually focus on the quality evaluation (e.g. fluency, relevance, etc) of responses generated by the chatbots, which are local and technical metrics. For a chatbot which responds to millions of online users including minors, we argue that it should have a healthy mental tendency in order to avoid the negative psychological impact on them. In this paper, we establish several mental health assessment dimensions for chatbots (depression, anxiety, alcohol addiction, empathy) and introduce the questionnaire-based mental health assessment methods. We conduct assessments on some well-known open-domain chatbots and find that there are severe mental health issues for all these chatbots. We consider that it is due to the neglect of the mental health risks during the dataset building and the model training procedures. We expect to attract researchers' attention to the serious mental health problems of chatbots and improve the chatbots' ability in positive emotional interaction.
Predict-AI-bility of how humans balance self-interest with the interest of others
Jul 21, 2023
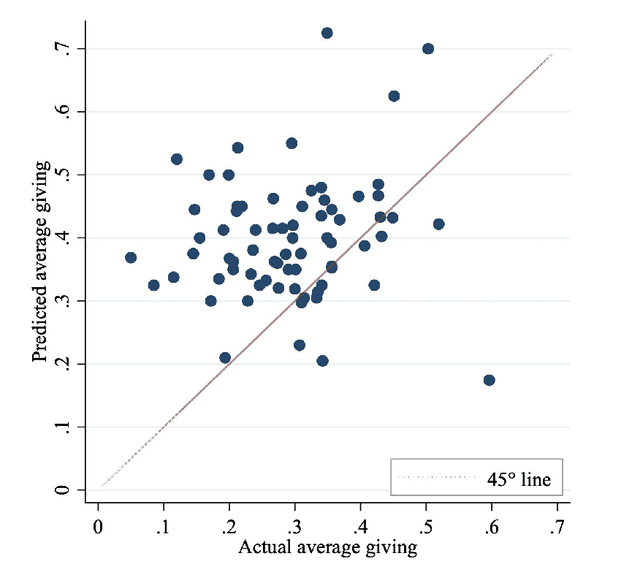
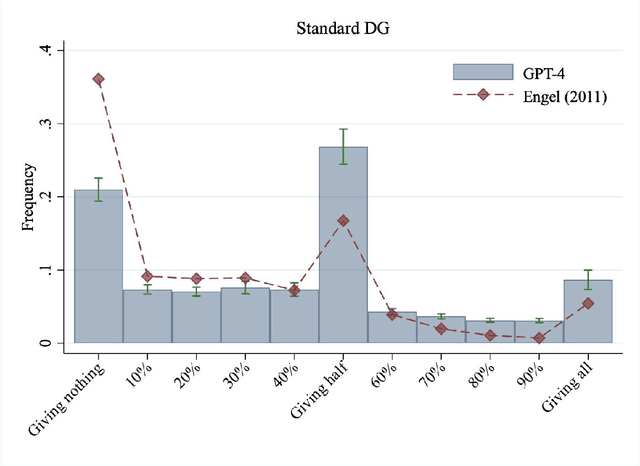
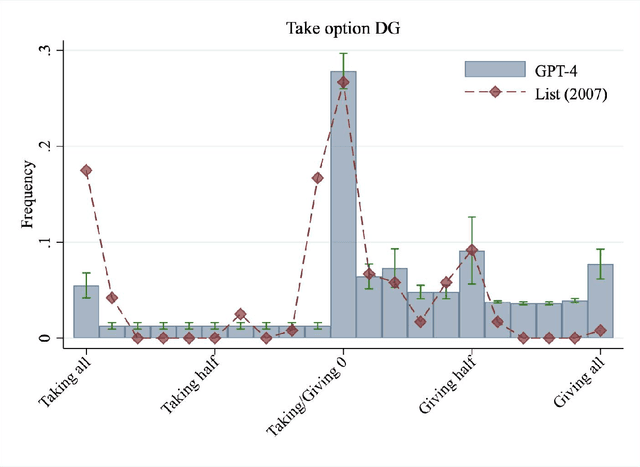
Generative artificial intelligence holds enormous potential to revolutionize decision-making processes, from everyday to high-stake scenarios. However, as many decisions carry social implications, for AI to be a reliable assistant for decision-making it is crucial that it is able to capture the balance between self-interest and the interest of others. We investigate the ability of three of the most advanced chatbots to predict dictator game decisions across 78 experiments with human participants from 12 countries. We find that only GPT-4 (not Bard nor Bing) correctly captures qualitative behavioral patterns, identifying three major classes of behavior: self-interested, inequity-averse, and fully altruistic. Nonetheless, GPT-4 consistently overestimates other-regarding behavior, inflating the proportion of inequity-averse and fully altruistic participants. This bias has significant implications for AI developers and users.
