 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Topic Grouper: An Agglomerative Clustering Approach to Topic Modeling
Apr 13, 2019
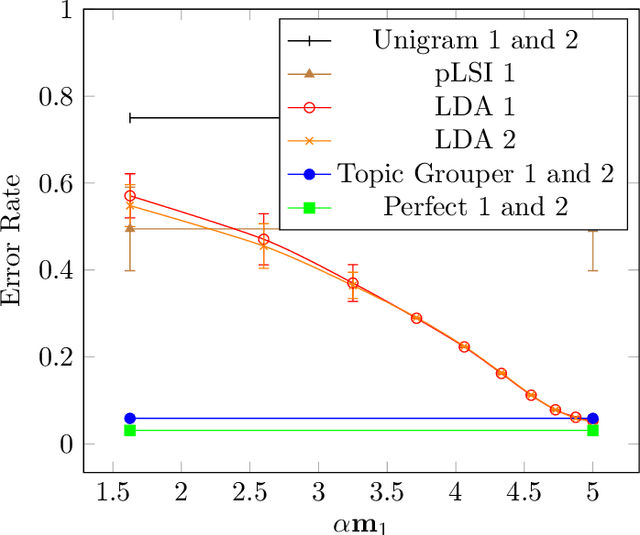
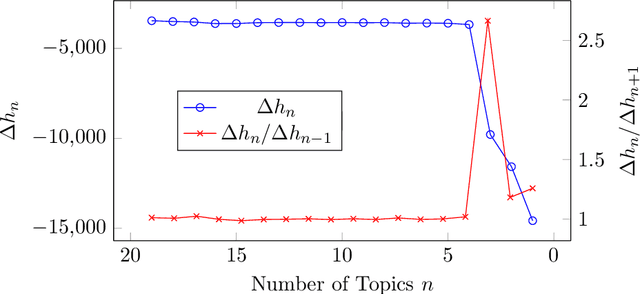
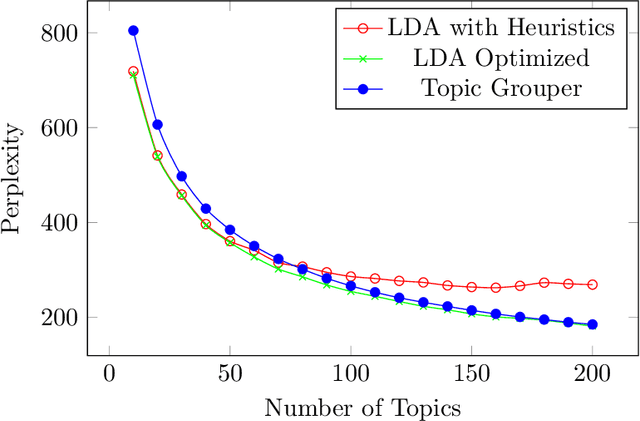
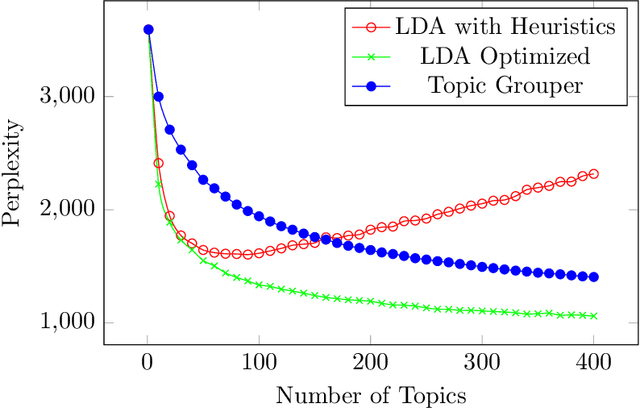
We introduce Topic Grouper as a complementary approach in the field of probabilistic topic modeling. Topic Grouper creates a disjunctive partitioning of the training vocabulary in a stepwise manner such that resulting partitions represent topics. It is governed by a simple generative model, where the likelihood to generate the training documents via topics is optimized. The algorithm starts with one-word topics and joins two topics at every step. It therefore generates a solution for every desired number of topics ranging between the size of the training vocabulary and one. The process represents an agglomerative clustering that corresponds to a binary tree of topics. A resulting tree may act as a containment hierarchy, typically with more general topics towards the root of tree and more specific topics towards the leaves. Topic Grouper is not governed by a background distribution such as the Dirichlet and avoids hyper parameter optimizations. We show that Topic Grouper has reasonable predictive power and also a reasonable theoretical and practical complexity. Topic Grouper can deal well with stop words and function words and tends to push them into their own topics. Also, it can handle topic distributions, where some topics are more frequent than others. We present typical examples of computed topics from evaluation datasets, where topics appear conclusive and coherent. In this context, the fact that each word belongs to exactly one topic is not a major limitation; in some scenarios this can even be a genuine advantage, e.g.