 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Any Motion Detector: Learning Class-agnostic Scene Dynamics from a Sequence of LiDAR Point Clouds
Apr 24, 2020
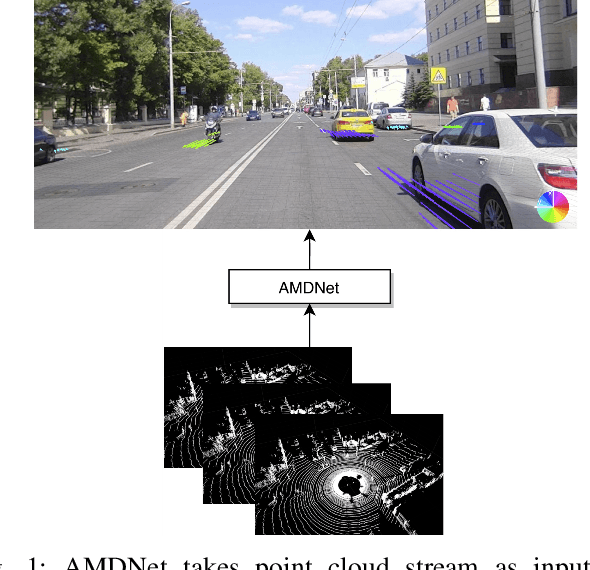
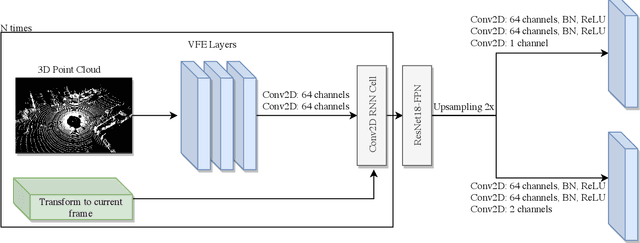
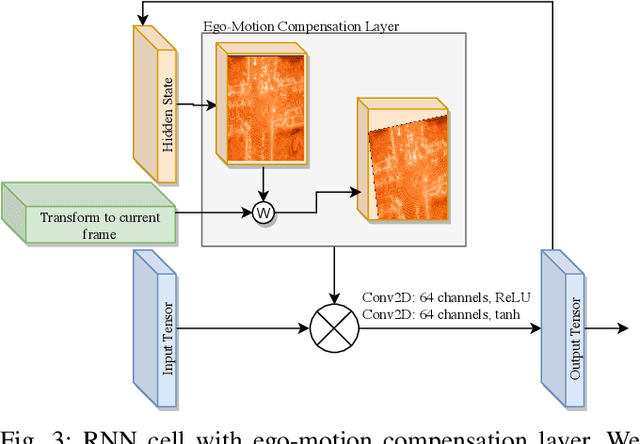
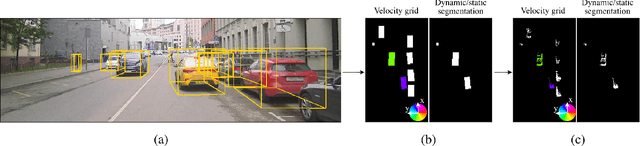
Object detection and motion parameters estimation are crucial tasks for self-driving vehicle safe navigation in a complex urban environment. In this work we propose a novel real-time approach of temporal context aggregation for motion detection and motion parameters estimation based on 3D point cloud sequence. We introduce an ego-motion compensation layer to achieve real-time inference with performance comparable to a naive odometric transform of the original point cloud sequence. Not only is the proposed architecture capable of estimating the motion of common road participants like vehicles or pedestrians but also generalizes to other object categories which are not present in training data. We also conduct an in-deep analysis of different temporal context aggregation strategies such as recurrent cells and 3D convolutions. Finally, we provide comparison results of our state-of-the-art model with existing solutions on KITTI Scene Flow dataset.