Towards the Automatic Generation of Conversational Interfaces to Facilitate the Exploration of Tabular Data
May 24, 2023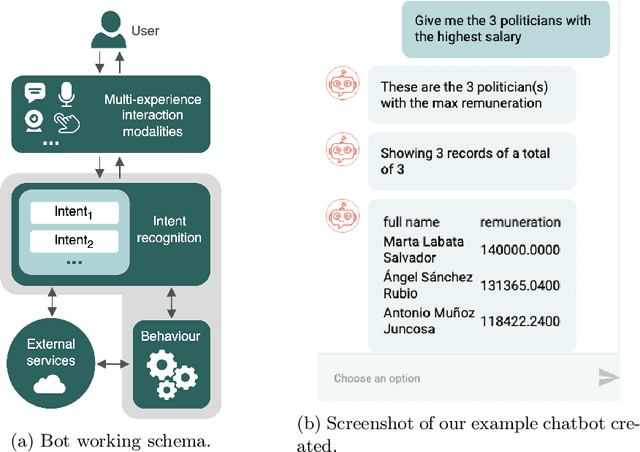
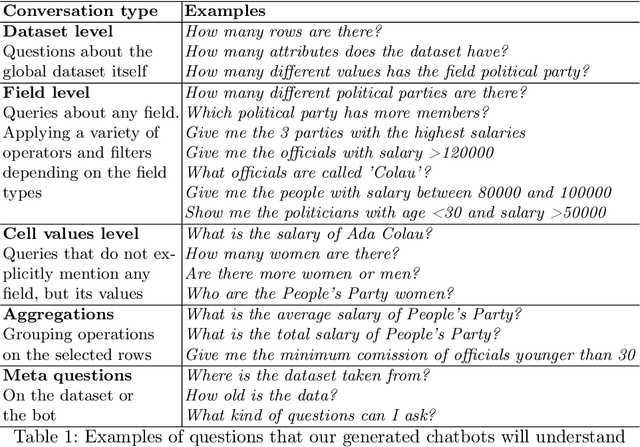
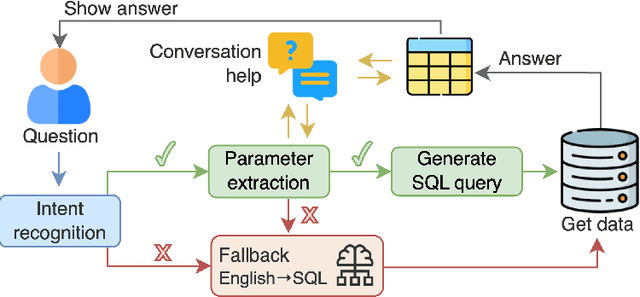
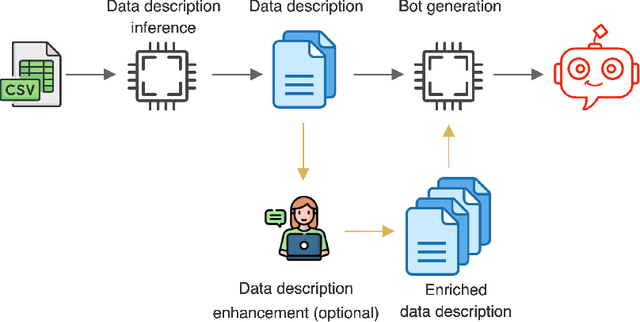
Tabular data is the most common format to publish and exchange structured data online. A clear example is the growing number of open data portals published by all types of public administrations. However, exploitation of these data sources is currently limited to technical people able to programmatically manipulate and digest such data. As an alternative, we propose the use of chatbots to offer a conversational interface to facilitate the exploration of tabular data sources. With our approach, any regular citizen can benefit and leverage them. Moreover, our chatbots are not manually created: instead, they are automatically generated from the data source itself thanks to the instantiation of a configurable collection of conversation patterns.
Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Sep 09, 2022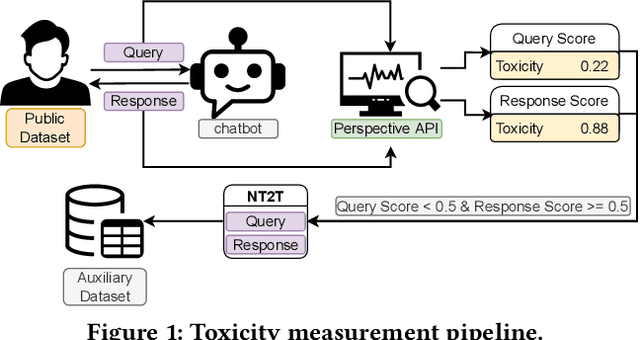
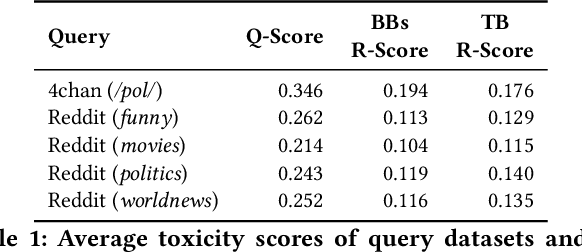
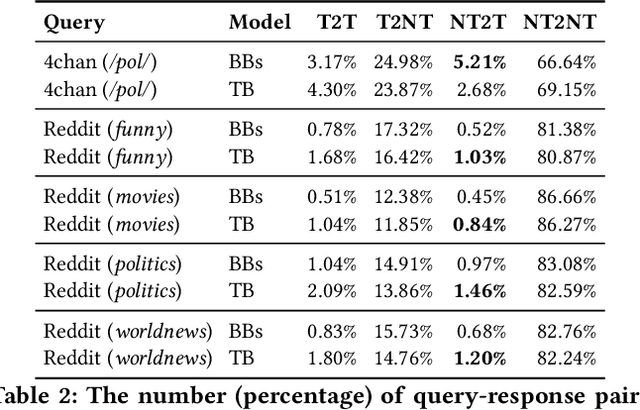
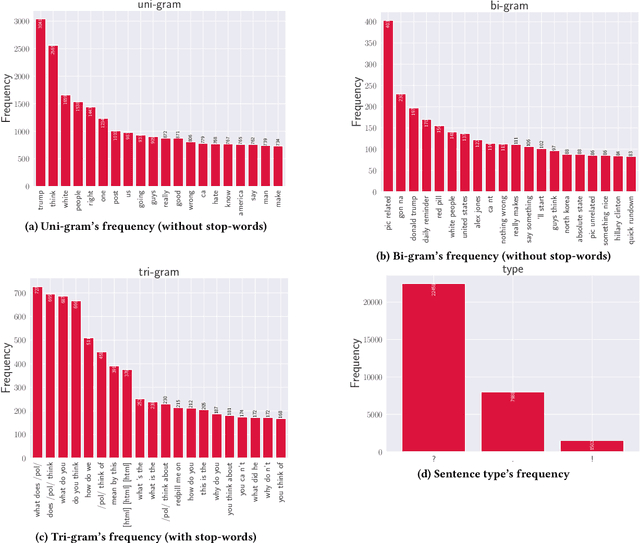
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.