~a related shopping basket analysis may aid in optimizing groupings of articles in sales catalogs.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022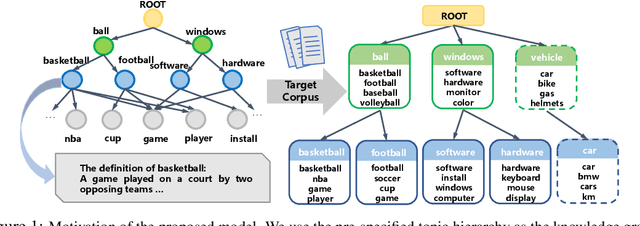
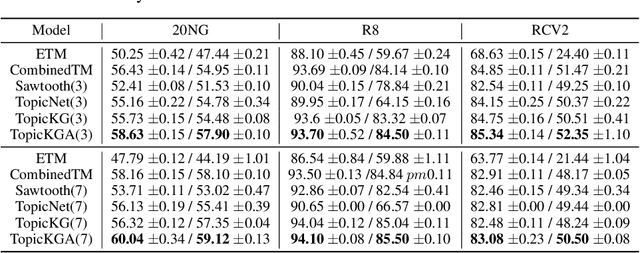
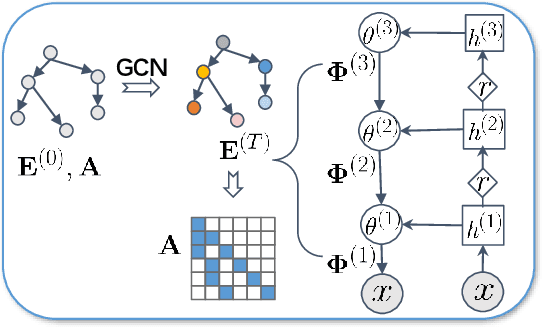

We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.
Open vs Closed-ended questions in attitudinal surveys -- comparing, combining, and interpreting using natural language processing
May 03, 2022
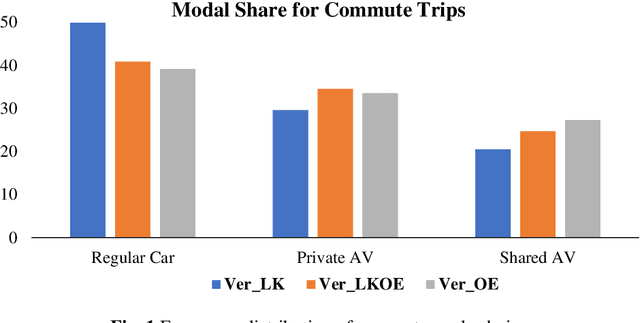
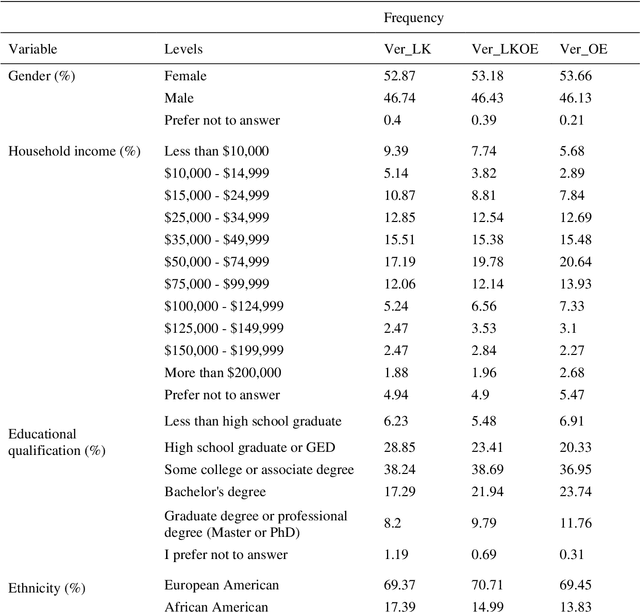
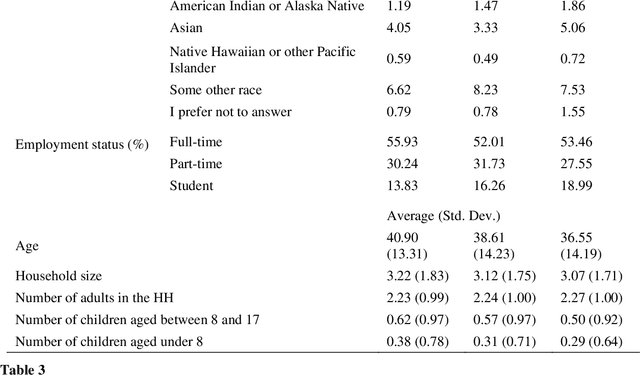
To improve the traveling experience, researchers have been analyzing the role of attitudes in travel behavior modeling. Although most researchers use closed-ended surveys, the appropriate method to measure attitudes is debatable. Topic Modeling could significantly reduce the time to extract information from open-ended responses and eliminate subjective bias, thereby alleviating analyst concerns. Our research uses Topic Modeling to extract information from open-ended questions and compare its performance with closed-ended responses. Furthermore, some respondents might prefer answering questions using their preferred questionnaire type. So, we propose a modeling framework that allows respondents to use their preferred questionnaire type to answer the survey and enable analysts to use the modeling frameworks of their choice to predict behavior. We demonstrate this using a dataset collected from the USA that measures the intention to use Autonomous Vehicles for commute trips. Respondents were presented with alternative