 Add to Chrome
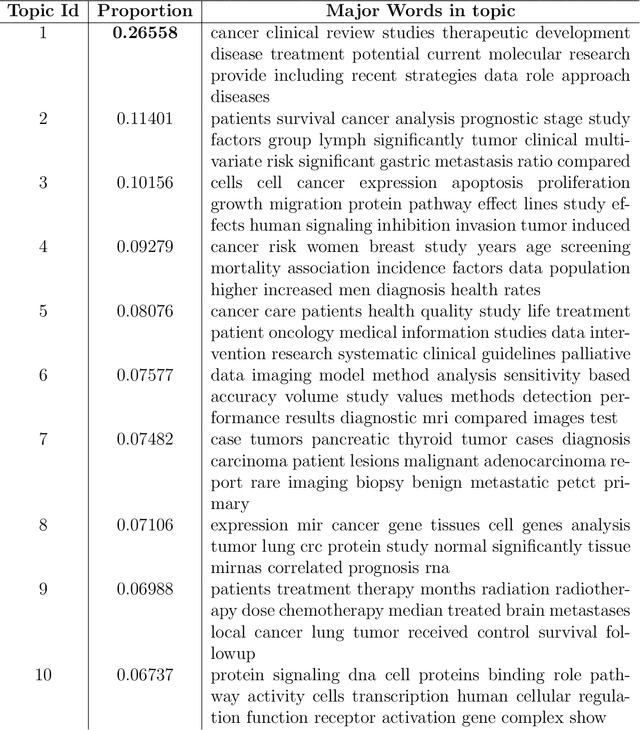
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Modeling community structure and topics in dynamic text networks
Aug 23, 2018
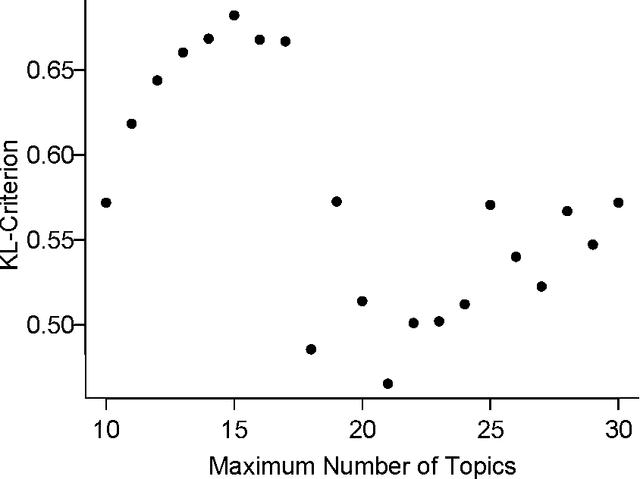
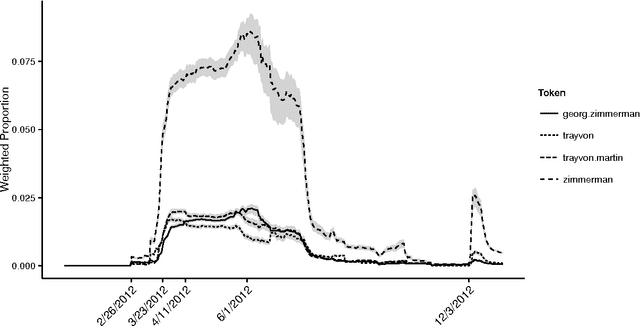
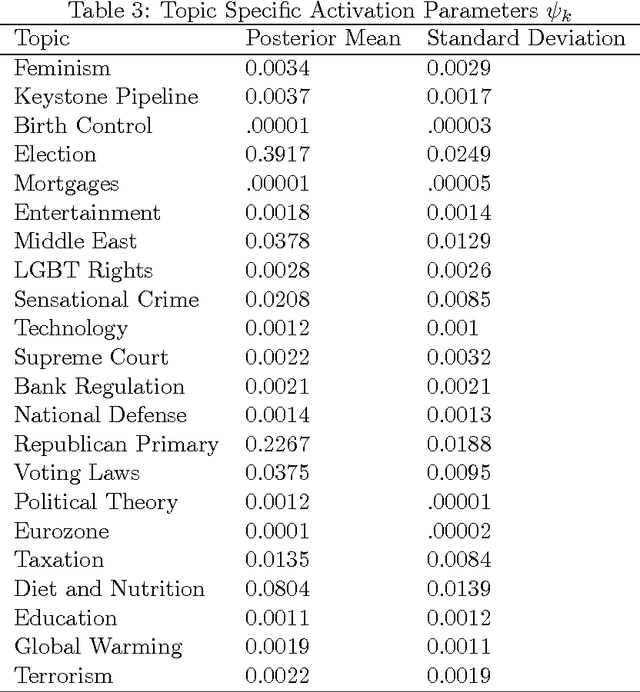
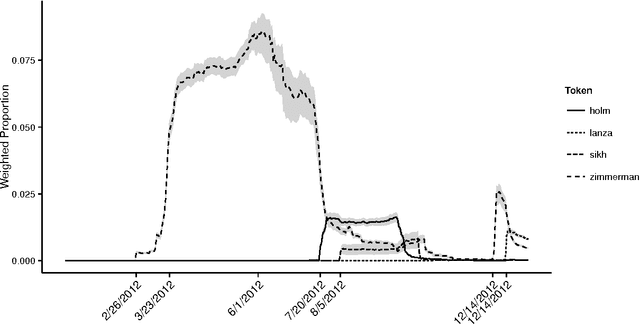
The last decade has seen great progress in both dynamic network modeling and topic modeling. This paper draws upon both areas to create a Bayesian method that allows topic discovery to inform the latent network model and the network structure to facilitate topic identification. We apply this method to the 467 top political blogs of 2012. Our results find complex community structure within this set of blogs, where community membership depends strongly upon the set of topics in which the blogger is interested.
Unsupervised Topic Modeling Approaches to Decision Summarization in Spoken Meetings
Jun 24, 2016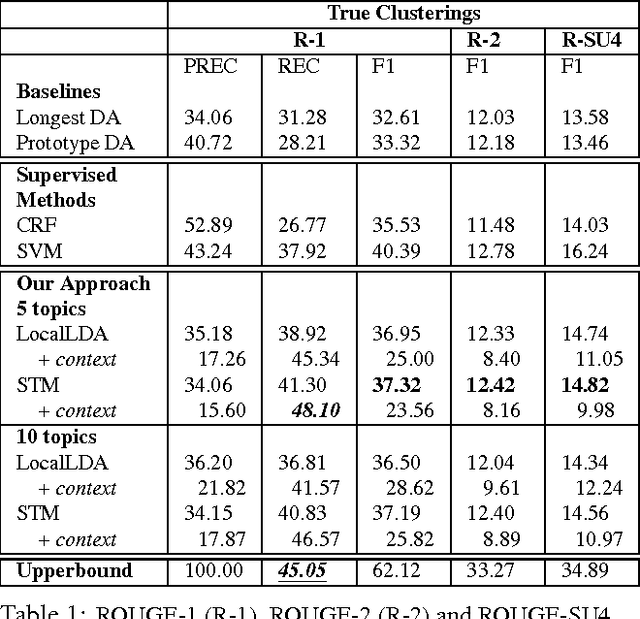
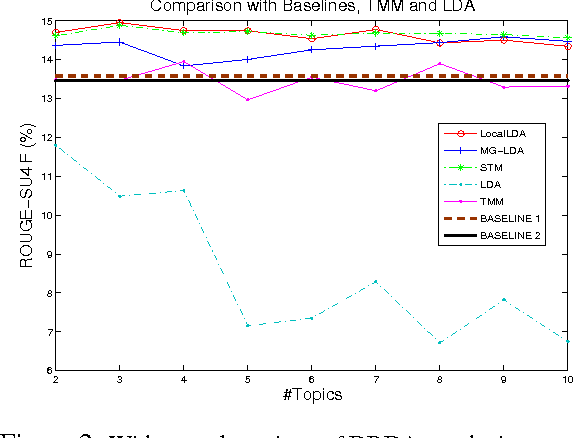
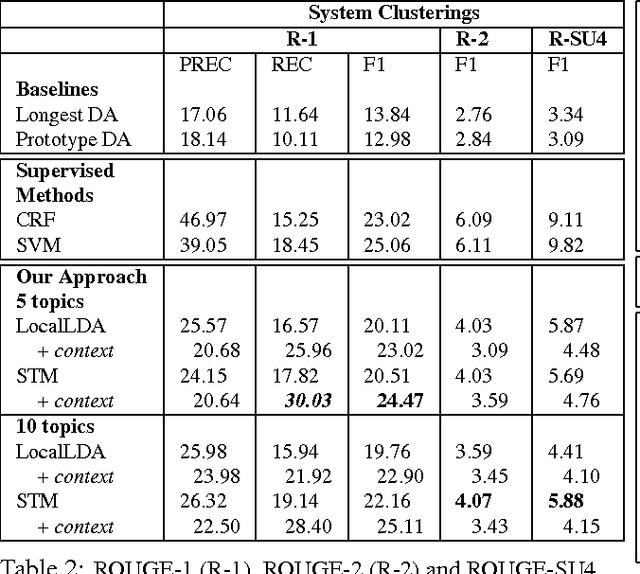
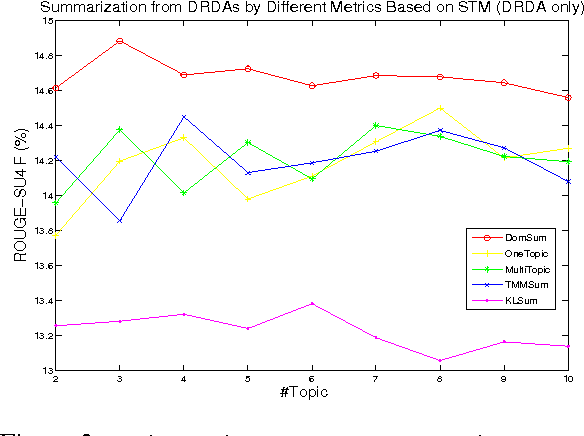
