 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Cross-Layer Reliability and Functional Safety Assessment Through ML-Based Compact Models
Apr 22, 2021
Typical design flows are hierarchical and rely on assembling many individual technology elements from standard cells to complete boards. Providers use compact models to provide simplified views of their products to their users. Designers group simpler elements in more complex structures and have to manage the corresponding propagation of reliability and functional safety information through the hierarchy of the system, accompanied by the obvious problems of IP confidentiality, possibility of reverse engineering and so on. This paper proposes a machine-learning-based approach to integrate the many individual models of a subsystem's elements in a single compact model that can be re-used and assembled further up in the hierarchy. The compact models provide consistency, accuracy and confidentiality, allowing technology, IP, component, sub-system or system providers to accompany their offering with high-quality reliability and functional safety compact models that can be safely and accurately consumed by their users.
Modeling Gate-Level Abstraction Hierarchy Using Graph Convolutional Neural Networks to Predict Functional De-Rating Factors
Apr 05, 2021
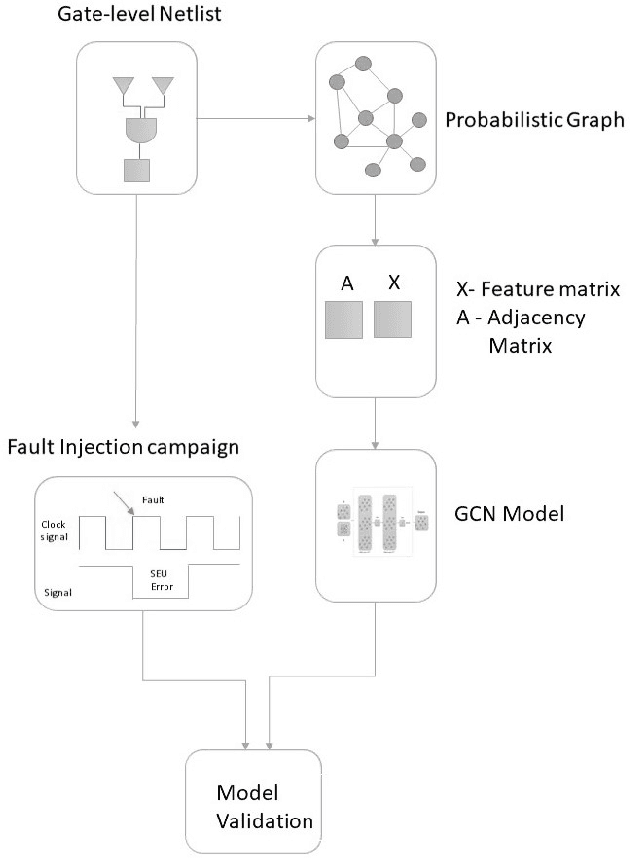
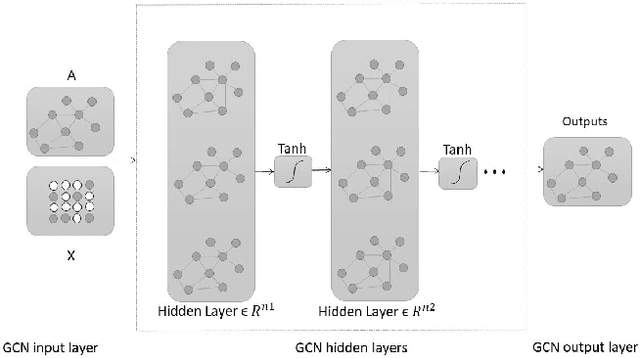
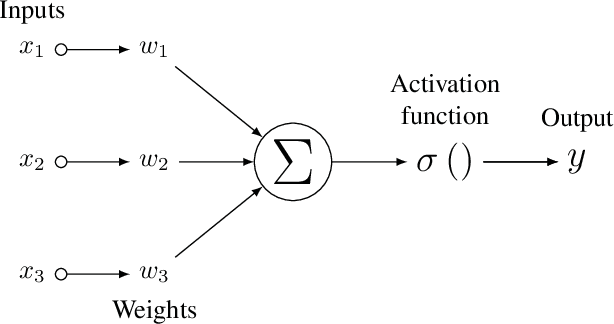
The paper is proposing a methodology for modeling a gate-level netlist using a Graph Convolutional Network (GCN). The model predicts the overall functional de-rating factors of sequential elements of a given circuit. In the preliminary phase of the work, the important goal is making a GCN which able to take a gate-level netlist as input information after transforming it into the Probabilistic Bayesian Graph in the form of Graph Modeling Language (GML). This part enables the GCN to learn the structural information of netlist in graph domains. In the second phase of the work, the modeled GCN trained with the a functional de-rating factor of a very low number of individual sequential elements (flip-flops). The third phase includes understanding of GCN models accuracy to model an arbitrary circuit netlist. The designed model was validated for two circuits. One is the IEEE 754 standard double precision floating point adder and the second one is the 10-Gigabit Ethernet MAC IEEE802.3 standard. The predicted results compared to the standard fault injection campaign results of the error called Single EventUpset (SEU). The validated results are graphically pictured in the form of the histogram and sorted probabilities and evaluated with the Confidence Interval (CI) metric between the predicted and simulated fault injection results.