Driving Through Ghosts: Behavioral Cloning with False Positives
Aug 29, 2020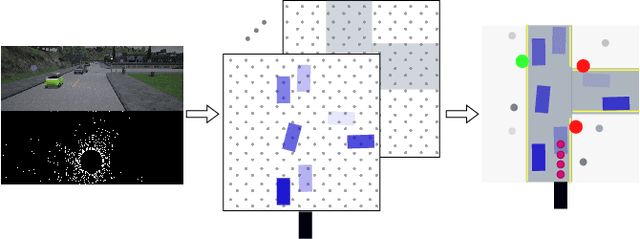
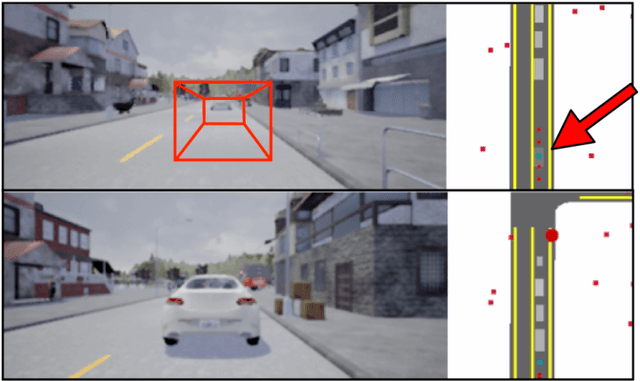
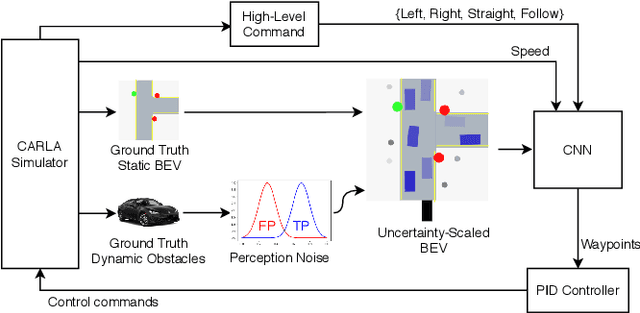
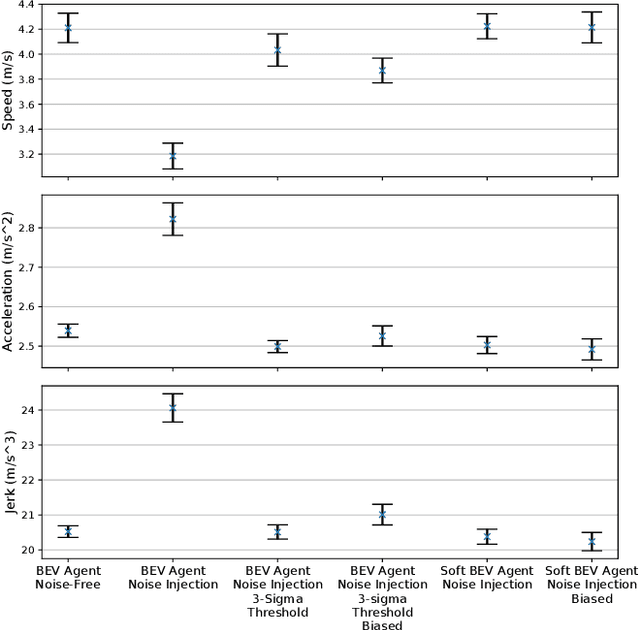
Safe autonomous driving requires robust detection of other traffic participants. However, robust does not mean perfect, and safe systems typically minimize missed detections at the expense of a higher false positive rate. This results in conservative and yet potentially dangerous behavior such as avoiding imaginary obstacles. In the context of behavioral cloning, perceptual errors at training time can lead to learning difficulties or wrong policies, as expert demonstrations might be inconsistent with the perceived world state. In this work, we propose a behavioral cloning approach that can safely leverage imperfect perception without being conservative. Our core contribution is a novel representation of perceptual uncertainty for learning to plan. We propose a new probabilistic birds-eye-view semantic grid to encode the noisy output of object perception systems. We then leverage expert demonstrations to learn an imitative driving policy using this probabilistic representation. Using the CARLA simulator, we show that our approach can safely overcome critical false positives that would otherwise lead to catastrophic failures or conservative behavior.