We present a token-level decision summarization framework that utilizes the latent topic structures of utterances to identify "summary-worthy" words. Concretely, a series of unsupervised topic models is explored and experimental results show that fine-grained topic models, which discover topics at the utterance-level rather than the document-level, can better identify the gist of the decision-making process. Moreover, our proposed token-level summarization approach, which is able to remove redundancies within utterances, outperforms existing utterance ranking based summarization methods. Finally, context information is also investigated to add additional relevant information to the summary.
OpenFraming: We brought the ML; you bring the data. Interact with your data and discover its frames
Aug 16, 2020When journalists cover a news story, they can cover the story from multiple angles or perspectives. A news article written about COVID-19 for example, might focus on personal preventative actions such as mask-wearing, while another might focus on COVID-19's impact on the economy. These perspectives are called "frames," which when used may influence public perception and opinion of the issue. We introduce a Web-based system for analyzing and classifying frames in text documents. Our goal is to make effective tools for automatic frame discovery and labeling based on topic modeling and deep learning widely accessible to researchers from a diverse array of disciplines. To this end, we provide both state-of-the-art pre-trained frame classification models on various issues as well as a user-friendly pipeline for training novel classification models on user-provided corpora. Researchers can submit their documents and obtain frames of the documents. The degree of user involvement is flexible: they can run models that have been pre-trained on select issues; submit labeled documents and train a new model for frame classification; or submit unlabeled documents and obtain potential frames of the documents. The code making up our system is also open-sourced and well-documented, making the system transparent and expandable. The system is available on-line at http://www.openframing.org and via our GitHub page https://github.com/davidatbu/openFraming .
