 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
TAN-NTM: Topic Attention Networks for Neural Topic Modeling
Dec 02, 2020
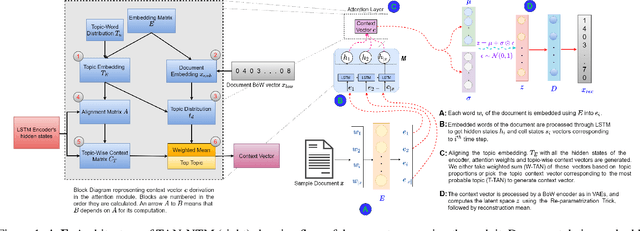
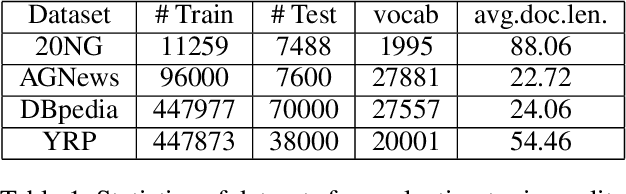
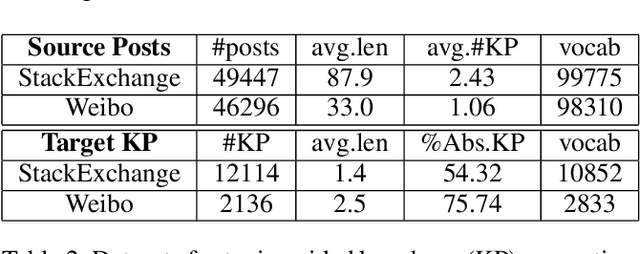

Topic models have been widely used to learn representations from text and gain insight into document corpora. To perform topic discovery, existing neural models use document bag-of-words (BoW) representation as input followed by variational inference and learn topic-word distribution through reconstructing BoW. Such methods have mainly focused on analysing the effect of enforcing suitable priors on document distribution. However, little importance has been given to encoding improved document features for capturing document semantics better. In this work, we propose a novel framework: TAN-NTM which models document as a sequence of tokens instead of BoW at the input layer and processes it through an LSTM whose output is used to perform variational inference followed by BoW decoding. We apply attention on LSTM outputs to empower the model to attend on relevant words which convey topic related cues. We hypothesise that attention can be performed effectively if done in a topic guided manner and establish this empirically through ablations. We factor in topic-word distribution to perform topic aware attention achieving state-of-the-art results with ~9-15 percentage improvement over score of existing SOTA topic models in NPMI coherence metric on four benchmark datasets - 20NewsGroup, Yelp, AGNews, DBpedia. TAN-NTM also obtains better document classification accuracy owing to learning improved document-topic features. We qualitatively discuss that attention mechanism enables unsupervised discovery of keywords. Motivated by this, we further show that our proposed framework achieves state-of-the-art performance on topic aware supervised generation of keyphrases on StackExchange and Weibo datasets.
Topic Modeling with Wasserstein Autoencoders
Jul 24, 2019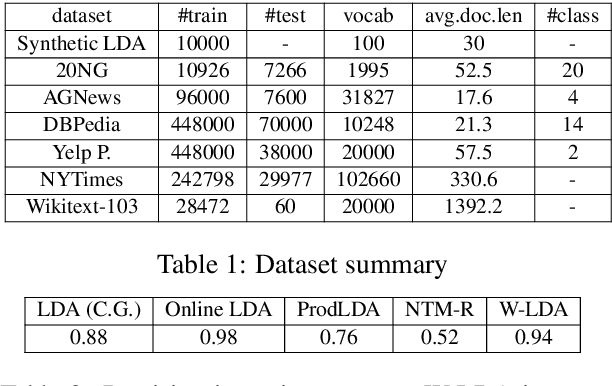
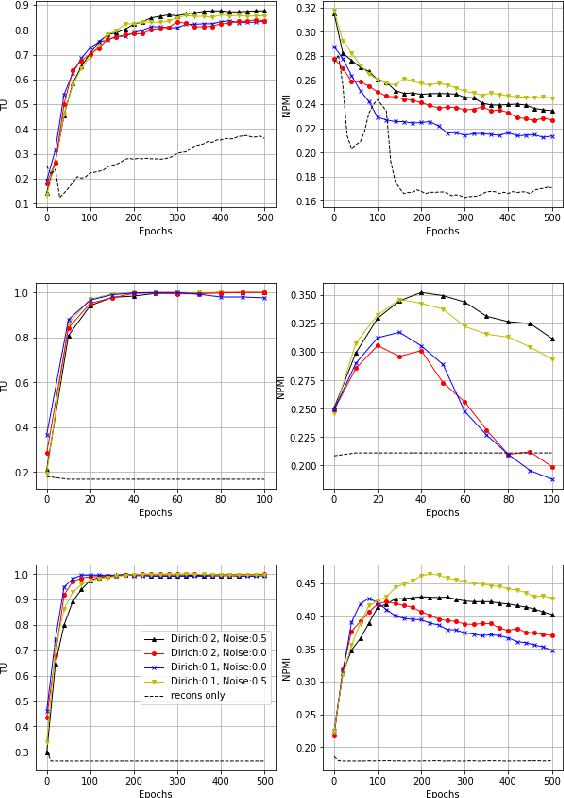
