 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Anytime Algorithm for Good Arm Identification
Oct 16, 2023
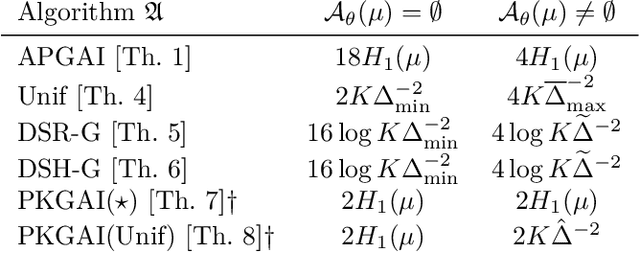
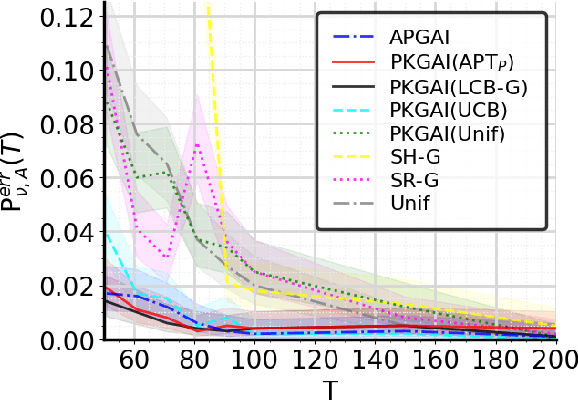

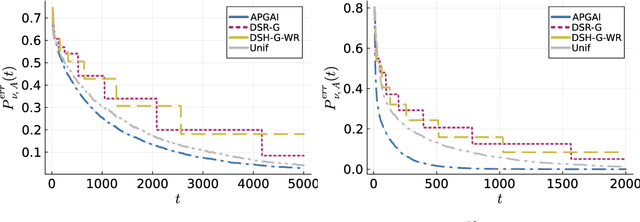
In good arm identification (GAI), the goal is to identify one arm whose average performance exceeds a given threshold, referred to as good arm, if it exists. Few works have studied GAI in the fixed-budget setting, when the sampling budget is fixed beforehand, or the anytime setting, when a recommendation can be asked at any time. We propose APGAI, an anytime and parameter-free sampling rule for GAI in stochastic bandits. APGAI can be straightforwardly used in fixed-confidence and fixed-budget settings. First, we derive upper bounds on its probability of error at any time. They show that adaptive strategies are more efficient in detecting the absence of good arms than uniform sampling. Second, when APGAI is combined with a stopping rule, we prove upper bounds on the expected sampling complexity, holding at any confidence level. Finally, we show good empirical performance of APGAI on synthetic and real-world data. Our work offers an extensive overview of the GAI problem in all settings.
Active Sensing for Localization with Reconfigurable Intelligent Surface
Oct 19, 2023This paper addresses an uplink localization problem in which the base station (BS) aims to locate a remote user with the aid of reconfigurable intelligent surface (RIS). This paper proposes a strategy in which the user transmits pilots over multiple time frames, and the BS adaptively adjusts the RIS reflection coefficients based on the observations already received so far in order to produce an accurate estimate of the user location at the end. This is a challenging active sensing problem for which finding an optimal solution involves a search through a complicated functional space whose dimension increases with the number of measurements. In this paper, we show that the long short-term memory (LSTM) network can be used to exploit the latent temporal correlation between measurements to automatically construct scalable information vectors (called hidden state) based on the measurements. Subsequently, the state vector can be mapped to the RIS configuration for the next time frame in a codebook-free fashion via a deep neural network (DNN). After all the measurements have been received, a final DNN can be used to map the LSTM cell state to the estimated user equipment (UE) position. Numerical result shows that the proposed active RIS design results in lower localization error as compared to existing active and nonactive methods. The proposed solution produces interpretable results and is generalizable to early stopping in the sequence of sensing stages.
