 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emergent symbolic language based deep medical image classification
Aug 22, 2020
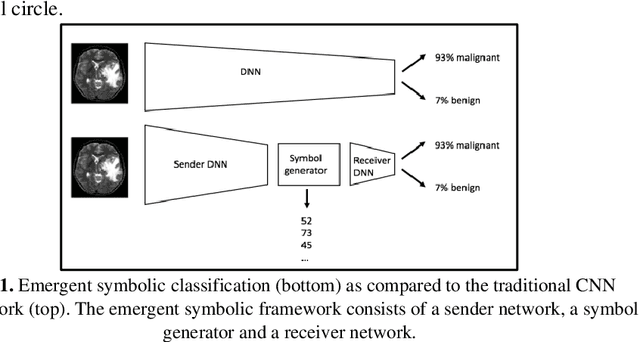
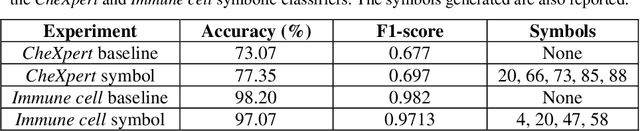
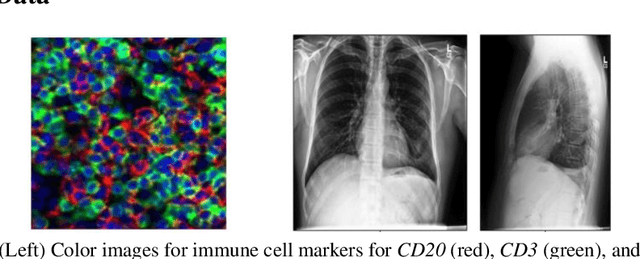
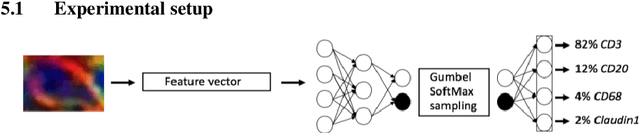
Modern deep learning systems for medical image classification have demonstrated exceptional capabilities for distinguishing between image based medical categories. However, they are severely hindered by their ina-bility to explain the reasoning behind their decision making. This is partly due to the uninterpretable continuous latent representations of neural net-works. Emergent languages (EL) have recently been shown to enhance the capabilities of neural networks by equipping them with symbolic represen-tations in the framework of referential games. Symbolic representations are one of the cornerstones of highly explainable good old fashioned AI (GOFAI) systems. In this work, we demonstrate for the first time, the emer-gence of deep symbolic representations of emergent language in the frame-work of image classification. We show that EL based classification models can perform as well as, if not better than state of the art deep learning mod-els. In addition, they provide a symbolic representation that opens up an entire field of possibilities of interpretable GOFAI methods involving symbol manipulation. We demonstrate the EL classification framework on immune cell marker based cell classification and chest X-ray classification using the CheXpert dataset. Code is available online at https://github.com/AriChow/EL.