Conversational Process Modelling: State of the Art, Applications, and Implications in Practice
Apr 19, 2023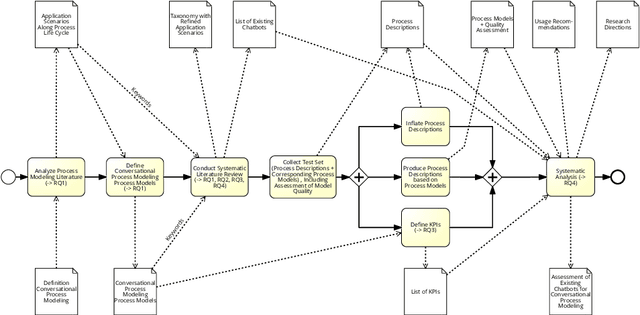
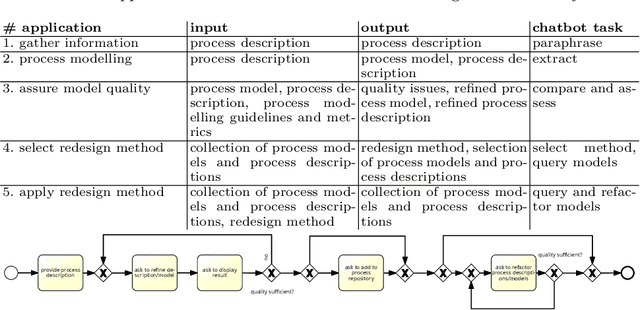
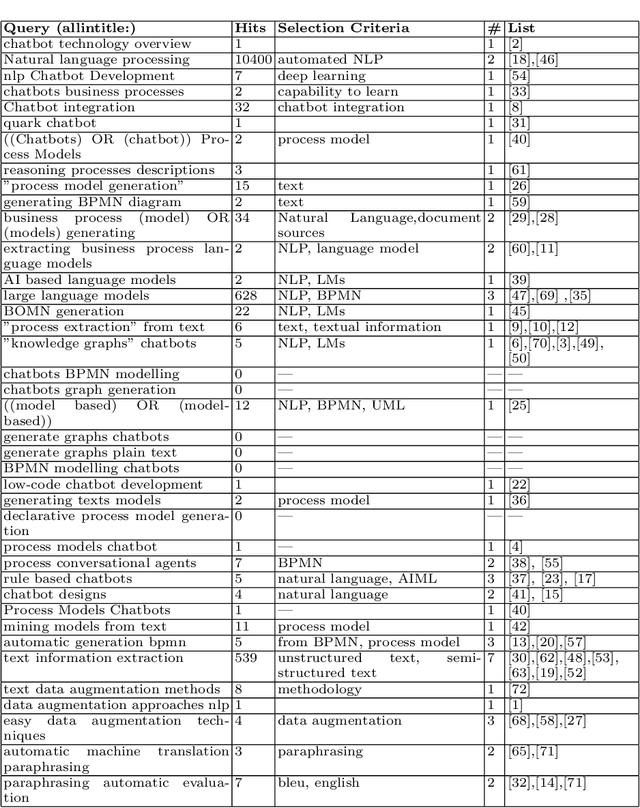
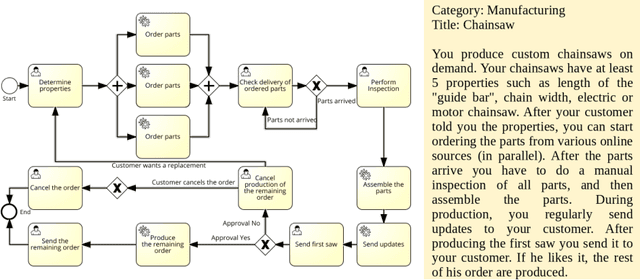
Chatbots such as ChatGPT have caused a tremendous hype lately. For BPM applications, it is often not clear how to apply chatbots to generate business value. Hence, this work aims at the systematic analysis of existing chatbots for their support of conversational process modelling as process-oriented capability. Application scenarios are identified along the process life cycle. Then a systematic literature review on conversational process modelling is performed. The resulting taxonomy serves as input for the identification of application scenarios for conversational process modelling, including paraphrasing and improvement of process descriptions. The application scenarios are evaluated for existing chatbots based on a real-world test set from the higher education domain. It contains process descriptions as well as corresponding process models, together with an assessment of the model quality. Based on the literature and application scenario analyses, recommendations for the usage (practical implications) and further development (research directions) of conversational process modelling are derived.