Match-And-Deform: Time Series Domain Adaptation through Optimal Transport and Temporal Alignment
Aug 24, 2023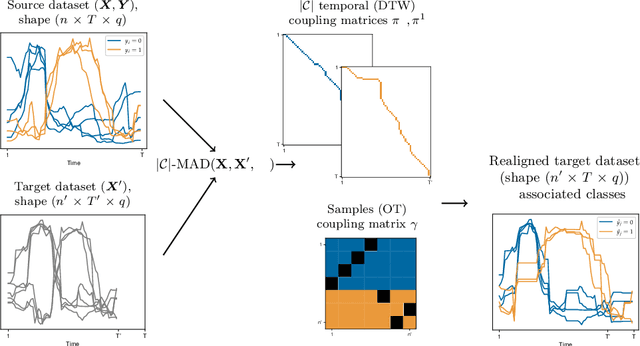
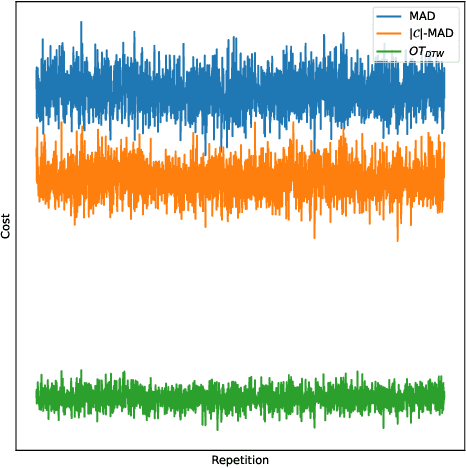
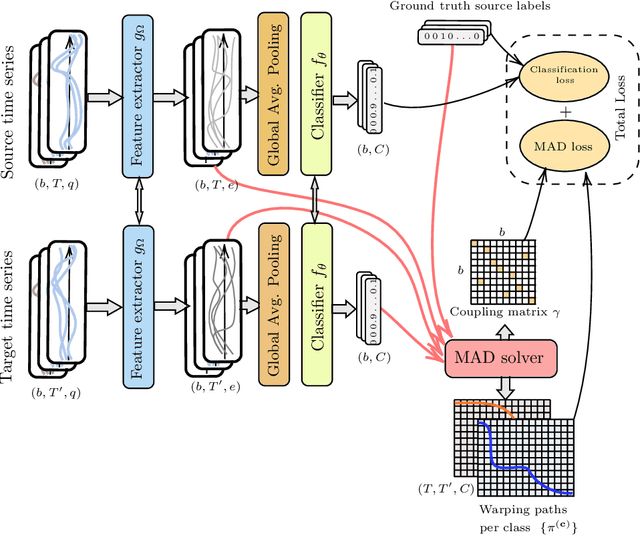
While large volumes of unlabeled data are usually available, associated labels are often scarce. The unsupervised domain adaptation problem aims at exploiting labels from a source domain to classify data from a related, yet different, target domain. When time series are at stake, new difficulties arise as temporal shifts may appear in addition to the standard feature distribution shift. In this paper, we introduce the Match-And-Deform (MAD) approach that aims at finding correspondences between the source and target time series while allowing temporal distortions. The associated optimization problem simultaneously aligns the series thanks to an optimal transport loss and the time stamps through dynamic time warping. When embedded into a deep neural network, MAD helps learning new representations of time series that both align the domains and maximize the discriminative power of the network. Empirical studies on benchmark datasets and remote sensing data demonstrate that MAD makes meaningful sample-to-sample pairing and time shift estimation, reaching similar or better classification performance than state-of-the-art deep time series domain adaptation strategies.
Analysing State-Backed Propaganda Websites: a New Dataset and Linguistic Study
Oct 21, 2023This paper analyses two hitherto unstudied sites sharing state-backed disinformation, Reliable Recent News (rrn.world) and WarOnFakes (waronfakes.com), which publish content in Arabic, Chinese, English, French, German, and Spanish. We describe our content acquisition methodology and perform cross-site unsupervised topic clustering on the resulting multilingual dataset. We also perform linguistic and temporal analysis of the web page translations and topics over time, and investigate articles with false publication dates. We make publicly available this new dataset of 14,053 articles, annotated with each language version, and additional metadata such as links and images. The main contribution of this paper for the NLP community is in the novel dataset which enables studies of disinformation networks, and the training of NLP tools for disinformation detection.