An Intelligent Control Strategy for buck DC-DC Converter via Deep Reinforcement Learning
Aug 11, 2020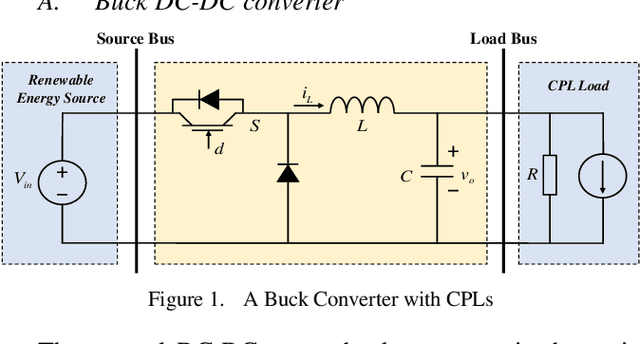
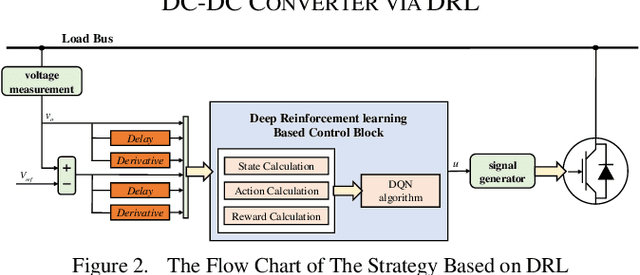
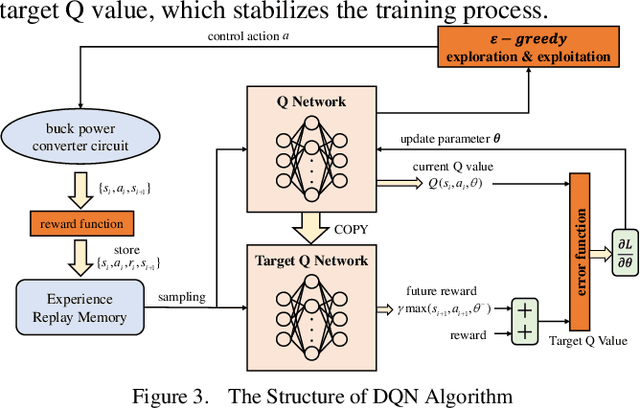
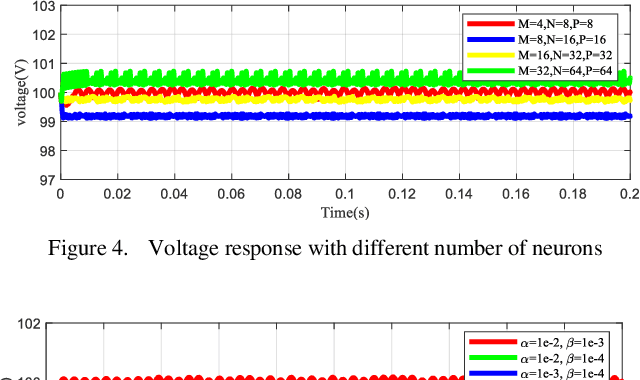
As a typical switching power supply, the DC-DC converter has been widely applied in DC microgrid. Due to the variation of renewable energy generation, research and design of DC-DC converter control algorithm with outstanding dynamic characteristics has significant theoretical and practical application value. To mitigate the bus voltage stability issue in DC microgrid, an innovative intelligent control strategy for buck DC-DC converter with constant power loads (CPLs) via deep reinforcement learning algorithm is constructed for the first time. In this article, a Markov Decision Process (MDP) model and the deep Q network (DQN) algorithm are defined for DC-DC converter. A model-free based deep reinforcement learning (DRL) control strategy is appropriately designed to adjust the agent-environment interaction through the rewards/penalties mechanism towards achieving converge to nominal voltage. The agent makes approximate decisions by extracting the high-dimensional feature of complex power systems without any prior knowledge. Eventually, the simulation comparison results demonstrate that the proposed controller has stronger self-learning and self-optimization capabilities under the different scenarios.
KR-BERT: A Small-Scale Korean-Specific Language Model
Aug 11, 2020



Since the appearance of BERT, recent works including XLNet and RoBERTa utilize sentence embedding models pre-trained by large corpora and a large number of parameters. Because such models have large hardware and a huge amount of data, they take a long time to pre-train. Therefore it is important to attempt to make smaller models that perform comparatively. In this paper, we trained a Korean-specific model KR-BERT, utilizing a smaller vocabulary and dataset. Since Korean is one of the morphologically rich languages with poor resources using non-Latin alphabets, it is also important to capture language-specific linguistic phenomena that the Multilingual BERT model missed. We tested several tokenizers including our BidirectionalWordPiece Tokenizer and adjusted the minimal span of tokens for tokenization ranging from sub-character level to character-level to construct a better vocabulary for our model. With those adjustments, our KR-BERT model performed comparably and even better than other existing pre-trained models using a corpus about 1/10 of the size.
