 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine Learning Clustering Techniques for Selective Mitigation of Critical Design Features
Aug 31, 2020
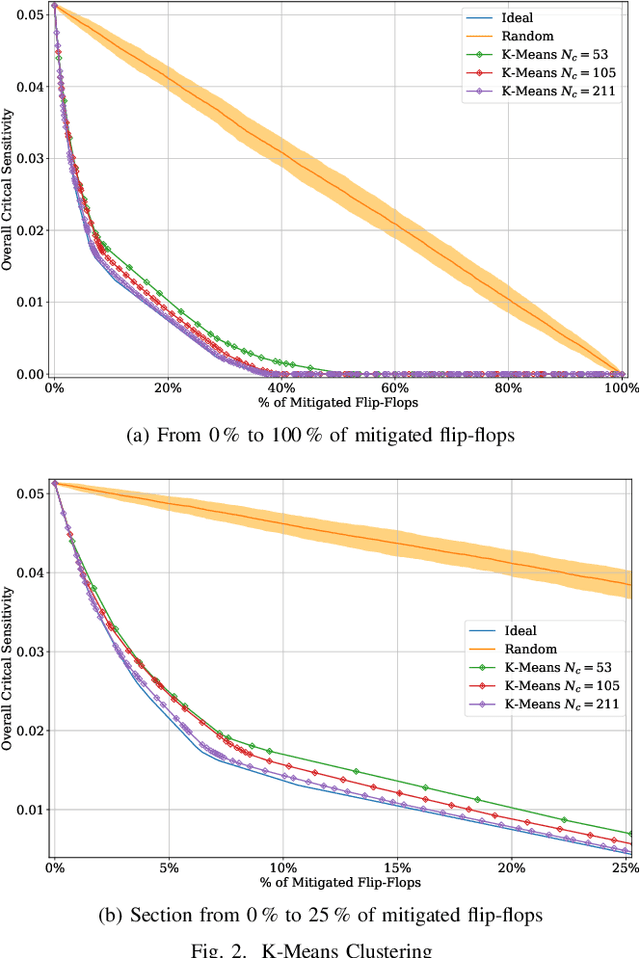
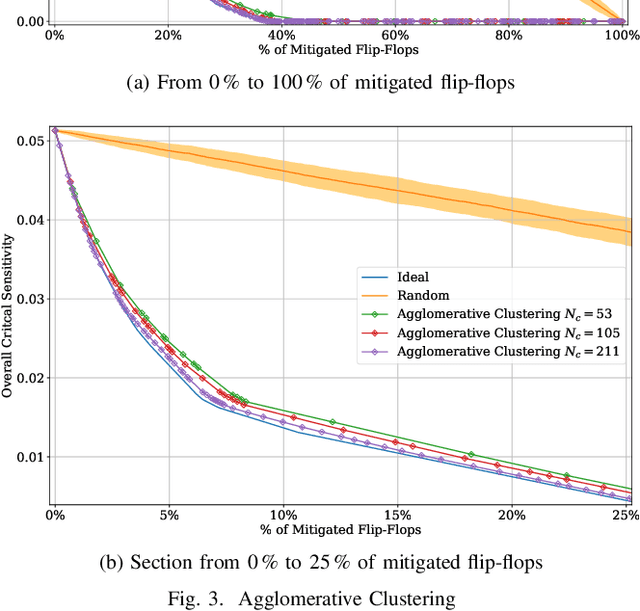
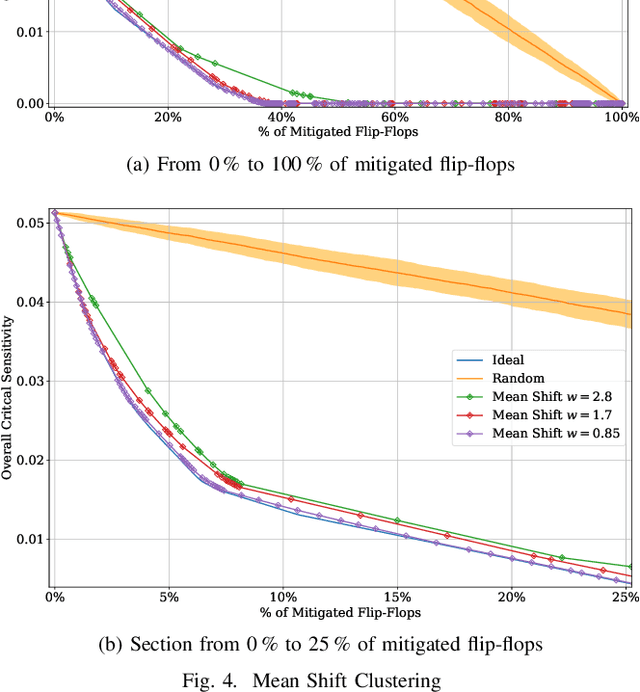
Selective mitigation or selective hardening is an effective technique to obtain a good trade-off between the improvements in the overall reliability of a circuit and the hardware overhead induced by the hardening techniques. Selective mitigation relies on preferentially protecting circuit instances according to their susceptibility and criticality. However, ranking circuit parts in terms of vulnerability usually requires computationally intensive fault-injection simulation campaigns. This paper presents a new methodology which uses machine learning clustering techniques to group flip-flops with similar expected contributions to the overall functional failure rate, based on the analysis of a compact set of features combining attributes from static elements and dynamic elements. Fault simulation campaigns can then be executed on a per-group basis, significantly reducing the time and cost of the evaluation. The effectiveness of grouping similar sensitive flip-flops by machine learning clustering algorithms is evaluated on a practical example.Different clustering algorithms are applied and the results are compared to an ideal selective mitigation obtained by exhaustive fault-injection simulation.
Using Monte Carlo dropout and bootstrap aggregation for uncertainty estimation in radiation therapy dose prediction with deep learning neural networks