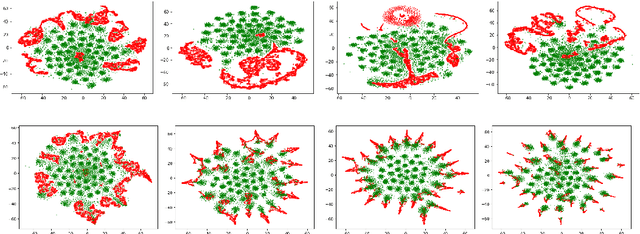

We propose a novel neural topic model in the Wasserstein autoencoders (WAE) framework. Unlike existing variational autoencoder based models, we directly enforce Dirichlet prior on the latent document-topic vectors. We exploit the structure of the latent space and apply a suitable kernel in minimizing the Maximum Mean Discrepancy (MMD) to perform distribution matching. We discover that MMD performs much better than the Generative Adversarial Network (GAN) in matching high dimensional Dirichlet distribution. We further discover that incorporating randomness in the encoder output during training leads to significantly more coherent topics. To measure the diversity of the produced topics, we propose a simple topic uniqueness metric. Together with the widely used coherence measure NPMI, we offer a more wholistic evaluation of topic quality. Experiments on several real datasets show that our model produces significantly better topics than existing topic models.
RATE: Overcoming Noise and Sparsity of Textual Features in Real-Time Location Estimation
Nov 12, 2021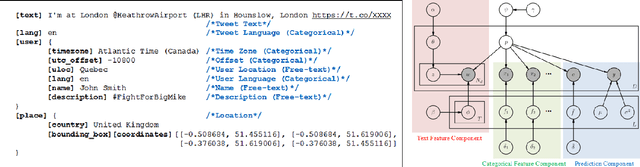
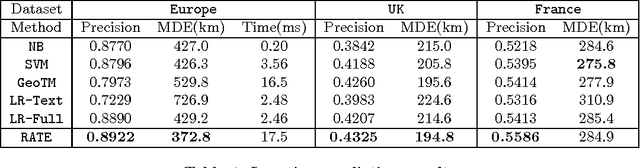
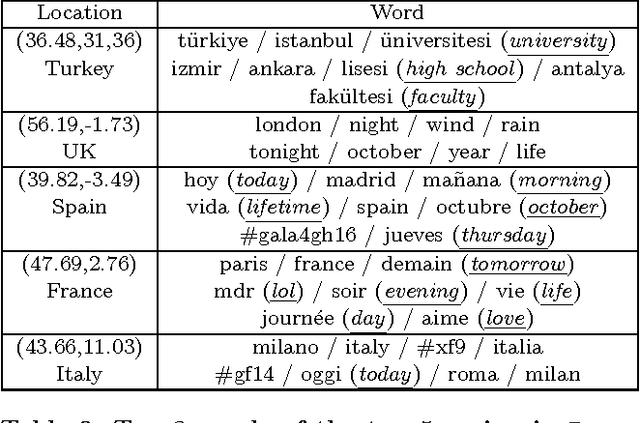
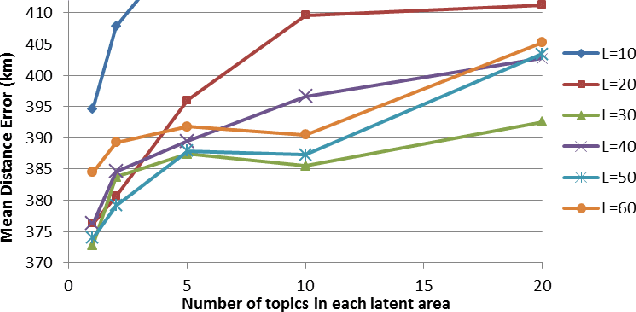
Real-time location inference of social media users is the fundamental of some spatial applications such as localized search and event detection. While tweet text is the most commonly used feature in location estimation, most of the prior works suffer from either the noise or the sparsity of textual features. In this paper, we aim to tackle these two problems. We use topic modeling as a building block to characterize the geographic topic variation and lexical variation so that "one-hot" encoding vectors will no longer be directly used. We also incorporate other features which can be extracted through the Twitter streaming API to overcome the noise problem. Experimental results show that our RATE algorithm outperforms several benchmark methods, both in the precision of region classification and the mean distance error of latitude and longitude regression.
