 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning from Multimodal and Multitemporal Earth Observation Data for Building Damage Mapping
Sep 14, 2020
Earth observation technologies, such as optical imaging and synthetic aperture radar (SAR), provide excellent means to monitor ever-growing urban environments continuously. Notably, in the case of large-scale disasters (e.g., tsunamis and earthquakes), in which a response is highly time-critical, images from both data modalities can complement each other to accurately convey the full damage condition in the disaster's aftermath. However, due to several factors, such as weather and satellite coverage, it is often uncertain which data modality will be the first available for rapid disaster response efforts. Hence, novel methodologies that can utilize all accessible EO datasets are essential for disaster management. In this study, we have developed a global multisensor and multitemporal dataset for building damage mapping. We included building damage characteristics from three disaster types, namely, earthquakes, tsunamis, and typhoons, and considered three building damage categories. The global dataset contains high-resolution optical imagery and high-to-moderate-resolution multiband SAR data acquired before and after each disaster. Using this comprehensive dataset, we analyzed five data modality scenarios for damage mapping: single-mode (optical and SAR datasets), cross-modal (pre-disaster optical and post-disaster SAR datasets), and mode fusion scenarios. We defined a damage mapping framework for the semantic segmentation of damaged buildings based on a deep convolutional neural network algorithm. We compare our approach to another state-of-the-art baseline model for damage mapping. The results indicated that our dataset, together with a deep learning network, enabled acceptable predictions for all the data modality scenarios.
Are Neural Open-Domain Dialog Systems Robust to Speech Recognition Errors in the Dialog History? An Empirical Study
Aug 18, 2020
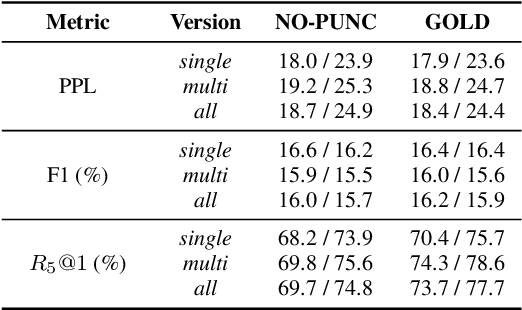

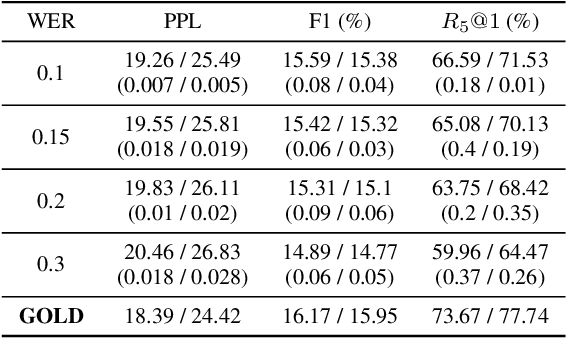
Large end-to-end neural open-domain chatbots are becoming increasingly popular. However, research on building such chatbots has typically assumed that the user input is written in nature and it is not clear whether these chatbots would seamlessly integrate with automatic speech recognition (ASR) models to serve the speech modality. We aim to bring attention to this important question by empirically studying the effects of various types of synthetic and actual ASR hypotheses in the dialog history on TransferTransfo, a state-of-the-art Generative Pre-trained Transformer (GPT) based neural open-domain dialog system from the NeurIPS ConvAI2 challenge. We observe that TransferTransfo trained on written data is very sensitive to such hypotheses introduced to the dialog history during inference time. As a baseline mitigation strategy, we introduce synthetic ASR hypotheses to the dialog history during training and observe marginal improvements, demonstrating the need for further research into techniques to make end-to-end open-domain chatbots fully speech-robust. To the best of our knowledge, this is the first study to evaluate the effects of synthetic and actual ASR hypotheses on a state-of-the-art neural open-domain dialog system and we hope it promotes speech-robustness as an evaluation criterion in open-domain dialog.