Nov 01, 2020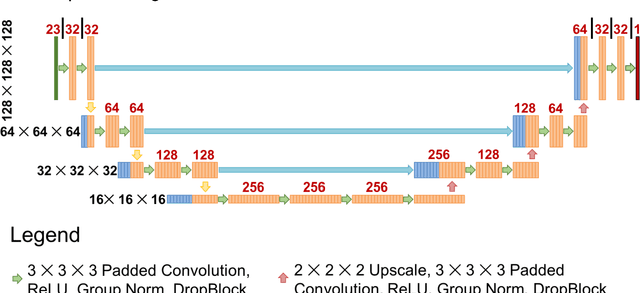
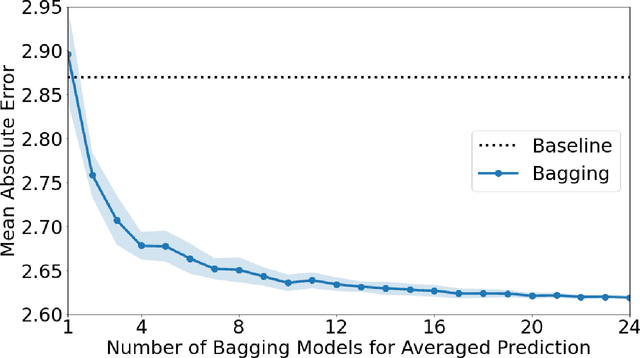
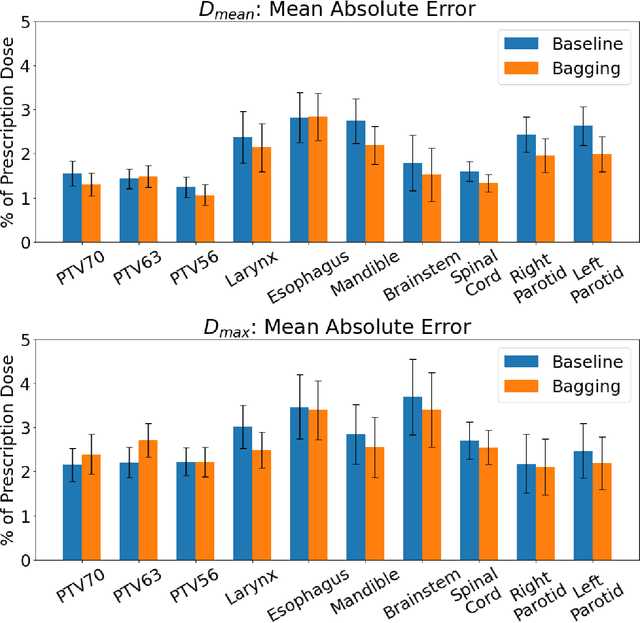
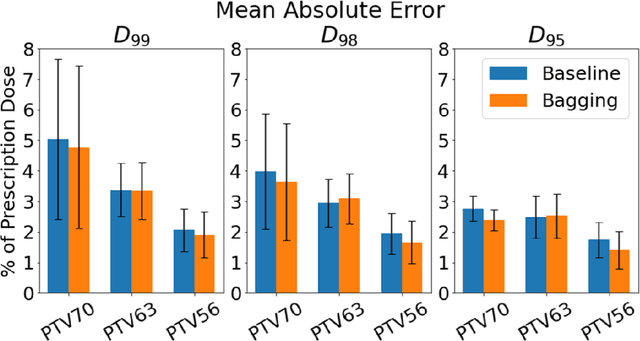
Recently, artificial intelligence technologies and algorithms have become a major focus for advancements in treatment planning for radiation therapy. As these are starting to become incorporated into the clinical workflow, a major concern from clinicians is not whether the model is accurate, but whether the model can express to a human operator when it does not know if its answer is correct. We propose to use Monte Carlo dropout (MCDO) and the bootstrap aggregation (bagging) technique on deep learning models to produce uncertainty estimations for radiation therapy dose prediction. We show that both models are capable of generating a reasonable uncertainty map, and, with our proposed scaling technique, creating interpretable uncertainties and bounds on the prediction and any relevant metrics. Performance-wise, bagging provides statistically significant reduced loss value and errors in most of the metrics investigated in this study. The addition of bagging was able to further reduce errors by another 0.34% for Dmean and 0.19% for Dmax, on average, when compared to the baseline framework. Overall, the bagging framework provided significantly lower MAE of 2.62, as opposed to the baseline framework's MAE of 2.87. The usefulness of bagging, from solely a performance standpoint, does highly depend on the problem and the acceptable predictive error, and its high upfront computational cost during training should be