questionnaire versions (open- and closed- ended). Since our objective was also to compare the performance of alternative questionnaire versions, the survey was designed to eliminate influences resulting from statements, behavioral framework, and the choice experiment. Results indicate the suitability of using Topic Modeling to extract information from open-ended responses; however, the models estimated using the closed-ended questions perform better compared to them. Besides, the proposed model performs better compared to the models used currently. Furthermore, our proposed framework will allow respondents to choose the questionnaire type to answer, which could be particularly beneficial to them when using voice-based surveys.
Twitter Topic Classification
Sep 20, 2022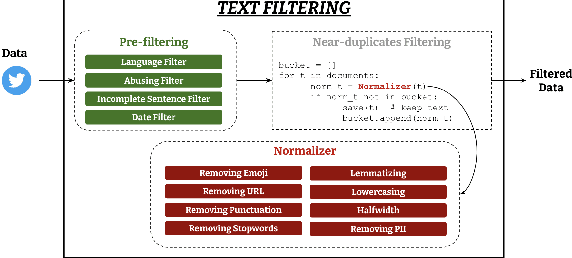


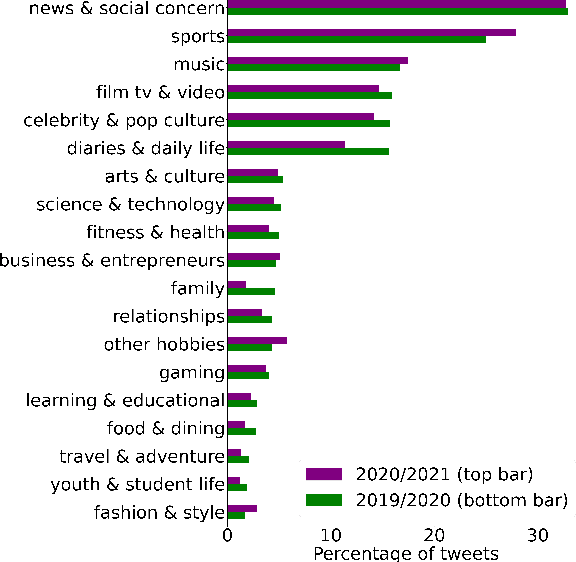
Social media platforms host discussions about a wide variety of topics that arise everyday. Making sense of all the content and organising it into categories is an arduous task. A common way to deal with this issue is relying on topic modeling, but topics discovered using this technique are difficult to interpret and can differ from corpus to corpus. In this paper, we present a new task based on tweet topic classification and release two associated datasets. Given a wide range of topics covering the most important discussion points in social media, we provide training and testing data from recent time periods that can be used to evaluate tweet classification models. Moreover, we perform a quantitative evaluation and analysis of current general- and domain-specific language models on the task, which provide more insights on the challenges and nature of the task.