Sequential Topic Selection Model with Latent Variable for Topic-Grounded Dialogue
Oct 17, 2022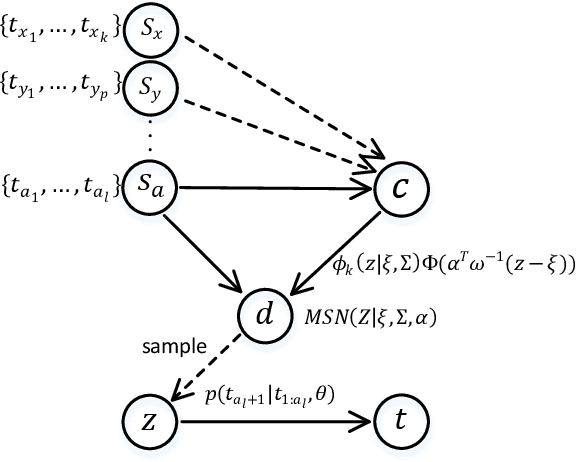
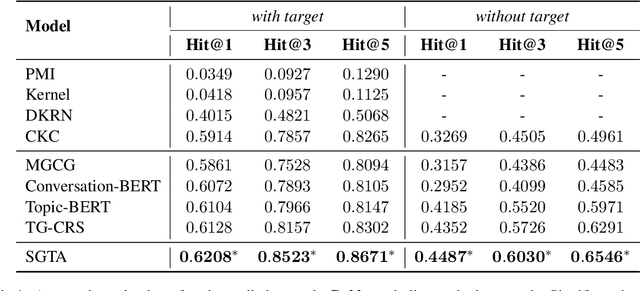
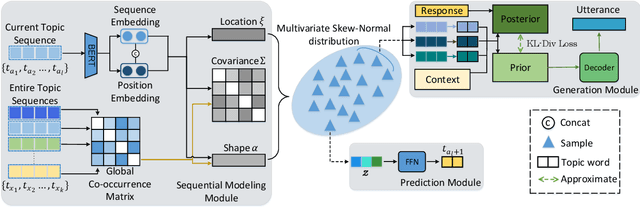
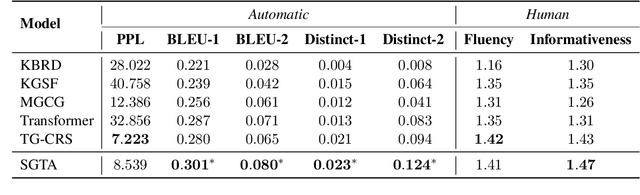
Recently, topic-grounded dialogue system has attracted significant attention due to its effectiveness in predicting the next topic to yield better responses via the historical context and given topic sequence. However, almost all existing topic prediction solutions focus on only the current conversation and corresponding topic sequence to predict the next conversation topic, without exploiting other topic-guided conversations which may contain relevant topic-transitions to current conversation. To address the problem, in this paper we propose a novel approach, named Sequential Global Topic Attention (SGTA) to exploit topic transition over all conversations in a subtle way for better modeling post-to-response topic-transition and guiding the response generation to the current conversation. Specifically, we introduce a latent space modeled as a Multivariate Skew-Normal distribution with hybrid kernel functions to flexibly integrate the global-level information with sequence-level information, and predict the topic based on the distribution sampling results. We also leverage a topic-aware prior-posterior approach for secondary selection of predicted topics, which is utilized to optimize the response generation task. Extensive experiments demonstrate that our model outperforms competitive baselines on prediction and generation tasks.