factored in to deciding whether it is advantageous to use it. In terms of deployment with uncertainty estimations turned on, both frameworks offer the same performance time of about 12 seconds. As an ensemble-based metaheuristic, bagging can be used with existing machine learning architectures to improve stability and performance, and MCDO can be applied to any deep learning models that have dropout as part of their architecture.
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos
Aug 12, 2020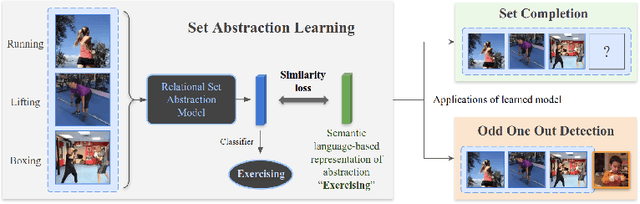
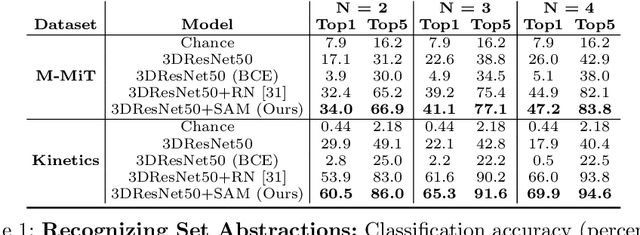

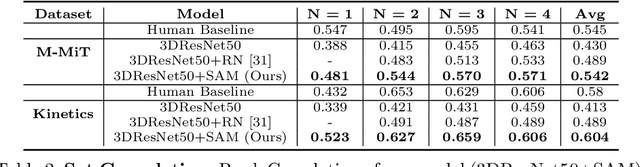
Identifying common patterns among events is a key ability in human and machine perception, as it underlies intelligent decision making. We propose an approach for learning semantic relational set abstractions on videos, inspired by human learning. We combine visual features with natural language supervision to generate high-level representations of similarities across a set of videos. This allows our model to perform cognitive tasks such as set abstraction (which general concept is in common among a set of videos?), set completion (which new video goes well with the set?), and odd one out detection (which video does not belong to the set?). Experiments on two video benchmarks, Kinetics and Multi-Moments in Time, show that robust and versatile representations emerge when learning to recognize commonalities among sets. We compare our model to several baseline algorithms and show that significant improvements result from explicitly learning relational abstractions with semantic supervision.