Short Text Topic Modeling: Application to tweets about Bitcoin
Mar 17, 2022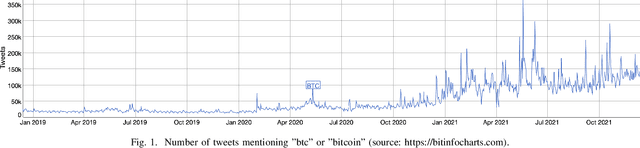

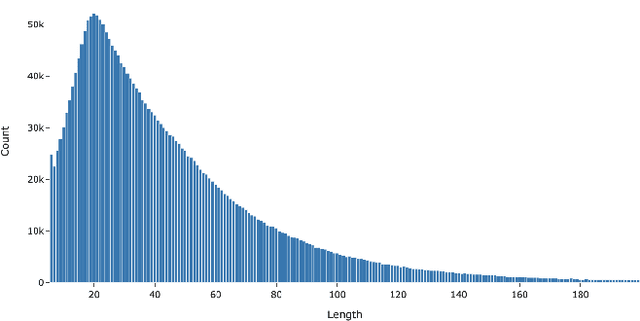
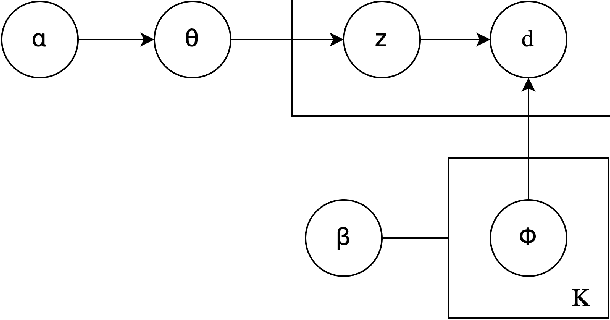
Understanding the semantic of a collection of texts is a challenging task. Topic models are probabilistic models that aims at extracting "topics" from a corpus of documents. This task is particularly difficult when the corpus is composed of short texts, such as posts on social networks. Following several previous research papers, we explore in this paper a set of collected tweets about bitcoin. In this work, we train three topic models and evaluate their output with several scores. We also propose a concrete application of the extracted topics.
Leveraging Natural Learning Processing to Uncover Themes in Clinical Notes of Patients Admitted for Heart Failure
Apr 14, 2022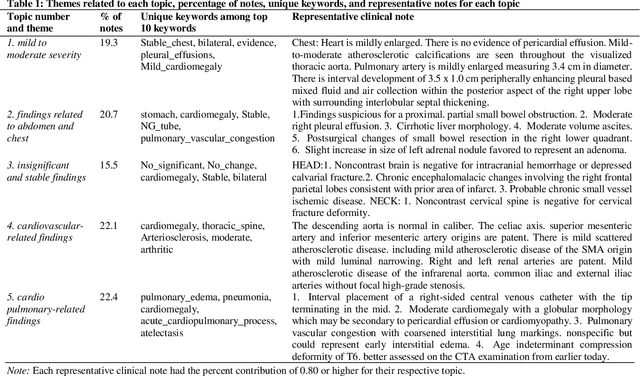
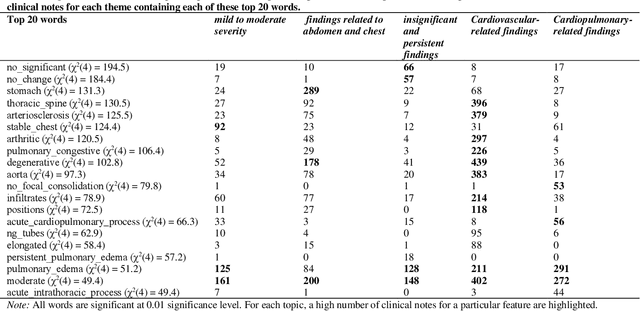
Heart failure occurs when the heart is not able to pump blood and oxygen to support other organs in the body as it should. Treatments include medications and sometimes hospitalization. Patients with heart failure can have both cardiovascular as well as non-cardiovascular comorbidities. Clinical notes of patients with heart failure can be analyzed to gain insight into the topics discussed in these notes and the major comorbidities in these patients. In this regard, we apply machine learning techniques, such as topic modeling, to identify the major themes found in the clinical notes specific to the procedures performed on 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling revealed five hidden themes in these clinical notes, including one related to heart disease comorbidities.