Machine Learning Clustering Techniques for Selective Mitigation of Critical Design Features
Aug 31, 2020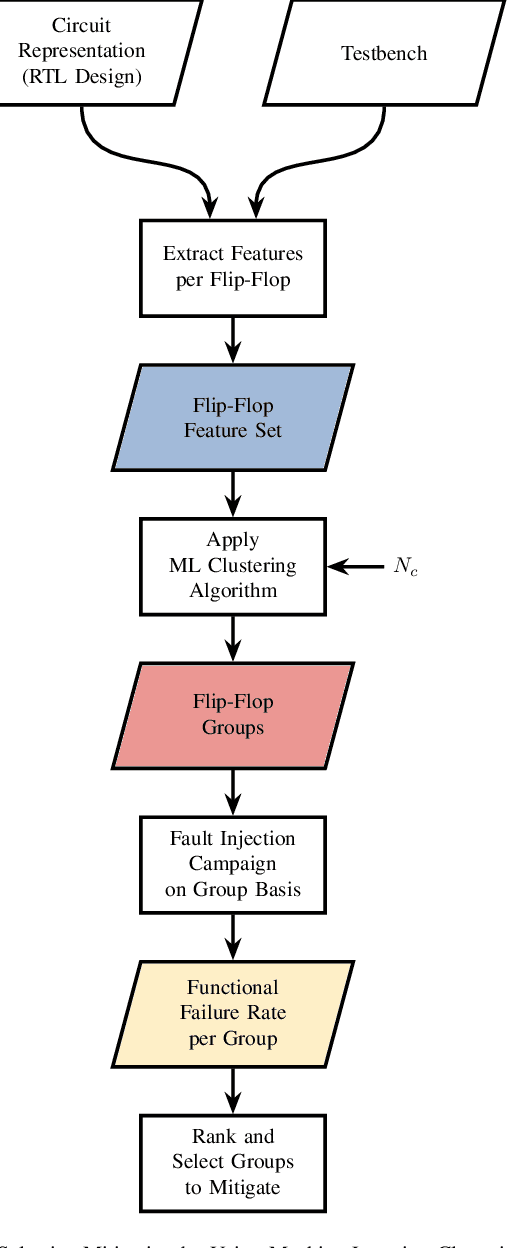
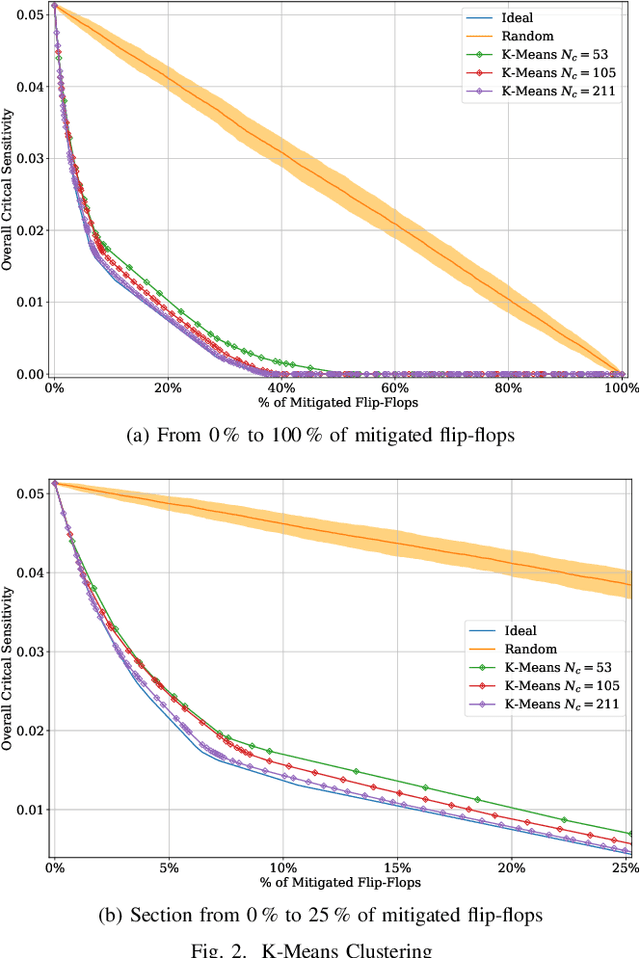
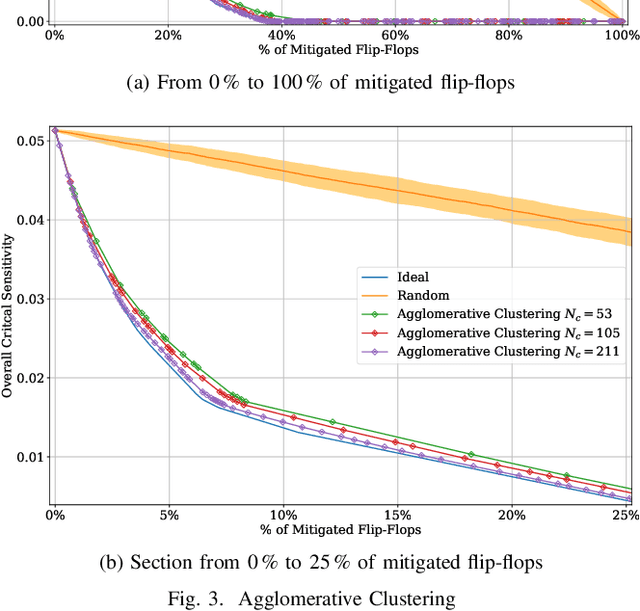
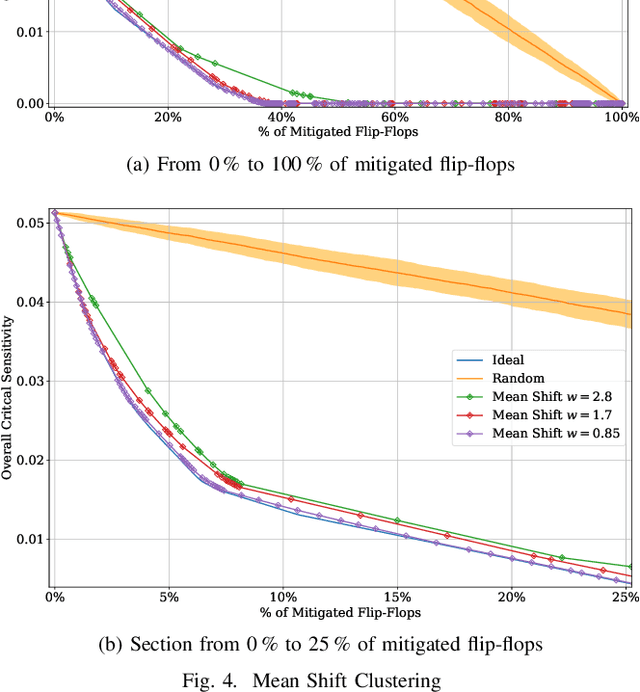
Selective mitigation or selective hardening is an effective technique to obtain a good trade-off between the improvements in the overall reliability of a circuit and the hardware overhead induced by the hardening techniques. Selective mitigation relies on preferentially protecting circuit instances according to their susceptibility and criticality. However, ranking circuit parts in terms of vulnerability usually requires computationally intensive fault-injection simulation campaigns. This paper presents a new methodology which uses machine learning clustering techniques to group flip-flops with similar expected contributions to the overall functional failure rate, based on the analysis of a compact set of features combining attributes from static elements and dynamic elements. Fault simulation campaigns can then be executed on a per-group basis, significantly reducing the time and cost of the evaluation. The effectiveness of grouping similar sensitive flip-flops by machine learning clustering algorithms is evaluated on a practical example.Different clustering algorithms are applied and the results are compared to an ideal selective mitigation obtained by exhaustive fault-injection simulation.