What is Wrong with Topic Modeling? (and How to Fix it Using Search-based Software Engineering)
Feb 20, 2018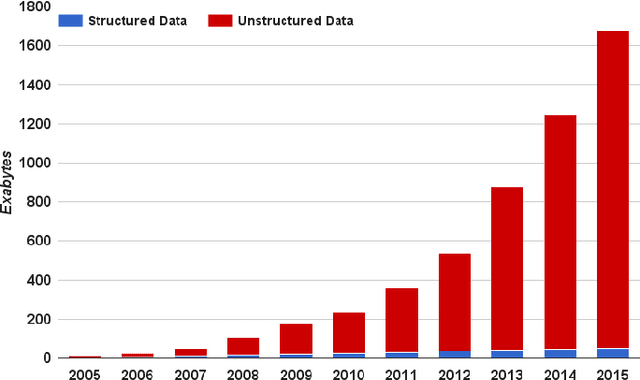
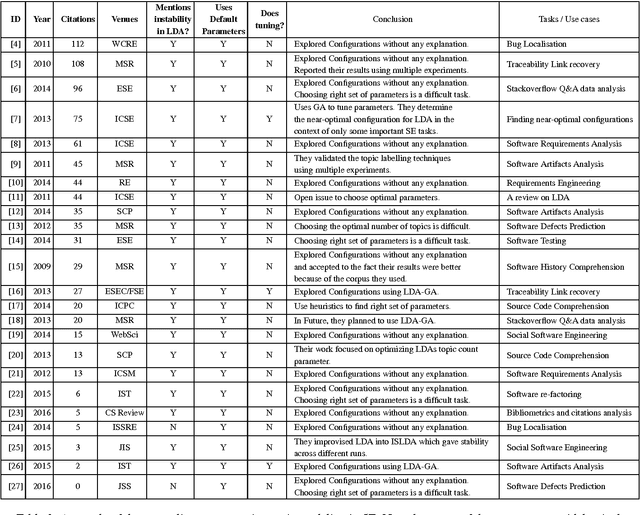

Context: Topic modeling finds human-readable structures in unstructured textual data. A widely used topic modeler is Latent Dirichlet allocation. When run on different datasets, LDA suffers from "order effects" i.e. different topics are generated if the order of training data is shuffled. Such order effects introduce a systematic error for any study. This error can relate to misleading results;specifically, inaccurate topic descriptions and a reduction in the efficacy of text mining classification results. Objective: To provide a method in which distributions generated by LDA are more stable and can be used for further analysis. Method: We use LDADE, a search-based software engineering tool that tunes LDA's parameters using DE (Differential Evolution). LDADE is evaluated on data from a programmer information exchange site (Stackoverflow), title and abstract text of thousands ofSoftware Engineering (SE) papers, and software defect reports from NASA. Results were collected across different implementations of LDA (Python+Scikit-Learn, Scala+Spark); across different platforms (Linux, Macintosh) and for different kinds of LDAs (VEM,or using Gibbs sampling). Results were scored via topic stability and text mining classification accuracy. Results: In all treatments: (i) standard LDA exhibits very large topic instability; (ii) LDADE's tunings dramatically reduce cluster instability; (iii) LDADE also leads to improved performances for supervised as well as unsupervised learning. Conclusion: Due to topic instability, using standard LDA with its "off-the-shelf" settings should now be depreciated. Also, in future, we should require SE papers that use LDA to test and (if needed) mitigate LDA topic instability. Finally, LDADE is a candidate technology for effectively and efficiently reducing that instability.