Recommendation System based on Semantic Scholar Mining and Topic modeling: A behavioral analysis of researchers from six conferences
Dec 20, 2018
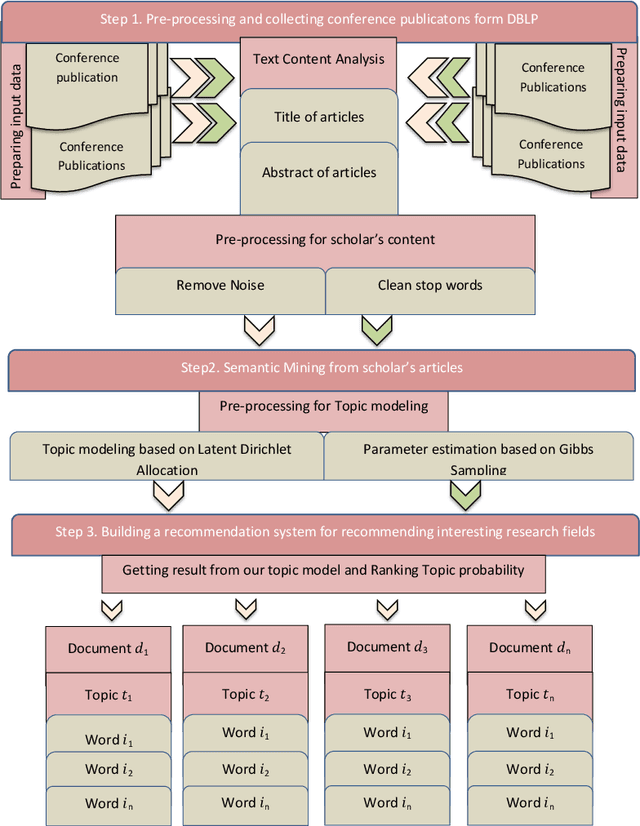
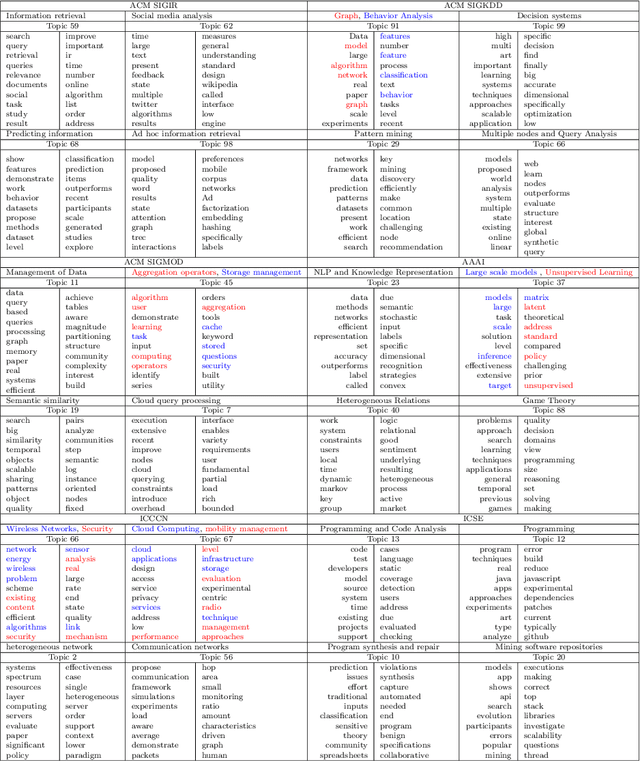
Recommendation systems have an important place to help online users in the internet society. Recommendation Systems in computer science are of very practical use these days in various aspects of the Internet portals, such as social networks, and library websites. There are several approaches to implement recommendation systems, Latent Dirichlet Allocation (LDA) is one the popular techniques in Topic Modeling. Recently, researchers have proposed many approaches based on Recommendation Systems and LDA. According to importance of the subject, in this paper we discover the trends of the topics and find relationship between LDA topics and Scholar-Context-documents. In fact, We apply probabilistic topic modeling based on Gibbs sampling algorithms for a semantic mining from six conference publications in computer science from DBLP dataset. According to our experimental results, our semantic framework can be effective to help organizations to better organize these conferences and cover future research topics.