Fully Convolutional Open Set Segmentation
Jun 25, 2020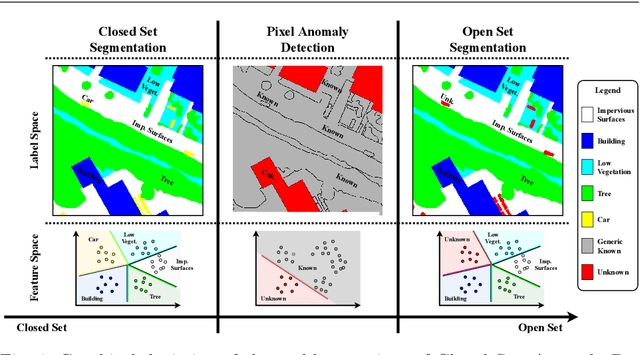
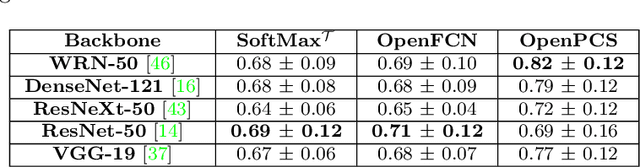
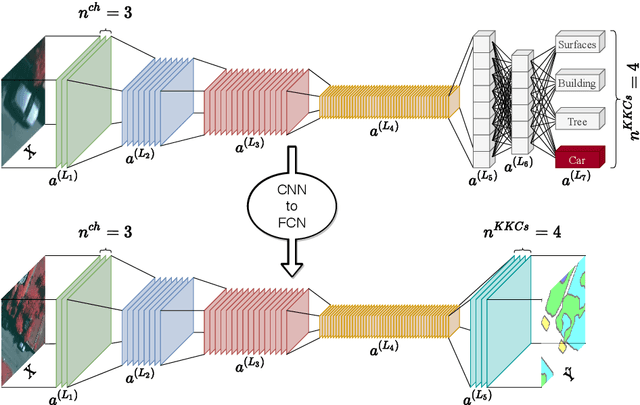
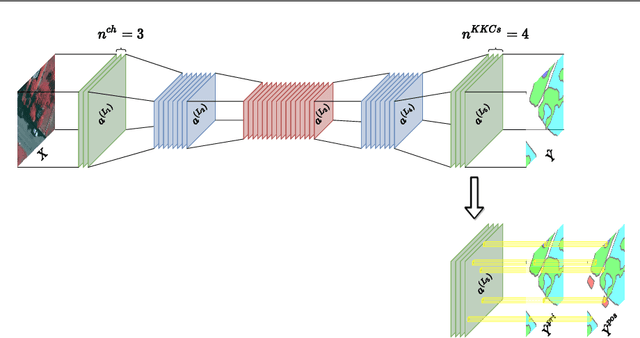
In semantic segmentation knowing about all existing classes is essential to yield effective results with the majority of existing approaches. However, these methods trained in a Closed Set of classes fail when new classes are found in the test phase. It means that they are not suitable for Open Set scenarios, which are very common in real-world computer vision and remote sensing applications. In this paper, we discuss the limitations of Closed Set segmentation and propose two fully convolutional approaches to effectively address Open Set semantic segmentation: OpenFCN and OpenPCS. OpenFCN is based on the well-known OpenMax algorithm, configuring a new application of this approach in segmentation settings. OpenPCS is a fully novel approach based on feature-space from DNN activations that serve as features for computing PCA and multi-variate gaussian likelihood in a lower dimensional space. Experiments were conducted on the well-known Vaihingen and Potsdam segmentation datasets. OpenFCN showed little-to-no improvement when compared to the simpler and much more time efficient SoftMax thresholding, while being between some orders of magnitude slower. OpenPCS achieved promising results in almost all experiments by overcoming both OpenFCN and SoftMax thresholding. OpenPCS is also a reasonable compromise between the runtime performances of the extremely fast SoftMax thresholding and the extremely slow OpenFCN, being close able to run close to real-time. Experiments also indicate that OpenPCS is effective, robust and suitable for Open Set segmentation, being able to improve the recognition of unknown class pixels without reducing the accuracy on the known class pixels.