An Adversarial Domain Separation Framework for Septic Shock Early Prediction Across EHR Systems
Oct 26, 2020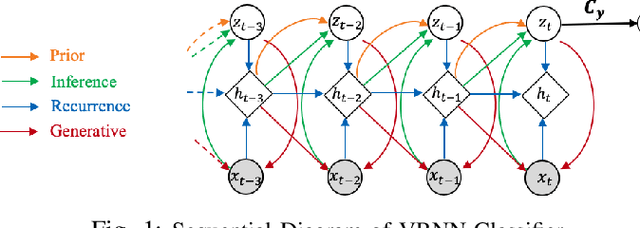
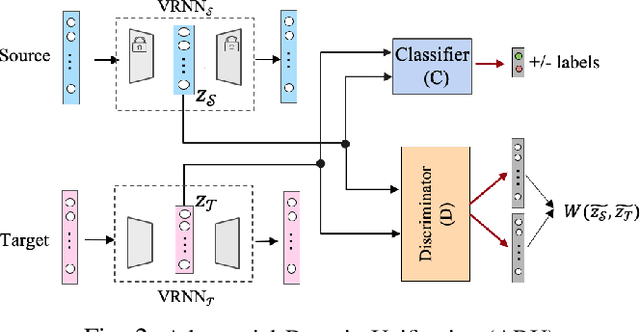
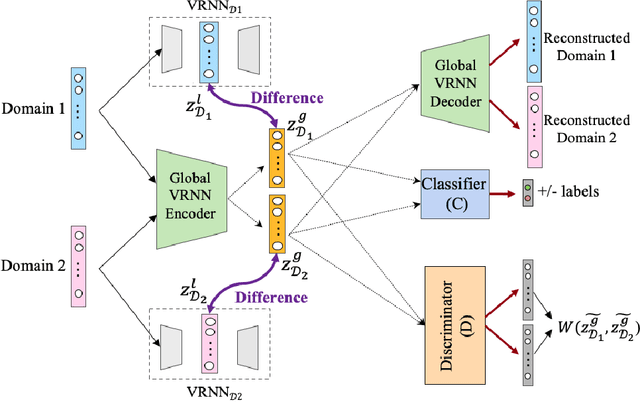
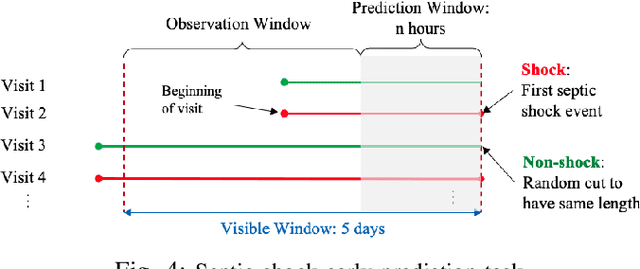
Modeling patient disease progression using Electronic Health Records (EHRs) is critical to assist clinical decision making. While most of prior work has mainly focused on developing effective disease progression models using EHRs collected from an individual medical system, relatively little work has investigated building robust yet generalizable diagnosis models across different systems. In this work, we propose a general domain adaptation (DA) framework that tackles two categories of discrepancies in EHRs collected from different medical systems: one is caused by heterogeneous patient populations (covariate shift) and the other is caused by variations in data collection procedures (systematic bias). Prior research in DA has mainly focused on addressing covariate shift but not systematic bias. In this work, we propose an adversarial domain separation framework that addresses both categories of discrepancies by maintaining one globally-shared invariant latent representation across all systems} through an adversarial learning process, while also allocating a domain-specific model for each system to extract local latent representations that cannot and should not be unified across systems. Moreover, our proposed framework is based on variational recurrent neural network (VRNN) because of its ability to capture complex temporal dependencies and handling missing values in time-series data. We evaluate our framework for early diagnosis of an extremely challenging condition, septic shock, using two real-world EHRs from distinct medical systems in the U.S. The results show that by separating globally-shared from domain-specific representations, our framework significantly improves septic shock early prediction performance in both EHRs and outperforms the current state-of-the-art DA models.