Hierarchical Methods of Moments
Oct 17, 2018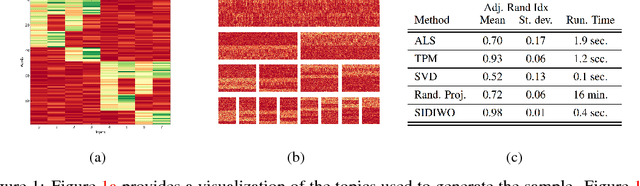
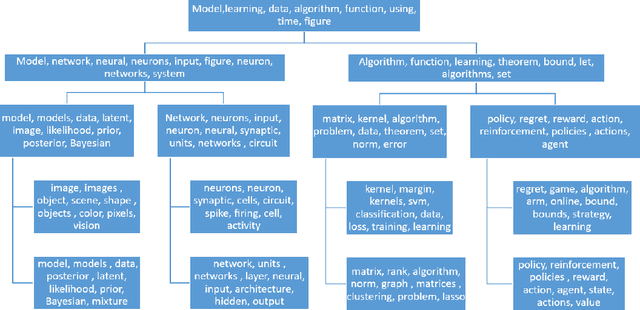
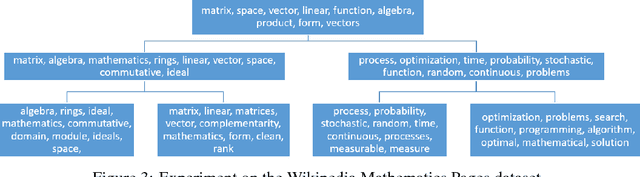
Spectral methods of moments provide a powerful tool for learning the parameters of latent variable models. Despite their theoretical appeal, the applicability of these methods to real data is still limited due to a lack of robustness to model misspecification. In this paper we present a hierarchical approach to methods of moments to circumvent such limitations. Our method is based on replacing the tensor decomposition step used in previous algorithms with approximate joint diagonalization. Experiments on topic modeling show that our method outperforms previous tensor decomposition methods in terms of speed and model quality.
Prediction Focused Topic Models for Electronic Health Records
Nov 15, 2019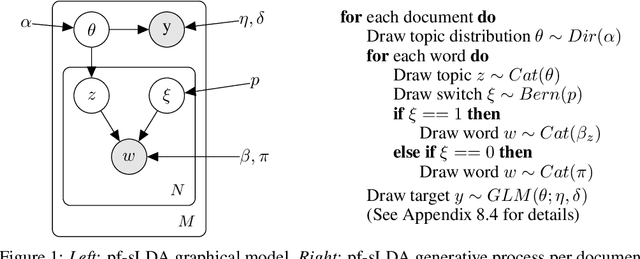
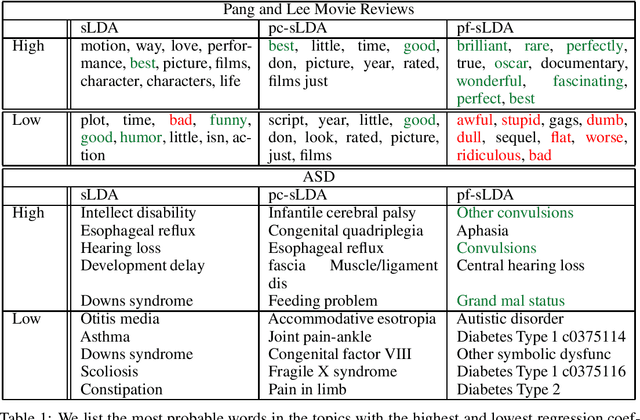
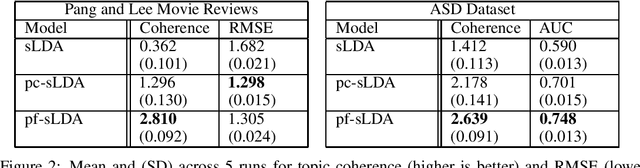
Electronic Health Record (EHR) data can be represented as discrete counts over a high dimensional set of possible procedures, diagnoses, and medications. Supervised topic models present an attractive option for incorporating EHR data as features into a prediction problem: given a patient's record, we estimate a set of latent factors that are predictive of the response variable. However, existing methods for supervised topic modeling struggle to balance prediction quality and coherence of the latent factors. We introduce a novel approach, the prediction-focused topic model, that uses the supervisory signal to retain only features that improve, or do not hinder, prediction performance. By removing features with irrelevant signal, the topic model is able to learn task-relevant, interpretable topics. We demonstrate on a EHR dataset and a movie review dataset that compared to existing approaches, prediction-focused topic models are able to learn much more coherent topics while maintaining competitive predictions.