Continuous Color Transfer
Aug 31, 2020

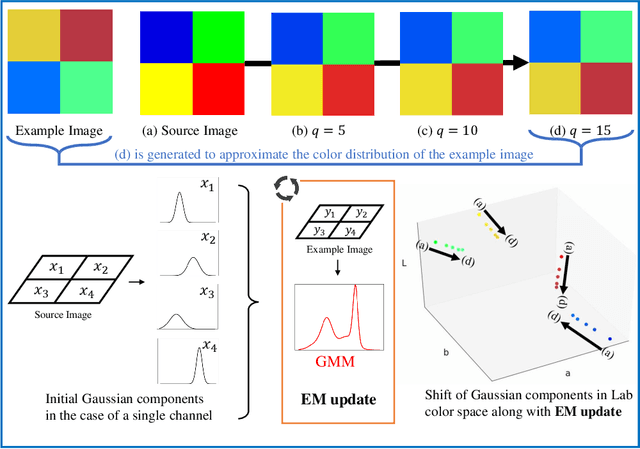

Color transfer, which plays a key role in image editing, has attracted noticeable attention recently. It has remained a challenge to date due to various issues such as time-consuming manual adjustments and prior segmentation issues. In this paper, we propose to model color transfer under a probability framework and cast it as a parameter estimation problem. In particular, we relate the transferred image with the example image under the Gaussian Mixture Model (GMM) and regard the transferred image color as the GMM centroids. We employ the Expectation-Maximization (EM) algorithm (E-step and M-step) for optimization. To better preserve gradient information, we introduce a Laplacian based regularization term to the objective function at the M-step which is solved by deriving a gradient descent algorithm. Given the input of a source image and an example image, our method is able to generate continuous color transfer results with increasing EM iterations. Various experiments show that our approach generally outperforms other competitive color transfer methods, both visually and quantitatively.
Visual Neural Decomposition to Explain Multivariate Data Sets
Sep 11, 2020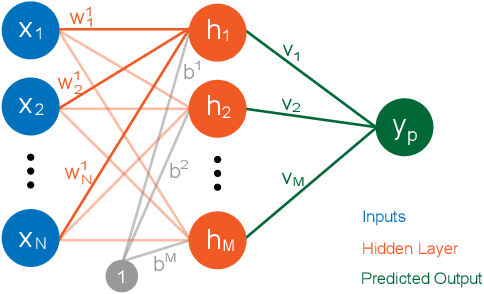
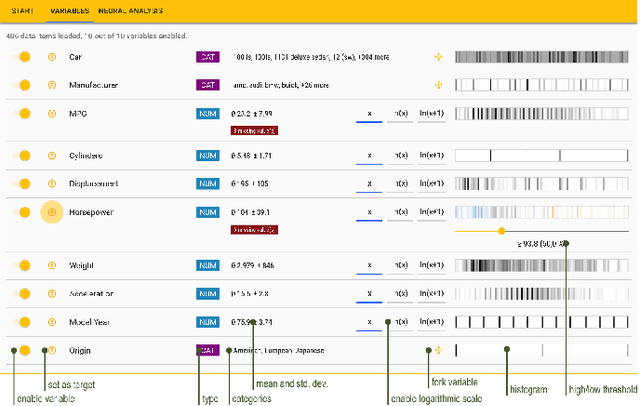

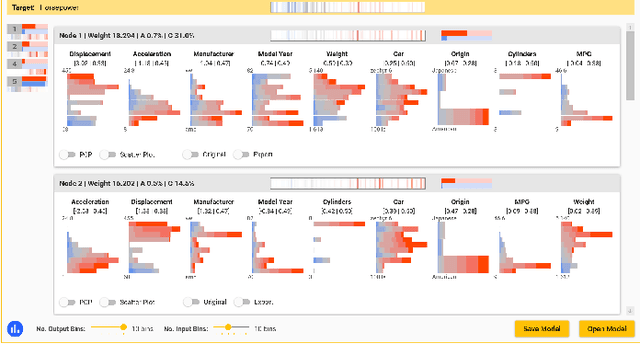
Investigating relationships between variables in multi-dimensional data sets is a common task for data analysts and engineers. More specifically, it is often valuable to understand which ranges of which input variables lead to particular values of a given target variable. Unfortunately, with an increasing number of independent variables, this process may become cumbersome and time-consuming due to the many possible combinations that have to be explored. In this paper, we propose a novel approach to visualize correlations between input variables and a target output variable that scales to hundreds of variables. We developed a visual model based on neural networks that can be explored in a guided way to help analysts find and understand such correlations. First, we train a neural network to predict the target from the input variables. Then, we visualize the inner workings of the resulting model to help understand relations within the data set. We further introduce a new regularization term for the backpropagation algorithm that encourages the neural network to learn representations that are easier to interpret visually. We apply our method to artificial and real-world data sets to show its utility.
