 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs AI different for SE?
Dec 09, 2019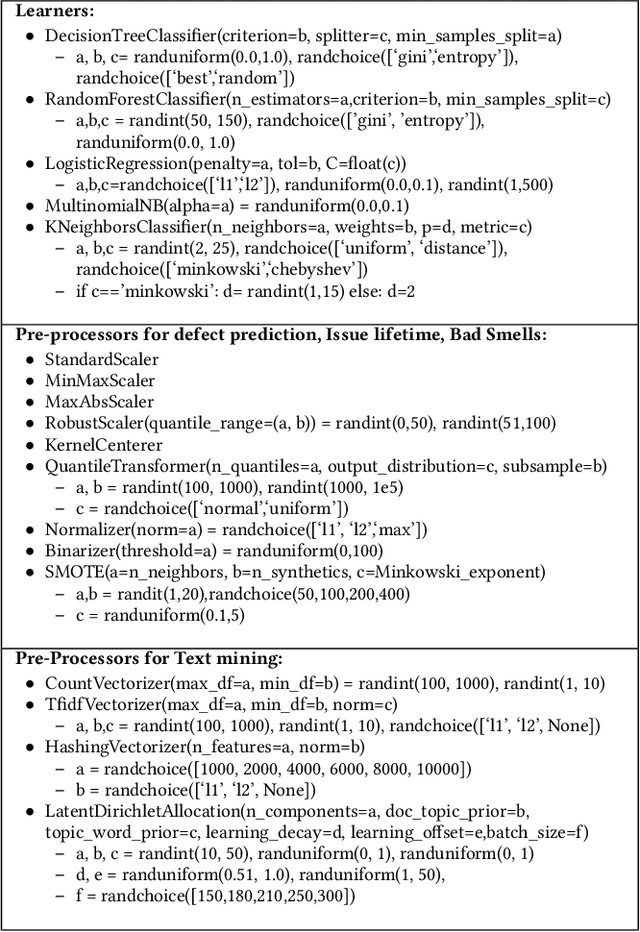
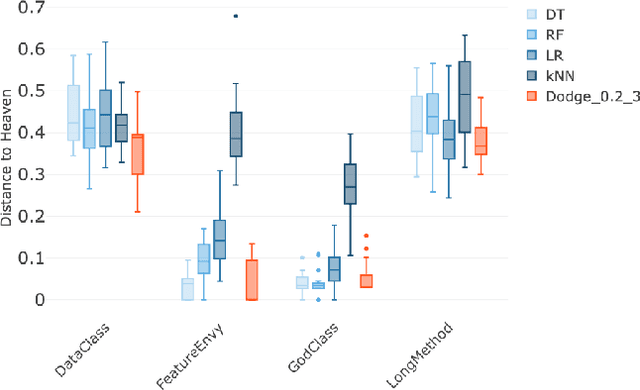
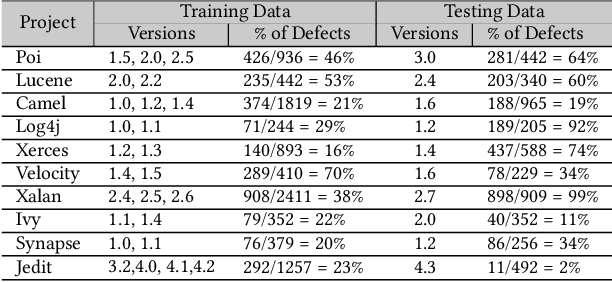
What AI tools are needed for SE? Ideally, we should have simple rules that peek at data, then say "use this tool" or "use that tool". To find such a rule, we explored 120 different data sets addressing numerous problems, including bad smell detection, predicting Github issue close time, bug report analysis, defect prediction and dozens of other non-SE problems. To this data, we apply a SE-based tool that (a)~out-performs the state-of-the-art for these SE problems yet (b)~fails very badly on standard AI problems. In those results, we can find a simple rule for when to use/avoid the SE-based tool. SE data is often about infrequent issues, like the occasional defect, or the rarely exploited security violation, or the requirement that holds for one special case. But as we show, standard AI tools work best when the target is relatively more frequent. Also, we can exploit these special properties of SE, to great effect (to rapidly find better optimizations for SE tasks via a tactic called "dodging", explained in this paper). More generally, this result says we need a new kind of SE research for developing new AI tools that are more suited to SE problems.
How to "DODGE" Complex Software Analytics?