jLDADMM: A Java package for the LDA and DMM topic models
Aug 11, 2018In this technical report, we present jLDADMM---an easy-to-use Java toolkit for conventional topic models. jLDADMM is released to provide alternatives for topic modeling on normal or short texts. It provides implementations of the Latent Dirichlet Allocation topic model and the one-topic-per-document Dirichlet Multinomial Mixture model (i.e. mixture of unigrams), using collapsed Gibbs sampling. In addition, jLDADMM supplies a document clustering evaluation to compare topic models. jLDADMM is open-source and available to download at: https://github.com/datquocnguyen/jLDADMM
Visual Exploration and Knowledge Discovery from Biomedical Dark Data
Sep 28, 2020
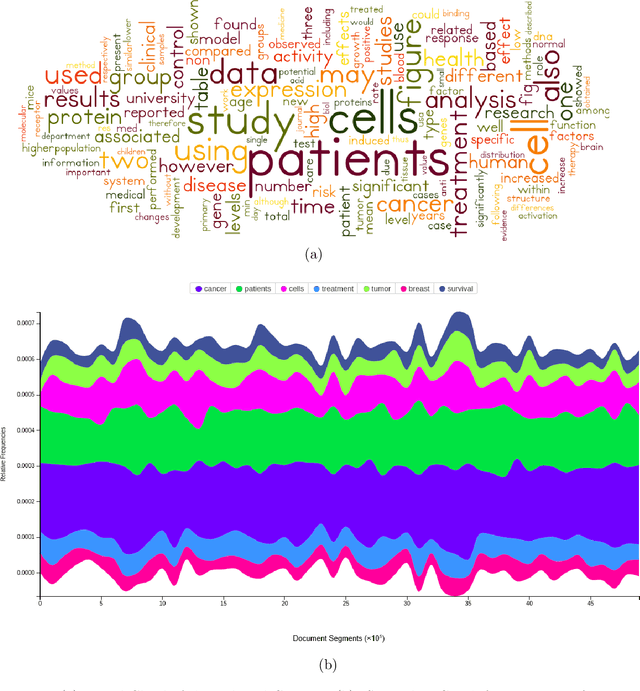
Data visualization techniques proffer efficient means to organize and present data in graphically appealing formats, which not only speeds up the process of decision making and pattern recognition but also enables decision-makers to fully understand data insights and make informed decisions. Over time, with the rise in technological and computational resources, there has been an exponential increase in the world's scientific knowledge. However, most of it lacks structure and cannot be easily categorized and imported into regular databases. This type of data is often termed as Dark Data. Data visualization techniques provide a promising solution to explore such data by allowing quick comprehension of information, the discovery of emerging trends, identification of relationships and patterns, etc. In this empirical research study, we use the rich corpus of PubMed comprising of more than 30 million citations from biomedical literature to visually explore and understand the underlying key-insights using various information visualization techniques. We employ a natural language processing based pipeline to discover knowledge out of the biomedical dark data. The pipeline comprises of different lexical analysis techniques like Topic Modeling to extract inherent topics and major focus areas, Network Graphs to study the relationships between various entities like scientific documents and journals, researchers, and, keywords and terms, etc. With this analytical research, we aim to proffer a potential solution to overcome the problem of analyzing overwhelming amounts of information and diminish the limitation of human cognition and perception in handling and examining such large volumes of data.