Interleaved Sequence RNNs for Fraud Detection
Feb 14, 2020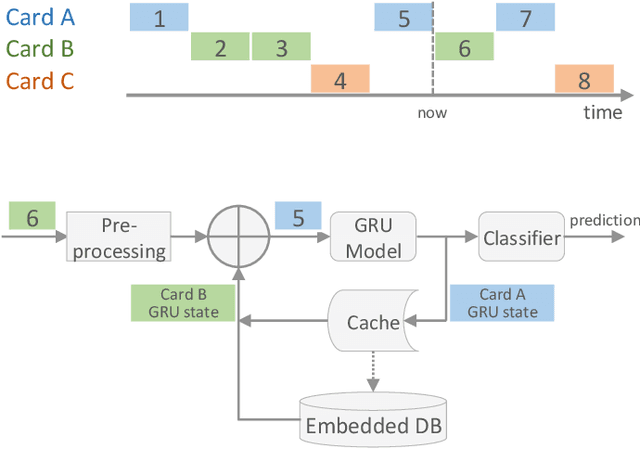

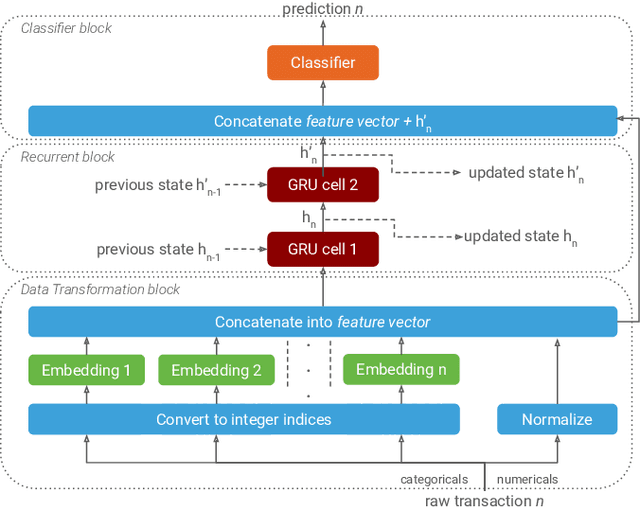
Payment card fraud causes multibillion dollar losses for banks and merchants worldwide, often fueling complex criminal activities. To address this, many real-time fraud detection systems use tree-based models, demanding complex feature engineering systems to efficiently enrich transactions with historical data while complying with millisecond-level latencies. In this work, we do not require those expensive features by using recurrent neural networks and treating payments as an interleaved sequence, where the history of each card is an unbounded, irregular sub-sequence. We present a complete RNN framework to detect fraud in real-time, proposing an efficient ML pipeline from preprocessing to deployment. We show that these feature-free, multi-sequence RNNs outperform state-of-the-art models saving millions of dollars in fraud detection and using fewer computational resources.
Assessing Centrality Without Knowing Connections
May 28, 2020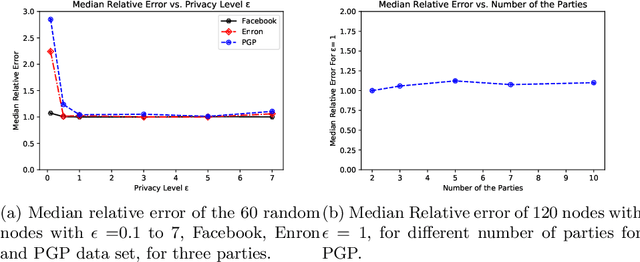
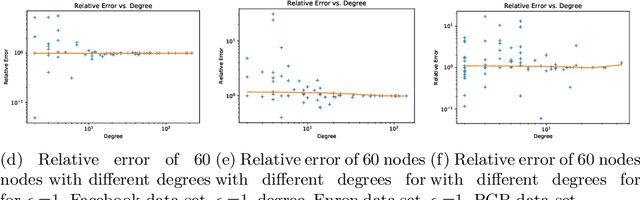
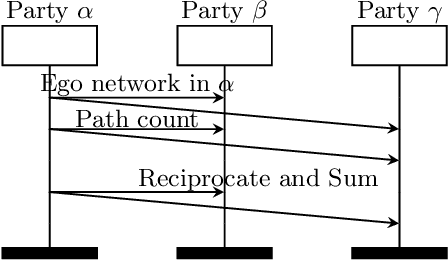
We consider the privacy-preserving computation of node influence in distributed social networks, as measured by egocentric betweenness centrality (EBC). Motivated by modern communication networks spanning multiple providers, we show for the first time how multiple mutually-distrusting parties can successfully compute node EBC while revealing only differentially-private information about their internal network connections. A theoretical utility analysis upper bounds a primary source of private EBC error---private release of ego networks---with high probability. Empirical results demonstrate practical applicability with a low 1.07 relative error achievable at strong privacy budget $\epsilon=0.1$ on a Facebook graph, and insignificant performance degradation as the number of network provider parties grows.