Tramp Ship Scheduling Problem with Berth Allocation Considerations and Time-dependent Constraints
May 04, 2017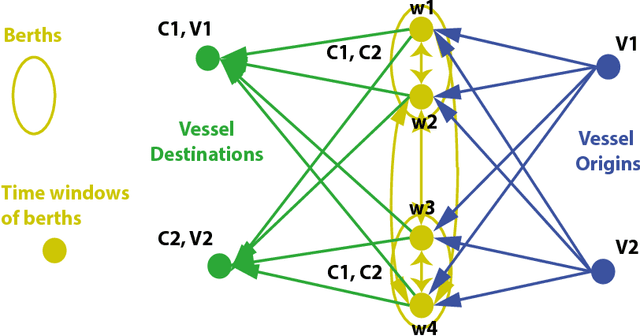

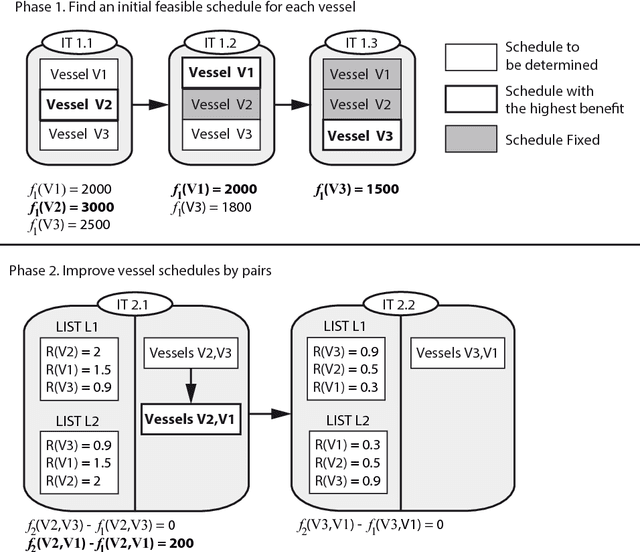

This work presents a model for the Tramp Ship Scheduling problem including berth allocation considerations, motivated by a real case of a shipping company. The aim is to determine the travel schedule for each vessel considering multiple docking and multiple time windows at the berths. This work is innovative due to the consideration of both spatial and temporal attributes during the scheduling process. The resulting model is formulated as a mixed-integer linear programming problem, and a heuristic method to deal with multiple vessel schedules is also presented. Numerical experimentation is performed to highlight the benefits of the proposed approach and the applicability of the heuristic. Conclusions and recommendations for further research are provided.
Orpheus: A New Deep Learning Framework for Easy Deployment and Evaluation of Edge Inference
Jul 24, 2020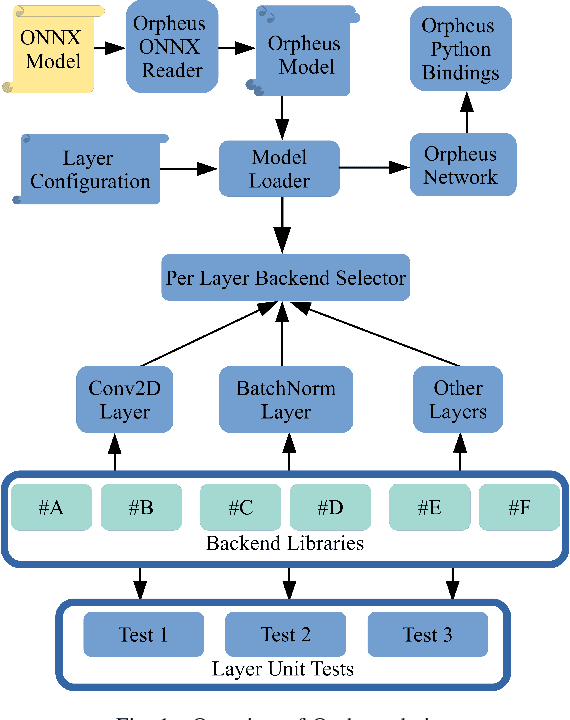
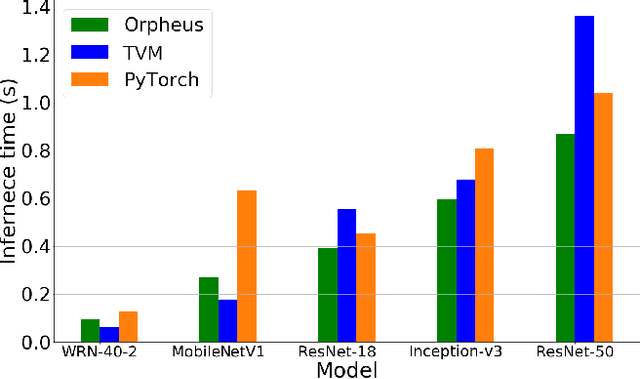
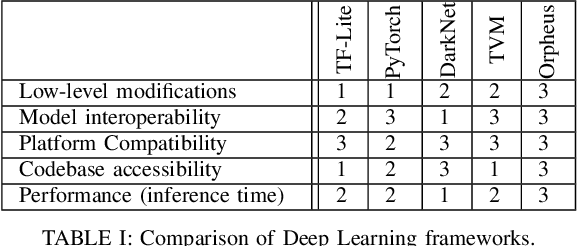
Optimising deep learning inference across edge devices and optimisation targets such as inference time, memory footprint and power consumption is a key challenge due to the ubiquity of neural networks. Today, production deep learning frameworks provide useful abstractions to aid machine learning engineers and systems researchers. However, in exchange they can suffer from compatibility challenges (especially on constrained platforms), inaccessible code complexity, or design choices that otherwise limit research from a systems perspective. This paper presents Orpheus, a new deep learning framework for easy prototyping, deployment and evaluation of inference optimisations. Orpheus features a small codebase, minimal dependencies, and a simple process for integrating other third party systems. We present some preliminary evaluation results.