Bayesian geoacoustic inversion using mixture density network
Aug 19, 2020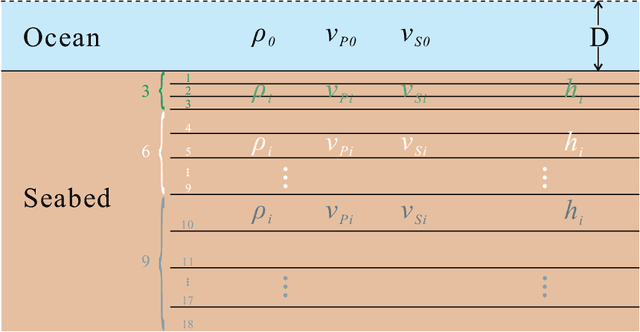
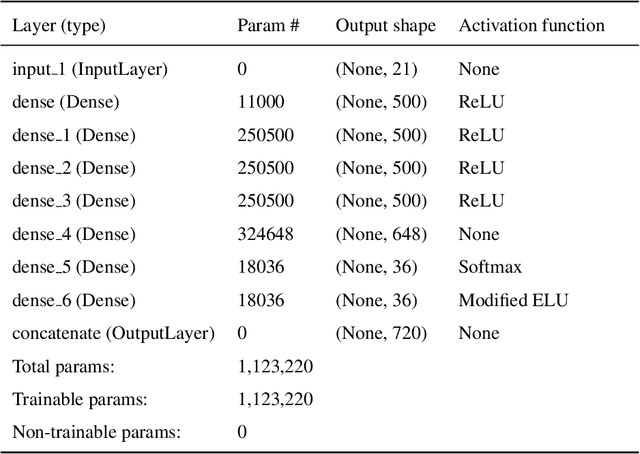
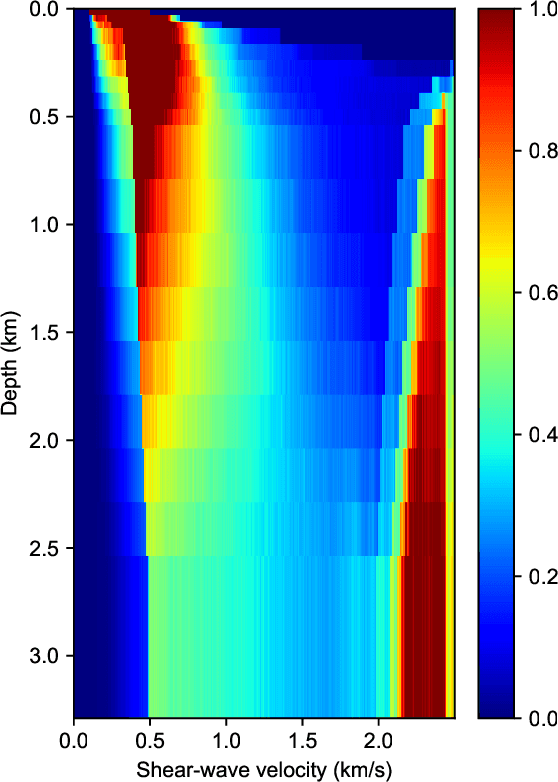
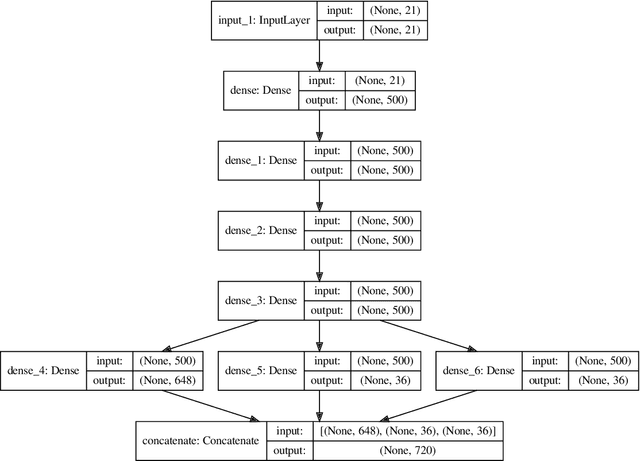
Bayesian geoacoustic inversion problems are conventionally solved by Markov chain Monte Carlo methods or its variants, which are computationally expensive. This paper extends the classic Bayesian geoacoustic inversion framework using the mixture density network (MDN), which provides a much more efficient way to solve geoacoustic inversion problems in Bayesian inference framework. Some important geoacoustic statistics of Bayesian geoacoustic inversion are derived from the multidimensional posterior probability density (PPD) using the MDN theory. These statistics make it convenient to train the network directly on the whole parameter space and get the multidimensional PPD of model parameters. The network is trained on a simulated dataset of surface-wave dispersion curves with shear-wave velocities as labels. The results show that the network gives reliable predictions and has good generalization performance on unseen data. Once trained, the network can rapidly (within seconds) give a fully probabilistic solution which is comparable to Monte Carlo methods. It provides an promissing approach for real-time inversion.
MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines
Oct 17, 2020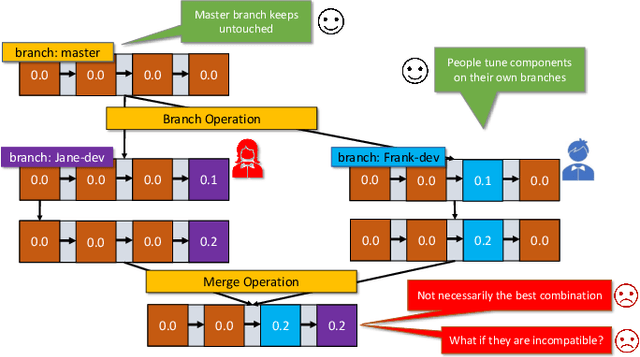
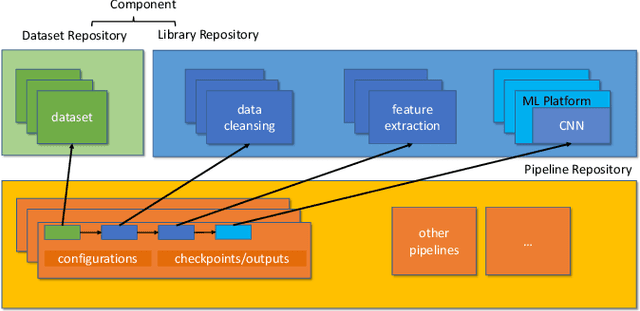
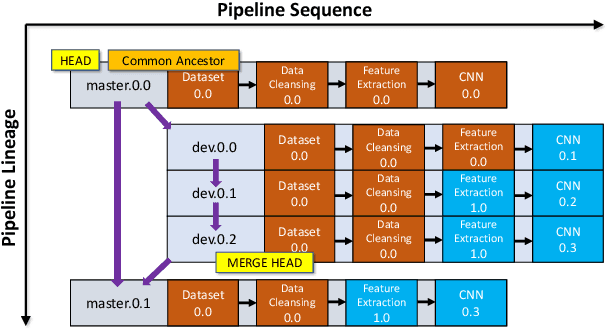
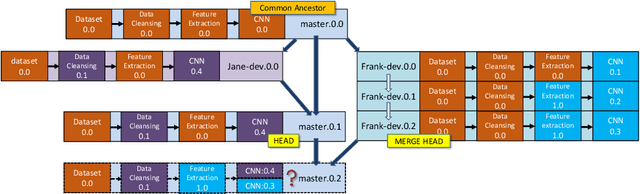
With the ever-increasing adoption of machine learning for data analytics, maintaining a machine learning pipeline is becoming more complex as both the datasets and trained models evolve with time. In a collaborative environment, the changes and updates due to pipeline evolution often cause cumbersome coordination and maintenance work, raising the costs and making it hard to use. Existing solutions, unfortunately, do not address the version evolution problem, especially in a collaborative environment where non-linear version control semantics are necessary to isolate operations made by different user roles. The lack of version control semantics also incurs unnecessary storage consumption and lowers efficiency due to data duplication and repeated data pre-processing, which are avoidable. In this paper, we identify two main challenges that arise during the deployment of machine learning pipelines, and address them with the design of versioning for an end-to-end analytics system MLCask. The system supports multiple user roles with the ability to perform Git-like branching and merging operations in the context of the machine learning pipelines. We define and accelerate the metric-driven merge operation by pruning the pipeline search tree using reusable history records and pipeline compatibility information. Further, we design and implement the prioritized pipeline search, which gives preference to the pipelines that probably yield better performance. The effectiveness of MLCask is evaluated through an extensive study over several real-world deployment cases. The performance evaluation shows that the proposed merge operation is up to 7.8x faster and saves up to 11.9x storage space than the baseline method that does not utilize history records.