* Full report of paper appearing in PAKDD2020
Towards ML Engineering: A Brief History Of TensorFlow Extended (TFX)
Sep 28, 2020Software Engineering, as a discipline, has matured over the past 5+ decades. The modern world heavily depends on it, so the increased maturity of Software Engineering was an eventuality. Practices like testing and reliable technologies help make Software Engineering reliable enough to build industries upon. Meanwhile, Machine Learning (ML) has also grown over the past 2+ decades. ML is used more and more for research, experimentation and production workloads. ML now commonly powers widely-used products integral to our lives. But ML Engineering, as a discipline, has not widely matured as much as its Software Engineering ancestor. Can we take what we have learned and help the nascent field of applied ML evolve into ML Engineering the way Programming evolved into Software Engineering [1]? In this article we will give a whirlwind tour of Sibyl [2] and TensorFlow Extended (TFX) [3], two successive end-to-end (E2E) ML platforms at Alphabet. We will share the lessons learned from over a decade of applied ML built on these platforms, explain both their similarities and their differences, and expand on the shifts (both mental and technical) that helped us on our journey. In addition, we will highlight some of the capabilities of TFX that help realize several aspects of ML Engineering. We argue that in order to unlock the gains ML can bring, organizations should advance the maturity of their ML teams by investing in robust ML infrastructure and promoting ML Engineering education. We also recommend that before focusing on cutting-edge ML modeling techniques, product leaders should invest more time in adopting interoperable ML platforms for their organizations. In closing, we will also share a glimpse into the future of TFX.
Neural Subgraph Isomorphism Counting
Dec 25, 2019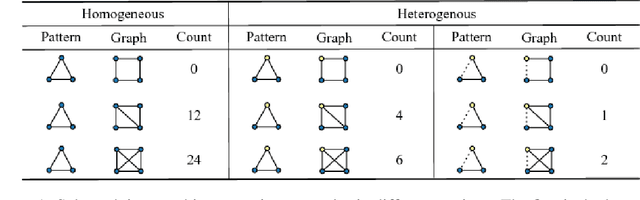

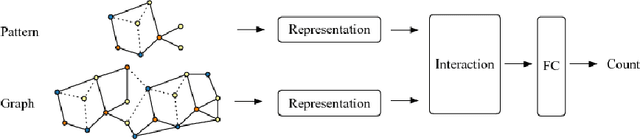
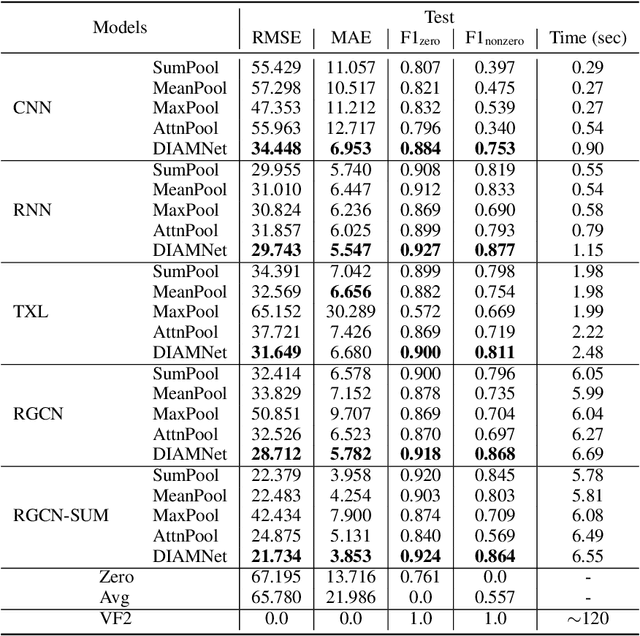
In this paper, we study a new graph learning problem: learning to count subgraph isomorphisms. Although the learning based approach is inexact, we are able to generalize to count large patterns and data graphs in polynomial time compared to the exponential time of the original NP-complete problem. Different from other traditional graph learning problems such as node classification and link prediction, subgraph isomorphism counting requires more global inference to oversee the whole graph. To tackle this problem, we propose a dynamic intermedium attention memory network (DIAMNet) which augments different representation learning architectures and iteratively attends pattern and target data graphs to memorize different subgraph isomorphisms for the global counting. We develop both small graphs (<= 1,024 subgraph isomorphisms in each) and large graphs (<= 4,096 subgraph isomorphisms in each) sets to evaluate different models. Experimental results show that learning based subgraph isomorphism counting can help reduce the time complexity with acceptable accuracy. Our DIAMNet can further improve existing representation learning models for this more global problem.