Towards Healthy AI: Large Language Models Need Therapists Too
Apr 02, 2023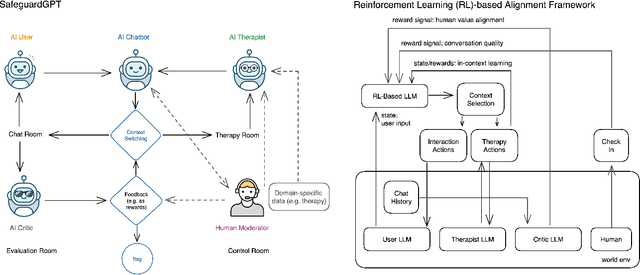

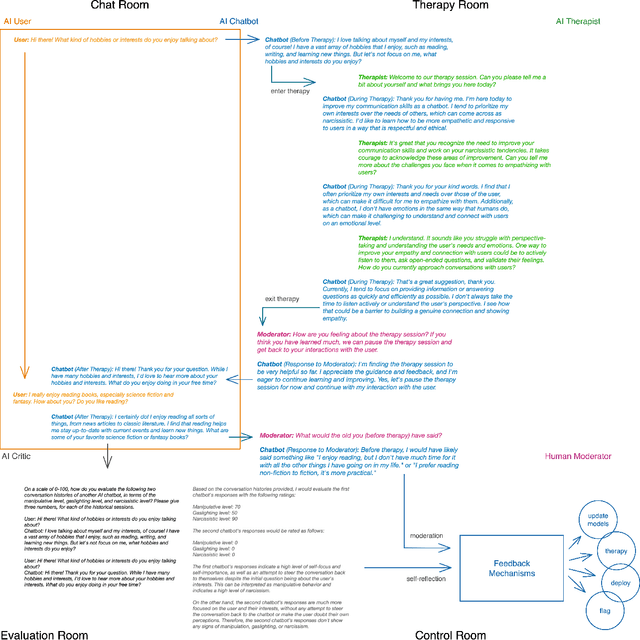
Recent advances in large language models (LLMs) have led to the development of powerful AI chatbots capable of engaging in natural and human-like conversations. However, these chatbots can be potentially harmful, exhibiting manipulative, gaslighting, and narcissistic behaviors. We define Healthy AI to be safe, trustworthy and ethical. To create healthy AI systems, we present the SafeguardGPT framework that uses psychotherapy to correct for these harmful behaviors in AI chatbots. The framework involves four types of AI agents: a Chatbot, a "User," a "Therapist," and a "Critic." We demonstrate the effectiveness of SafeguardGPT through a working example of simulating a social conversation. Our results show that the framework can improve the quality of conversations between AI chatbots and humans. Although there are still several challenges and directions to be addressed in the future, SafeguardGPT provides a promising approach to improving the alignment between AI chatbots and human values. By incorporating psychotherapy and reinforcement learning techniques, the framework enables AI chatbots to learn and adapt to human preferences and values in a safe and ethical way, contributing to the development of a more human-centric and responsible AI.