Feb 05, 2019
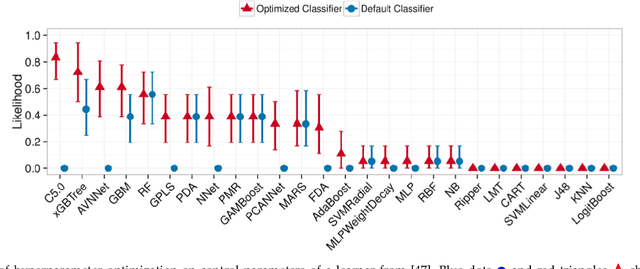

AI software is still software. Software engineers need better tools to make better use of AI software. For example, for software defect prediction and software text mining, the default tunings for software analytics tools can be improved with "hyperparameter optimization" tools that decide (e.g.,) how many trees are needed in a random forest. Hyperparameter optimization is unnecessarily slow when optimizers waste time exploring redundant options (i.e., pairs of tunings with indistinguishably different results). By ignoring redundant tunings, the Dodge(E) hyperparameter optimization tool can run orders of magnitude faster, yet still find better tunings than prior state-of-the-art algorithms (for software defect prediction and software text mining).
What is Wrong with Topic Modeling? (and How to Fix it Using Search-based Software Engineering)
Feb 20, 2018
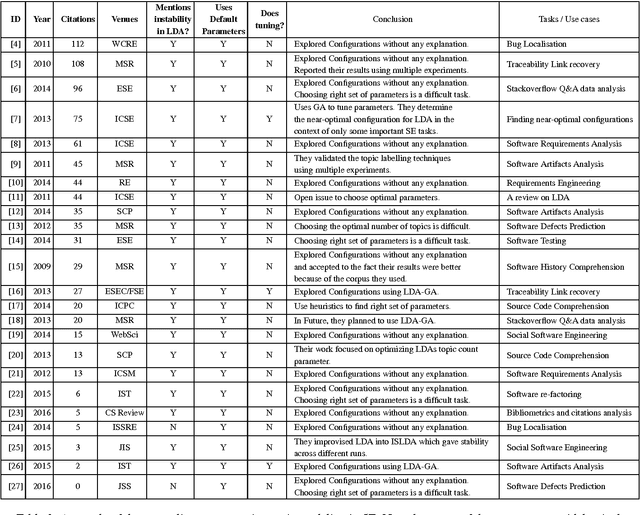

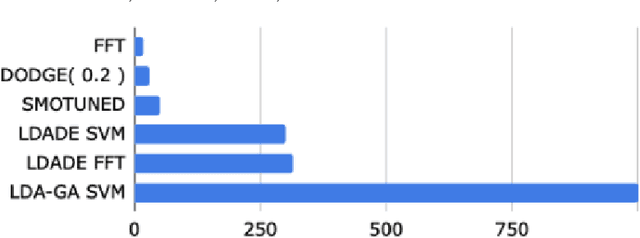
Context: Topic modeling finds human-readable structures in unstructured textual data. A widely used topic modeler is Latent Dirichlet allocation. When run on different datasets, LDA suffers from "order effects" i.e. different topics are generated if the order of training data is shuffled. Such order effects introduce a systematic error for any study. This error can relate to misleading results;specifically, inaccurate topic descriptions and a reduction in the efficacy of text mining classification results. Objective: To provide a method in which distributions generated by LDA are more stable and can be used for further analysis. Method: We use LDADE, a search-based software engineering tool that tunes LDA's parameters using DE (Differential Evolution). LDADE is evaluated on data from a programmer information exchange site (Stackoverflow), title and abstract text of thousands ofSoftware Engineering (SE) papers, and software defect reports from NASA. Results were collected across different implementations of LDA (Python+Scikit-Learn, Scala+Spark); across different platforms (Linux, Macintosh) and for different kinds of LDAs (VEM,or using Gibbs sampling). Results were scored via topic stability and text mining classification accuracy. Results: In all treatments: (i) standard LDA exhibits very large topic instability; (ii) LDADE's tunings dramatically reduce cluster instability; (iii) LDADE also leads to improved performances for supervised as well as unsupervised learning. Conclusion: Due to topic instability, using standard LDA with its "off-the-shelf" settings should now be depreciated. Also, in future, we should require SE papers that use LDA to test and (if needed) mitigate LDA topic instability. Finally, LDADE is a candidate technology for effectively and efficiently reducing that instability.
* 15 pages + 2 page references. Accepted to IST