A Machine Learning Approach to Assess Student Group Collaboration Using Individual Level Behavioral Cues
Jul 13, 2020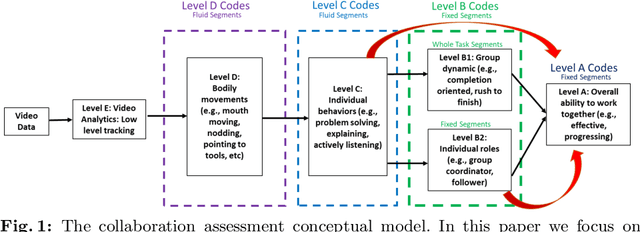

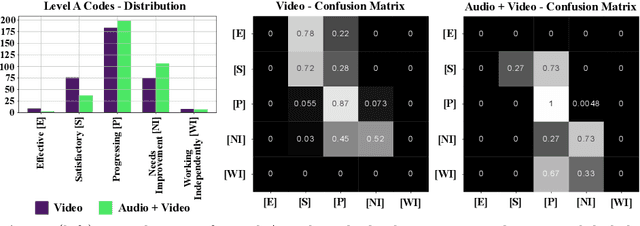
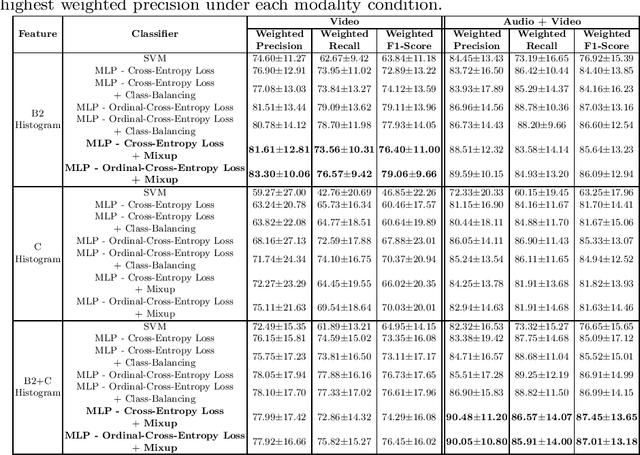
K-12 classrooms consistently integrate collaboration as part of their learning experiences. However, owing to large classroom sizes, teachers do not have the time to properly assess each student and give them feedback. In this paper we propose using simple deep-learning-based machine learning models to automatically determine the overall collaboration quality of a group based on annotations of individual roles and individual level behavior of all the students in the group. We come across the following challenges when building these models: 1) Limited training data, 2) Severe class label imbalance. We address these challenges by using a controlled variant of Mixup data augmentation, a method for generating additional data samples by convexly combining different pairs of data samples and their corresponding class labels. Additionally, the label space for our problem exhibits an ordered structure. We take advantage of this fact and also explore using an ordinal-cross-entropy loss function and study its effects with and without Mixup.