Comparing Writing Styles using Word Embedding and Dynamic Time Warping
Nov 05, 2015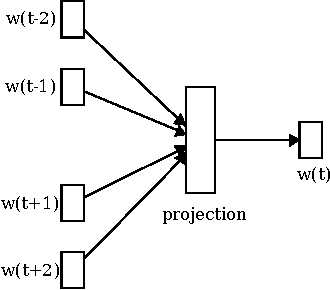
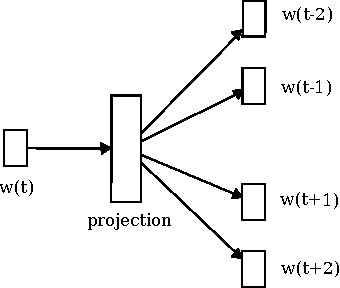
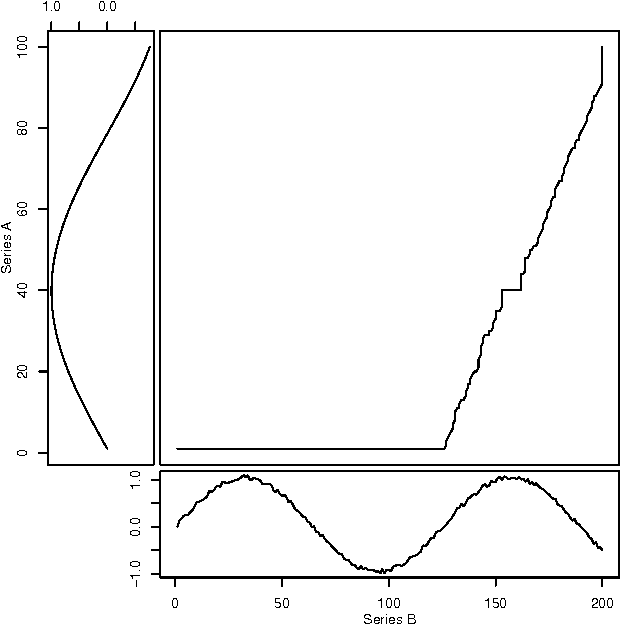
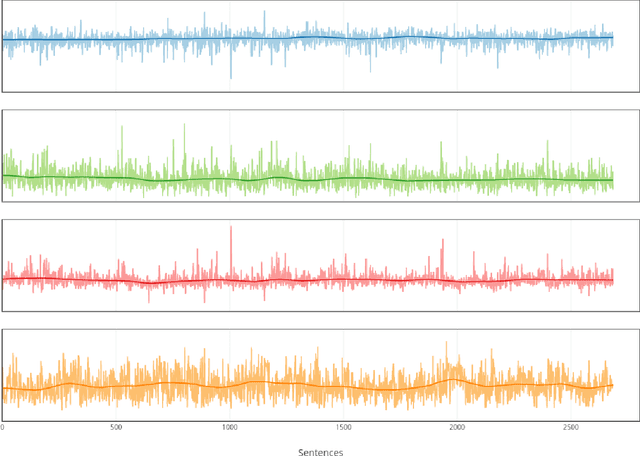
The development of plot or story in novels is reflected in the content and the words used. The flow of sentiments, which is one aspect of writing style, can be quantified by analyzing the flow of words. This study explores literary works as signals in word embedding space and tries to compare writing styles of popular classic novels using dynamic time warping.