Machine Learning to Tackle the Challenges of Transient and Soft Errors in Complex Circuits
Feb 18, 2020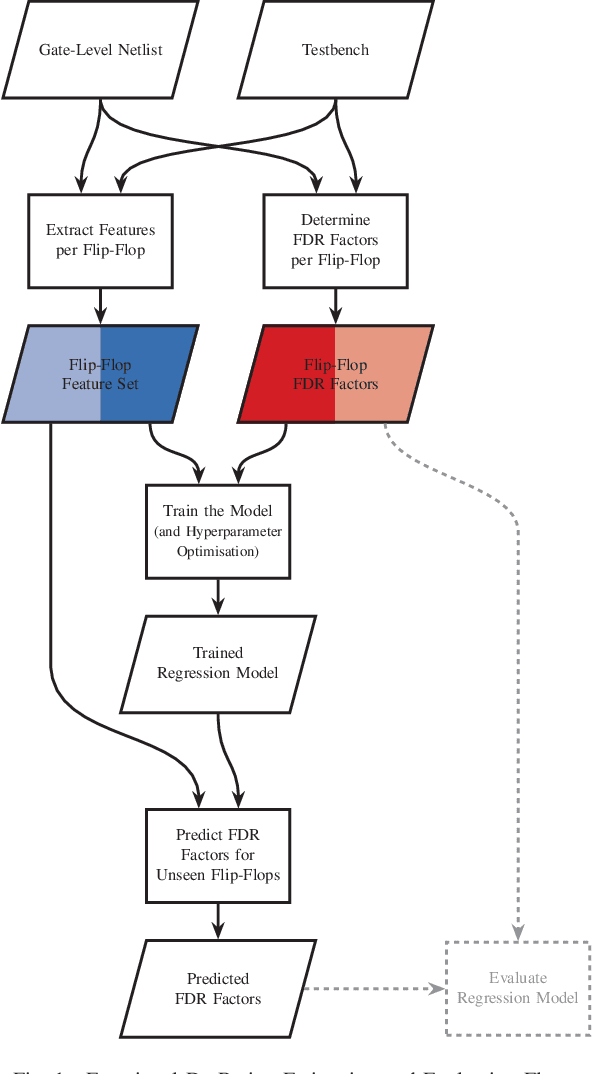
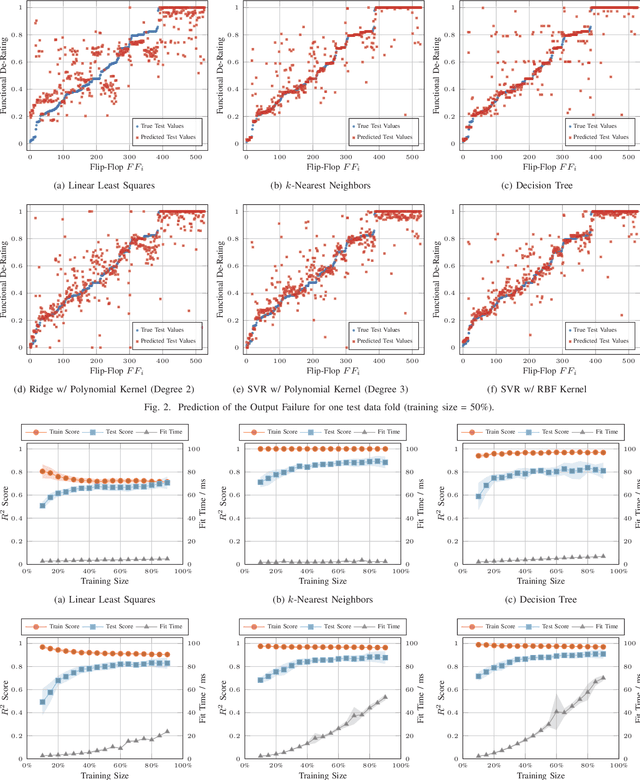
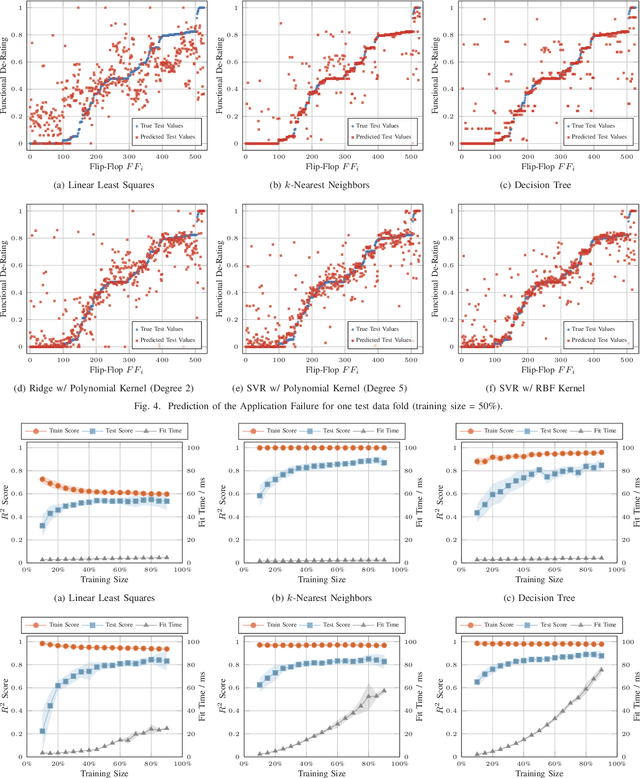
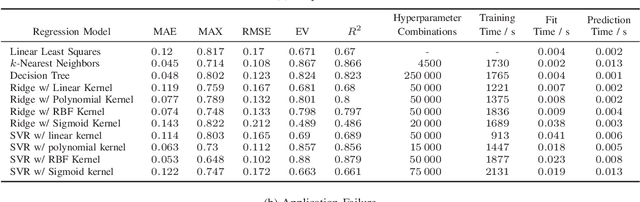
The Functional Failure Rate analysis of today's complex circuits is a difficult task and requires a significant investment in terms of human efforts, processing resources and tool licenses. Thereby, de-rating or vulnerability factors are a major instrument of failure analysis efforts. Usually computationally intensive fault-injection simulation campaigns are required to obtain a fine-grained reliability metrics for the functional level. Therefore, the use of machine learning algorithms to assist this procedure and thus, optimising and enhancing fault injection efforts, is investigated in this paper. Specifically, machine learning models are used to predict accurate per-instance Functional De-Rating data for the full list of circuit instances, an objective that is difficult to reach using classical methods. The described methodology uses a set of per-instance features, extracted through an analysis approach, combining static elements (cell properties, circuit structure, synthesis attributes) and dynamic elements (signal activity). Reference data is obtained through first-principles fault simulation approaches. One part of this reference dataset is used to train the machine learning model and the remaining is used to validate and benchmark the accuracy of the trained tool. The presented methodology is applied on a practical example and various machine learning models are evaluated and compared.