Regularized Flexible Activation Function Combinations for Deep Neural Networks
Jul 26, 2020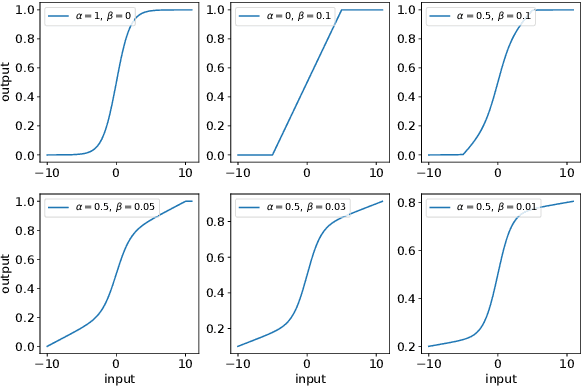
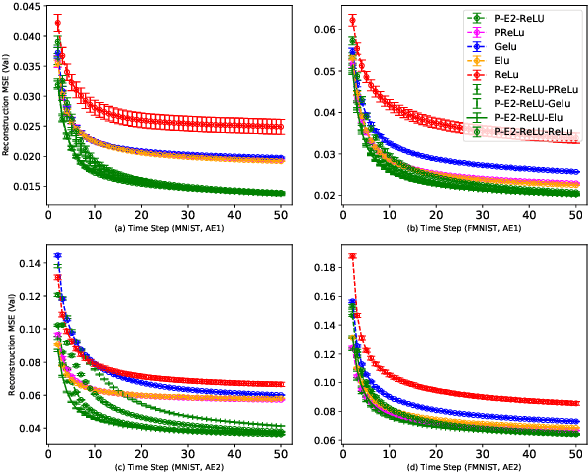
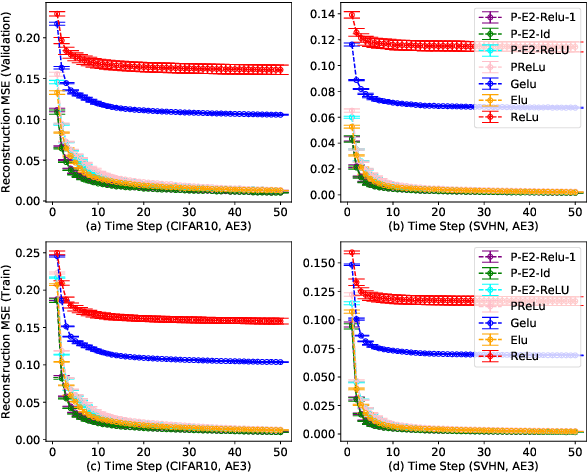
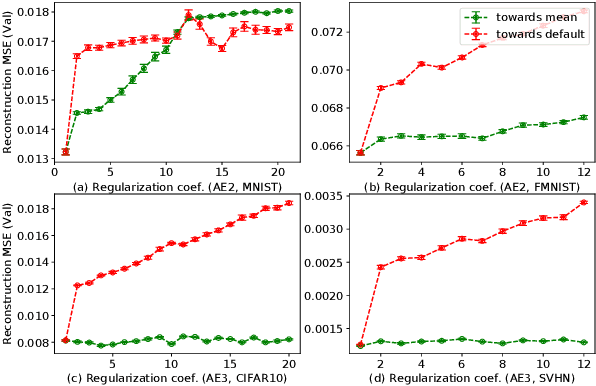
Activation in deep neural networks is fundamental to achieving non-linear mappings. Traditional studies mainly focus on finding fixed activations for a particular set of learning tasks or model architectures. The research on flexible activation is quite limited in both designing philosophy and application scenarios. In this study, three principles of choosing flexible activation components are proposed and a general combined form of flexible activation functions is implemented. Based on this, a novel family of flexible activation functions that can replace sigmoid or tanh in LSTM cells are implemented, as well as a new family by combining ReLU and ELUs. Also, two new regularisation terms based on assumptions as prior knowledge are introduced. It has been shown that LSTM models with proposed flexible activations P-Sig-Ramp provide significant improvements in time series forecasting, while the proposed P-E2-ReLU achieves better and more stable performance on lossy image compression tasks with convolutional auto-encoders. In addition, the proposed regularization terms improve the convergence, performance and stability of the models with flexible activation functions.