Fast Approximation of Similarity Graphs with Kernel Density Estimation
Oct 21, 2023Constructing a similarity graph from a set $X$ of data points in $\mathbb{R}^d$ is the first step of many modern clustering algorithms. However, typical constructions of a similarity graph have high time complexity, and a quadratic space dependency with respect to $|X|$. We address this limitation and present a new algorithmic framework that constructs a sparse approximation of the fully connected similarity graph while preserving its cluster structure. Our presented algorithm is based on the kernel density estimation problem, and is applicable for arbitrary kernel functions. We compare our designed algorithm with the well-known implementations from the scikit-learn library and the FAISS library, and find that our method significantly outperforms the implementation from both libraries on a variety of datasets.
Learning-based Scheduling for Information Accuracy and Freshness in Wireless Networks
Oct 24, 2023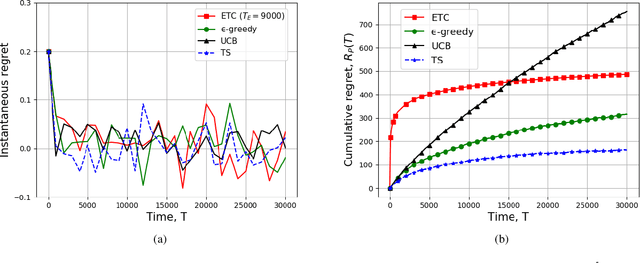
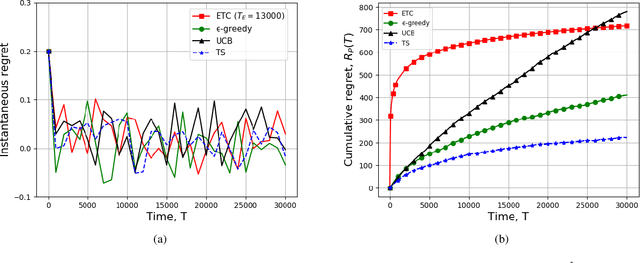
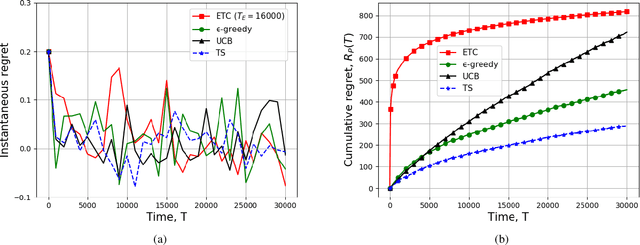
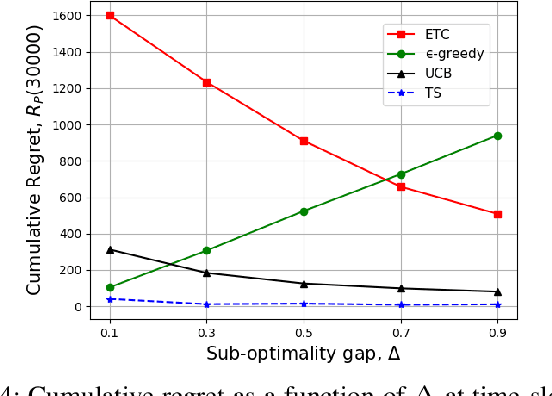
We consider a system of multiple sources, a single communication channel, and a single monitoring station. Each source measures a time-varying quantity with varying levels of accuracy and one of them sends its update to the monitoring station via the channel. The probability of success of each attempted communication is a function of the source scheduled for transmitting its update. Both the probability of correct measurement and the probability of successful transmission of all the sources are unknown to the scheduler. The metric of interest is the reward received by the system which depends on the accuracy of the last update received by the destination and the Age-of-Information (AoI) of the system. We model our scheduling problem as a variant of the multi-arm bandit problem with sources as different arms. We compare the performance of all $4$ standard bandit policies, namely, ETC, $\epsilon$-greedy, UCB, and TS suitably adjusted to our system model via simulations. In addition, we provide analytical guarantees of $2$ of these policies, ETC, and $\epsilon$-greedy. Finally, we characterize the lower bound on the cumulative regret achievable by any policy.