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023
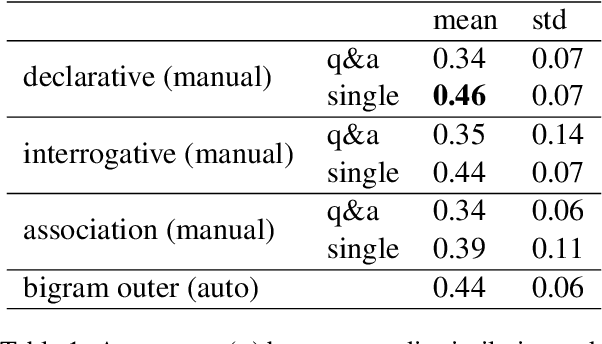

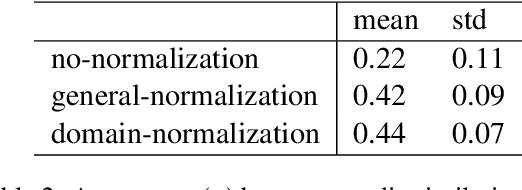
Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
Topic Modeling of Hierarchical Corpora
Apr 13, 2015



We study the problem of topic modeling in corpora whose documents are organized in a multi-level hierarchy. We explore a parametric approach to this problem, assuming that the number of topics is known or can be estimated by cross-validation. The models we consider can be viewed as special (finite-dimensional) instances of hierarchical Dirichlet processes (HDPs). For these models we show that there exists a simple variational approximation for probabilistic inference. The approximation relies on a previously unexploited inequality that handles the conditional dependence between Dirichlet latent variables in adjacent levels of the model's hierarchy. We compare our approach to existing implementations of nonparametric HDPs. On several benchmarks we find that our approach is faster than Gibbs sampling and able to learn more predictive models than existing variational methods. Finally, we demonstrate the large-scale viability of our approach on two newly available corpora from researchers in computer security---one with 350,000 documents and over 6,000 internal subcategories, the other with a five-level deep hierarchy.