Towards Deep Clustering of Human Activities from Wearables
Aug 19, 2020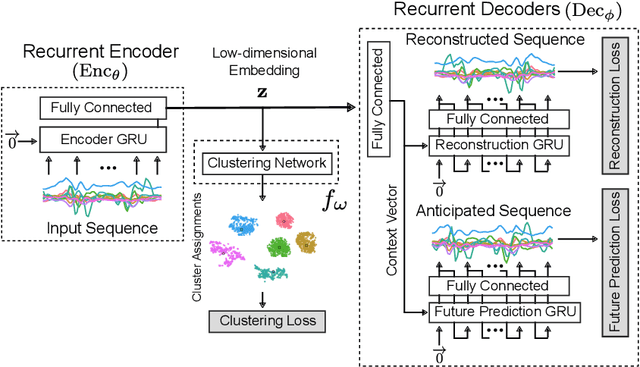
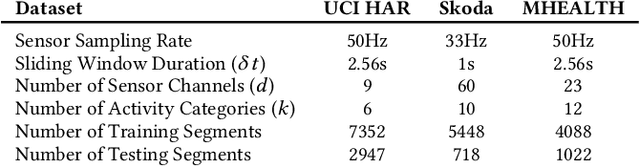
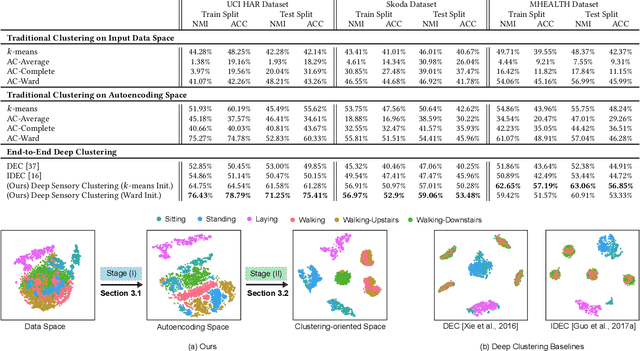
Our ability to exploit low-cost wearable sensing modalities for critical human behaviour and activity monitoring applications in health and wellness is reliant on supervised learning regimes; here, deep learning paradigms have proven extremely successful in learning activity representations from annotated data. However, the costly work of gathering and annotating sensory activity datasets is labor-intensive, time consuming and not scalable to large volumes of data. While existing unsupervised remedies of deep clustering leverage network architectures and optimization objectives that are tailored for static image datasets, deep architectures to uncover cluster structures from raw sequence data captured by on-body sensors remains largely unexplored. In this paper, we develop an unsupervised end-to-end learning strategy for the fundamental problem of human activity recognition (HAR) from wearables. Through extensive experiments, including comparisons with existing methods, we show the effectiveness of our approach to jointly learn unsupervised representations for sensory data and generate cluster assignments with strong semantic correspondence to distinct human activities.
State Action Separable Reinforcement Learning
Jun 05, 2020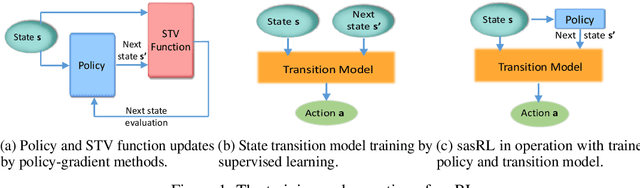
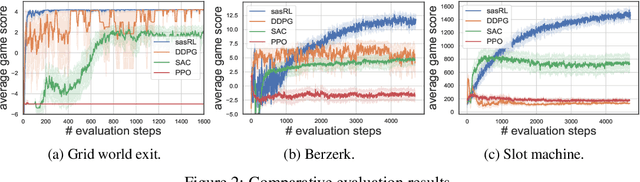
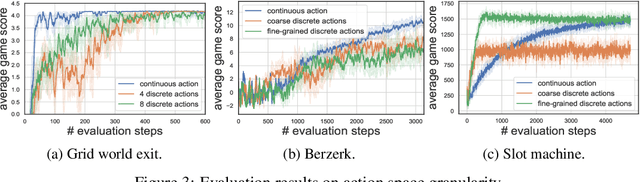
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.