Batch Nonlinear Continuous-Time Trajectory Estimation as Exactly Sparse Gaussian Process Regression
Dec 01, 2014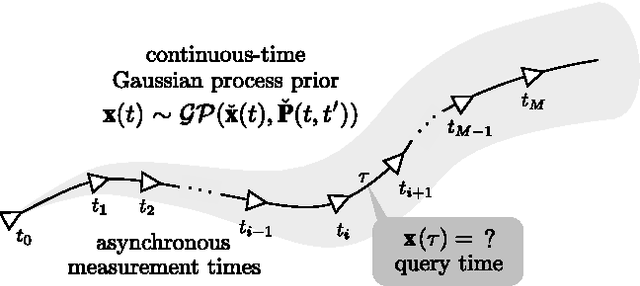

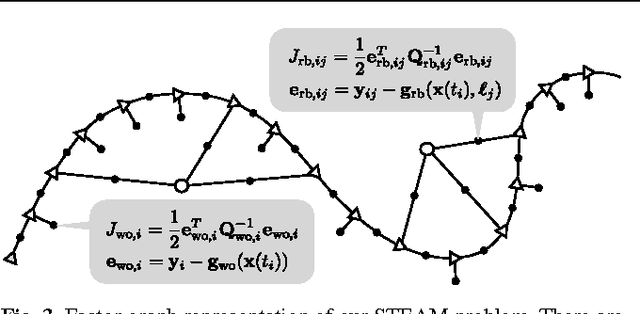
In this paper, we revisit batch state estimation through the lens of Gaussian process (GP) regression. We consider continuous-discrete estimation problems wherein a trajectory is viewed as a one-dimensional GP, with time as the independent variable. Our continuous-time prior can be defined by any nonlinear, time-varying stochastic differential equation driven by white noise; this allows the possibility of smoothing our trajectory estimates using a variety of vehicle dynamics models (e.g., `constant-velocity'). We show that this class of prior results in an inverse kernel matrix (i.e., covariance matrix between all pairs of measurement times) that is exactly sparse (block-tridiagonal) and that this can be exploited to carry out GP regression (and interpolation) very efficiently. When the prior is based on a linear, time-varying stochastic differential equation and the measurement model is also linear, this GP approach is equivalent to classical, discrete-time smoothing (at the measurement times); when a nonlinearity is present, we iterate over the whole trajectory to maximize accuracy. We test the approach experimentally on a simultaneous trajectory estimation and mapping problem using a mobile robot dataset.
Multifractal analysis of the time series of daily means of wind speed in complex regions
Oct 04, 2017
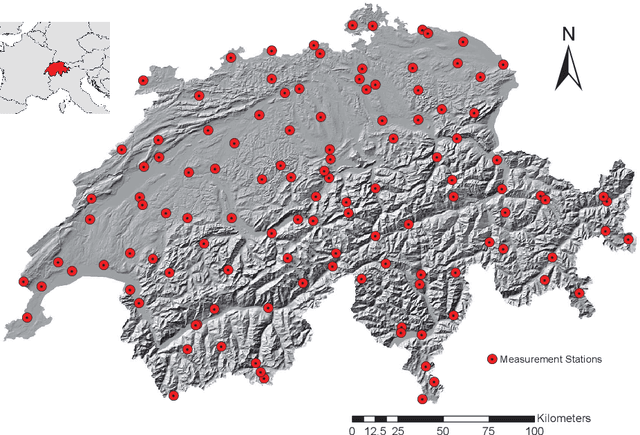
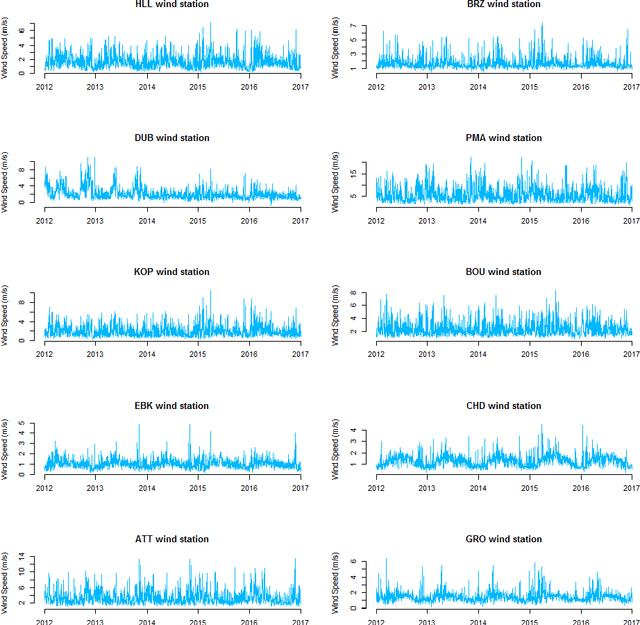
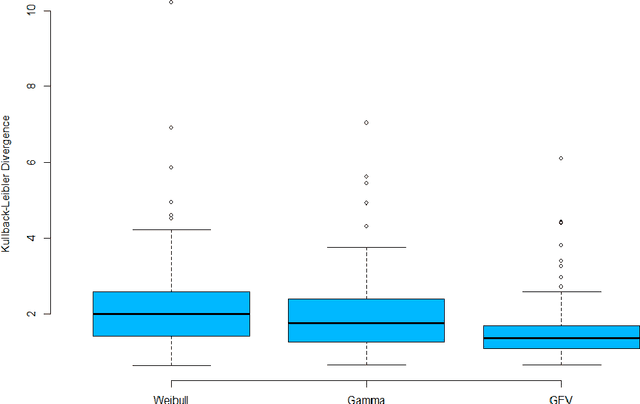
In this paper, we applied the multifractal detrended fluctuation analysis to the daily means of wind speed measured by 119 weather stations distributed over the territory of Switzerland. The analysis was focused on the inner time fluctuations of wind speed, which could be more linked with the local conditions of the highly varying topography of