* 15 pages + 2 page references. Accepted to IST
A Coefficient of Determination for Probabilistic Topic Models
Nov 26, 2019
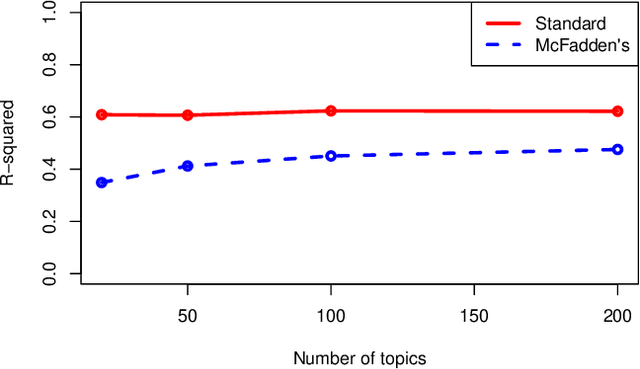
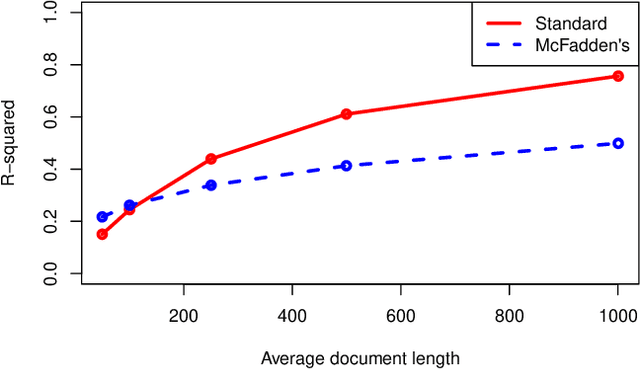
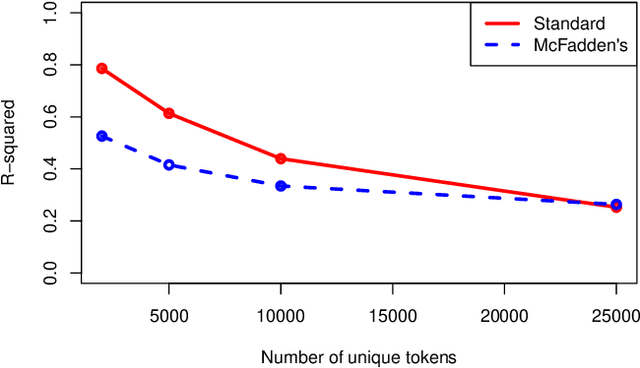
This research proposes a new (old) metric for evaluating goodness of fit in topic models, the coefficient of determination, or $R^2$. Within the context of topic modeling, $R^2$ has the same interpretation that it does when used in a broader class of statistical models. Reporting $R^2$ with topic models addresses two current problems in topic modeling: a lack of standard cross-contextual evaluation metrics for topic modeling and ease of communication with lay audiences. The author proposes that $R^2$ should be reported as a standard metric when constructing topic models.
Temporal Analysis on Topics Using Word2Vec
Sep 23, 2022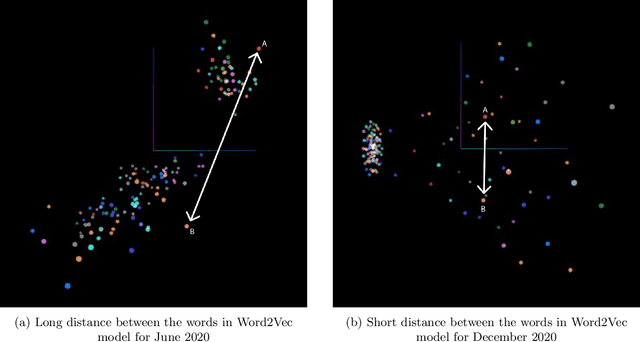

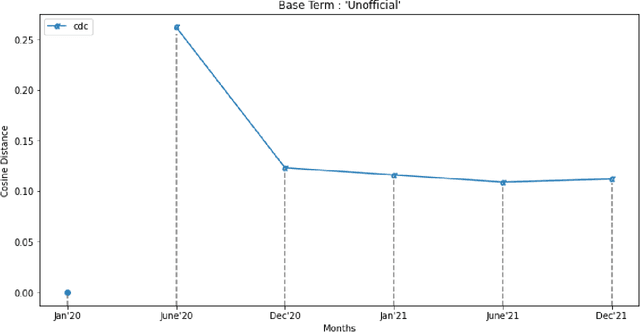
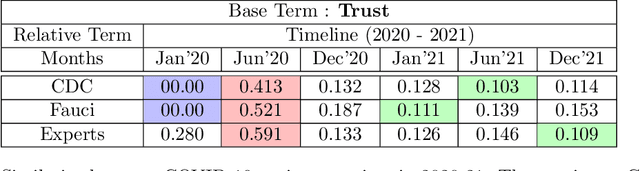
The present study proposes a novel method of trend detection and visualization - more specifically, modeling the change in a topic over time. Where current models used for the identification and visualization of trends only convey the popularity of a singular word based on stochastic counting of usage, the approach in the present study illustrates the popularity and direction that a topic is moving in. The direction in this case is a distinct subtopic within the selected corpus. Such trends are generated by modeling the movement of a topic by using k-means clustering and cosine similarity to group the distances between clusters over time. In a convergent scenario, it can be inferred that the topics as a whole are meshing (tokens between topics, becoming interchangeable). On the contrary, a divergent scenario would imply that each topics' respective tokens would not be found in the same context (the words are increasingly different to each other). The methodology was tested on a group of articles from various media houses present in the 20 Newsgroups dataset.