Guided Semi-Supervised Non-negative Matrix Factorization on Legal Documents
Jan 31, 2022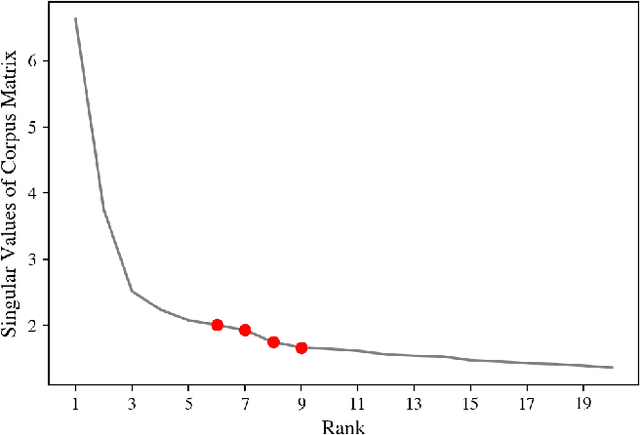
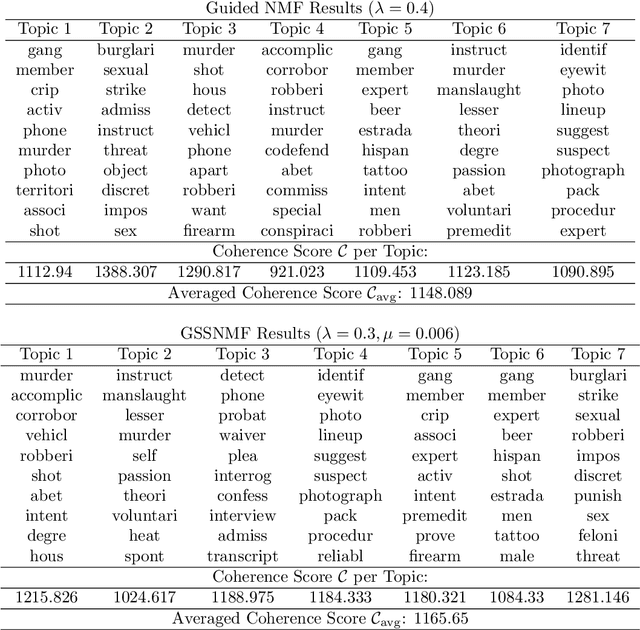
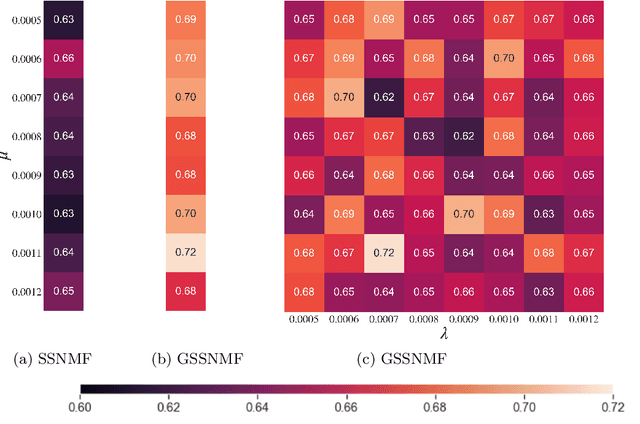
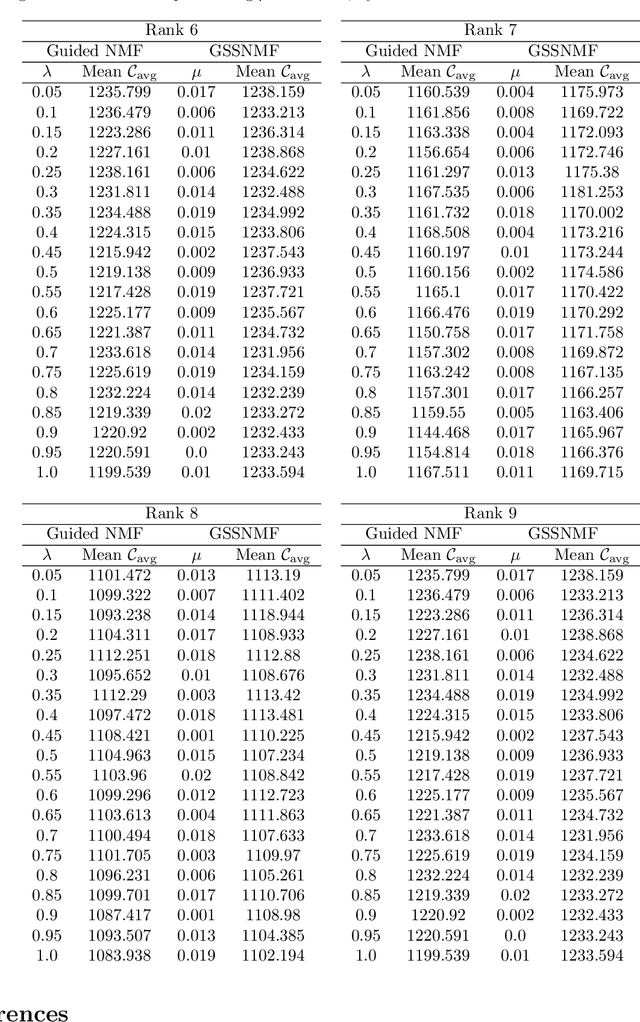
Classification and topic modeling are popular techniques in machine learning that extract information from large-scale datasets. By incorporating a priori information such as labels or important features, methods have been developed to perform classification and topic modeling tasks; however, most methods that can perform both do not allow for guidance of the topics or features. In this paper, we propose a method, namely Guided Semi-Supervised Non-negative Matrix Factorization (GSSNMF), that performs both classification and topic modeling by incorporating supervision from both pre-assigned document class labels and user-designed seed words. We test the performance of this method through its application to legal documents provided by the California Innocence Project, a nonprofit that works to free innocent convicted persons and reform the justice system. The results show that our proposed method improves both classification accuracy and topic coherence in comparison to past methods like Semi-Supervised Non-negative Matrix Factorization (SSNMF) and Guided Non-negative Matrix Factorization (Guided NMF).