Switzerland. Our findings point out to a persistent behaviour of all the measured wind speed series (indicated by a Hurst exponent significantly larger than 0.5), and to a high multifractality degree indicating a relative dominance of the large fluctuations in the dynamics of wind speed, especially in the Swiss plateau, which is comprised between the Jura and Alp mountain ranges. The study represents a contribution to the understanding of the dynamical mechanisms of wind speed variability in mountainous regions.
A Comparison of LSTM and BERT for Small Corpus
Sep 11, 2020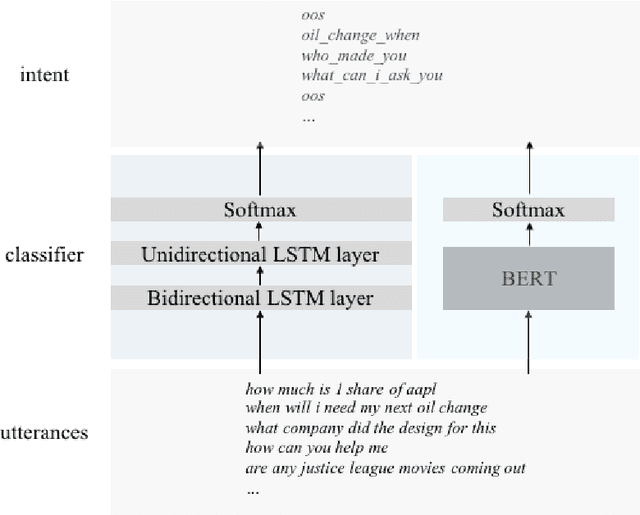
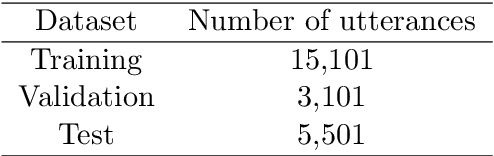
Recent advancements in the NLP field showed that transfer learning helps with achieving state-of-the-art results for new tasks by tuning pre-trained models instead of starting from scratch. Transformers have made a significant improvement in creating new state-of-the-art results for many NLP tasks including but not limited to text classification, text generation, and sequence labeling. Most of these success stories were based on large datasets. In this paper we focus on a real-life scenario that scientists in academia and industry face frequently: given a small dataset, can we use a large pre-trained model like BERT and get better results than simple models? To answer this question, we use a small dataset for intent classification collected for building chatbots and compare the performance of a simple bidirectional LSTM model with a pre-trained BERT model. Our experimental results show that bidirectional LSTM models can achieve significantly higher results than a BERT model for a small dataset and these simple models get trained in much less time than tuning the pre-trained counterparts. We conclude that the performance of a model is dependent on the task and the data, and therefore before making a model choice, these factors should be taken into consideration instead of directly choosing the most popular model.