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Oct 24, 2023Traditional pruning methods are known to be challenging to work in Large Language Models (LLMs) for Generative AI because of their unaffordable training process and large computational demands. For the first time, we introduce the information entropy of hidden state features into a pruning metric design, namely E-Sparse, to improve the accuracy of N:M sparsity on LLM. E-Sparse employs the information richness to leverage the channel importance, and further incorporates several novel techniques to put it into effect: (1) it introduces information entropy to enhance the significance of parameter weights and input feature norms as a novel pruning metric, and performs N:M sparsity without modifying the remaining weights. (2) it designs global naive shuffle and local block shuffle to quickly optimize the information distribution and adequately cope with the impact of N:M sparsity on LLMs' accuracy. E-Sparse is implemented as a Sparse-GEMM on FasterTransformer and runs on NVIDIA Ampere GPUs. Extensive experiments on the LLaMA family and OPT models show that E-Sparse can significantly speed up the model inference over the dense model (up to 1.53X) and obtain significant memory saving (up to 43.52%), with acceptable accuracy loss.
Grid Frequency Forecasting in University Campuses using Convolutional LSTM
Oct 24, 2023The modern power grid is facing increasing complexities, primarily stemming from the integration of renewable energy sources and evolving consumption patterns. This paper introduces an innovative methodology that harnesses Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks to establish robust time series forecasting models for grid frequency. These models effectively capture the spatiotemporal intricacies inherent in grid frequency data, significantly enhancing prediction accuracy and bolstering power grid reliability. The research explores the potential and development of individualized Convolutional LSTM (ConvLSTM) models for buildings within a university campus, enabling them to be independently trained and evaluated for each building. Individual ConvLSTM models are trained on power consumption data for each campus building and forecast the grid frequency based on historical trends. The results convincingly demonstrate the superiority of the proposed models over traditional forecasting techniques, as evidenced by performance metrics such as Mean Square Error (MSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE). Additionally, an Ensemble Model is formulated to aggregate insights from the building-specific models, delivering comprehensive forecasts for the entire campus. This approach ensures the privacy and security of power consumption data specific to each building.
Elucidating the solution space of extended reverse-time SDE for diffusion models
Sep 12, 2023



Diffusion models (DMs) demonstrate potent image generation capabilities in various generative modeling tasks. Nevertheless, their primary limitation lies in slow sampling speed, requiring hundreds or thousands of sequential function evaluations through large neural networks to generate high-quality images. Sampling from DMs can be seen as solving corresponding stochastic differential equations (SDEs) or ordinary differential equations (ODEs). In this work, we formulate the sampling process as an extended reverse-time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and arbitrarily high-order approximate solutions for VP SDE and VE SDE, respectively. Based on the solution space of the ER SDE, we yield mathematical insights elucidating the superior performance of ODE solvers over SDE solvers in terms of fast sampling. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Finally, we devise fast and training-free samplers, ER-SDE Solvers, elevating the efficiency of stochastic samplers to unprecedented levels. Experimental results demonstrate achieving 3.45 FID in 20 function evaluations and 2.24 FID in 50 function evaluations on the ImageNet 64$\times$64 dataset.
Evaluating sleep-stage classification: how age and early-late sleep affects classification performance
Oct 20, 2023Sleep stage classification is a common method used by experts to monitor the quantity and quality of sleep in humans, but it is a time-consuming and labour-intensive task with high inter- and intra-observer variability. Using Wavelets for feature extraction and Random Forest for classification, an automatic sleep-stage classification method was sought and assessed. The age of the subjects, as well as the moment of sleep (early-night and late-night), were confronted to the performance of the classifier. From this study, we observed that these variables do affect the automatic model performance, improving the classification of some sleep stages and worsening others.