 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFIG: Vectorizing Complex Figures in SVG with Vision-Language Models
Mar 25, 2026Scalable Vector Graphics (SVG) are an essential format for technical illustration and digital design, offering precise resolution independence and flexible semantic editability. In practice, however, original vector source files are frequently lost or inaccessible, leaving only "flat" rasterized versions (e.g., PNG or JPEG) that are difficult to modify or scale. Manually reconstructing these figures is a prohibitively labor-intensive process, requiring specialized expertise to recover the original geometric intent. To bridge this gap, we propose VFIG, a family of Vision-Language Models trained for complex and high-fidelity figure-to-SVG conversion. While this task is inherently data-driven, existing datasets are typically small-scale and lack the complexity of professional diagrams. We address this by introducing VFIG-DATA, a large-scale dataset of 66K high-quality figure-SVG pairs, curated from a diverse mix of real-world paper figures and procedurally generated diagrams. Recognizing that SVGs are composed of recurring primitives and hierarchical local structures, we introduce a coarse-to-fine training curriculum that begins with supervised fine-tuning (SFT) to learn atomic primitives and transitions to reinforcement learning (RL) refinement to optimize global diagram fidelity, layout consistency, and topological edge cases. Finally, we introduce VFIG-BENCH, a comprehensive evaluation suite with novel metrics designed to measure the structural integrity of complex figures. VFIG achieves state-of-the-art performance among open-source models and performs on par with GPT-5.2, achieving a VLM-Judge score of 0.829 on VFIG-BENCH.
Prediction Focused Topic Models for Electronic Health Records
Nov 15, 2019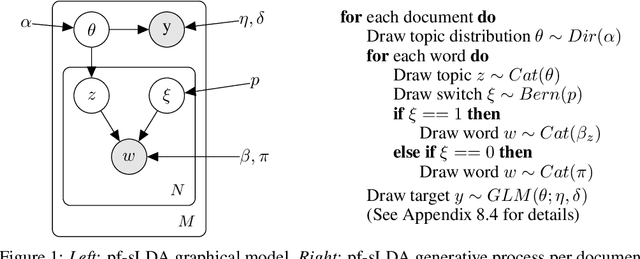
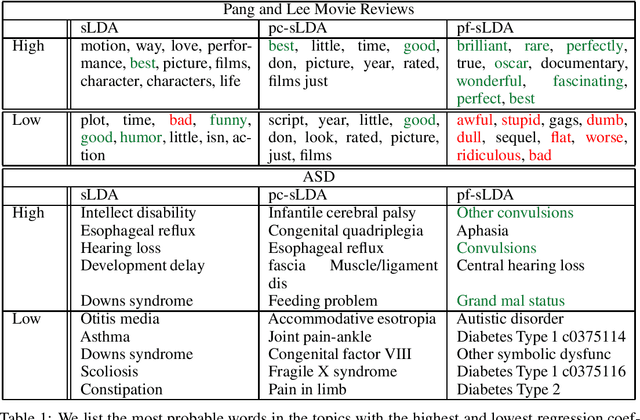
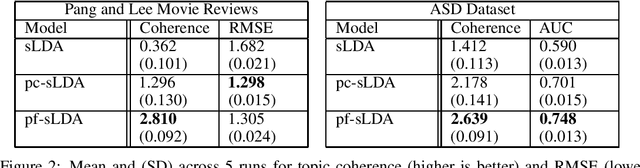
Electronic Health Record (EHR) data can be represented as discrete counts over a high dimensional set of possible procedures, diagnoses, and medications. Supervised topic models present an attractive option for incorporating EHR data as features into a prediction problem: given a patient's record, we estimate a set of latent factors that are predictive of the response variable. However, existing methods for supervised topic modeling struggle to balance prediction quality and coherence of the latent factors. We introduce a novel approach, the prediction-focused topic model, that uses the supervisory signal to retain only features that improve, or do not hinder, prediction performance. By removing features with irrelevant signal, the topic model is able to learn task-relevant, interpretable topics. We demonstrate on a EHR dataset and a movie review dataset that compared to existing approaches, prediction-focused topic models are able to learn much more coherent topics while maintaining competitive predictions.
Prediction Focused Topic Models via Vocab Selection
Oct 12, 2019

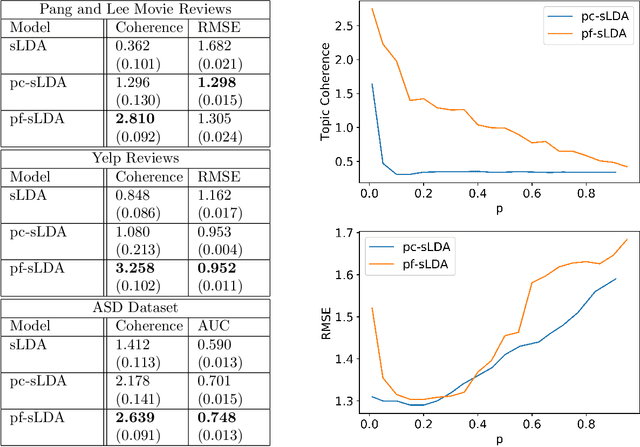
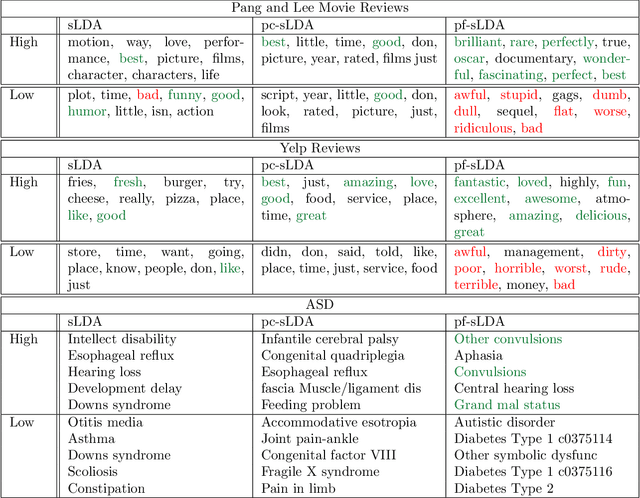
Supervised topic models are often sought to balance prediction quality and interpretability. However, when models are (inevitably) misspecified, standard approaches rarely deliver on both. We introduce a novel approach, the prediction-focused topic model, that uses the supervisory signal to retain only vocabulary terms that improve, or do not hinder, prediction performance. By removing terms with irrelevant signal, the topic model is able to learn task-relevant, interpretable topics. We demonstrate on several data sets that compared to existing approaches, prediction-focused topic models are able to learn much more coherent topics while maintaining competitive predictions.