Comprehensive Image Captioning via Scene Graph Decomposition
Jul 23, 2020
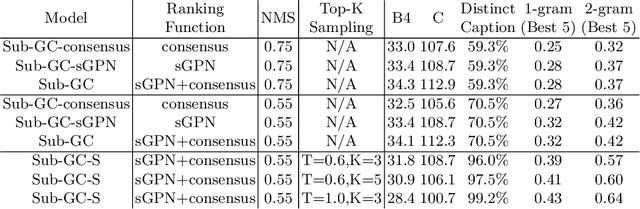
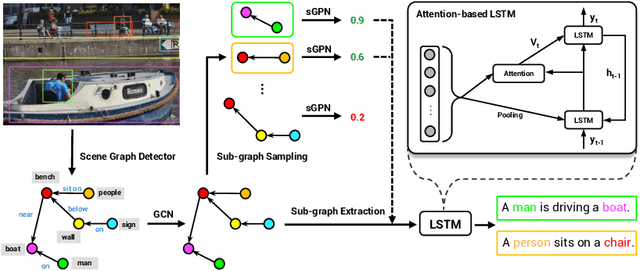
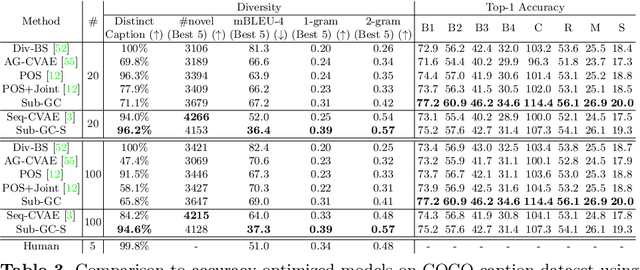
We address the challenging problem of image captioning by revisiting the representation of image scene graph. At the core of our method lies the decomposition of a scene graph into a set of sub-graphs, with each sub-graph capturing a semantic component of the input image. We design a deep model to select important sub-graphs, and to decode each selected sub-graph into a single target sentence. By using sub-graphs, our model is able to attend to different components of the image. Our method thus accounts for accurate, diverse, grounded and controllable captioning at the same time. We present extensive experiments to demonstrate the benefits of our comprehensive captioning model. Our method establishes new state-of-the-art results in caption diversity, grounding, and controllability, and compares favourably to latest methods in caption quality. Our project website can be found at http://pages.cs.wisc.edu/~yiwuzhong/Sub-GC.html.