RTFE: A Recursive Temporal Fact Embedding Framework for Temporal Knowledge Graph Completion
Oct 10, 2020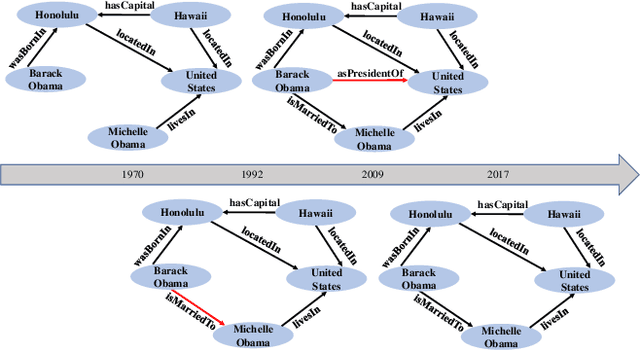
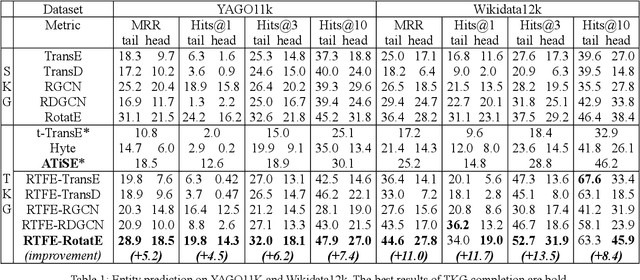

In recent years, many efforts have been made to complete knowledge graphs (KGs) by various graph embedding methods, most of which only focus on static KGs (SKGs) without considering the time dependency of facts. However, KGs in reality are dynamic and there exists correlations between facts with different timestamps. Due to the sparsity of temporal KGs (TKGs), SKG embedding methods cannot be directly applied to TKGs. And existing methods of TKG embedding suffer from two issues: (1) they follow the pattern of SKG embedding where all facts need to be retrained when a new timestamp appears; (2) they don't provide a general way to transplant SKG embedding methods to TKGs and therefore lack extensibility. In this paper, we propose a novel Recursive Temporal Fact Embedding Framework (RTFE) to transplant translation-based or graph neural network-based SKG embedding methods to TKGs. In the recursive way, timestamp parameters provide a good starting point for the next future timestamp. And existing SKG embedding models can be used as components. Experiments on TKGs show that our proposed framework (1) outperforms the state-of-the-art baseline model in the entity prediction task on fact datasets; (2) achieves similar performance compared with the state-of-the-art baseline model in relation prediction task on fact datasets; and (3) shows performance in the entity prediction task on event datasets.