Visualization of Clandestine Labs from Seizure Reports: Thematic Mapping and Data Mining Research Directions
Mar 05, 2015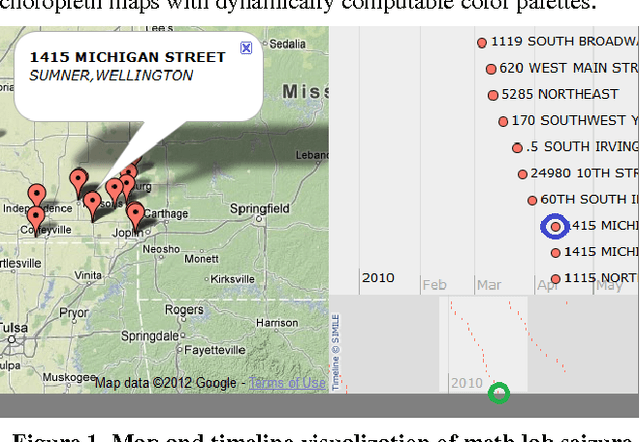
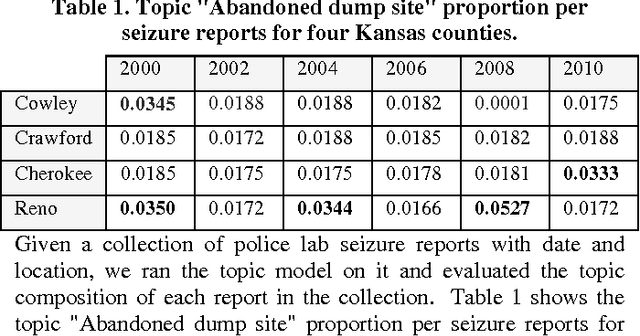
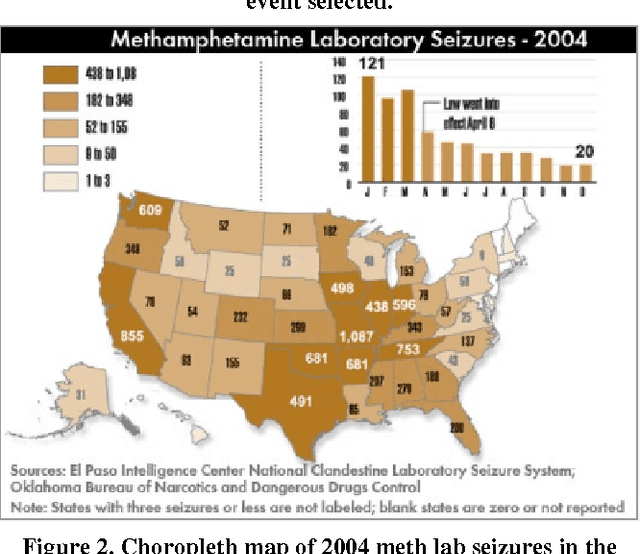
The problem of spatiotemporal event visualization based on reports entails subtasks ranging from named entity recognition to relationship extraction and mapping of events. We present an approach to event extraction that is driven by data mining and visualization goals, particularly thematic mapping and trend analysis. This paper focuses on bridging the information extraction and visualization tasks and investigates topic modeling approaches. We develop a static, finite topic model and examine the potential benefits and feasibility of extending this to dynamic topic modeling with a large number of topics and continuous time. We describe an experimental test bed for event mapping that uses this end-to-end information retrieval system, and report preliminary results on a geoinformatics problem: tracking of methamphetamine lab seizure events across time and space.