Multi-way Graph Signal Processing on Tensors: Integrative analysis of irregular geometries
Jun 30, 2020
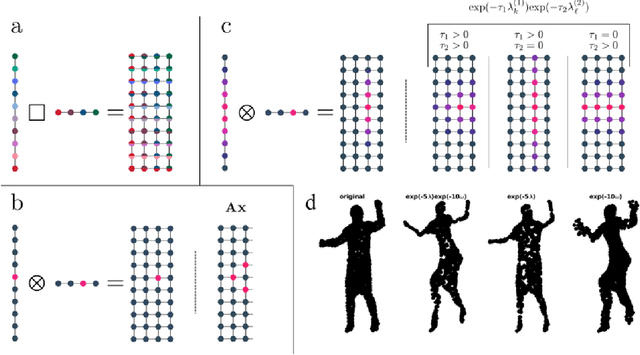
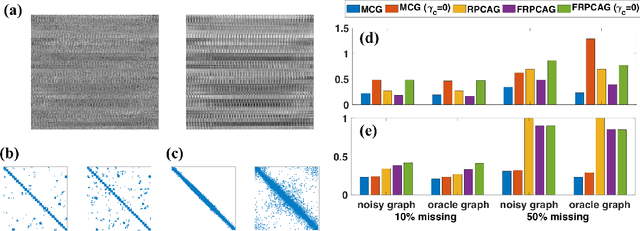
Graph signal processing (GSP) is an important methodology for studying arbitrarily structured data. As acquired data is increasingly taking the form of multi-way tensors, new signal processing tools are needed to maximally utilize the multi-way structure within the data. We review modern signal processing frameworks generalizing GSP to multi-way data, starting from graph signals coupled to familiar regular axes such as time in sensor networks, and then extending to general graphs across all tensor modes. This widely applicable paradigm motivates reformulating and improving upon classical problems and approaches to creatively address the challenges in tensor-based data. We synthesize common themes arising from current efforts to combine GSP with tensor analysis and highlight future directions in extending GSP to the multi-way paradigm.
A Panda? No, It's a Sloth: Slowdown Attacks on Adaptive Multi-Exit Neural Network Inference
Oct 06, 2020

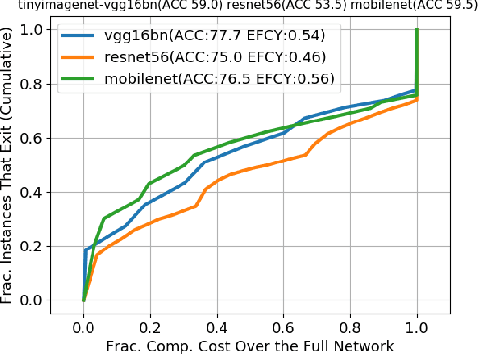
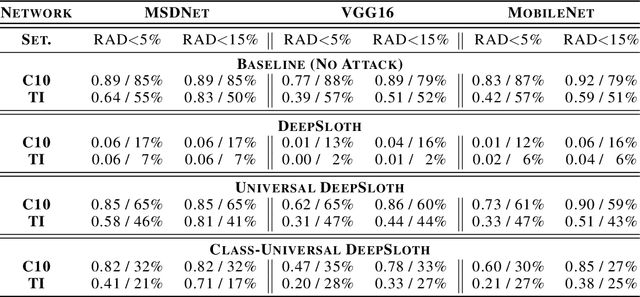
Recent increases in the computational demands of deep neural networks (DNNs), combined with the observation that most input samples require only simple models, have sparked interest in $input$-$adaptive$ multi-exit architectures, such as MSDNets or Shallow-Deep Networks. These architectures enable faster inferences and could bring DNNs to low-power devices, e.g. in the Internet of Things (IoT). However, it is unknown if the computational savings provided by this approach are robust against adversarial pressure. In particular, an adversary may aim to slow down adaptive DNNs by increasing their average inference time$-$a threat analogous to the $denial$-$of$-$service$ attacks from the Internet. In this paper, we conduct a systematic evaluation of this threat by experimenting with three generic multi-exit DNNs (based on VGG16, MobileNet, and ResNet56) and a custom multi-exit architecture, on two popular image classification benchmarks (CIFAR-10 and Tiny ImageNet). To this end, we show that adversarial sample-crafting techniques can be modified to cause slowdown, and we propose a metric for comparing their impact on different architectures. We show that a slowdown attack reduces the efficacy of multi-exit DNNs by 90%-100%, and it amplifies the latency by 1.5-5$\times$ in a typical IoT deployment. We also show that it is possible to craft universal, reusable perturbations and that the attack can be effective in realistic black-box scenarios, where the attacker has limited knowledge about the victim. Finally, we show that adversarial training provides limited protection against slowdowns. These results suggest that further research is needed for defending multi-exit architectures against this emerging threat.