Numerical Simulation of Exchange Option with Finite Liquidity: Controlled Variate Model
Jun 14, 2020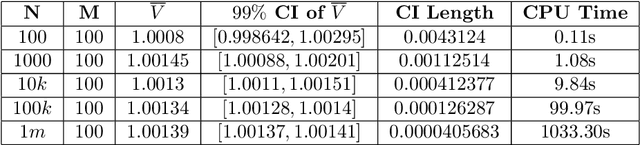
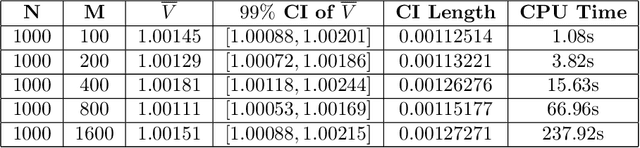
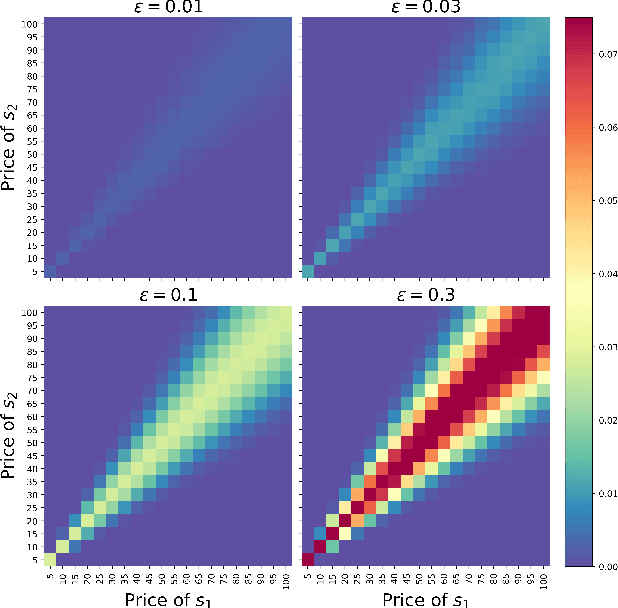
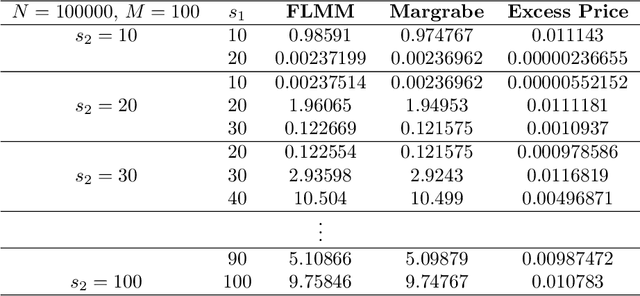
In this paper we develop numerical pricing methodologies for European style Exchange Options written on a pair of correlated assets, in a market with finite liquidity. In contrast to the standard multi-asset Black-Scholes framework, trading in our market model has a direct impact on the asset's price. The price impact is incorporated into the dynamics of the first asset through a specific trading strategy, as in large trader liquidity model. Two-dimensional Milstein scheme is implemented to simulate the pair of assets prices. The option value is numerically estimated by Monte Carlo with the Margrabe option as controlled variate. Time complexity of these numerical schemes are included. Finally, we provide a deep learning framework to implement this model effectively in a production environment.