A study of influential factors in designing self-reconfigurable robots for green manufacturing
Apr 17, 2020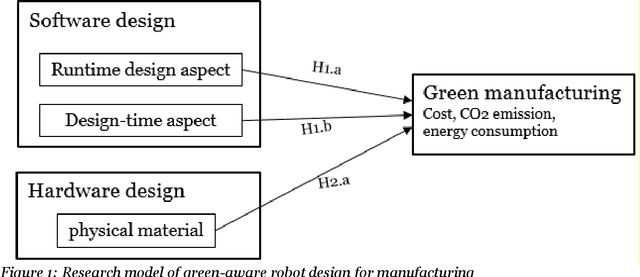
There is incremental growth in adopting self-reconfigurable robots in automating manufacturing conventional product lines. Using this class of robots adapting themselves with ever-changing environmental conditions has been acclaimed as a promising way of reducing energy consumption and environmental impact and thus enabling green manufacturing. Whilst the majority of existing research focuses on highlighting the efficacy of self-reconfigurable robots in energy reduction with technical driven solutions, the research on exploring the salient factors in design and development self-reconfigurable robots that directly enable or hinder green manufacturing is non-extant. This interdisciplinary research contributes to the nascent body of the knowledge by empirical investigation of design-time, run-time, and hardware aspects which should be contingently balanced when developing green-aware self-reconfigurable robots. Keywords Green manufacturing, self-reconfigurable robots, robot design, green awareness
Spectral Clustering with Smooth Tiny Clusters
Sep 10, 2020Spectral clustering is one of the most prominent clustering approaches. The distance-based similarity is the most widely used method for spectral clustering. However, people have already noticed that this is not suitable for multi-scale data, as the distance varies a lot for clusters with different densities. State of the art(ROSC and CAST ) addresses this limitation by taking the reachability similarity of objects into account. However, we observe that in real-world scenarios, data in the same cluster tend to present in a smooth manner, and previous algorithms never take this into account. Based on this observation, we propose a novel clustering algorithm, which con-siders the smoothness of data for the first time. We first divide objects into a great many tiny clusters. Our key idea is to cluster tiny clusters, whose centers constitute smooth graphs. Theoretical analysis and experimental results show that our clustering algorithm significantly outperforms state of the art. Although in this paper, we singly focus on multi-scale situations, the idea of data smoothness can certainly be extended to any clustering algorithms
Breaking (Global) Barriers in Parallel Stochastic Optimization with Wait-Avoiding Group Averaging
Apr 30, 2020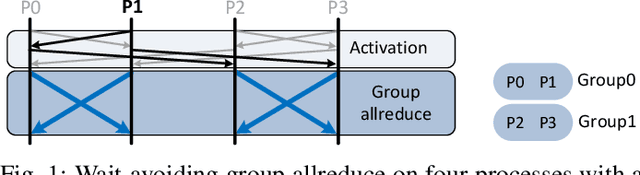
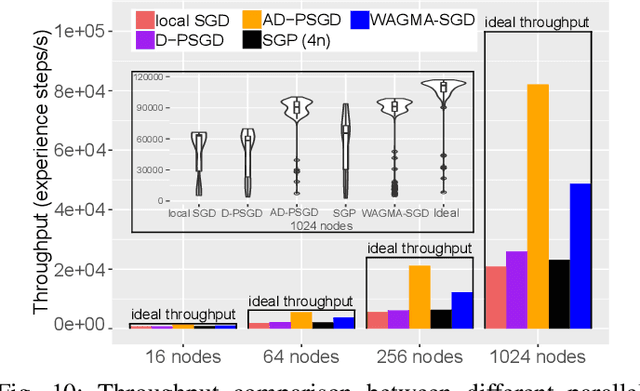
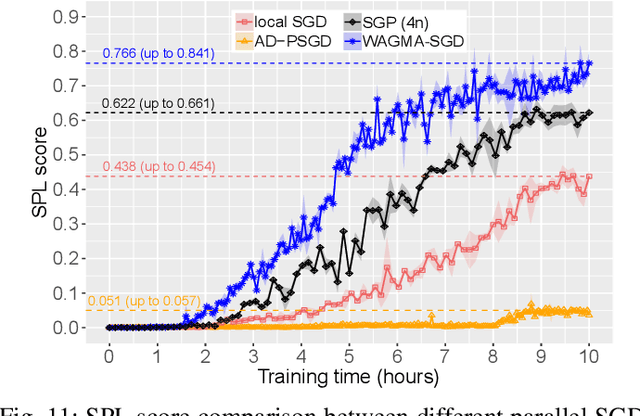
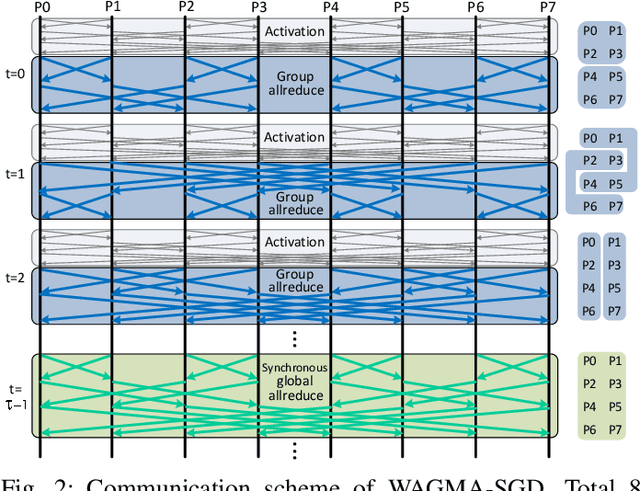