A Generalized Hierarchical Nonnegative Tensor Decomposition
Sep 30, 2021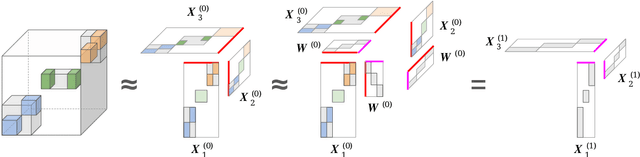
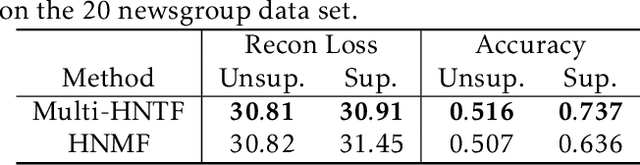
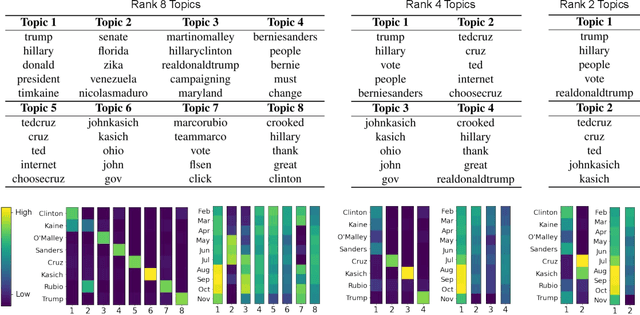
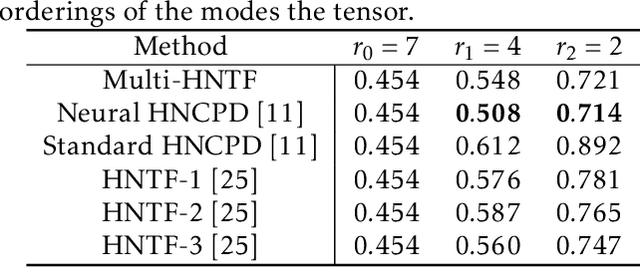
Nonnegative matrix factorization (NMF) has found many applications including topic modeling and document analysis. Hierarchical NMF (HNMF) variants are able to learn topics at various levels of granularity and illustrate their hierarchical relationship. Recently, nonnegative tensor factorization (NTF) methods have been applied in a similar fashion in order to handle data sets with complex, multi-modal structure. Hierarchical NTF (HNTF) methods have been proposed, however these methods do not naturally generalize their matrix-based counterparts. Here, we propose a new HNTF model which directly generalizes a HNMF model special case, and provide a supervised extension. We also provide a multiplicative updates training method for this model. Our experimental results show that this model more naturally illuminates the topic hierarchy than previous HNMF and HNTF methods.
Discriminative Topic Modeling with Logistic LDA
Sep 03, 2019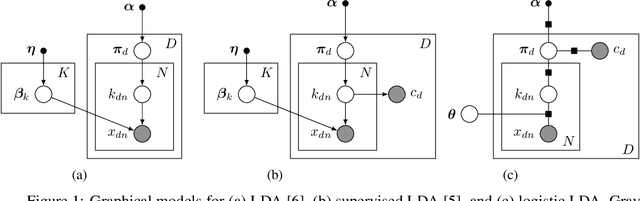


Despite many years of research into latent Dirichlet allocation (LDA), applying LDA to collections of non-categorical items is still challenging. Yet many problems with much richer data share a similar structure and could benefit from the vast literature on LDA. We propose logistic LDA, a novel discriminative variant of latent Dirichlet allocation which is easy to apply to arbitrary inputs. In particular, our model can easily be applied to groups of images, arbitrary text embeddings, and integrate well with deep neural networks. Although it is a discriminative model, we show that logistic LDA can learn from unlabeled data in an unsupervised manner by exploiting the group structure present in the data. In contrast to other recent topic models designed to handle arbitrary inputs, our model does not sacrifice the interpretability and principled motivation of LDA.