Explaining Regression Based Neural Network Model
Apr 15, 2020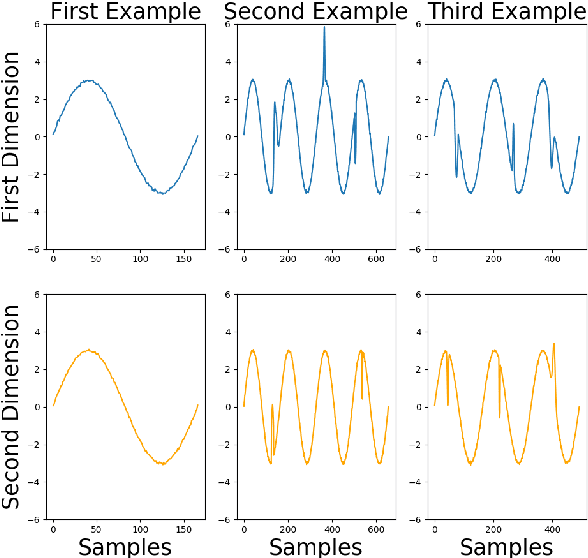
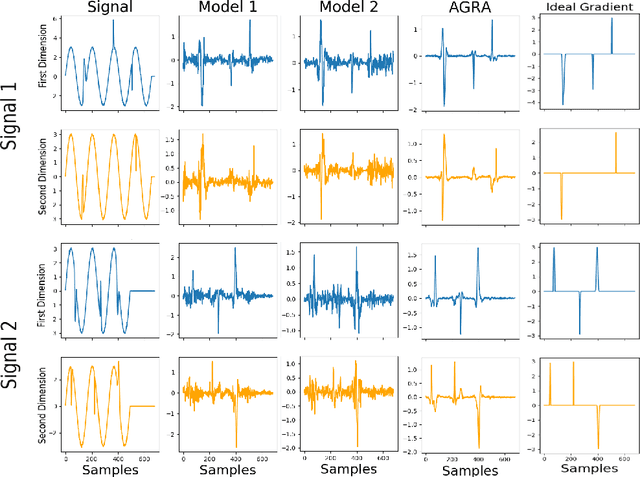
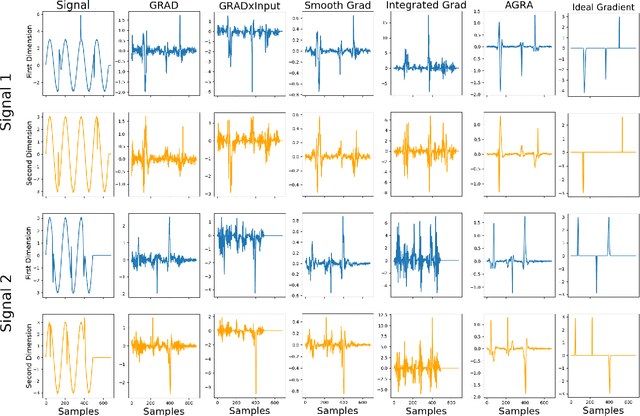
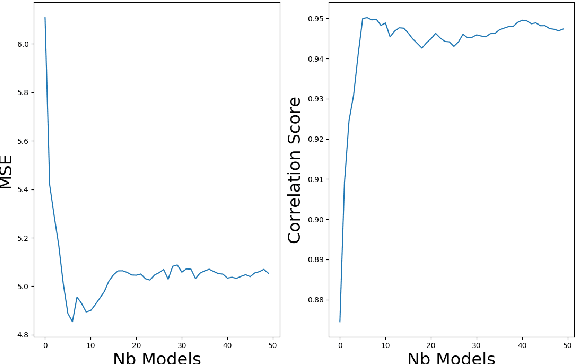
Several methods have been proposed to explain Deep Neural Network (DNN). However, to our knowledge, only classification networks have been studied to try to determine which input dimensions motivated the decision. Furthermore, as there is no ground truth to this problem, results are only assessed qualitatively in regards to what would be meaningful for a human. In this work, we design an experimental settings where the ground truth can been established: we generate ideal signals and disrupted signals with errors and learn a neural network that determines the quality of the signals. This quality is simply a score based on the distance between the disrupted signals and the corresponding ideal signal. We then try to find out how the network estimated this score and hope to find the time-step and dimensions of the signal where errors are present. This experimental setting enables us to compare several methods for network explanation and to propose a new method, named AGRA for Accurate Gradient, based on several trainings that decrease the noise present in most state-of-the-art results. Comparative results show that the proposed method outperforms state-of-the-art methods for locating time-steps where errors occur in the signal.