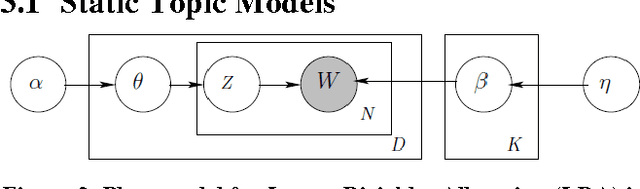
Sato: Contextual Semantic Type Detection in Tables
Nov 14, 2019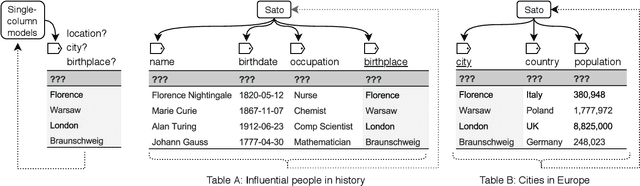

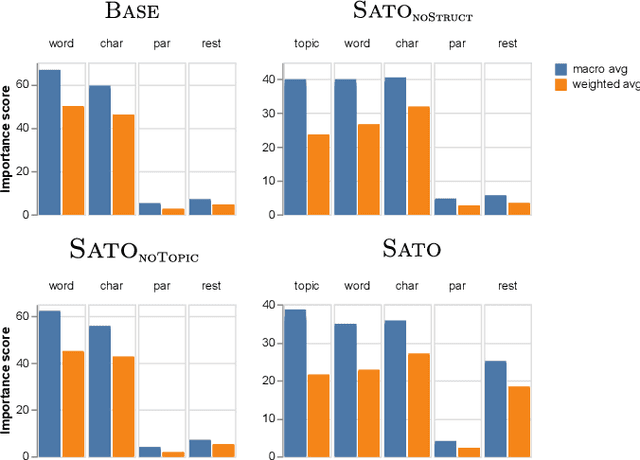
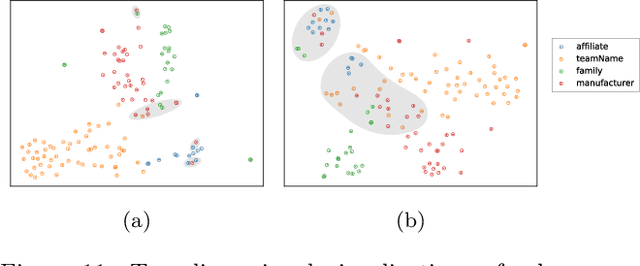
Detecting the semantic types of data columns in relational tables is important for various data preparation and information retrieval tasks such as data cleaning, schema matching, data discovery, and semantic search. However, existing detection approaches either perform poorly with dirty data, support only a limited number of semantic types, fail to incorporate the table context of columns or rely on large sample sizes in the training data. We introduce Sato, a hybrid machine learning model to automatically detect the semantic types of columns in tables, exploiting the signals from the context as well as the column values. Sato combines a deep learning model trained on a large-scale table corpus with topic modeling and structured prediction to achieve support-weighted and macro average F1 scores of 0.901 and 0.973, respectively, exceeding the state-of-the-art performance by a significant margin. We extensively analyze the overall and per-type performance of Sato, discussing how individual modeling components, as well as feature categories, contribute to its performance.
