 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of LSTM and BERT for Small Corpus
Paper and Code
Sep 11, 2020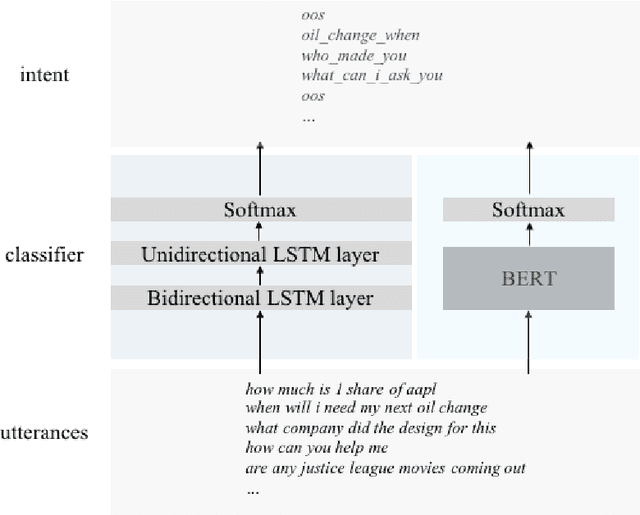
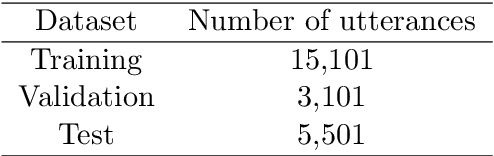
Recent advancements in the NLP field showed that transfer learning helps with achieving state-of-the-art results for new tasks by tuning pre-trained models instead of starting from scratch. Transformers have made a significant improvement in creating new state-of-the-art results for many NLP tasks including but not limited to text classification, text generation, and sequence labeling. Most of these success stories were based on large datasets. In this paper we focus on a real-life scenario that scientists in academia and industry face frequently: given a small dataset, can we use a large pre-trained model like BERT and get better results than simple models? To answer this question, we use a small dataset for intent classification collected for building chatbots and compare the performance of a simple bidirectional LSTM model with a pre-trained BERT model. Our experimental results show that bidirectional LSTM models can achieve significantly higher results than a BERT model for a small dataset and these simple models get trained in much less time than tuning the pre-trained counterparts. We conclude that the performance of a model is dependent on the task and the data, and therefore before making a model choice, these factors should be taken into consideration instead of directly choosing the most popular model.