Deep learning at scale is dominated by communication time. Distributing samples across nodes usually yields the best performance, but poses scaling challenges due to global information dissemination and load imbalance across uneven sample lengths. State-of-the-art decentralized optimizers mitigate the problem, but require more iterations to achieve the same accuracy as their globally-communicating counterparts. We present Wait-Avoiding Group Model Averaging (WAGMA) SGD, a wait-avoiding stochastic optimizer that reduces global communication via subgroup weight exchange. The key insight is a combination of algorithmic changes to the averaging scheme and the use of a group allreduce operation. We prove the convergence of WAGMA-SGD, and empirically show that it retains convergence rates equivalent to Allreduce-SGD. For evaluation, we train ResNet-50 on ImageNet; Transformer for machine translation; and deep reinforcement learning for navigation at scale. Compared with state-of-the-art decentralized SGD, WAGMA-SGD significantly improves training throughput (by 2.1x on 1,024 GPUs) and achieves the fastest time-to-solution.
Handgun detection using combined human pose and weapon appearance
Oct 26, 2020
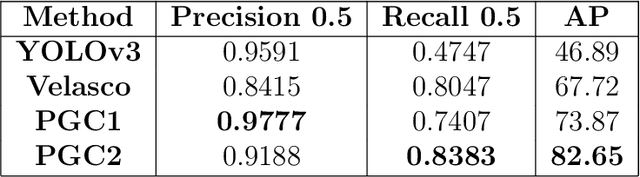

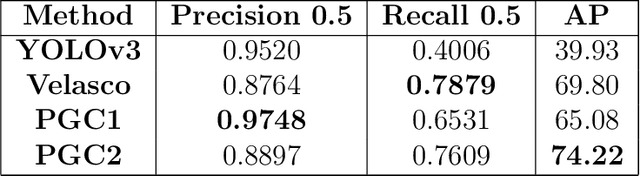
CCTV surveillance systems are essential nowadays to prevent and mitigate security threats or dangerous situations such as mass shootings or terrorist attacks, in which early detection is crucial. These solutions are manually supervised by a security operator, which has significant limitations. Novel deep learning-based methods have allowed to develop automatic and real time weapon detectors with promising results. However, these approaches are based on visual weapon appearance only and no additional contextual information is exploited. For handguns, body pose may be a useful cue, especially in cases where the gun is barely visible and also as a way to reduce false positives. In this work, a novel method is proposed to combine in a single architecture both weapon appearance and 2D human pose information. First, pose keypoints are estimated to extract hand regions and generate binary pose images, which are the model inputs. Then, each input is processed with a different subnetwork to extract two feature maps. Finally, this information is combined to produce the hand region prediction (handgun vs no-handgun). A new dataset composed of samples collected from different sources has been used to evaluate model performance under different situations. Moreover, the robustness of the model to different brightness and weapon size conditions (simulating conditions in which appearance is degraded by low light and distance to the camera) have also been tested. Results obtained show that the combined model improves overall performance substantially with respect to appearance alone as used by other popular methods such as YOLOv3.