On the Estimation of Complex Circuits Functional Failure Rate by Machine Learning Techniques
Feb 18, 2020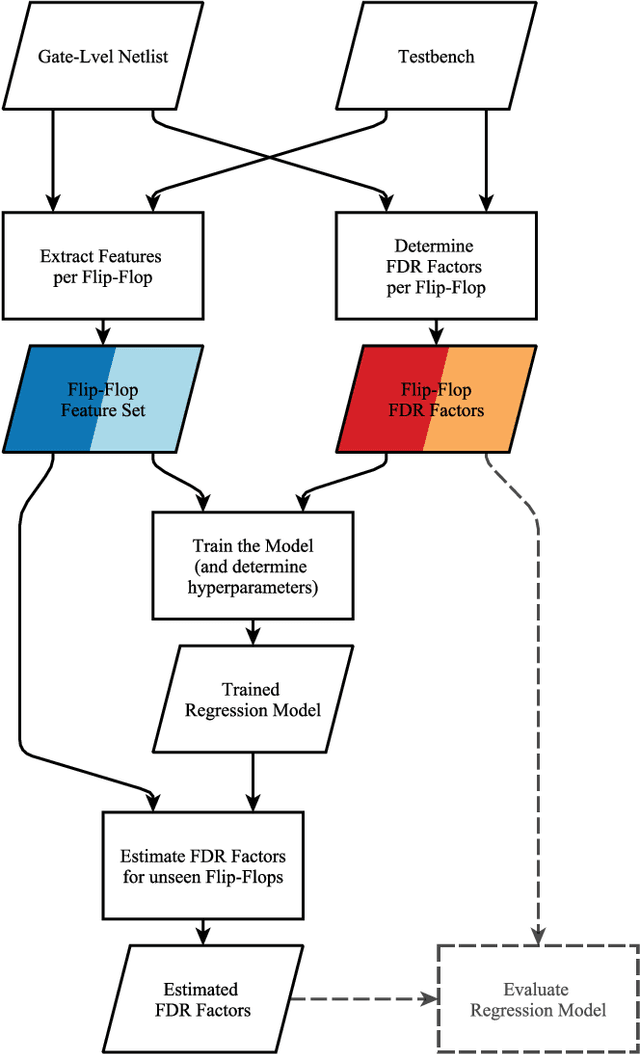
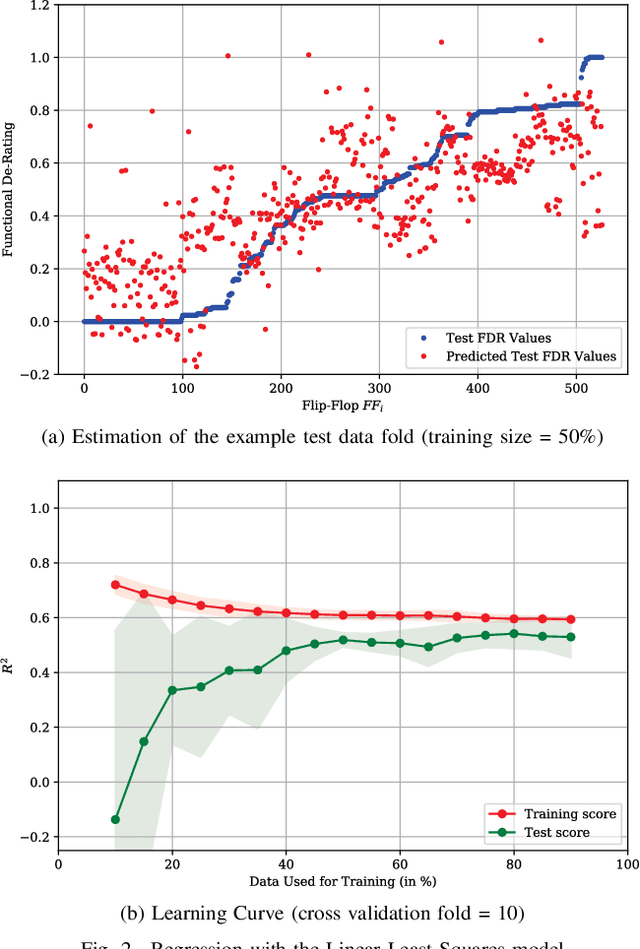
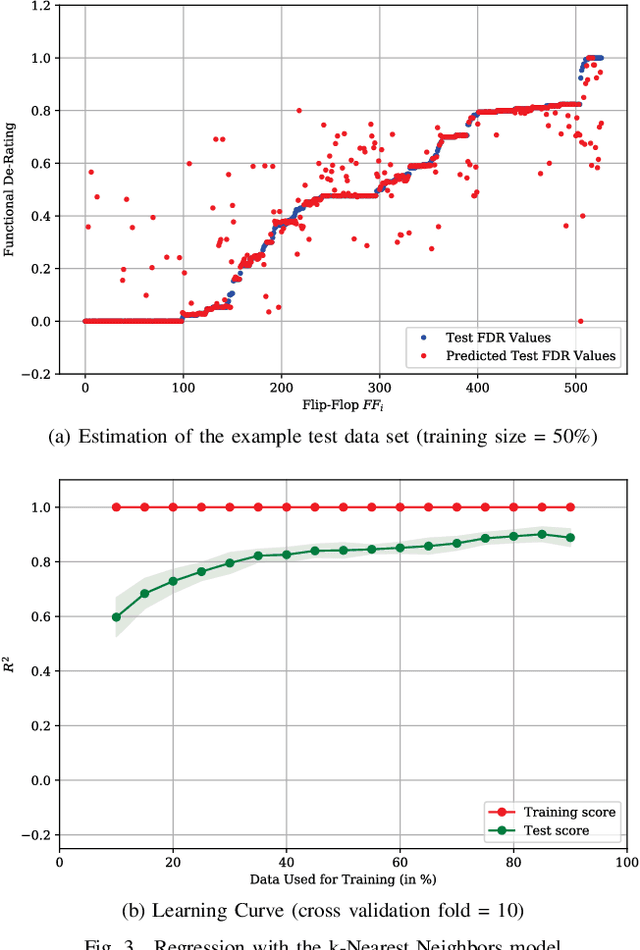
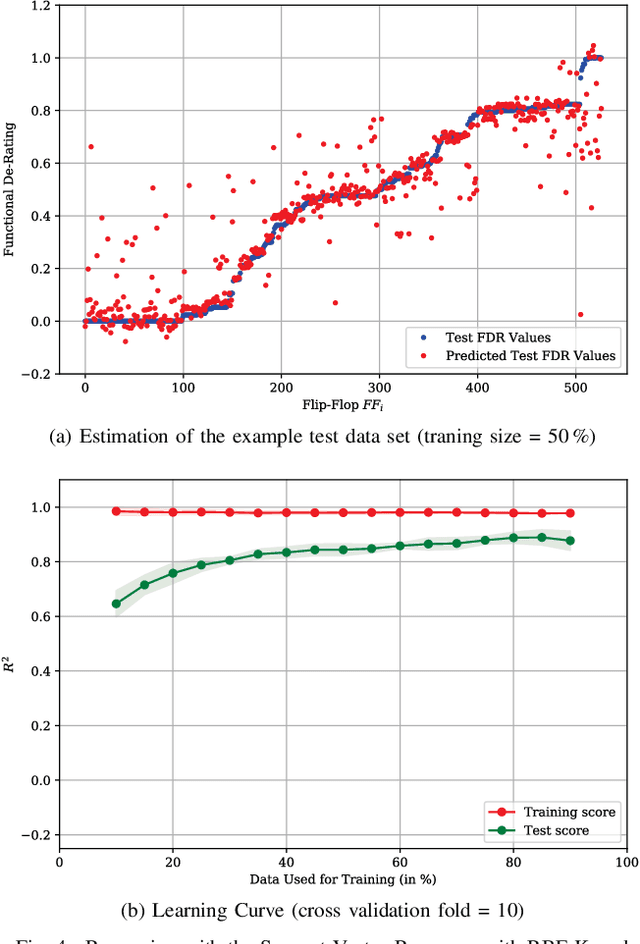
De-Rating or Vulnerability Factors are a major feature of failure analysis efforts mandated by today's Functional Safety requirements. Determining the Functional De-Rating of sequential logic cells typically requires computationally intensive fault-injection simulation campaigns. In this paper a new approach is proposed which uses Machine Learning to estimate the Functional De-Rating of individual flip-flops and thus, optimising and enhancing fault injection efforts. Therefore, first, a set of per-instance features is described and extracted through an analysis approach combining static elements (cell properties, circuit structure, synthesis attributes) and dynamic elements (signal activity). Second, reference data is obtained through first-principles fault simulation approaches. Finally, one part of the reference dataset is used to train the Machine Learning algorithm and the remaining is used to validate and benchmark the accuracy of the trained tool. The intended goal is to obtain a trained model able to provide accurate per-instance Functional De-Rating data for the full list of circuit instances, an objective that is difficult to reach using classical methods. The presented methodology is accompanied by a practical example to determine the performance of various Machine Learning models for different training sizes.