Content analysis of Persian/Farsi Tweets during COVID-19 pandemic in Iran using NLP
May 17, 2020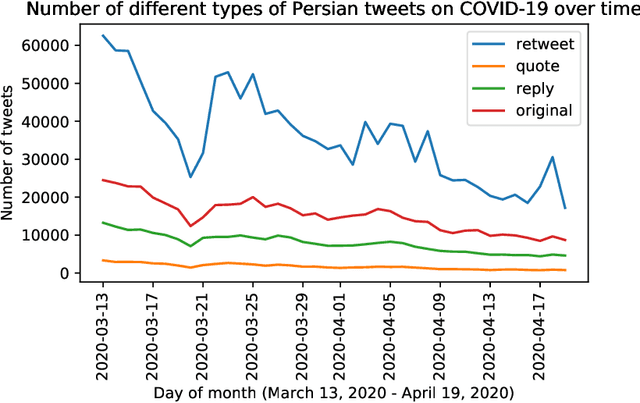
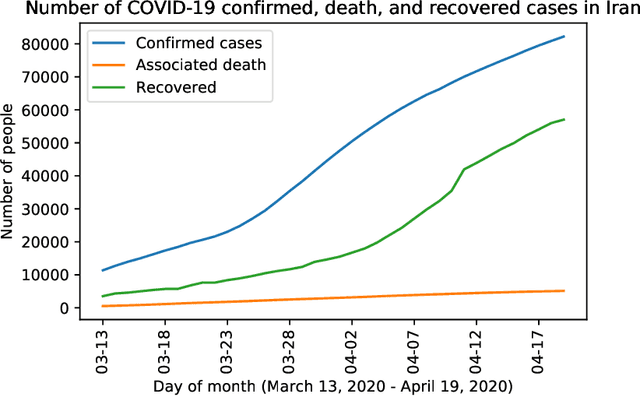
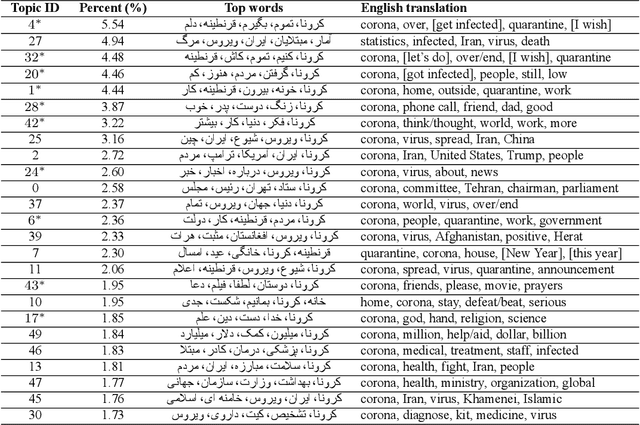
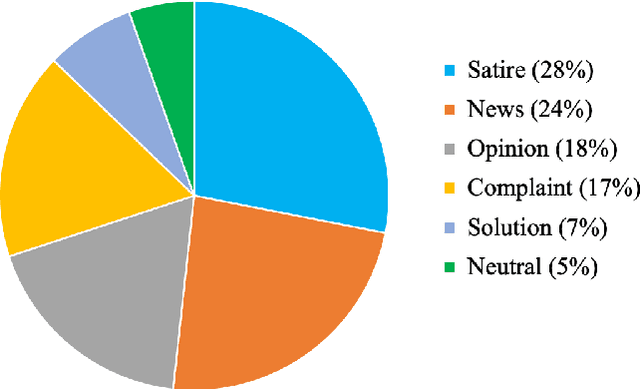
Iran, along with China, South Korea, and Italy was among the countries that were hit hard in the first wave of the COVID-19 spread. Twitter is one of the widely-used online platforms by Iranians inside and abroad for sharing their opinion, thoughts, and feelings about a wide range of issues. In this study, using more than 530,000 original tweets in Persian/Farsi on COVID-19, we analyzed the topics discussed among users, who are mainly Iranians, to gauge and track the response to the pandemic and how it evolved over time. We applied a combination of manual annotation of a random sample of tweets and topic modeling tools to classify the contents and frequency of each category of topics. We identified the top 25 topics among which living experience under home quarantine emerged as a major talking point. We additionally categorized broader content of tweets that shows satire, followed by news, is the dominant tweet type among the Iranian users. While this framework and methodology can be used to track public response to ongoing developments related to COVID-19, a generalization of this framework can become a useful framework to gauge Iranian public reaction to ongoing policy measures or events locally and internationally.